Управление ресурсами для кластера Apache Spark в Azure HDInsight
Узнайте, как получать доступ к разным интерфейсам, связанным с кластером Spark, включая пользовательский интерфейс Apache Ambari, пользовательский интерфейс Apache Hadoop YARN и сервер журнала Apache Spark, и как настроить конфигурацию кластера для оптимальной производительности.
Открытие сервера журнала Spark
Сервер журнала Spark — это пользовательский веб-интерфейс для готовых и запущенных приложений Spark. Он представляет собой расширение для пользовательского веб-интерфейса Spark. Полные сведения см. в статье о сервере журнала Spark.
Открытие пользовательского интерфейса YARN
Вы можете использовать пользовательский интерфейс YARN для мониторинга приложений, которые выполняются в кластере Spark в настоящее время.
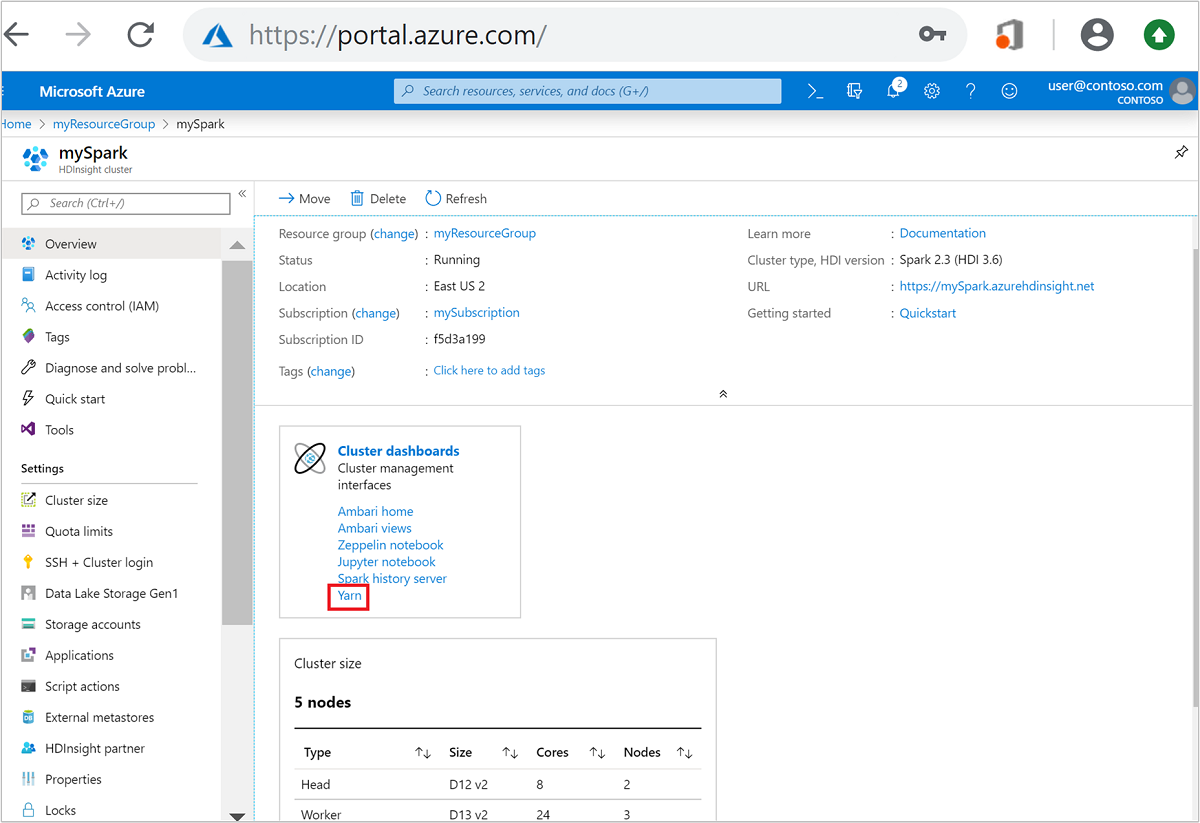
Откройте кластер Spark на портале Azure. Дополнительные сведения см. в разделе Отображение кластеров.
На панелях мониторинга кластеров выберите Yarn. При появлении запроса введите учетные данные администратора для кластера Spark.
