Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом кратком руководстве вы используете портал Azure для создания кластера Apache Spark в Azure HDInsight. Затем мы создадим записную книжку Jupyter Notebook и с ее помощью выполним SQL-запрос Spark к таблицам Apache Hive. Azure HDInsight — это управляемая комплексная служба аналитики с открытым кодом, предназначенная для предприятий. Платформа Apache Spark для HDInsight обеспечивает быструю аналитику данных и кластерные вычисления, используя обработку в памяти. Jupyter Notebook позволяет работать с данными, объединять код с текстом Markdown и выполнять простые визуализации.
Подробные объяснения доступных конфигураций см. в статье об установке кластеров в HDInsight. Дополнительные сведения об использовании портала для создания кластеров см. в статье о создании кластеров на портале.
Если вы используете несколько кластеров вместе, может потребоваться создать виртуальную сеть; Если вы используете кластер Spark, может также потребоваться использовать соединитель хранилища Hive. См. сведения о планировании виртуальной сети для Azure HDInsight и интеграции Apache Spark и Apache Hive с Hive Warehouse Connector.
Это важно
Выставление счетов за кластеры HDInsight осуществляется по пропорциональной поминутной тарификации, независимо от того, используете ли вы их или нет. Обязательно удалите кластер, когда завершите его использование. Дополнительные сведения см. в разделе Очистка ресурсов этой статьи.
Предпосылки
Учетная запись Azure с активной подпиской. Создайте учетную запись бесплатно .
Создание кластера Apache Spark в HDInsight
Портал Azure используется для создания кластера HDInsight, который использует облака Azure Storage в качестве хранилища кластера. Дополнительные сведения об использовании Data Lake Storage Gen2 см. в статье Краткое руководство по установке кластеров в HDInsight.
Войдите на портал Azure.
В меню сверху выберите + Create a resource (+ Создать ресурс).
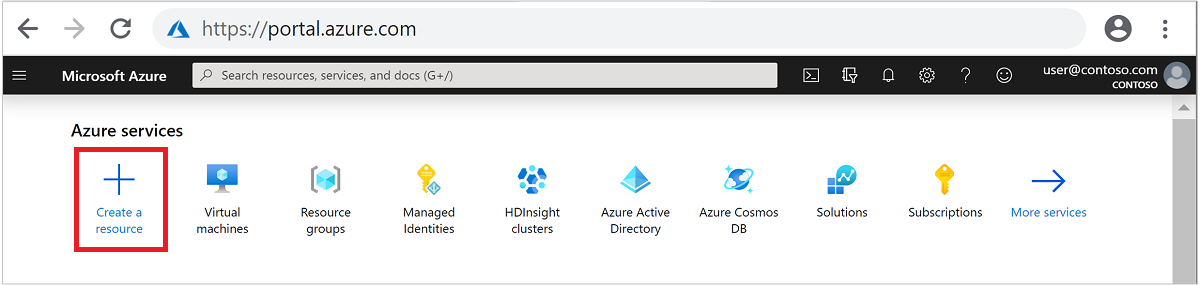
Выберите Analytics>Azure HDInsight, чтобы перейти на страницу Создание кластера HDInsight.
