Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом руководстве описывается, как создать кадр данных из CSV-файла и как отправлять интерактивные запросы SQL Spark к кластеру Apache Spark в Azure HDInsight. В Spark кадр данных — это распределенная коллекция данных, упорядоченных в именованных столбцах. Dataframe концептуально эквивалентен таблице в реляционной базе данных или фрейму данных в R/Python.
В этом руководстве описано следующее:
- Создание кадра данных из CSV-файла
- Запуск запросов на фрейме данных
Предпосылки
Кластер Apache Spark в HDInsight. См. Создание кластера Apache Spark.
Создание записной книжки Jupyter
Jupyter Notebook — это интерактивная среда записных книжек, которая поддерживает различные языки программирования. Notebook позволяет работать с данными, объединять код с текстом Markdown и выполнять простые визуализации.
Измените URL-адрес
https://SPARKCLUSTER.azurehdinsight.net/jupyter, заменивSPARKCLUSTERименем кластера Spark. В веб-браузере введите измененный URL-адрес. При появлении запроса введите учетные данные для входа в кластер.На веб-странице Jupyter для кластеров Spark 2.4, выберите New (Создать)>PySpark, чтобы создать записную книжку. Для выпуска Spark 3.1 вместо этого выберите New (Создать)>PySpark3, чтобы создать записную книжку, поскольку ядро PySpark больше не доступно в Spark 3.1.
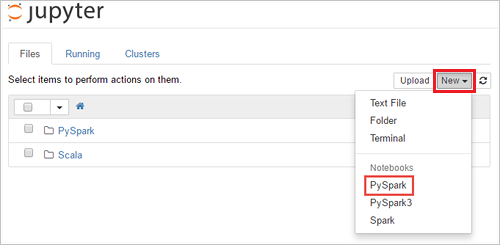
Будет создана и открыта записная книжка с именем Untitled(
Untitled.ipynb).Примечание.
Если записная книжка создается с использованием PySpark или ядра PySpark3, сеанс
sparkавтоматически создается при выполнении первой ячейки кода. Вам не нужно явно создавать этот сеанс.
Создание кадра данных из CSV-файла
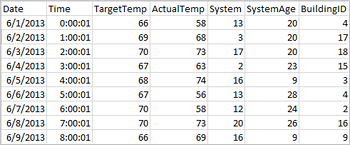
Приложения могут создавать кадры данных непосредственно из файлов или папок в удаленном хранилище, например служба хранилища Azure или Azure Data Lake Storage; из таблицы Hive; или из других источников данных, поддерживаемых Spark, таких как Azure Cosmos DB, База данных SQL Azure, DW и т. д. На изображении экрана представлен фрагмент файла hvac.csv, используемого в этом руководстве. CSV-файл содержит все кластеры HDInsight Spark. Эти данные демонстрируют колебания температуры в некоторых зданиях.
Вставьте следующий код в пустую ячейку записной книжки Jupyter Notebook и нажмите SHIFT+ВВОД для выполнения кода. Код импортирует типы, необходимые для этого сценария:
from pyspark.sql import * from pyspark.sql.types import *При выполнении интерактивного запроса в Jupyter окно веб-браузера или заголовок вкладки отображает состояние (занято) вместе с заголовком записной книжки. Кроме того, рядом с надписью PySpark в верхнем правом углу вы видите закрашенный кружок. После завершения работы он изменится на окружность.