Совет
Также пользовательский интерфейс YARN можно открыть из пользовательского интерфейса Ambari. В пользовательском интерфейсе Ambari перейдите к YARN>Быстрые ссылки>Активные>Пользовательский интерфейс Диспетчера ресурсов.
Оптимизация кластеров для приложений Spark
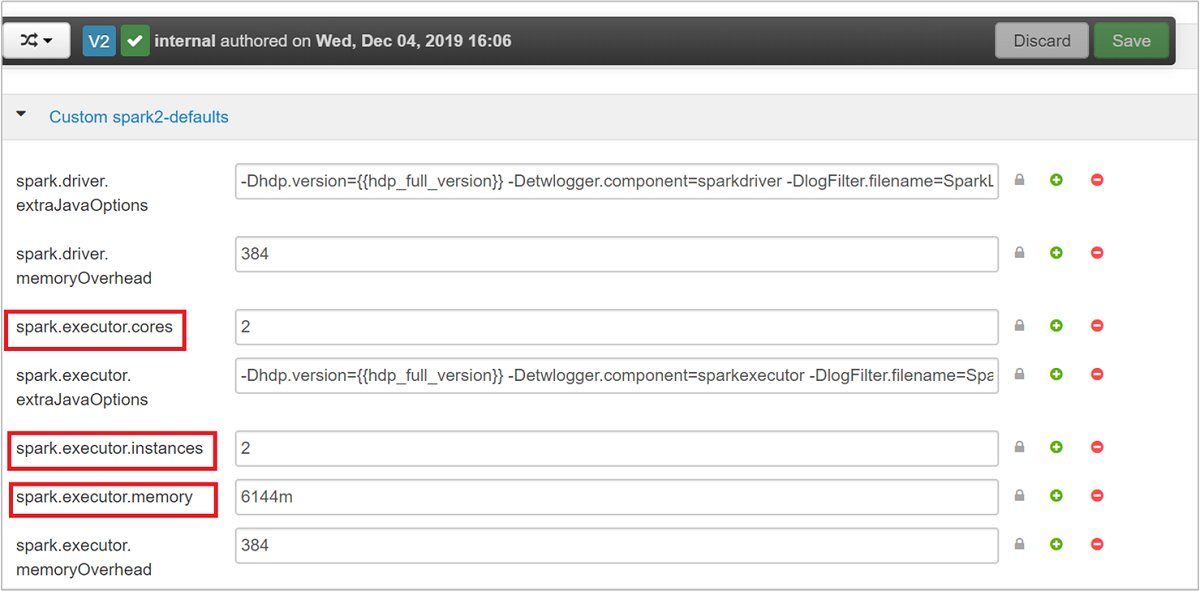
В зависимости от требований приложения можно изменять три основных параметра Spark: spark.executor.instances, spark.executor.cores и spark.executor.memory. Исполнитель — это процесс, запущенный для приложения Spark. Он выполняется на рабочем узле и отвечает за выполнение задач этого приложения. Число исполнителей по умолчанию и размеры исполнителя для каждого кластера определяются с учетом числа рабочих узлов и размера каждого рабочего узла. Эти сведения хранятся в файле spark-defaults.conf на головных узлах кластера.
Эти три параметра конфигурации можно настроить на уровне кластера (для всех приложений, работающих в кластере) или для каждого отдельного приложения.
Изменение параметров с помощью пользовательского интерфейса Ambari
В пользовательском интерфейсе Ambari перейдите к конфигурации>Spark 2>Custom spark2-defaults.
