Использование Apache Spark MLlib для создания приложения машинного обучения и анализа набора данных
Узнайте, как использовать Apache Spark MLlib для создания приложения машинного обучения. Приложение выполняет прогнозный анализ открытого набора данных. В этом примере используется классификация посредством логистической регрессии на основе встроенных библиотек машинного обучения Spark.
MLlib — это основная библиотека Spark, содержащая множество служебных программ, которые подходят для задач машинного обучения, в том числе:
- Классификация
- Регрессия
- Кластеризация
- Моделирование
- сингулярного разложения и анализа по методу главных компонент;
- проверки гипотез и статистической выборки.
Общие сведения о классификации и логистической регрессии
Классификация — это распространенная задача машинного обучения, которая представляет собой процесс сортировки входных данных по категориям. Алгоритм классификации определяет принцип назначения "меток" предоставленным входным данным. Например, можно создать алгоритм машинного обучения, который принимает в качестве входных данных информацию об акциях. Затем он делит акции на две категории: акции, которые следует продать, и акции, которые следует оставить.
Логистическая регрессия — один из алгоритмов классификации. API Spark для логистической регрессии подходит для задач двоичной классификации или разделения входных данных на две группы. Дополнительные сведения о логистической регрессии см. в статье Википедии.
В целом, процесс логистической регрессии создает логистическую функцию. С помощью этой функции можно спрогнозировать, к какой группе относится входной вектор.
Пример прогнозного анализа данных проверки продуктов питания
В этом примере показано, как можно использовать Spark для прогнозного анализа на основе данных контроля качества пищевых продуктов (Food_Inspections1.csv). Эти данные получены с информационного портала города Чикаго. Этот набор данных содержит сведения о проверках качества пищевых продуктов, проведенных в Чикаго. В частности, в нем содержится информация о каждом предприятии общественного питания, обнаруженных нарушениях (если таковые были) и результатах проверки. CSV-файл данных уже доступен в учетной записи хранения, связанной с кластером /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv.
В следующих шагах вы разрабатываете модель, чтобы узнать, что требуется для прохождения или сбоя проверки продуктов питания.
Создание приложения машинного обучения Apache Spark MLlib
Создайте записную книжку Jupyter Notebook с помощью ядра PySpark. Инструкции см. в разделе Создание файла записной книжки Jupyter Notebook.
Импортируйте типы, необходимые для этого приложения. Скопируйте указанный ниже фрагмент кода, вставьте его в пустую ячейку и нажмите клавиши SHIFT+ВВОД.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *Ядро PySpark позволяет не задавать контексты явным образом. Контексты Spark и Hive будут созданы автоматически при выполнении первой ячейки кода.
Создание входного кадра данных
Используйте контекст Spark для извлечения необработанных данных CSV в память в виде неструктурированного текста. Затем с помощью библиотеки CSV Python проанализируйте каждую строку данных.
Запустите следующие строки, чтобы импортировать входные данные и создать на их основе устойчивый распределенный набор данных (RDD).
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)Выполните следующий код, чтобы получить из набора RDD одну строку, которая позволит изучить схему данных.
inspections.take(1)Результат выглядит так:
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]Эти выходные данные позволяют составить представление о схеме данных во входном файле. В файле содержатся название и тип каждого учреждения. Помимо прочего, в нем также содержатся адрес, данные проверок и расположение.
Выполните следующий код, чтобы создать кадр данных под (df) и временную таблицу (CountResults) с несколькими столбцами, которые помогут выполнить прогностический анализ. Для преобразования структурированных данных используйте
sqlContext.schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')В этом кадре данных нас интересуют 4 столбца: ID, name, results и violations.
Выполните следующий код, чтобы получить небольшую выборку данных.
df.show(5)Результат выглядит так:
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
Используемые данные
Давайте подробно рассмотрим содержимое нашего набора данных.
Выполните следующий код, чтобы увидеть конкретные значения из столбца результаты:
df.select('results').distinct().show()Результат выглядит так:
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+Выполните следующий код, чтобы создать визуализацию на основе этих результатов.
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY resultsВолшебное слово
%%sql, за которым следует-o countResultsdf, гарантирует, что вывод запроса сохраняется локально на сервере Jupyter (обычно это головной узел кластера). Выходные данные сохраняются в кадре данных Pandas с именем countResultsdf. Дополнительные сведения о команде magic%%sql, а также других командах magic, доступных в ядре PySpark, приведены в статье Ядра для записной книжки Jupyter в кластерах Apache Spark в Azure HDInsight.Результат выглядит так:
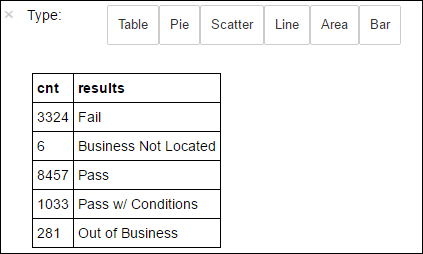
Также вы можете создать диаграмму с помощью библиотеки визуализации данных Matplotlib. Так как диаграмма должна создаваться из локально сохраненного кадра данных countResultsdf, фрагмент кода должен начинаться с волшебного слова
%%local. Это гарантирует, что код будет выполняться локально на сервере Jupyter.%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Чтобы спрогнозировать результат проверки пищевых продуктов, вам нужно разработать модель для анализа нарушений. Логистическая регрессия является методом двоичной классификации, а значит данные целесообразно разделить на две категории: Fail и Pass.
