Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье показано, как использовать расширенные функции сервера журналов Apache Spark для отладки и диагностики готовых и запущенных приложений Spark. Расширение содержит вкладки Данные, Диаграмма и Диагностика. На вкладке Данные можно проверить входные и выходные данные задания Spark. На вкладке Диаграмма можно проверить поток данных и воспроизвести диаграмму заданий. На вкладке Диагностика можно воспользоваться функциями Неравномерное распределение данных, Неравномерное распределение времени и Executor Usage Analysis (Анализ использования исполнителя).
Получение доступа к серверу журнала Spark
Сервер журнала Spark — это пользовательский веб-интерфейс для готовых и запущенных приложений Spark. Его можно открыть либо с портала Azure, либо по URL-адресу.
Открытие пользовательского веб-интерфейса сервера журнала Spark на портале Azure
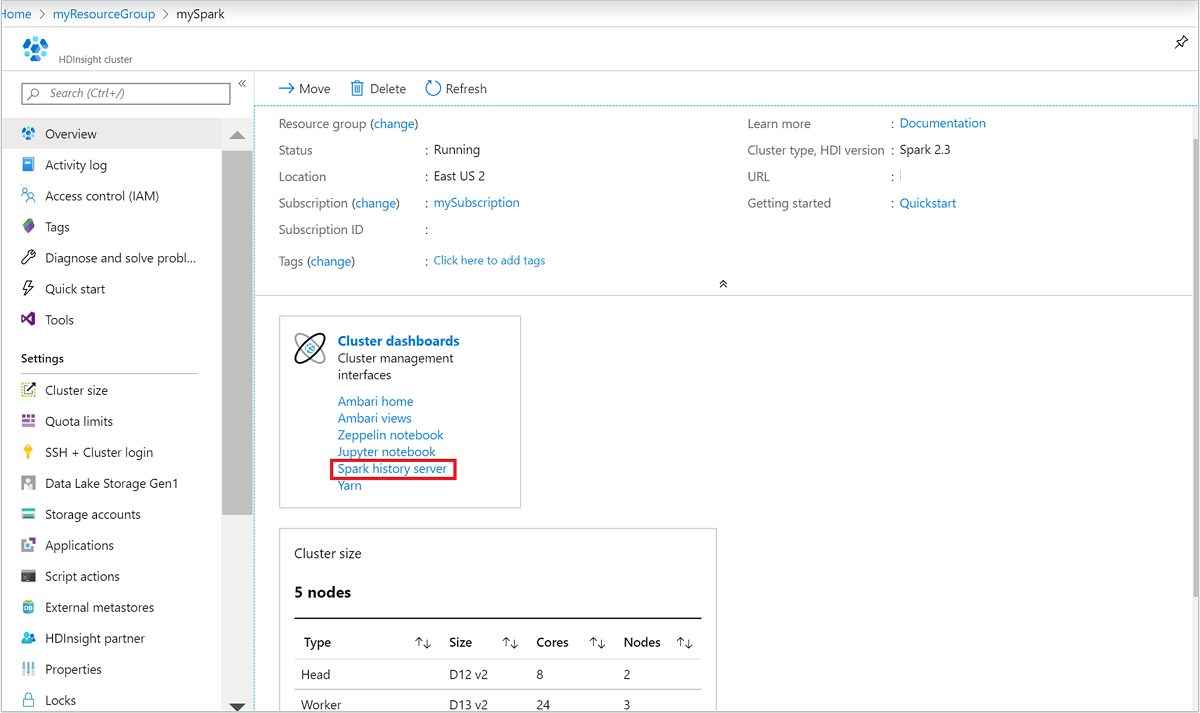
Откройте кластер Spark на портале Azure. Дополнительные сведения см. в разделе Отображение кластеров.
На Панели мониторинга кластера выберите Сервер журнала Spark. При появлении запроса введите учетные данные администратора для кластера Spark.
 портал Azure." border="true":::
портал Azure." border="true":::
Открытие пользовательского веб-интерфейса сервера журнала Spark по URL-адресу
Откройте сервер журнала Spark, перейдя по адресу https://CLUSTERNAME.azurehdinsight.net/sparkhistory, где CLUSTERNAME — это имя кластера Spark.
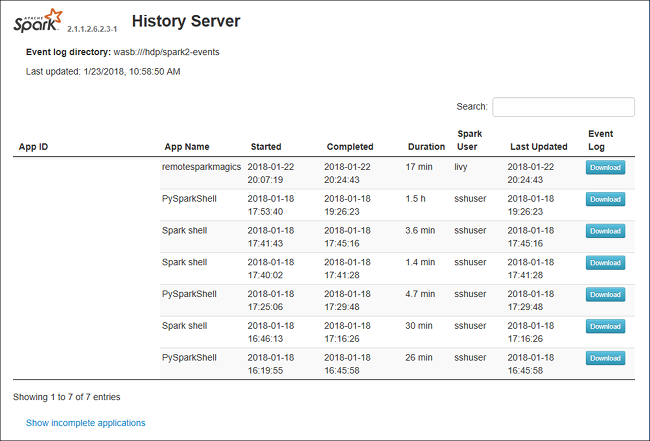
Веб-интерфейс сервера журнала Spark может выглядеть следующим образом:
Использование вкладки "Данные" на сервере журнала Spark
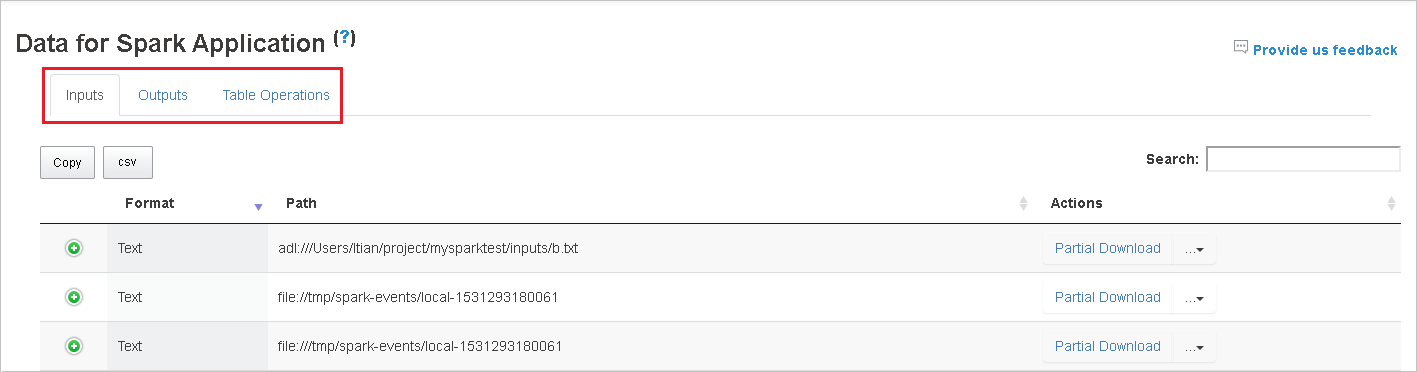
Выберите идентификатор задания, а затем в меню инструментов выберите пункт Данные, чтобы открыть представление данных.