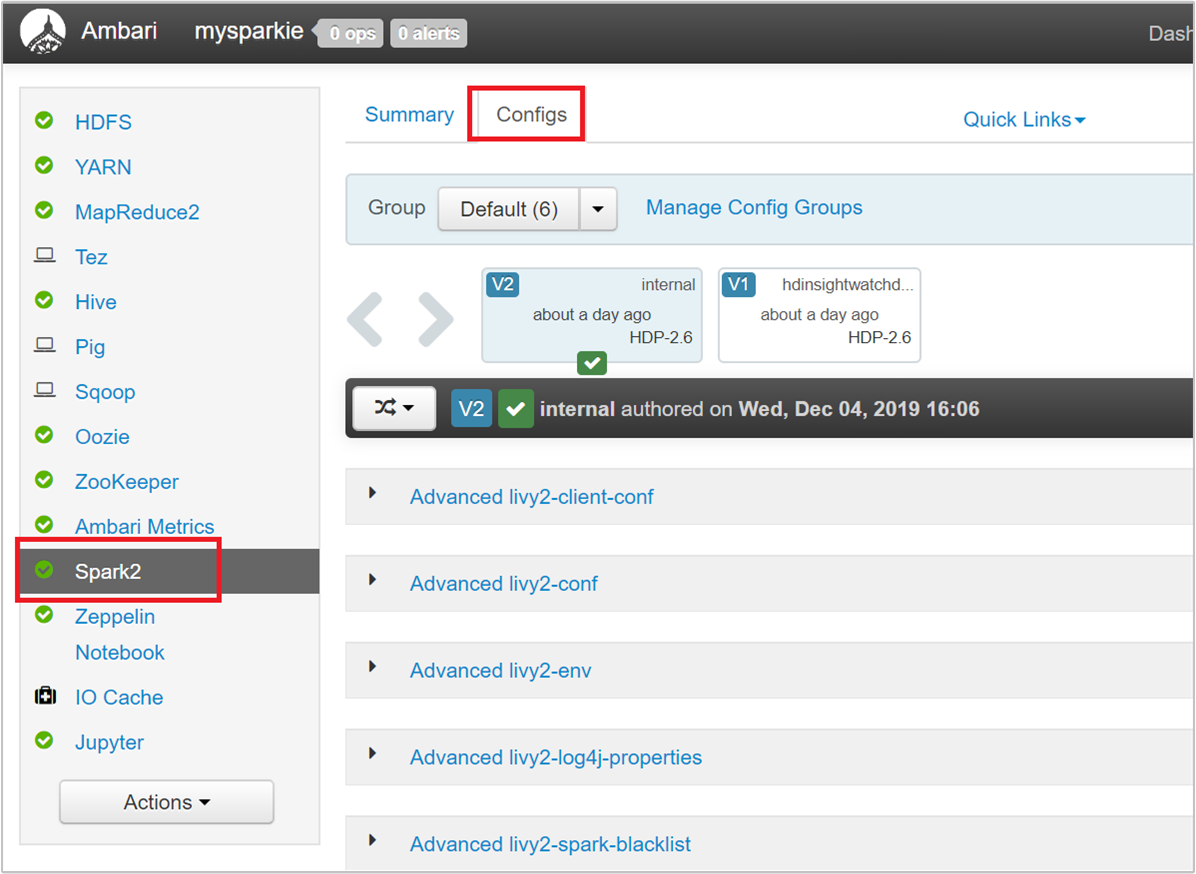
Значения по умолчанию позволяют запустить в кластере одновременно четыре приложения Spark. Вы можете изменять эти значения из пользовательского интерфейса, как показано на следующем снимке экрана:
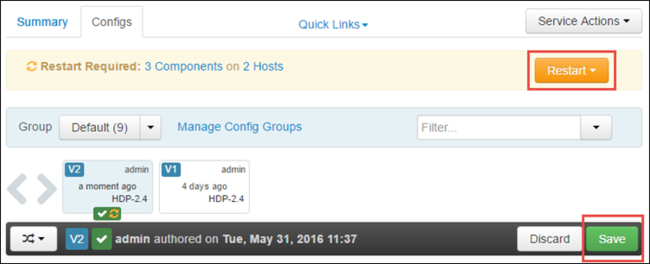
Чтобы сохранить изменения конфигурации, нажмите кнопку Сохранить. В верхней части страницы вы увидите предложение перезапустить все затронутые службы. Выберите Перезапустить.
Изменение параметров для приложения, запущенного в Jupyter Notebook
Чтобы изменить конфигурацию для приложений, запущенных в Jupyter Notebook, можно использовать магическую команду %%configure. Желательно вносить такие изменения в начале приложения, перед запуском первой ячейки кода. Это гарантирует, что конфигурация будет применена к сеансу Livy, когда он будет создан. Если вы хотите изменить конфигурацию на более позднем этапе выполнения приложения, следует использовать параметр -f . Но при этом будут потеряны все результаты, полученные в приложении.
