Использование модели глубокого обучения Microsoft Cognitive Toolkit в кластере Azure HDInsight Spark
Ниже перечислены действия, которые вы выполните в этой статье.
запуск пользовательского сценария для установки Microsoft Cognitive Toolkit в кластере Azure HDInsight Spark;
передача Jupyter Notebook в кластер Apache Spark для применения обученной модели глубокого обучения Microsoft Cognitive Toolkit к файлам в учетной записи хранилища BLOB-объектов Azure с помощью API Python для Spark (PySpark).
Необходимые компоненты
Кластер Apache Spark в HDInsight. Ознакомьтесь со статьей Краткое руководство. Создание кластера Apache Spark в HDInsight с помощью шаблона.
Опыт работы с записными книжками Jupyter и Spark в HDInsight. Дополнительные сведения см. в статье Руководство. Загрузка данных и выполнение запросов в кластере Apache Spark в Azure HDInsight.
Как реализуется это решение?
Для описания этого решения используются данная статья и элемент Jupyter Notebook, загружаемый в рамках данной статьи. Ниже перечислены действия, которые вы выполните в этой статье.
- Запуск действия сценария в кластере HDInsight Spark для установки Microsoft Cognitive Toolkit и пакетов Python.
- Передача элемента Jupyter Notebook, запускающего решение в кластере HDInsight Spark.
Перечисленные ниже оставшиеся шаги приведены в описании Jupyter Notebook.
- Загрузка примеров изображений в устойчивый распределенный набор данных Spark (RDD).
- Загрузка модулей и определение предустановок.
- Скачивание набора данных локально в кластер Spark.
- Преобразование набора данных в RDD.
- Оценка изображений с помощью обученной модели Cognitive Toolkit.
- Скачивание обученной модели Cognitive Toolkit в кластер Spark.
- Определение функций, используемых рабочими узлами.
- Оценка изображений на рабочих узлах.
- Анализ точности модели.
Установка Microsoft Cognitive Toolkit
Microsoft Cognitive Toolkit в кластере Spark можно установить с помощью действия сценария. Действие сценария использует пользовательские скрипты для установки компонентов в кластере, которые по умолчанию недоступны. Можно использовать пользовательский сценарий с портала Azure, воспользовавшись пакетом SDK .NET для HDInsight или Azure PowerShell. Этот сценарий можно также использовать для установки данного набора средств при создании кластера или после его подготовки и запуска.
В этой статье мы используем портал для установки набора средств после того, как кластер был создан. Другие способы выполнения пользовательского сценария описаны в разделе Настройка кластеров HDInsight под управлением Linux с помощью действия сценария.
Использование портала Azure
Инструкции по использованию портала Azure для выполнения действия сценария см. в статье Настройка кластеров HDInsight под управлением Linux с помощью действия сценария. Обязательно укажите приведенные ниже данные для установки Microsoft Cognitive Toolkit. Используйте следующие значения для действия сценария.
| Свойство | Значение |
|---|---|
| Тип скрипта | - Custom |
| Имя. | Установка MCT |
| URI bash-скрипта | https://raw.githubusercontent.com/Azure-Samples/hdinsight-pyspark-cntk-integration/master/cntk-install.sh |
| Типы узлов: | Головной, рабочий |
| Параметры | нет |
Передача Jupyter Notebook в кластер Azure HDInsight Spark
Чтобы использовать Microsoft Cognitive Toolkit с кластером Azure HDInsight Spark, необходимо загрузить Jupyter Notebook CNTK_model_scoring_on_Spark_walkthrough.ipynb в кластер Azure HDInsight Spark. Эта записная книжка доступна на GitHub по адресу https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration.
Скачайте и распакуйте архив https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration.
В веб-браузере перейдите на страницу
https://CLUSTERNAME.azurehdinsight.net/jupyter, гдеCLUSTERNAME— это имя вашего кластера.В Jupyter Notebook выберите Отправить в правом верхнем углу, а затем перейдите к загрузкам и выберите файл
CNTK_model_scoring_on_Spark_walkthrough.ipynb.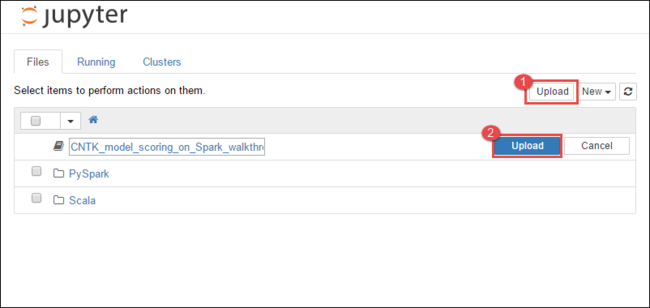
Щелкните Передать еще раз.
После передачи элемента Notebook щелкните его имя, а затем следуйте отображаемым в Notebook указаниям по загрузке набора данных и выполните задания в статье.
См. также
Сценарии
- Использование Apache Spark со средствами бизнес-аналитики. Выполнение интерактивного анализа данных с использованием Spark в HDInsight с помощью средств бизнес-аналитики
- Apache Spark и Машинное обучение. Анализ температуры в здании на основе данных системы кондиционирования с помощью Spark в HDInsight
- Apache Spark и Машинное обучение. Прогнозирование результатов проверки пищевых продуктов с помощью Spark в HDInsight
- Анализ журналов веб-сайтов с помощью Apache Spark в HDInsight
- Анализ журналов телеметрии Application Insights с помощью Apache Spark в HDInsight
Создание и запуск приложений
- Создание автономного приложения с использованием Scala
- Удаленный запуск заданий с помощью Apache Livy в кластере Apache Spark
Инструменты и расширения
- Использование подключаемого модуля средств HDInsight для IntelliJ IDEA для создания и отправки приложений Spark Scala
- Удаленная отладка приложений Apache Spark с помощью подключаемого модуля средств HDInsight для IntelliJ IDEA
- Использование записных книжек Zeppelin с кластером Apache Spark в Azure HDInsight
- Ядра, доступные для Jupyter Notebook в кластерах Apache Spark в HDInsight
- Использование внешних пакетов с Jupyter Notebook
- Установка записной книжки Jupyter на компьютере и ее подключение к кластеру Apache Spark в Azure HDInsight (предварительная версия)
Управление ресурсами
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по