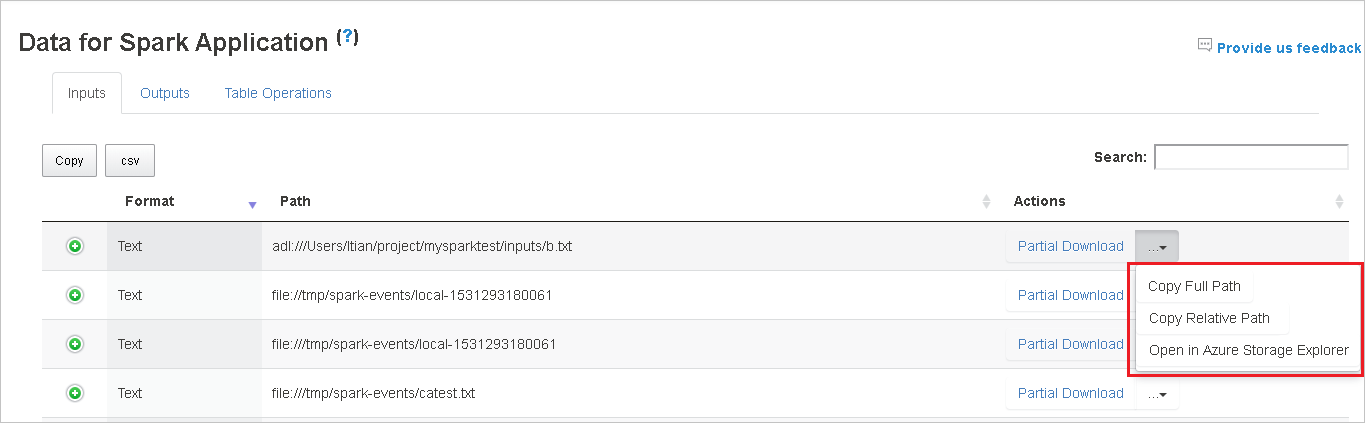
Просмотрите данные на вкладках Входы, Выходы и Операции с таблицей.
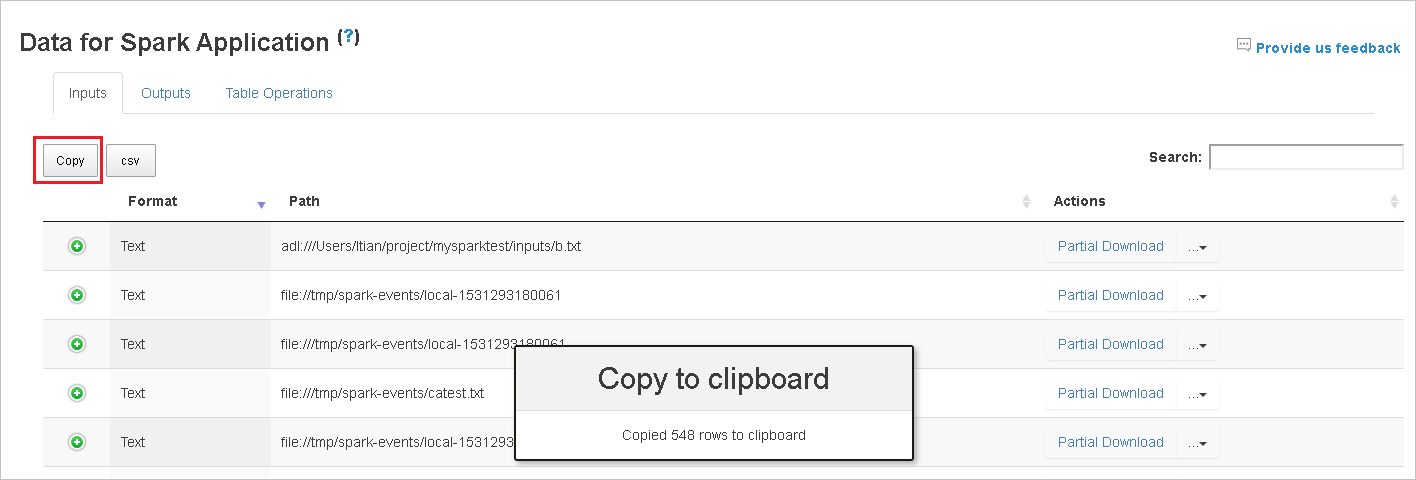
Скопируйте все строки, нажав кнопку Копировать.
Сохраните все данные как CSV-файл, нажав кнопку CSV.
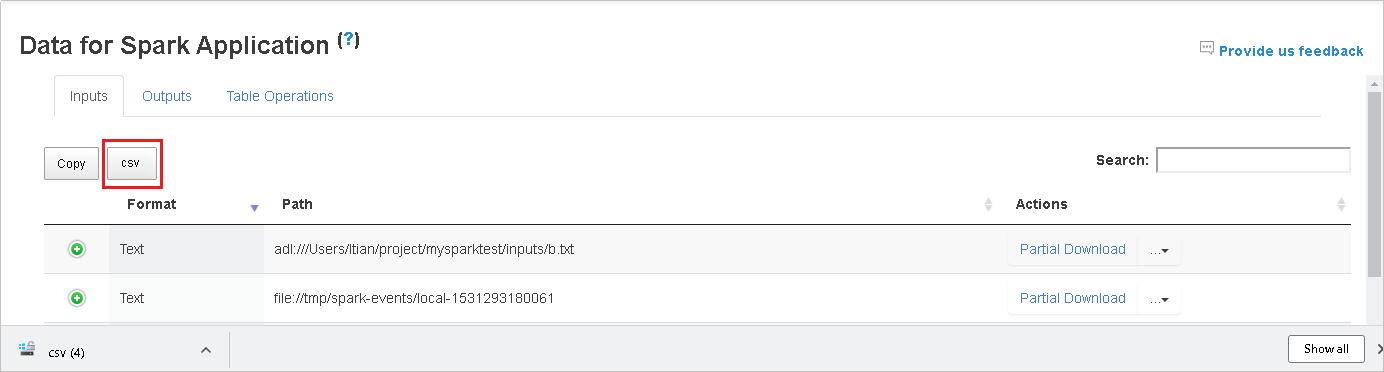
Выполните поиск данных, введя ключевые слова в поле Поиск. Результаты поиска отобразятся немедленно.
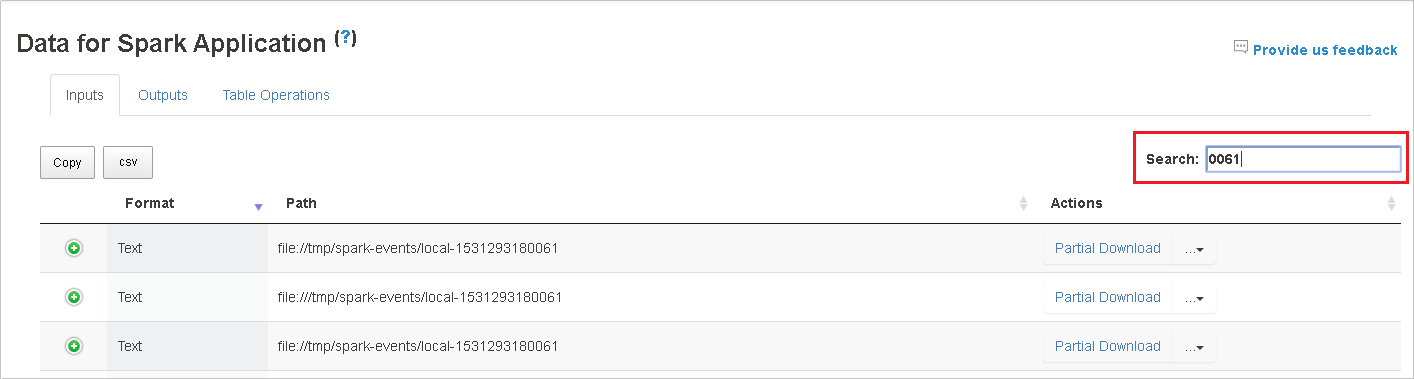
Выберите заголовок столбца, чтобы сортировать таблицу. Щелкните знак "плюс", чтобы развернуть строку и отобразить дополнительные сведения. Щелкните знак "минус", чтобы свернуть строку.