В следующем фрагменте кода показано, как изменить конфигурацию для приложения, работающего в Jupyter.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Параметры конфигурации следует передавать в виде строки JSON, расположенной сразу после команды magic, как показано в столбце примера.
Изменение параметров для приложения, отправленного с помощью spark-submit
Следующая команда демонстрирует, как можно изменять параметры конфигурации для приложения пакетной службы, отправленного с помощью spark-submit.
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
Изменение параметров для приложения, отправленного с помощью cURL
В следующей команде показано, как изменить параметры конфигурации для приложения пакетной службы, отправленного с помощью cURL.
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
Примечание.
Скопируйте JAR-файл в учетную запись хранения кластера. Не копируйте JAR-файл непосредственно на головной узел.
Изменение этих параметров на сервере Thrift Spark
Сервер Thrift Spark предоставляет доступ JDBC и ODBC к кластеру Spark. Разные средства, такие как Power BI, Tableau и др., используют протокол ODBC для обмена данными с сервером Thrift Spark и выполнения запросов Spark SQL в виде приложения Spark. Когда вы создаете кластер Spark, запускаются два экземпляра сервера Thrift Spark, по одному на каждый головной узел. Каждый сервер Thrift Spark отображается в пользовательском интерфейсе YARN как приложение Spark.