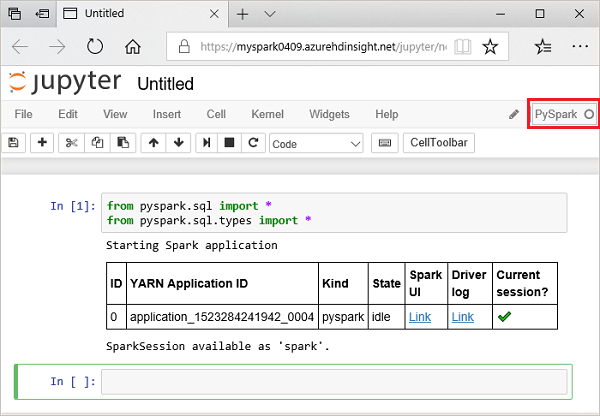
Запишите возвращенный идентификатор сеанса. На рисунке выше идентификатор сеанса равен 0. При необходимости можно получить сведения о сеансе, перейдя по ссылке
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statements, где CLUSTERNAME — это имя кластера Spark, а ID — идентификатор сеанса.Выполните следующий код, чтобы создать кадр данных и временную таблицу hvac, выполнив следующий код.
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
Выполнение запросов в системе datanami
Когда таблица будет готова, выполните интерактивный запрос к данным.
Запустите следующий фрагмент кода в пустой ячейке блокнота:
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Отобразятся следующие табличные данные.
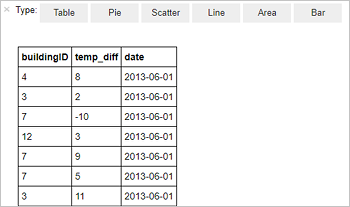
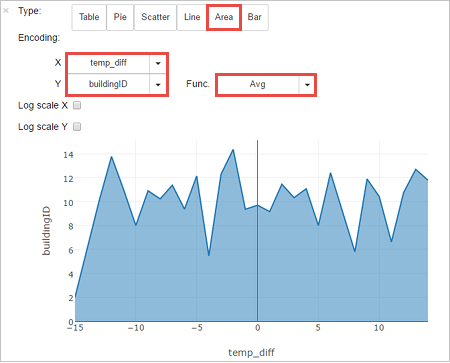
Результаты также можно просмотреть и в других визуализациях. Чтобы увидеть результат в виде диаграммы с областями, выберите Область и укажите другие значения, как показано ниже.
В строке меню записной книжки выберите Файл>Сохранить и создать контрольную точку.
Если вы начинаете следующий учебник сейчас, оставьте записную книжку открытой. В противном случае завершите работу записной книжки, чтобы освободить ресурсы кластера. В строке меню записной книжки выберите File (Файл) >Close and Halt (Закрыть и остановить).
Очистка ресурсов
С HDInsight ваши данные и записные книжки Jupyter сохраняются в Службе хранилища Azure или Azure Data Lake Storage, поэтому вы можете безопасно удалить кластер, когда он не используется. Плата за кластеры HDInsight взимается, даже когда они не используются. Так как затраты на кластер во много раз превышают затраты на хранилище, экономически целесообразно удалять неиспользуемые кластеры. Если вы планируете немедленно начать следующее руководство, можете оставить кластер.
Откройте кластер на портале Azure и выберите Удалить.
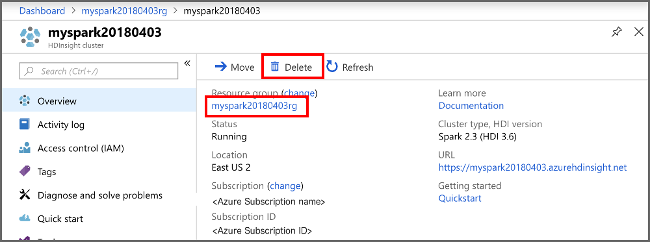
Кроме того, можно выбрать имя группы ресурсов, чтобы открыть страницу группы ресурсов, а затем щелкнуть Удалить группу ресурсов. Вместе с группой ресурсов вы также удалите кластер Spark в HDInsight и учетную запись хранения по умолчанию.
Следующие шаги
В этом учебнике описывается, как создать кадр данных из CSV-файла и как отправлять интерактивные запросы SQL Spark к кластеру Apache Spark в Azure HDInsight. Теперь переходите к следующей статье, в которой объясняется, как перенести зарегистрированные в Apache Spark данные в средство бизнес-аналитики, например в Power BI.