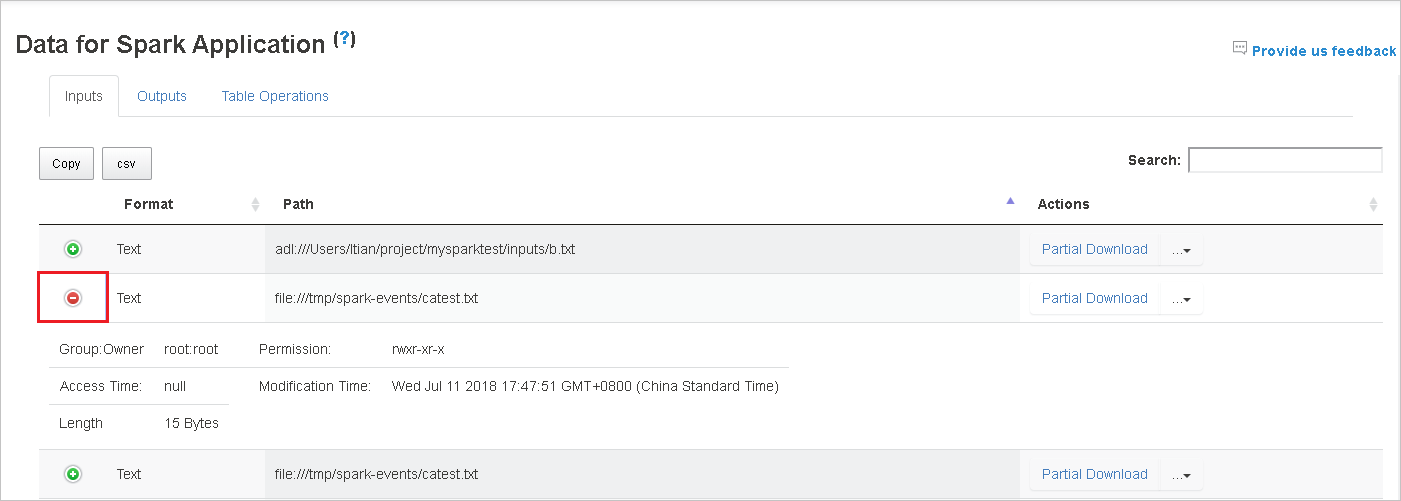
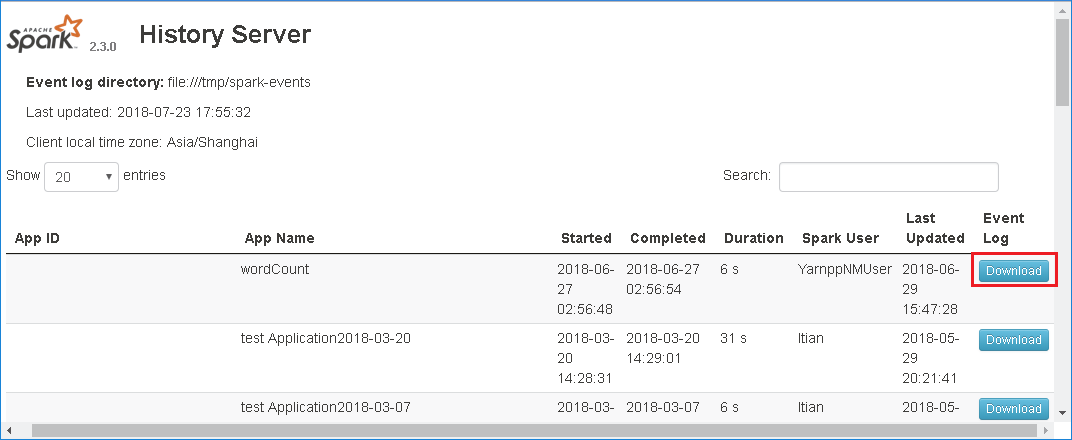
Скачайте один файл, нажав кнопку Частичное скачивание справа. Выбранный файл будет скачан локально. Если файл больше не существует, откроется новая вкладка с сообщениями об ошибках.
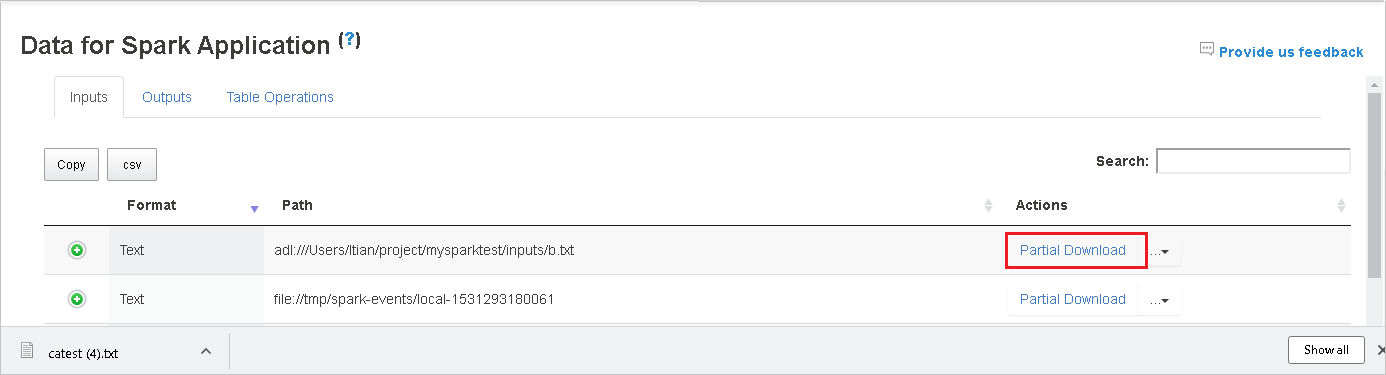
Скопируйте полный или относительный путь, выбрав в раскрывающемся меню скачивания параметр Копировать полный путь или Копировать относительный путь. Для файлов Azure Data Lake Storage выберите Открыть в Обозревателе службы хранилища Azure, чтобы запустить Обозреватель службы хранилища Azure, и найдите папку после входа в систему.
Если на одной странице слишком много строк для отображения, выберите номера страниц в нижней части таблицы для перехода.

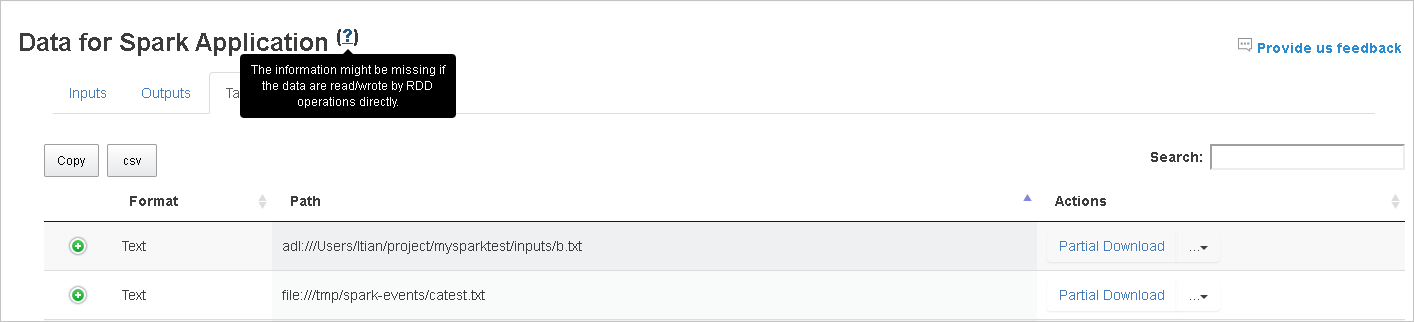
Для получения дополнительных сведений наведите указатель мыши на знак вопроса или щелкните его рядом с надписью Data for Spark Application (Данные для приложения Spark), чтобы отобразить подсказку.
Чтобы отправить отзыв о проблемах, выберите Provide us feedback (Отправить нам отзыв).