На вкладке Основные сведения укажите следующую информацию:
Недвижимость Описание Подписка В раскрывающемся списке выберите подписку Azure, которая используется для кластера. Группа ресурсов В раскрывающемся списке выберите существующую группу ресурсов, а затем Создать новую. Имя кластера Введите глобально уникальное имя. Регион В раскрывающемся списке выберите регион, в котором создается кластер. Зона доступности Необязательно. Укажите зону доступности, в которой необходимо развернуть кластер. Тип кластера Выберите тип кластера, чтобы открыть список. В списке выберите Spark. Версия кластера Это поле будет автоматически заполнено версией по умолчанию после выбора типа кластера. Имя пользователя для входа в кластер Введите имя пользователя для входа в кластер. Имя по умолчанию — admin. Эта учетная запись используется для входа в Jupyter Notebook позже, в ходе экспресс-настройки. Пароль для входа в кластер Введите пароль для входа в кластер. Имя пользователя для Secure Shell (SSH) Введите имя пользователя SSH. Имя пользователя SSH, используемое для этого быстрого запуска, — sshuser. По умолчанию эта учетная запись использует тот же пароль, что и учетная запись входа в кластер. 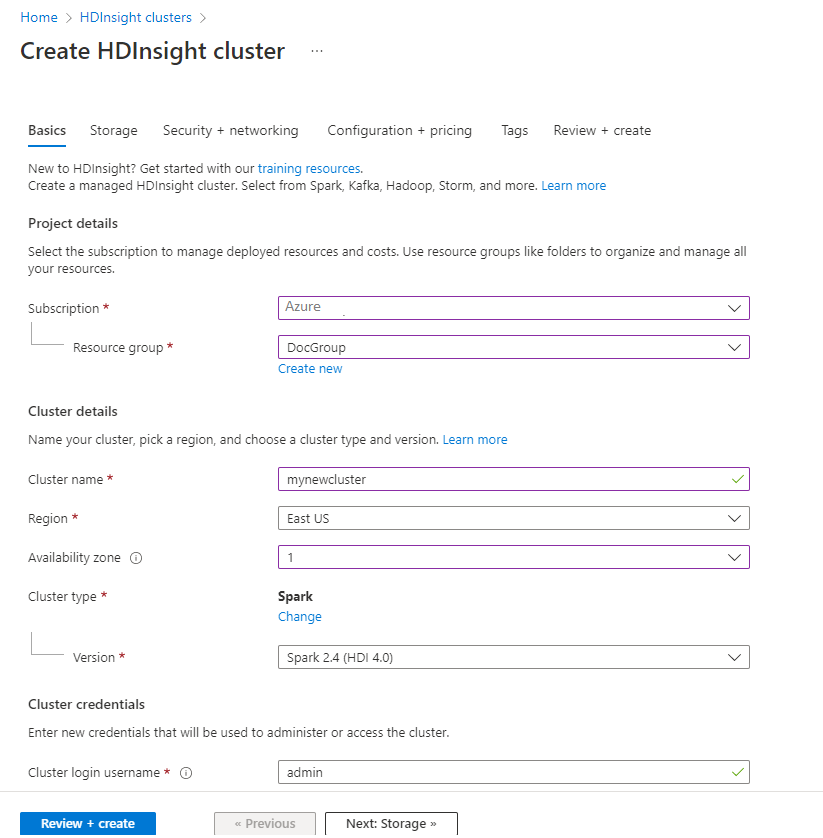
Нажмите кнопку "Далее" — хранилище >> , чтобы перейти на страницу хранилища .
В разделе "Хранилище" укажите следующие значения:
Недвижимость Описание Тип первичного хранилища Используйте значение Azure Storage по умолчанию. Метод выбора Используйте значение Выбрать в списке по умолчанию. Основную учетную запись хранения Используйте значение, предоставленное автоматически. Контейнер Используйте значение, предоставленное автоматически. 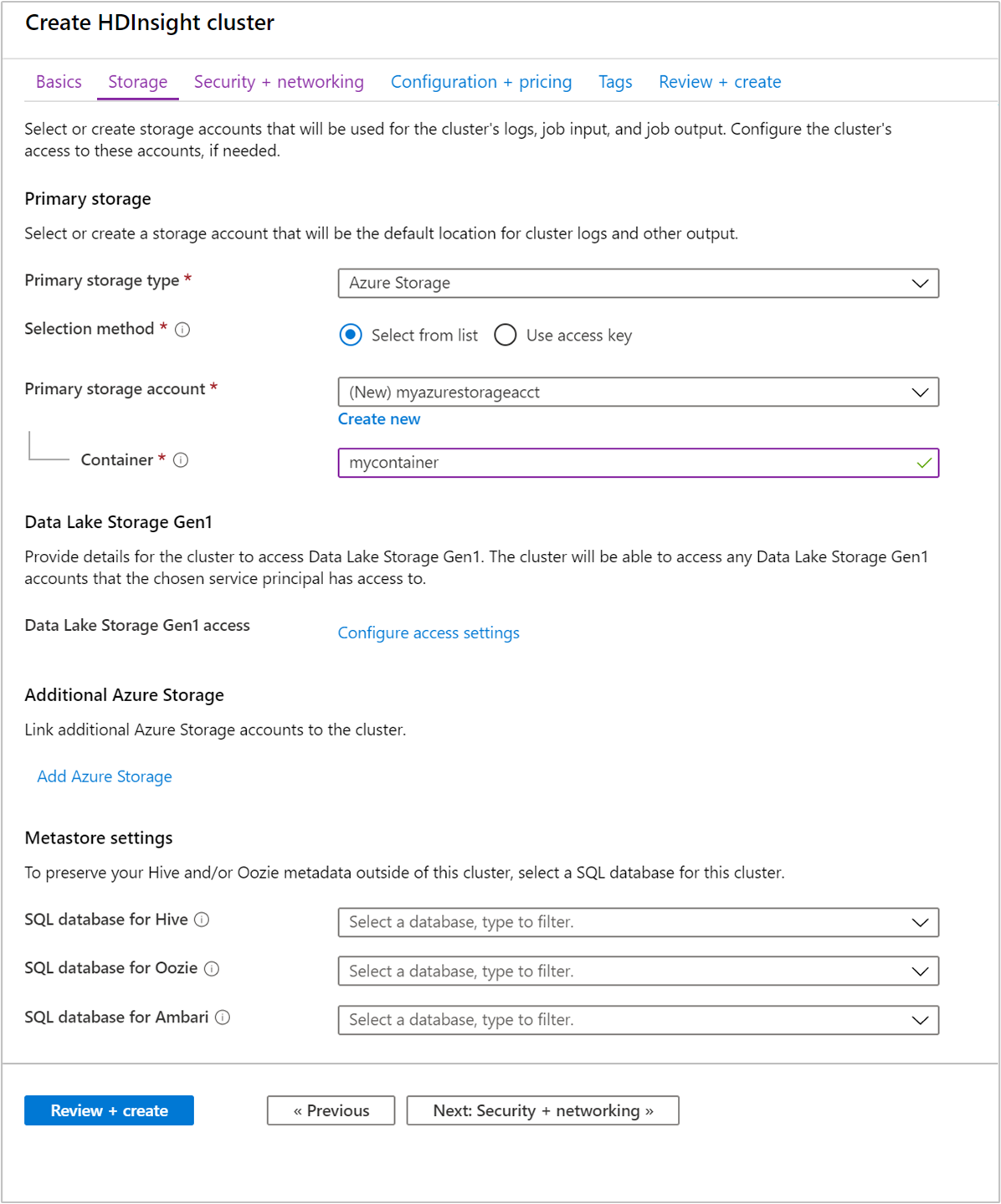
