Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье вы узнаете, как установить Jupyter Notebook с пользовательскими ядрами PySpark (для Python) и Apache Spark (для Scala) с помощью магии Spark. Затем вы подключаете записную книжку к кластеру HDInsight.
Существует четыре ключевых шага, связанных с установкой Jupyter и подключением к Apache Spark в HDInsight.
- Настройка кластера Spark.
- Установите Jupyter Notebook.
- Установите ядра PySpark и Spark с использованием функции Spark magic.
- Настройте магию Spark для доступа к кластеру Spark в HDInsight.
Дополнительные сведения о пользовательских ядрах и магии Spark см. в разделе "Ядра", доступные для jupyter Notebook с кластерами Apache Spark Linux в HDInsight.
Предпосылки
Кластер Apache Spark в HDInsight. Для получения инструкций см. Создание кластеров Apache Spark в Azure HDInsight. Локальная записная книжка подключается к кластеру HDInsight.
Опыт работы с записными книжками Jupyter и Spark в HDInsight.
Установка Jupyter Notebook на компьютере
Установите Python перед установкой Jupyter Notebook. Дистрибутив Anaconda установит как Python, так и Jupyter Notebook.
Скачайте установщик Anaconda для своей платформы и запустите программу установки. При запуске мастера установки убедитесь, что выбран параметр для добавления Anaconda в переменную PATH. См. также, установка Jupyter с помощью Anaconda.
Установка магии Spark
Введите команду
pip install sparkmagic==0.13.1для установки модуля Spark magic для кластеров HDInsight версии 3.6 и 4.0. См. также документацию sparkmagic.Убедитесь, что
ipywidgetsустановлено правильно, выполнив следующую команду:jupyter nbextension enable --py --sys-prefix widgetsnbextension
Установка ядер PySpark и Spark
Определите, где
sparkmagicустановлено, введя следующую команду:pip show sparkmagicЗатем измените рабочий каталог на расположение , указанное в приведенной выше команде.
В новом рабочем каталоге введите одну или несколько команд ниже, чтобы установить нужные ядра:
Ядро Приказ Спарк jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelНеобязательно. Введите следующую команду, чтобы включить расширение сервера:
jupyter serverextension enable --py sparkmagic
Настройка Spark magic для подключения к кластеру HDInsight Spark
В этом разделе настраивается Spark magic, который вы установили ранее, для подключения к кластеру Apache Spark.
Запустите оболочку Python с помощью следующей команды:
pythonСведения о конфигурации Jupyter обычно хранятся в домашнем каталоге пользователей. Введите следующую команду, чтобы определить домашний каталог и создать папку с именем Sparkmagic. Будет выведен полный путь.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()В папке
.sparkmagicсоздайте файл с именем config.json и добавьте в него следующий фрагмент JSON.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }Внесите следующие изменения в файл:
Значение шаблона Новое значение {USERNAME} Имя входа в кластер, по умолчанию — admin.{CLUSTERDNSNAME} Имя кластера {BASE64ENCODEDPASSWORD} Пароль, закодированный в Base64, для вашего основного пароля. Вы можете создать пароль base64 по адресу https://www.url-encode-decode.com/base64-encode-decode/. "livy_server_heartbeat_timeout_seconds": 60Оставьте, если используете sparkmagic 0.12.7(кластеры версии 3.5 и 3.6). При использованииsparkmagic 0.2.3(кластеры версии 3.4) замените на"should_heartbeat": true.Полный пример файла можно просмотреть в примере config.json.
Подсказка
Сигналы отправляются, чтобы предотвратить утечки сеансов. Когда компьютер переходит в спящий режим или выключается, пульс не отправляется, в результате чего сеанс очищается. Для кластеров версии 3.4, если вы хотите отключить это поведение, можно задать конфигурацию
livy.server.interactive.heartbeat.timeout0Livy в пользовательском интерфейсе Ambari. Для кластеров версии 3.5, если конфигурация 3.5 выше не задана, сеанс не будет удален.Запустите Jupyter. Используйте следующую команду из командной строки.
jupyter notebookУбедитесь, что вы можете использовать магию Spark, доступную с ядрами. Выполните следующие действия.
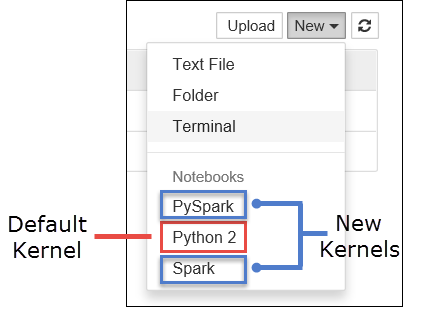
a. Создайте записную книжку. В правом углу нажмите кнопку "Создать". Вы должны увидеть ядро Python 2 или Python 3 по умолчанию и установленные ядра. Фактические значения могут отличаться в зависимости от вариантов установки. Выберите PySpark.
Это важно
После выбора Новый проверьте оболочку на наличие ошибок. Если вы видите ошибку
TypeError: __init__() got an unexpected keyword argument 'io_loop', возможно, вы сталкиваетесь с известной проблемой в определённых версиях Tornado. Если это так, остановите ядро, а затем понизьте версию Tornado с помощью следующей команды:pip install tornado==4.5.3.б. Выполните следующий фрагмент кода.
%%sql SELECT * FROM hivesampletable LIMIT 5Если вы можете успешно получить выходные данные, проверяется подключение к кластеру HDInsight.
Если вы хотите обновить конфигурацию записной книжки для подключения к другому кластеру, обновите config.json с новым набором значений, как показано на шаге 3 выше.
Зачем устанавливать Jupyter на моем компьютере?
Причины установки Jupyter на компьютере и последующего подключения к кластеру Apache Spark в HDInsight:
- Предоставляет возможность локального создания записных книжек, тестирования приложения в работающем кластере и отправки записных книжек в кластер. Чтобы загрузить записные книжки в кластер, можно либо загрузить их, используя запущенную записную книжку Jupyter, либо сам кластер, или сохранить их в папке
/HdiNotebooksв учетной записи хранения, связанной с кластером. Дополнительные сведения о том, как записные книжки хранятся в кластере, см. в разделе "Где хранятся записные книжки Jupyter? - С помощью записных книжек, доступных локально, вы можете подключиться к разным кластерам Spark на основе требований приложения.
- Вы можете использовать GitHub для внедрения системы управления исходным кодом и контроля версий для ноутбуков. Вы также можете использовать среду совместной работы, в которой несколько пользователей могут работать с одной записной книжкой.
- Вы можете работать с записными книжками локально, даже не имея кластера. Кластер нужен только для тестирования ваших записных книжек, а не для их ручного управления или управления средой разработки.
- Возможно, проще настроить собственную локальную среду разработки, чем настроить установку Jupyter в кластере. Вы можете использовать все программное обеспечение, установленное локально, без настройки одного или нескольких удаленных кластеров.
Предупреждение
С помощью Jupyter, установленного на локальном компьютере, несколько пользователей могут одновременно запускать одну и ту же записную книжку в одном кластере Spark. В такой ситуации создаются несколько сеансов Livy. Если возникла проблема и хотите отладить это, это будет сложная задача для отслеживания того, какой сеанс Livy принадлежит пользователю.