Использование вкладки "Диаграмма" на сервере журналов Spark
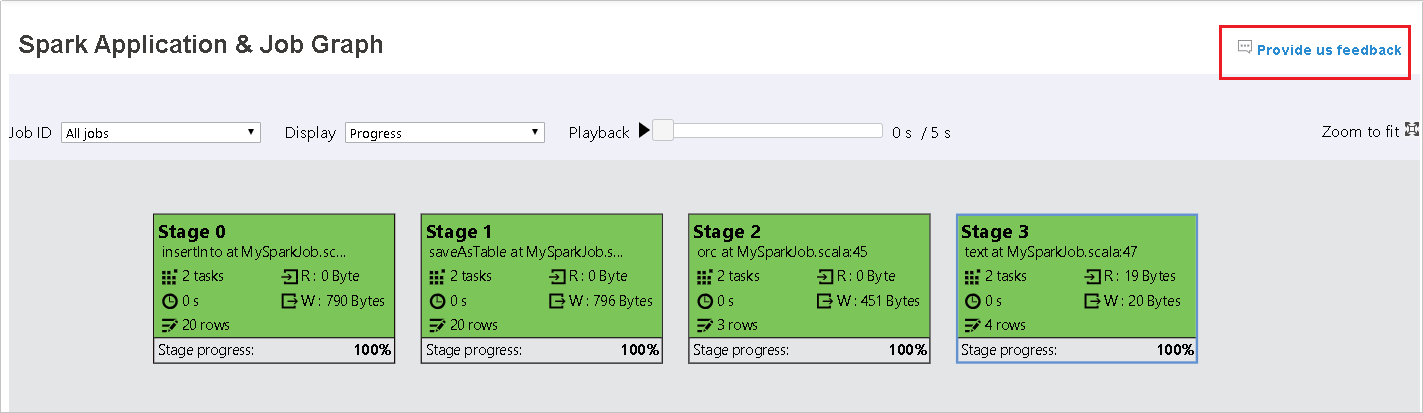
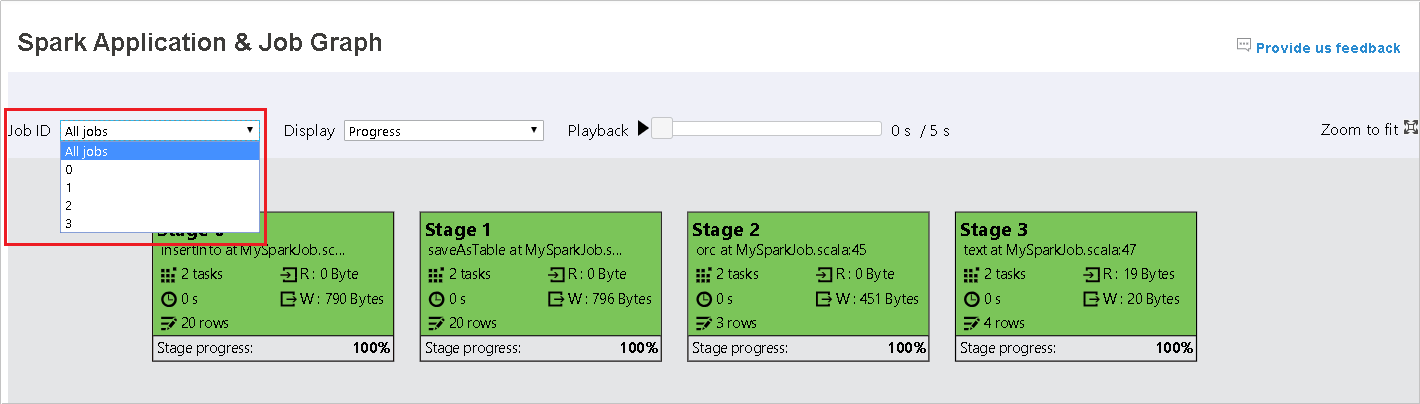
Выберите идентификатор задания, а затем в меню инструментов выберите пункт Диаграмма, чтобы просмотреть диаграмму заданий. По умолчанию на диаграмме отображаются все задания. Отфильтруйте результаты с помощью раскрывающегося меню Идентификатор задания.
По умолчанию выбрано значение Выполнение. Выбрав в раскрывающемся меню Отображение пункт Чтение или Запись, можно проверить поток данных.
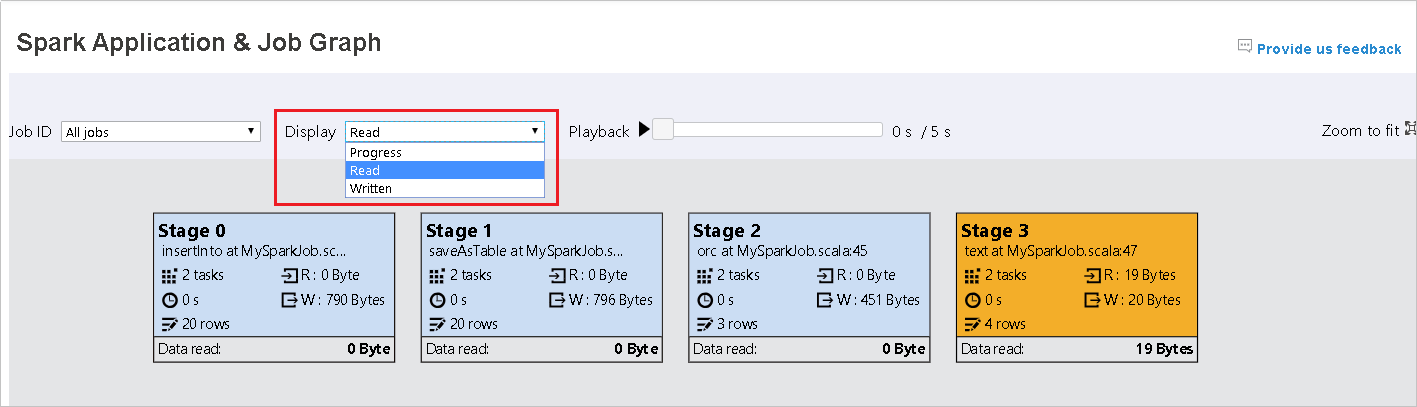
Цвет фона каждой задачи соответствует тепловой карте.