Нажмите кнопку "Проверить и создать ", чтобы продолжить.
В разделе "Проверка и создание" нажмите кнопку "Создать". Процесс создания кластеров занимает около 20 минут. Прежде чем перейти к следующему сеансу, вы должны создать кластер.
Если при создании кластера HDInsight возникают проблемы, возможно, у вас нет необходимых разрешений. Дополнительные сведения см. в разделе Требования к контролю доступа.
Создание записной книжки Jupyter
Jupyter Notebook — это интерактивная среда записной книжки, поддерживающая различные языки программирования. Notebook позволяет работать с данными, объединять код с текстом Markdown и выполнять простые визуализации.
В веб-браузере перейдите на страницу
https://CLUSTERNAME.azurehdinsight.net/jupyter, гдеCLUSTERNAME— это имя вашего кластера. При появлении запроса введите учетные данные для входа в кластер.Выберите New>PySpark, чтобы создать блокнот.
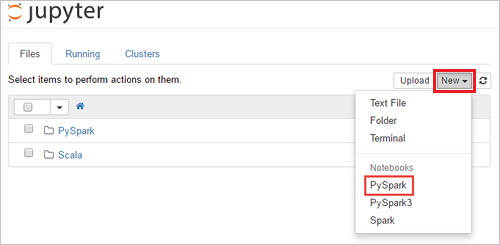
Будет создана и открыта записная книжка с именем Untitled (Untitled.pynb).
Выполнение инструкций SQL в Apache Spark
SQL — это наиболее распространенный и широко используемый язык для создания запросов и определения данных. Spark SQL работает как расширение Apache Spark для обработки структурированных данных с использованием знакомого синтаксиса SQL.
Убедитесь, что ядро готово. Ядро будет готово, когда в записной книжке появится пустой круг рядом с именем ядра. Сплошной круг означает, что ядро занято.

При первом запуске записной книжки некоторые задачи ядро выполняет в фоновом режиме. Дождитесь готовности ядра.