Сервер Thrift Spark использует динамическое выделение исполнителей Spark, поэтому spark.executor.instances не используется. Вместо этого сервер Thrift Spark использует spark.dynamicAllocation.maxExecutors и spark.dynamicAllocation.minExecutors, чтобы указать число исполнителей. Параметры конфигурации spark.executor.cores и spark.executor.memory используются для изменения размера исполнителя. Эти параметры можно изменить, как описано ниже.
Разверните категорию Advanced spark2-thrift-sparkconf, чтобы обновить параметры
spark.dynamicAllocation.maxExecutorsиspark.dynamicAllocation.minExecutors.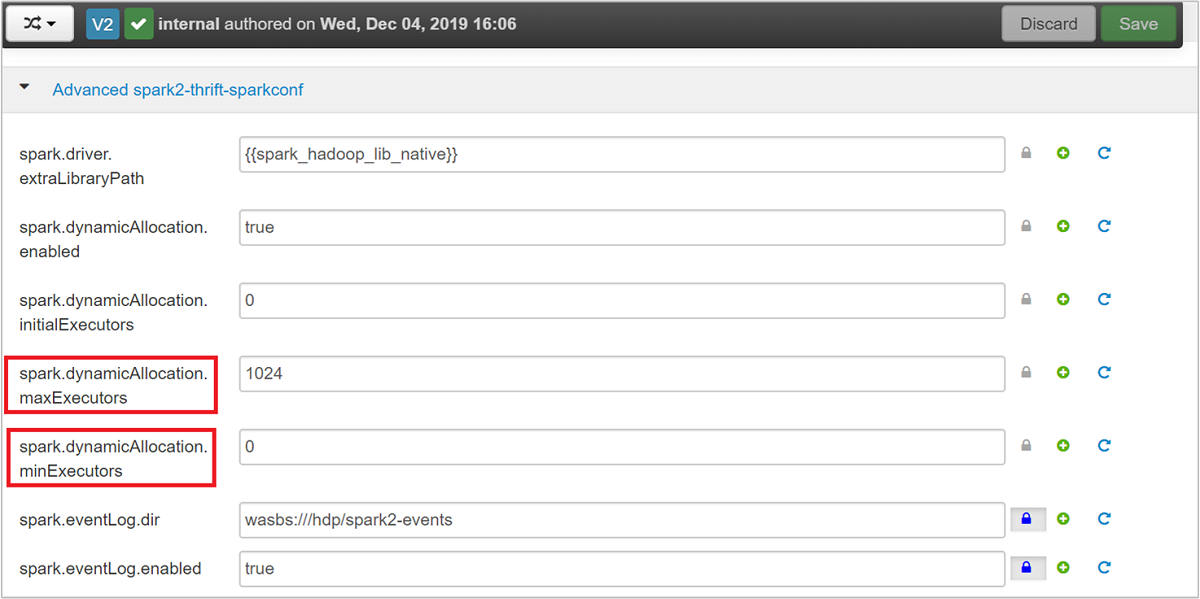
Разверните категорию Custom spark2-thrift-sparkconf, чтобы обновить параметры
spark.executor.coresиspark.executor.memory.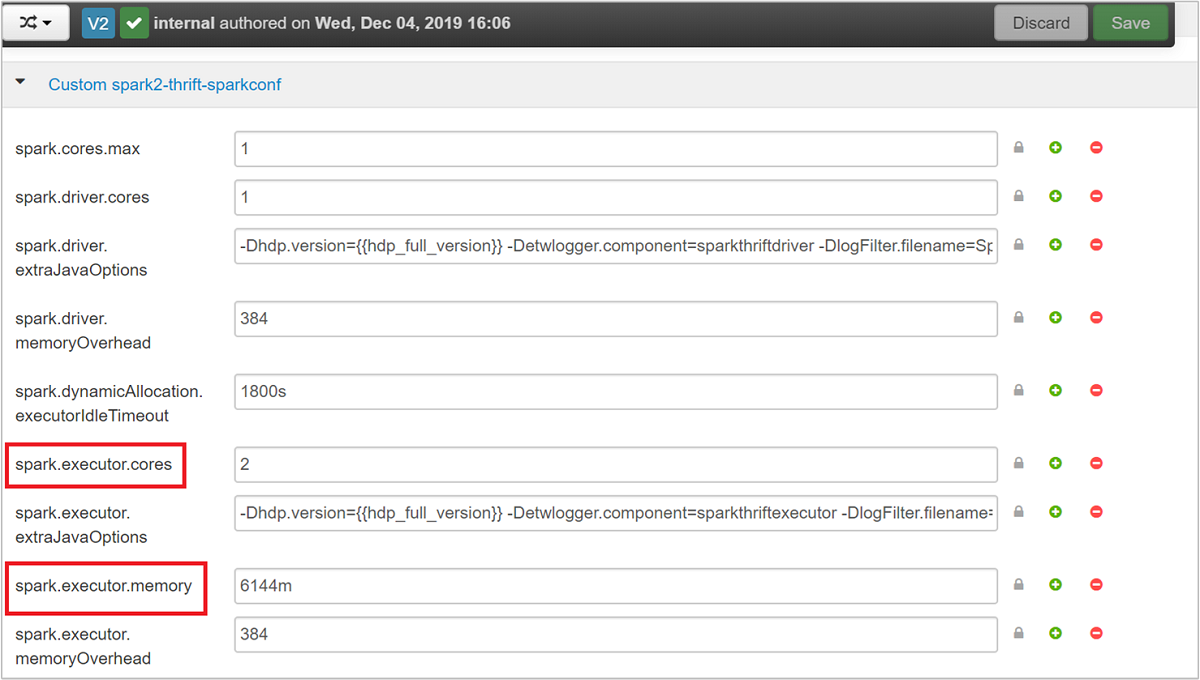
Изменение памяти драйверов для сервера Thrift Spark
Память драйверов сервера Thrift Spark настроена так, что она использует 25 % от размера ОЗУ головного узла, при условии, что общий объем ОЗУ головного узла превышает 14 ГБ. Конфигурацию памяти драйверов можно изменить с помощью пользовательского интерфейса Ambari, как показано на снимке экрана ниже.
В пользовательском интерфейсе Ambari перейдите к Spark2>Конфигурации>Advanced spark2-env. Затем укажите значение для spark_thrift_cmd_opts.
Освобождение кластерных ресурсов Spark
Так как используется динамическое выделение Spark, сервер Thrift потребляет только ресурсы, предназначенные для двух главных серверов приложений. Чтобы освободить эти ресурсы, следует остановить службы сервера Thrift, запущенные в кластере.
В пользовательском интерфейсе Ambari на панели слева щелкните Spark2.
На следующей странице выберите Spark 2 Thrift Servers.