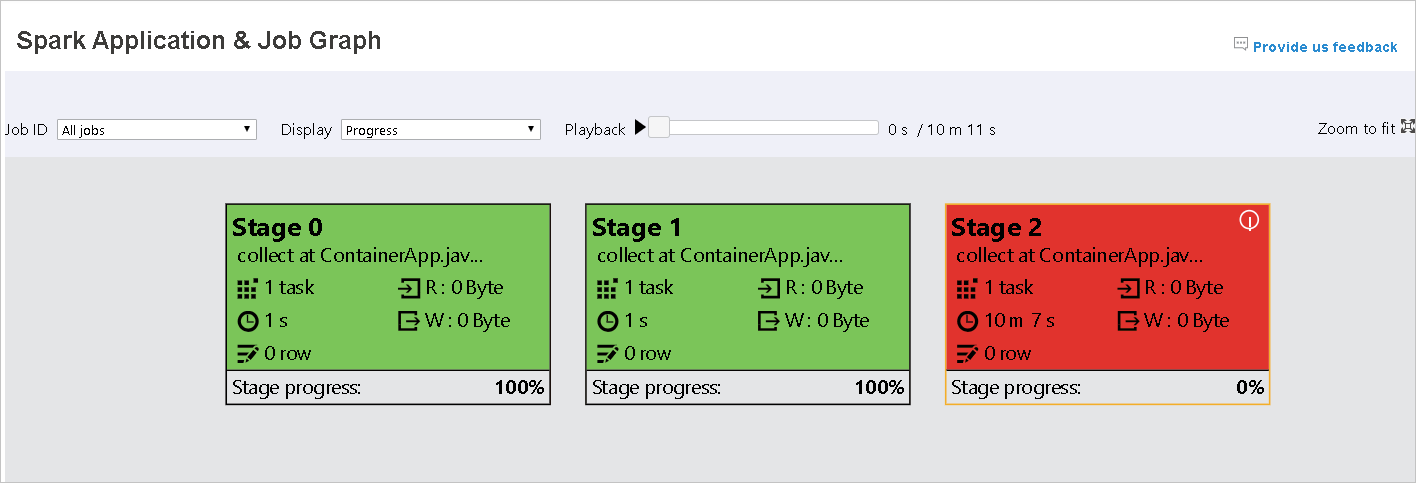
Color Description Зеленый задание выполнено успешно. Orange Задачу выполнить не удалось, но это не повлияет на окончательный результат задания. Эти задачи имеют дублирующиеся или повторные экземпляры, которые могут быть успешно выполнены позже. Синий задача выполняется. Белый задача ожидает выполнения, либо этап пропущен. Красный задачу выполнить не удалось. 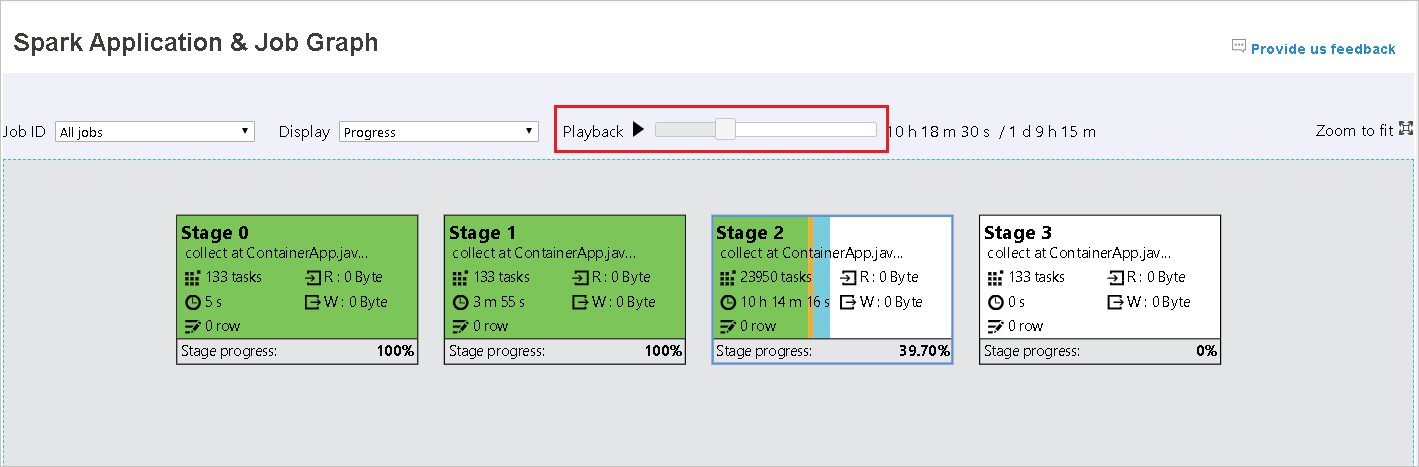
Пропущенный этап отображается белым цветом.
Примечание.
Для завершенных заданий доступно воспроизведение. Нажмите кнопку Воспроизведение, чтобы воспроизвести задание. Задание можно прервать в любое время, нажав кнопку "Остановить". При воспроизведении задания в каждой задаче его состояние обозначается цветом. Для незавершенных заданий воспроизведение не поддерживается.
С помощью прокрутки можно увеличить или уменьшить диаграмму задания, а выбрав Подогнать масштаб, можно отобразить ее в соответствии с размерами экрана.
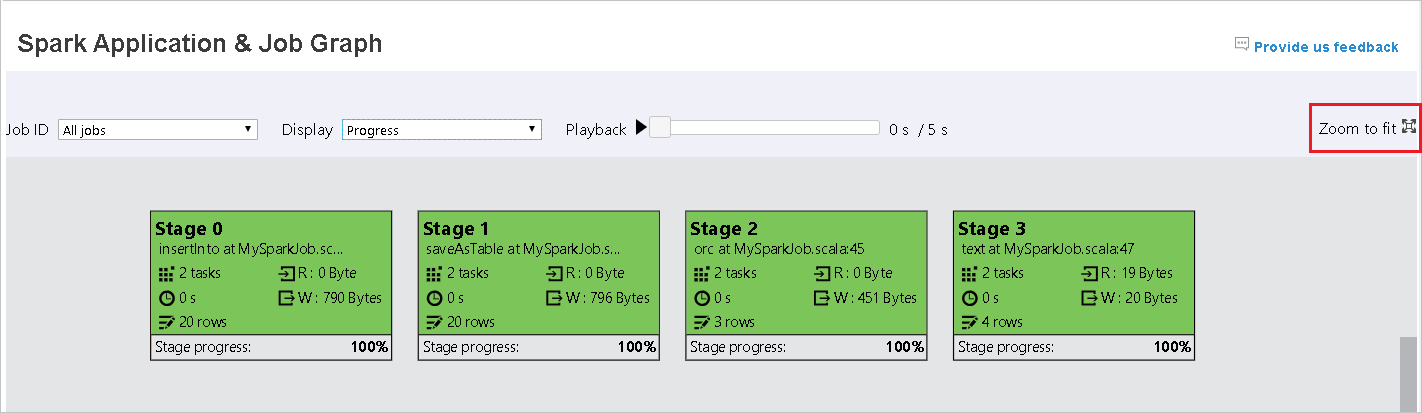
При сбое задач наведите указатель мыши на узел графа, чтобы увидеть подсказку, а затем выберите этап, чтобы открыть его на новой странице.
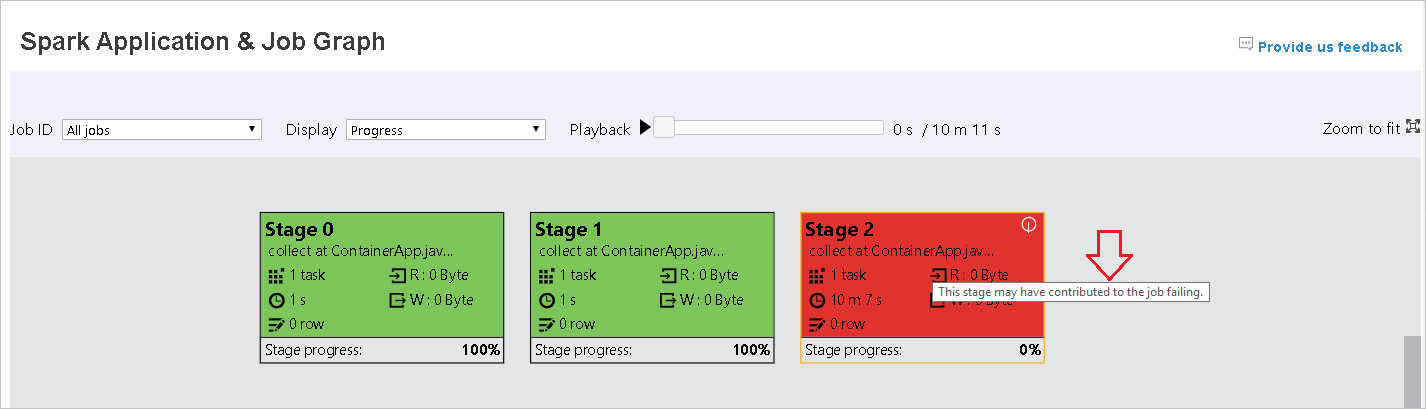
На странице Spark Application & Job Graph (Приложение Spark и диаграмма заданий) для этапов будут отображаться подсказки и небольшие значки, если задачи соответствуют следующим условиям.
Неравномерное распределение данных: размер считанных данных > средний размер считанных данных для всех задач на этом этапе * 2 и размер считанных данных > 10 МБ.