Вставьте указанный ниже код в пустую ячейку и нажмите сочетание клавиш SHIFT + ВВОД, чтобы выполнить код. Эта команда выводит список таблиц Hive в кластере:
%%sql SHOW TABLESПри использовании Jupyter Notebook с кластером HDInsight вы получите предустановленный набор
sqlContext, который можно использовать для выполнения запросов Hive с помощью Spark SQL.%%sqlСообщает Jupyter Notebook использовать предустановкуsqlContextдля выполнения запроса Hive. Запрос извлекает первые 10 строк из таблицы Hive (hivesampletable), которая по умолчанию входит в состав всех кластеров HDInsight. Для получения результатов может понадобиться около 30 секунд. Выходные данные выглядят следующим образом: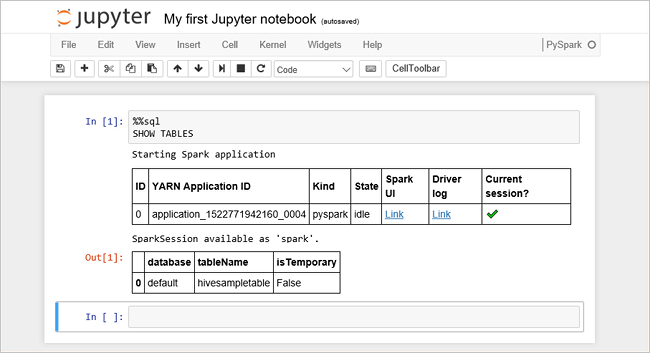 is quickstart." border="true":::
is quickstart." border="true":::При каждом выполнении запроса в Jupyter в заголовке окна веб-браузера будет отображаться состояние (Занято), а также название записной книжки. Кроме того, рядом с надписью PySpark в верхнем правом углу будет показан сплошной кружок.
Выполните другой запрос, чтобы вывести данные из таблицы
hivesampletable.%%sql SELECT * FROM hivesampletable LIMIT 10Экран обновится, и отобразятся выходные данные запроса.
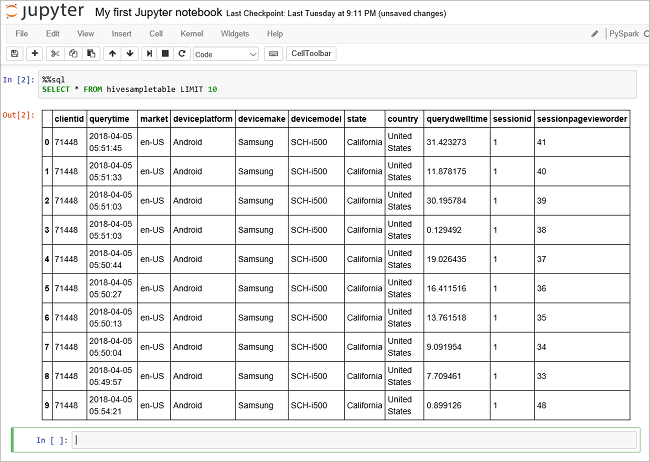 Insights" border="true":::
Insights" border="true":::В меню Файл на ноутбуке выберите Закрыть и остановить. Выключение приложения ноутбука освобождает ресурсы кластера.
Очистка ресурсов
HDInsight сохраняет ваши данные в службе хранилища Azure или Azure Data Lake Storage, что позволяет безопасно удалить неиспользуемый кластер. Плата за кластеры HDInsight взимается, даже когда они не используются. Так как затраты на кластер во много раз превышают затраты на хранилище, экономически целесообразно удалять неиспользуемые кластеры. Если вы планируете немедленно работать с учебником, перечисленным в следующих шагах, возможно, вы захотите сохранить кластер.
Вернитесь на портал Azure и выберите Удалить.
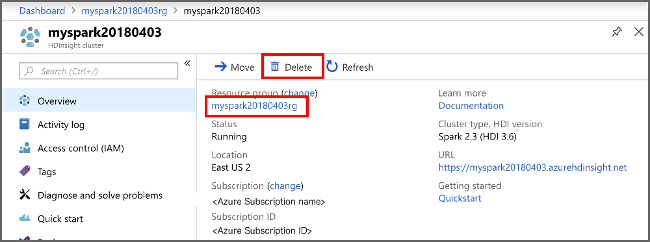 sight cluster" border="true":::
sight cluster" border="true":::
Кроме того, можно выбрать имя группы ресурсов, чтобы открыть страницу группы ресурсов, а затем щелкнуть Удалить группу ресурсов. Вместе с группой ресурсов вы также удалите кластер HDInsight и учетную запись хранения по умолчанию.
Дальнейшие действия
Из этого краткого руководства вы узнали, как создать кластер Apache Spark в HDInsight и выполнить простой SQL-запрос Spark. Из следующего руководства вы узнаете, как с помощью кластера HDInsight выполнять интерактивные запросы, используя для этого пример данных.