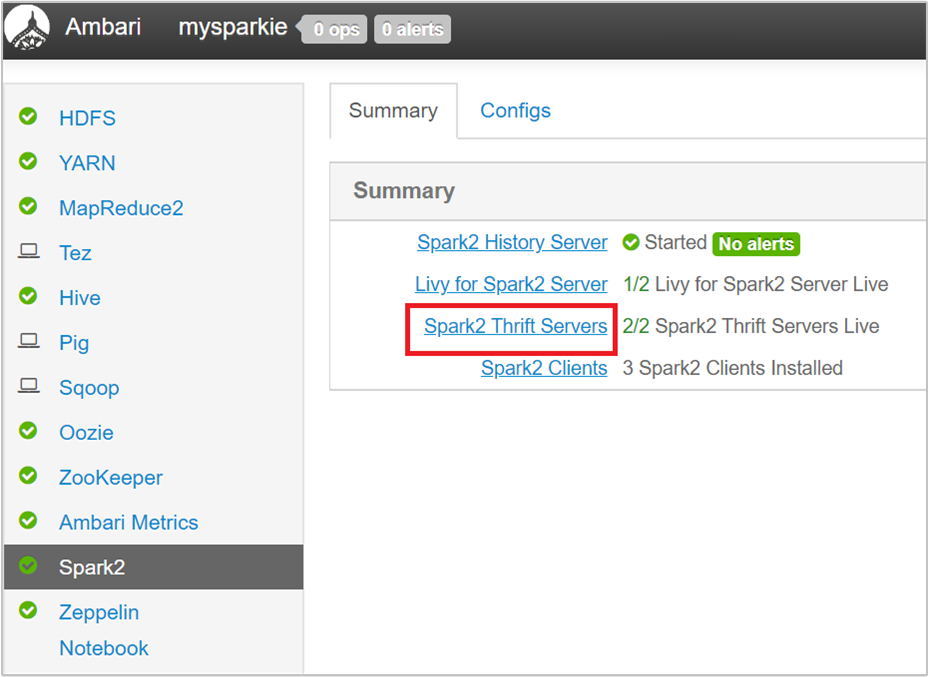
Вы увидите два головных заголовка, на которых запущен сервер Spark 2 Thrift. Выберите один из этих головных узлов.
На следующей странице перечислены все службы, запущенные на выбранном головном узле. В списке нажмите кнопку раскрывающегося списка рядом с сервером Spark 2 Thrift Server, а затем нажмите кнопку "Остановить".
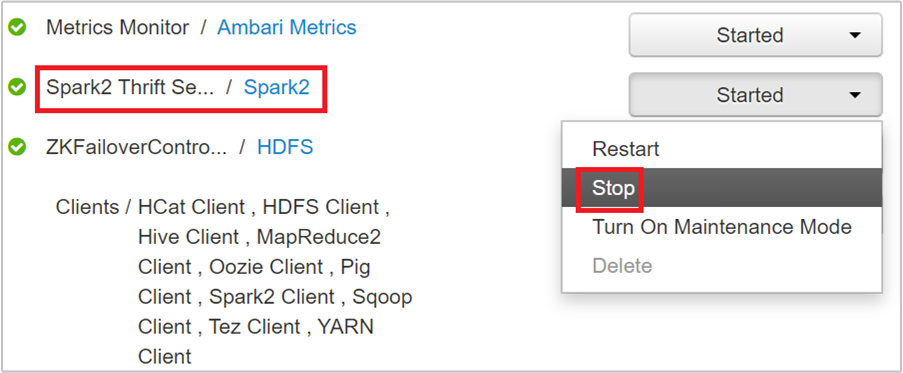
Повторите эти действия на другом головном узле.
Перезапуск службы Jupyter
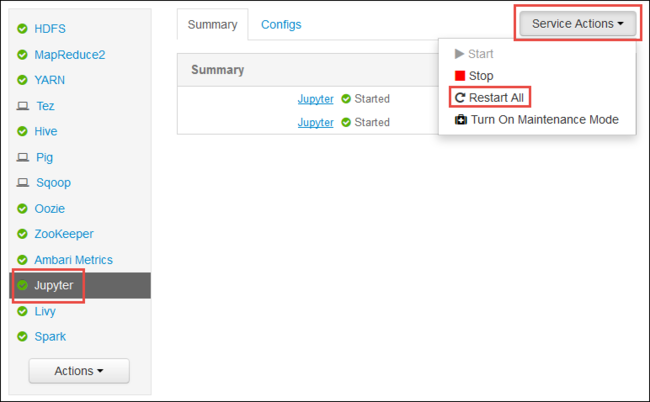
Откройте пользовательский веб-интерфейс Ambari, как показано в начале статьи. В левой области навигации щелкните Jupyter, Действия службы, а затем — Перезапустить все. Служба Jupyter запустится на всех головных узлах.