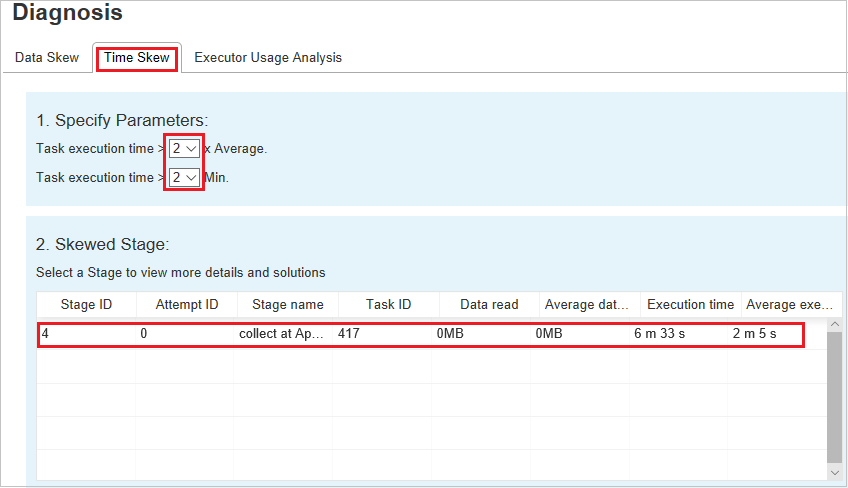
Неравномерное распределение времени: время выполнения > среднее время выполнения всех задач на этом этапе * 2 и время выполнения > 2 мин.
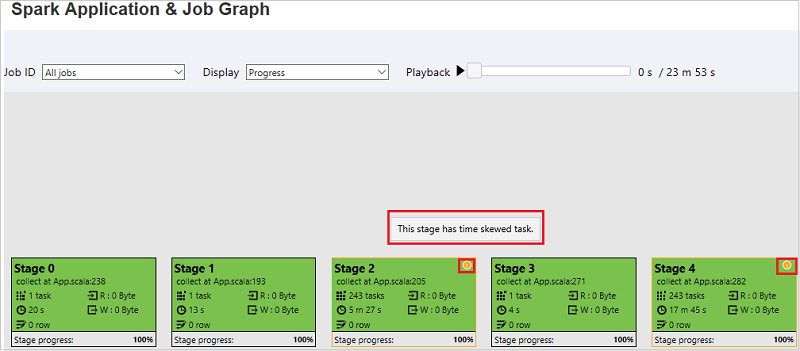
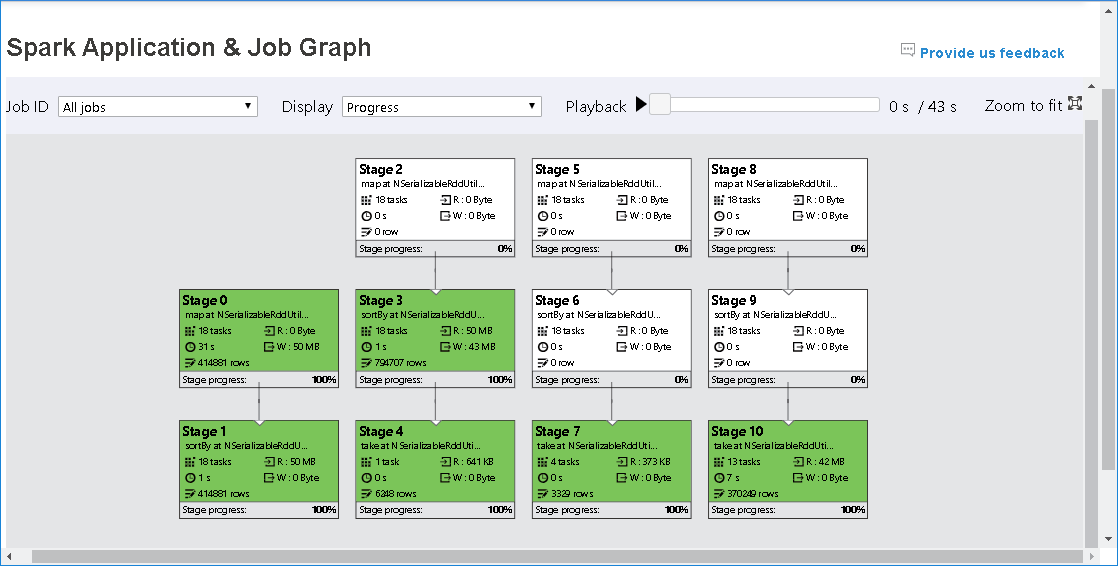
В узле графа задания отображаются следующие сведения о каждом этапе:
Идентификатор
Имя или описание
общее количество задач;
чтение данных: сумма размера входных данных и размер данных чтения в случайном порядке;
запись данных: сумма размера выходных данных и размер данных записи в случайном порядке;
время выполнения: время от начала первой попытки до завершения последней попытки;
число строк: сумма входных записей, выходных записей, записей смешанного чтения и записей смешанной записи;
Ход выполнения
Примечание.
По умолчанию в узле диаграммы заданий отображаются сведения о последней попытке каждого этапа (за исключением времени выполнения этапа). Однако во время воспроизведения в узле графа задания будут отображаться сведения о каждой попытке.
Примечание.
Для размера считанных и записанных данных используются соотношения 1 МБ = 1000 КБ = 1000 * 1000 байтов.
Чтобы отправить отзыв о проблемах, щелкните Provide us feedback.
Использование вкладки "Диагностика" на сервере журналов Spark
Выберите идентификатор задания, а затем в меню инструментов выберите пункт Диагностика, чтобы отобразить диагностику задания. На вкладке Диагностика доступны вкладки Неравномерное распределение данных, Неравномерное распределение времени и Executor Usage Analysis (Анализ использования исполнителя).
Выберите вкладку Неравномерное распределение данных, Неравномерное распределение времени или Executor Usage Analysis (Анализ использования исполнителя), чтобы просмотреть соответствующие сведения.
Неравномерное распределение данных
Выберите вкладку Неравномерное распределение данных. Отобразятся соответствующие задачи с неравномерным распределением на основе указанных параметров.
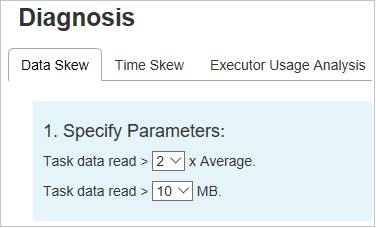
Указание параметров
В разделе Укажите параметры отображаются параметры, которые служат для обнаружения неравномерного распределения данных. Правило по умолчанию формулируется так: размер считанных данных задачи больше троекратного среднего размера считанных данных задачи и больше 10 МБ. Если необходимо самостоятельно задать правила для задач с неравномерным распределением, вы сможете сделать это, настроив необходимые параметры. Разделы Этап с отклонением и Диаграмма отклонений будут обновлены соответствующим образом.
Этап с отклонением
В разделе Этап с отклонением отображаются этапы, имеющие задачи с неравномерным распределением, которые отвечают указанным критериям. Если на этапе присутствует несколько задач с отклонением, в разделе Этап с отклонением отобразится только задача с наибольшим отклонением (то есть наибольшие данные для неравномерного распределения данных).