Пройдено
- Пройдено
- Pass w/ conditions;
Сбой
- Сбой
Игнорировать
- Business not located;
- Out of Business.
Данные с другими результатами ("Business Not Located" или "Out of Business") для нас бесполезны, и в любом случае их доля в общей выборке результатов невелика.
Выполните следующий код, чтобы преобразовать существующий кадр данных (
df) в новый кадр данных, где каждая проверка будет представлена в виде пары "метка — нарушение". В нашем случае метка0.0обозначает неудачу,1.0— успех, а-1.0— все остальные результаты, кроме этих двух.def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')Выполните следующий код, чтобы отобразить одну строку данных с меткой:
labeledData.take(1)Результат выглядит так:
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
Создание модели логистической регрессии на основе входной таблицы данных
Последняя задача — преобразование помеченных данных. Преобразуйте данные в формат, анализируемый логистической регрессией. Входные данные для алгоритма логистической регрессии должны представлять собой набор пар "метка — вектор признаков". "Вектор признаков" — это вектор чисел, которые представляют точку входа. Таким образом, нужно преобразовать столбец "violations", содержащий полуструктурированные данные и множество текстовых комментариев в свободной форме. Преобразуйте столбец в массив действительных чисел, которые может распознать компьютер.
Одним из стандартных подходов машинного обучения для обработки естественного языка является назначение каждого отдельного слова индексом. Затем передайте вектор в алгоритм машинного обучения. Каждое значение индекса содержит относительную частоту этого слова в текстовой строке.
MLlib предоставляет простой способ выполнения этой операции. Сначала пометим каждую строку нарушений с помощью маркеров, чтобы определить отдельные слова в каждой строке. Затем используем HashingTF, чтобы преобразовать каждый набор маркеров в вектор признаков, который затем может быть передан в алгоритм логистической регрессии для создания модели. Все эти шаги выполняются в последовательности с помощью конвейера.
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
Оценка модели по другому набору данных
Вы можете использовать созданную ранее модель для прогнозирования результатов новых проверок. Прогнозы основываются на обнаруженных нарушениях. Мы обучили эту модель по набору данных Food_Inspections1.csv. Вы можете применить другой набор данных, например Food_Inspections2.csv, чтобы оценить эффективность полученной модели на основе новых данных. Этот новый набор данных (Food_Inspections2.csv) следует поместить в контейнер хранилища по умолчанию, связанный с кластером.
Выполните приведенный ниже фрагмент кода, чтобы создать кадр данных predictionsDf с прогнозами нашей модели. Фрагмент кода также создает временную таблицу Predictions на основе кадра данных.
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columnsДолжны отобразиться подобные выходные данные:
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']Чтобы просмотреть пример прогноза, выполните этот фрагмент кода:
predictionsDf.take(1)Вы получите прогноз для первой записи в тестовом наборе данных.
Метод
model.transform()таким же образом преобразовывает новые данные и определяет, как их классифицировать. Можно выполнить статистические расчеты, чтобы оценить точность полученных прогнозов:numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")Выходные данные выглядят так:
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success rateПри использовании логистической регрессии со Spark создается модель связей между описаниями нарушений на английском языке. Кроме того, вы узнаете, пройдет ли определенная организация проверку качества пищевых продуктов.
Создание визуального представления прогноза
Теперь создайте итоговую визуализацию, которая позволит оценить результаты теста.
Начнем с извлечения разных прогнозов и результатов из временной таблицы Predictions, созданной ранее. Следующие запросы разделяют выходные данные на true_positive, false_positive, true_negative и false_negative. В приведенных ниже запросах мы отключим визуализацию с помощью
-q, а также сохраним выходные данные (с помощью-o) как кадры данных, которые затем можно будет использовать с волшебным словом%%local.%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')Наконец, используйте следующий фрагмент кода для создания диаграммы с помощью Matplotlib.
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Должен появиться следующий результат:
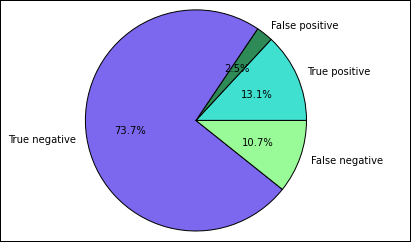
На этой диаграмме «положительный» результат представляет собой непройденную проверку, а отрицательный — пройденную.
Завершение работы записной книжки
После запуска приложения необходимо завершить работу записной книжки, чтобы освободить ресурсы. Для этого в меню File (Файл) записной книжки выберите пункт Close and Halt (Закрыть и остановить). Записная книжка завершит работу и закроется.
Следующие шаги
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по