Мониторинг ресурсов
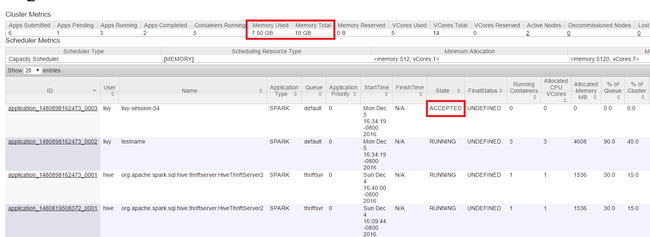
Откройте пользовательский интерфейс Yarn, как показано в начале статьи. В таблице метрик кластера в верхней части экрана проверьте значения столбцов Memory Used (Используемая память) и Memory Total (Всего памяти). Если эти два значения близки, то для запуска следующего приложения может не хватить ресурсов. То же самое относится к столбцам VCores Used (Используемые ядра VCore) и VCores Total (Всего ядер VCore). Кроме того, если в главном представлении есть приложение с состоянием ACCEPTED (Принято), которое не переходит в состояние RUNNING (Выполняется) или FAILED (Сбой), то это также может означать, что для его запуска недостаточно ресурсов.
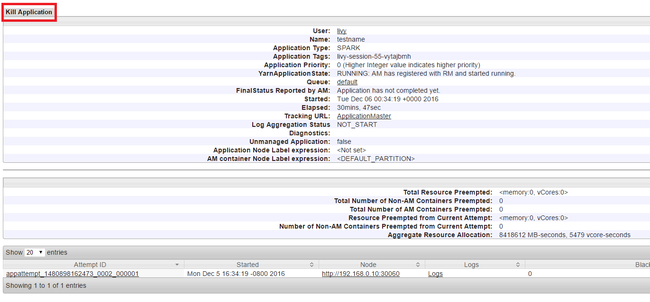
Завершение работы запущенных приложений
В пользовательском интерфейсе Yarn на левой панели щелкните Выполняется. В списке выполняющихся приложений определите приложение, работу которого необходимо завершить, и щелкните ID (Идентификатор).
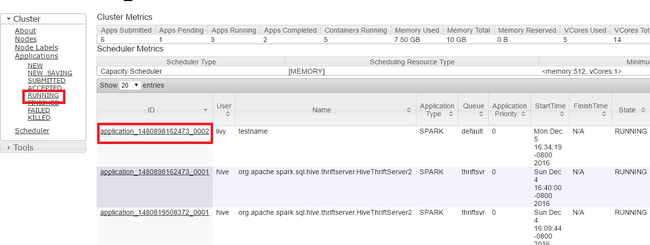
В правом верхнем углу щелкните Завершить работу приложения, а затем нажмите кнопку ОК.
См. также
Для специалистов по анализу данных
- Apache Spark и Машинное обучение. Анализ температуры в здании на основе данных системы кондиционирования с помощью Spark в HDInsight
- Apache Spark и Машинное обучение. Прогнозирование результатов проверки пищевых продуктов с помощью Spark в HDInsight
- Анализ журналов веб-сайтов с помощью Apache Spark в HDInsight
- Анализ журналов телеметрии Application Insights с помощью Apache Spark в HDInsight
Для разработчиков Apache Spark
- Создание автономного приложения с использованием Scala
- Удаленный запуск заданий с помощью Apache Livy в кластере Apache Spark
- Использование подключаемого модуля средств HDInsight для IntelliJ IDEA для создания и отправки приложений Spark Scala
- Удаленная отладка приложений Apache Spark с помощью подключаемого модуля средств HDInsight для IntelliJ IDEA
- Использование записных книжек Zeppelin с кластером Apache Spark в Azure HDInsight
- Ядра, доступные для Jupyter Notebook в кластерах Apache Spark в HDInsight
- Использование внешних пакетов с Jupyter Notebook
- Установка записной книжки Jupyter на компьютере и ее подключение к кластеру Apache Spark в Azure HDInsight (предварительная версия)