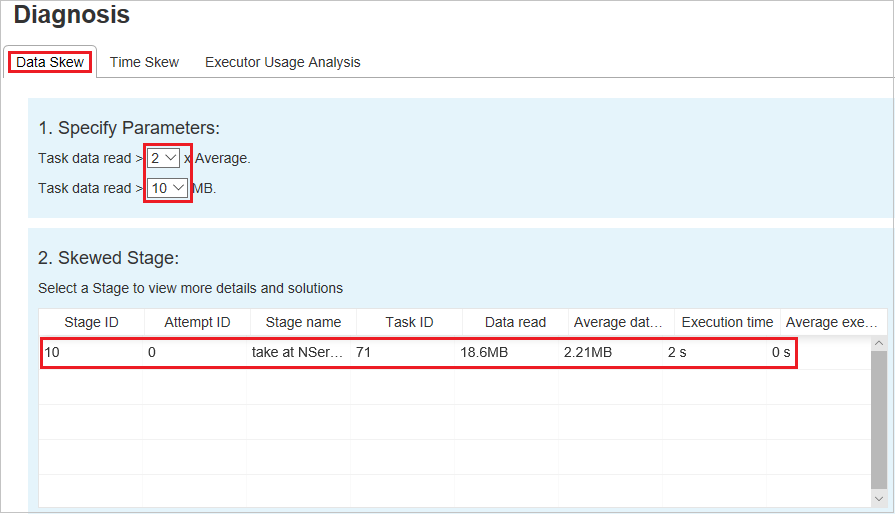
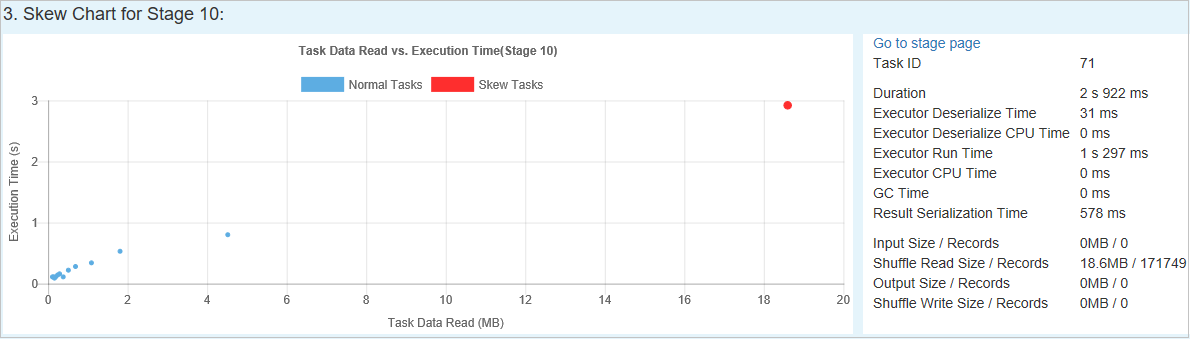
Диаграмма отклонений
При выборе конкретной строки в таблице Этап с отклонением на диаграмме отклонений отображаются более подробные сведения о распределении задач на основе показателей считанных данных и времени выполнения. Задачи с неравномерным распределением отмечены красным цветом, а нормальные задачи — синим. Для повышения производительности на диаграмме отображаются не более 100 образцов задач. Подробные сведения о задаче отображаются на правой нижней панели.
Неравномерное распределение времени
На вкладке Неравномерное распределение времени отображаются задачи с неравномерным распределением времени выполнения.
Указание параметров
В разделе Укажите параметры отображаются параметры, которые служат для обнаружения неравномерного распределения времени. Правило по умолчанию — время выполнения задачи больше троекратного среднего времени выполнения и превышает 30 секунд. Параметры можно изменить в соответствии с вашими потребностями. В разделах Этап с отклонением и Диаграмма отклонения отображаются соответствующие сведения об этапах и задачах, так же как на вкладке Неравномерное распределение данных.
При выборе параметра Неравномерное распределение времени в разделе Этап с отклонением отображается результат, отфильтрованный в соответствии с параметрами, заданными в разделе Укажите параметры. При выборе одного элемента в разделе Этап с отклонением соответствующая диаграмма в третьем разделе преобразуется в черновик, а на нижней правой панели отображаются сведения о задаче.
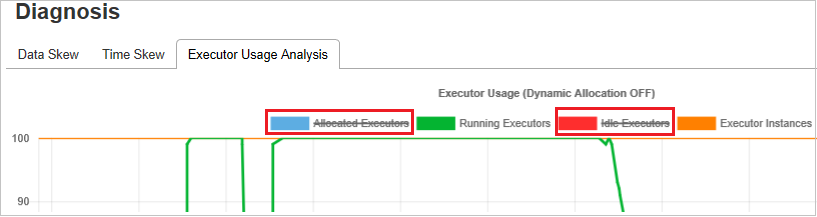
Диаграммы для анализа использования исполнителя
На графе использования исполнителей отображается фактическое распределение исполнителей и состояние выполнения задания.
При выборе вкладки Executor Usage Analysis (Анализ использования исполнителя) будут построены четыре кривые использования исполнителя четырех типов: Выделенные исполнители, Выполняющиеся исполнители, Исполнители в режиме ожидания и Максимальное количество экземпляров исполнителей. Каждое событие добавления или удаления исполнителя приводит к увеличению или уменьшению количества выделенных исполнителей. Дополнительные возможности сравнения доступны на временной шкале событий на вкладке Задания.
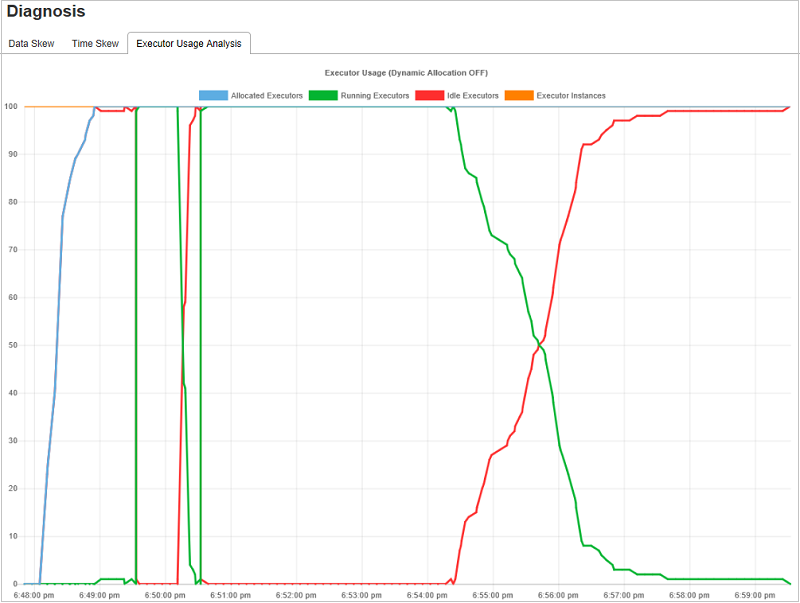
Щелкните значок цвета, чтобы выбрать соответствующее содержимое на всех графиках или отменить его выбор.
Вопросы и ответы
Как вернуться к версии для сообщества?
Чтобы вернуться к версии для сообщества, сделайте следующее.
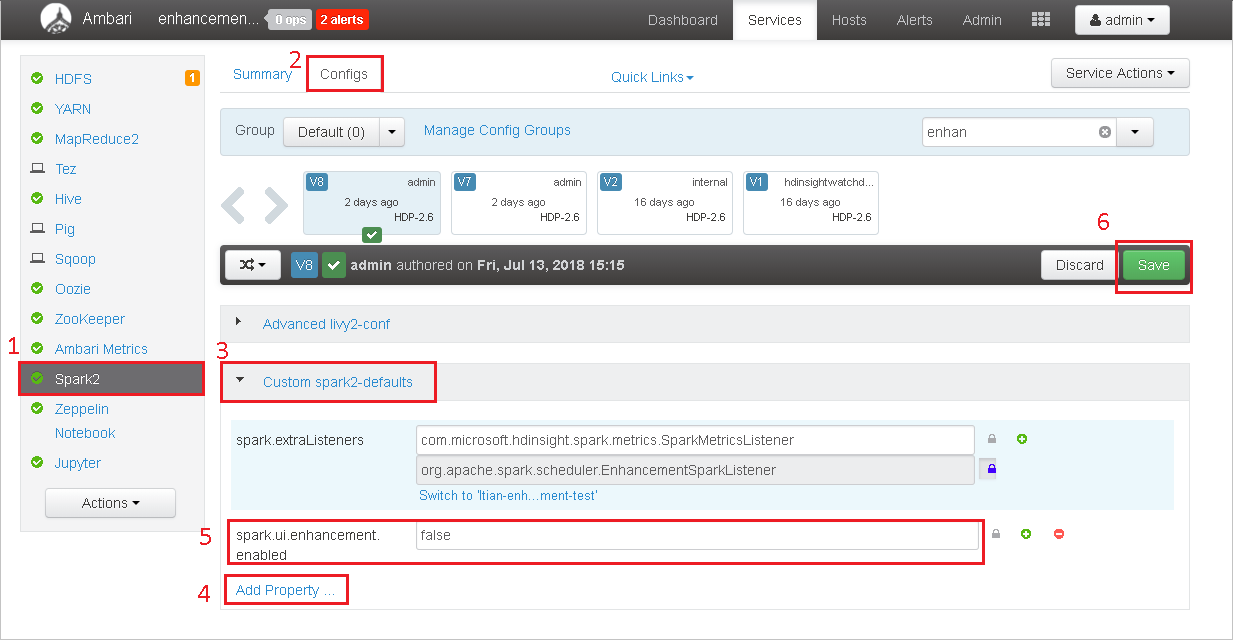
Откройте кластер в Ambari.
