Применение внешних пакетов с Jupyter Notebook в кластерах Apache Spark в HDInsight
Узнайте, как настроить для Jupyter Notebook в кластере Apache Spark в HDInsight использование предоставленных сообществом внешних пакетов Apache Maven, которые не включены в базовую версию кластера.
Полный список доступных пакетов можно найти в репозитории Maven . Его также можно получить из других источников. Например, полный список предоставленных сообществом пакетов можно найти в разделе Пакеты Spark.
В этой статье описано, как использовать пакет spark-csv с Jupyter Notebook.
Необходимые компоненты
Кластер Apache Spark в HDInsight. Инструкции см. в статье Начало работы. Создание кластера Apache Spark в HDInsight на платформе Linux и выполнение интерактивных запросов с помощью SQL Spark.
Опыт работы с записными книжками Jupyter и Spark в HDInsight. Дополнительные сведения см. в статье Руководство. Загрузка данных и выполнение запросов в кластере Apache Spark в Azure HDInsight.
Схема универсального кода ресурса (URI) для основного хранилища кластеров. Это было бы
wasb://для служба хранилища Azure,abfs://для Azure Data Lake Storage 2-го поколения. Если для службы хранилища Azure или Azure Data Lake Storage 2-го поколения включена безопасная передача, URI будетwasbs://илиabfss://соответственно (см. также сведения о безопасной передаче).
Использование внешних пакетов с Jupyter Notebook
Перейдите на страницу
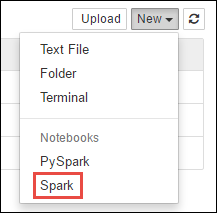
https://CLUSTERNAME.azurehdinsight.net/jupyter, гдеCLUSTERNAME— имя кластера Spark.Создайте новую записную книжку. Щелкните New (Создать), затем выберите Spark.
Будет создана и открыта записная книжка с именем Untitled.pynb. Выберите имя записной книжки в верхней части страницы и введите понятное имя.
Используйте волшебную команду
%%configure, чтобы настроить для записной книжки использование внешнего пакета. В записных книжках, которые используют внешние пакеты, следует вызывать волшебную команду%%configureв первой ячейке кода. Она настраивает ядро для использования пакета до начала сеанса.Внимание
Если вы забыли настроить ядро в первой ячейке, можно использовать
%%configureс параметром-f, но при этом сеанс будет перезапущен и все изменения будут утеряны.Версия HDInsight Команда Для HDInsight 3.5 и HDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}Для HDInsight 3.3 и HDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }Приведенный выше фрагмент ожидает получить координаты Maven для внешнего пакета в центральном репозитории Maven. В этом фрагменте кода
com.databricks:spark-csv_2.11:1.5.0— координата пакета spark-csv в Maven. Вот как сформировать координаты для пакета.a. Найдите пакет в репозитории Maven. В этой статье мы используем spark-csv.
b. В репозитории найдите значения для параметров GroupId, ArtifactId и Version. Убедитесь, что полученные значения соответствуют кластеру. В нашем примере мы используем Scala 2.11 и пакет Spark 1.5.0, но вам могут понадобиться другие версии для соответствующих версий Scala и Spark в вашем кластере. Выяснить версию Scala в кластере можно, выполнив
scala.util.Properties.versionStringдля ядра Jupyter Spark или при отправке Spark. Версию Spark в кластере можно узнать, выполнивsc.versionдля Jupyter Notebook.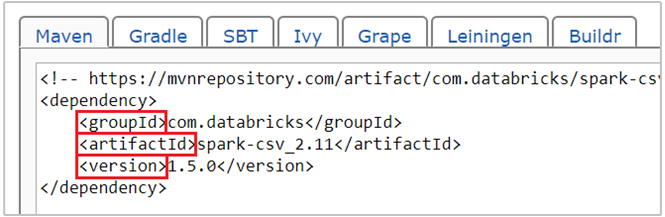
c. Объедините три значения, разделив их двоеточием (:).
com.databricks:spark-csv_2.11:1.5.0Запустите ячейку кода с помощью волшебной команды
%%configure. После выполнения этой команды соответствующий сеанс Livy будет использовать указанный вами пакет. В последующих ячейках записной книжки теперь можно использовать этот пакет, как показано ниже.val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Для HDInsight 3.4 и более старых версий следует использовать фрагмент кода ниже.
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Затем можно запустить фрагменты кода, как показано ниже, чтобы просмотреть данные из таблицы данных, созданной на предыдущем шаге.
df.show() df.select("Time").count()
См. также
Сценарии
- Использование Apache Spark со средствами бизнес-аналитики. Выполнение интерактивного анализа данных с использованием Spark в HDInsight с помощью средств бизнес-аналитики
- Apache Spark и Машинное обучение. Анализ температуры в здании на основе данных системы кондиционирования с помощью Spark в HDInsight
- Apache Spark и Машинное обучение. Прогнозирование результатов проверки пищевых продуктов с помощью Spark в HDInsight
- Анализ журналов веб-сайтов с помощью Apache Spark в HDInsight
Создание и запуск приложений
- Создание автономного приложения с использованием Scala
- Удаленный запуск заданий с помощью Apache Livy в кластере Apache Spark
Инструменты и расширения
- Использование внешних пакетов Python с Jupyter Notebook в кластерах Apache Spark в HDInsight в Linux
- Использование подключаемого модуля средств HDInsight для IntelliJ IDEA для создания и отправки приложений Spark Scala
- Удаленная отладка приложений Apache Spark с помощью подключаемого модуля средств HDInsight для IntelliJ IDEA
- Использование записных книжек Zeppelin с кластером Apache Spark в Azure HDInsight
- Ядра, доступные для Jupyter Notebook в кластерах Apache Spark в HDInsight
- Установка записной книжки Jupyter на компьютере и ее подключение к кластеру Apache Spark в Azure HDInsight (предварительная версия)