Перейдите в раздел Spark2>Configs.
Выберите Custom spark2-defaults.
Выберите Добавить свойство...
Добавьте свойство spark.ui.enhancement.enabled=false, а затем сохраните его.
Это свойство задает значение false.
Выберите Сохранить, чтобы сохранить конфигурацию.
Выберите Spark2 на панели слева. Затем на вкладке Сводка выберите Spark2 History Server.
Чтобы перезапустить сервер журнала Spark, нажмите кнопку Запущено справа от Spark2 History Server, а затем в раскрывающемся меню выберите Перезапустить.
Обновите пользовательский веб-интерфейс сервера журнала Spark. В результате будет выполнен возврат к версии для сообщества.
Как отправить событие сервера журнала Spark, чтобы сообщить о нем как о проблеме?
В случае ошибки на сервере журнала Spark выполните следующие действия, чтобы сообщить о событии.
Скачайте событие, выбрав Скачать в пользовательском веб-интерфейсе сервера журнала Spark.
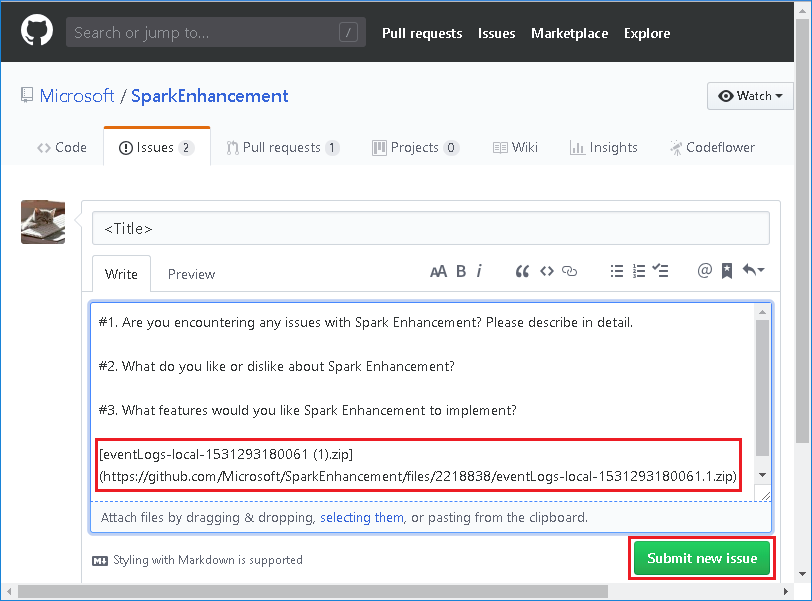
Выберите Provide us feedback (Отправить нам отзыв) на странице Spark Application & Job Graph (Приложение Spark и диаграмма заданий).
Укажите заголовок и описание ошибки. Затем перетащите ZIP-файл в поле редактирования и выберите Submit new issue (Передать данные о новой проблеме).
Как обновить JAR-файл в сценарии исправления?
Если необходимо применить исправление, воспользуйтесь следующим скриптом, который обновит spark-enhancement.jar*.
upgrade_spark_enhancement.sh:
#!/usr/bin/env bash
# Copyright (C) Microsoft Corporation. All rights reserved.
# Arguments:
# $1 Enhancement jar path
if [ "$#" -ne 1 ]; then
>&2 echo "Please provide the upgrade jar path."
exit 1
fi
install_jar() {
tmp_jar_path="/tmp/spark-enhancement-hotfix-$( date +%s )"
if wget -O "$tmp_jar_path" "$2"; then
for FILE in "$1"/spark-enhancement*.jar
do
back_up_path="$FILE.original.$( date +%s )"
echo "Back up $FILE to $back_up_path"
mv "$FILE" "$back_up_path"
echo "Copy the hotfix jar file from $tmp_jar_path to $FILE"
cp "$tmp_jar_path" "$FILE"
"Hotfix done."
break
done
else
>&2 echo "Download jar file failed."
exit 1
fi
}
jars_folder="/usr/hdp/current/spark2-client/jars"
jar_path=$1
if ls ${jars_folder}/spark-enhancement*.jar 1>/dev/null 2>&1; then
install_jar "$jars_folder" "$jar_path"
else
>&2 echo "There is no target jar on this node. Exit with no action."
exit 0
fi
Использование
upgrade_spark_enhancement.sh https://${jar_path}
Пример
upgrade_spark_enhancement.sh https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar
Использование bash-файла на портале Azure
Запустите портал Azure, а затем выберите кластер.
Запустите выполнение действий скрипта со следующими параметрами.
Свойство Значение Тип скрипта - Custom Имя. UpgradeJar URI bash-скрипта https://hdinsighttoolingstorage.blob.core.windows.net/shsscriptactions/upgrade_spark_enhancement.shТипы узлов Головной, рабочий Параметры https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar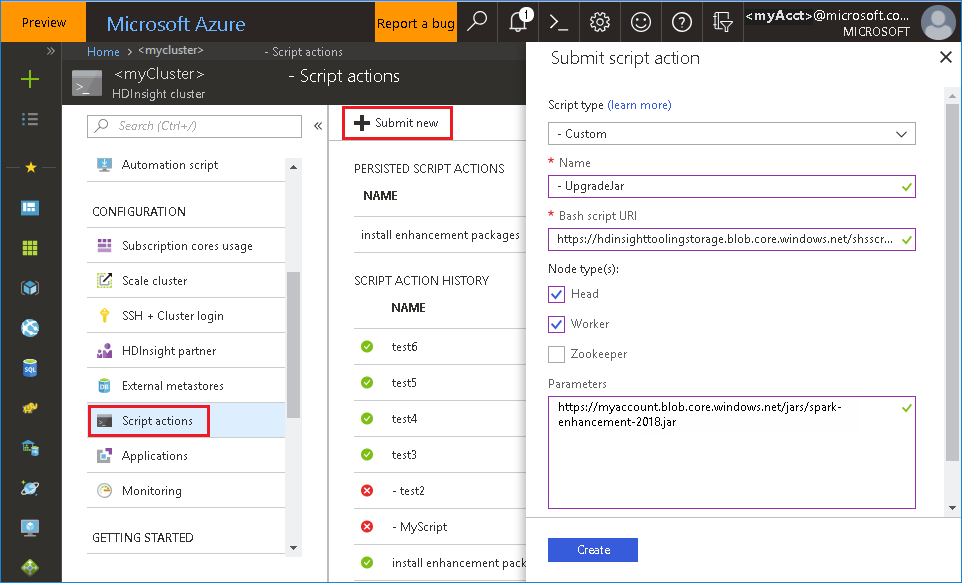
Известные проблемы
В настоящее время сервер журнала Spark работает только для Spark 2.3 и 2.4.
На вкладке Данные не будут отображаться входные и выходные данные, использующие RDD.
Следующие шаги
Предложения
Если у вас имеются какие-либо отзывы или возникли проблемы при использовании этого средства, отправьте сообщение электронной почты по адресу hdivstool@microsoft.com.