Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Потоковая передача Apache Spark дает возможность реализовывать масштабируемые отказоустойчивые приложения с высокой пропускной способностью для обработки потоков данных. Приложения потоковой передачи Spark на кластере HDInsight Spark можно подключить к различным источникам данных, таким как Azure Event Hubs, Azure IoT Hub, Apache Kafka, Apache Flume, X, ZeroMQ, сырым сокетам TCP или к мониторингу изменений в файловой системе Apache Hadoop HDFS. Spark Streaming поддерживает отказоустойчивость и гарантирует, что любое событие обрабатывается точно один раз, даже в случае сбоя узла.
Spark Streaming создает длительные задания, во время которых вы можете применять преобразования к данным и затем передавать результаты в файловые системы, базы данных, панели мониторинга и консоль. Spark Streaming обрабатывает микропакеты данных, сначала собирая пакет событий за определённый интервал времени. а затем этот пакет отправляется на обработку и формирование выходных результатов. Интервалы времени для обработки пакета обычно определяются в долях секунды.

Потоки DStream
Потоковая передача Spark представляет непрерывный поток данных с использованием дискретизированного потока — DStream. Этот поток можно создать из источников входных данных, таких как Центры событий или Kafka, либо путем применения преобразований в другом потоке DStream. При поступлении события в приложение потоковой передачи Spark, оно сохраняется надежным образом. То есть, данные события реплицируются таким образом, чтобы на нескольких узлах была их копия. Благодаря этому сбой одного любого узла не приведет к потере события.
Ядро Spark использует устойчивые распределенные наборы данных (RDD). Эти наборы данных (RDDs) распределяют данные по нескольким узлам кластера, где каждый узел обычно хранит свои данные полностью в памяти для максимальной производительности. Каждый набор данных RDD представляет события, собранные за интервал пакетной обработки. По истечении интервала пакетной обработки потоковая передача Spark формирует новый набор данных RDD со всеми данными, созданными за этот интервал. Этот непрерывный набор RDD собирается в поток DStream. Приложение потоковой передачи Spark обрабатывает данные, хранящиеся в RDD каждого пакета.

Задачи структурированного потокового вещания Spark
Структурированная потоковая передача Spark была представлена в Spark 2.0 как механизм аналитики для структурированных данных потоковой передачи. В структурированной потоковой передаче Spark используются API механизма пакетной обработки SparkSQL. Как и обычная потоковая передача Spark, структурированная потоковая передача Spark выполняет обработку непрерывно поступающих микропакетов данных. В структурированной потоковой передаче Spark поток данных представлен в качестве входной таблицы с неограниченным количеством строк. То есть входная таблица продолжает расширяться по мере поступления новых данных. Эта таблица непрерывно обрабатывается с помощью долго выполняющегося запроса, а результаты обработки записываются в выходную таблицу.
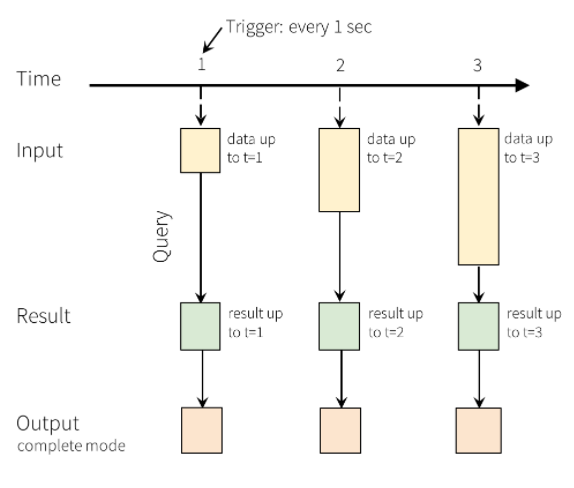
В структурированной потоковой передаче данные передаются в систему и сразу же поступают во входную таблицу. Вы можете написать запросы для выполнения операций в этой входной таблице. Выходные данные запроса поступают в другую таблицу — таблицу результатов. В таблице результатов содержатся результаты запроса, из которых извлекаются данные для отправки во внешнее хранилище данных, например реляционную базу данных. С помощью интервала триггера задается расписание для обработки данных во входной таблице. По умолчанию в структурированной потоковой передаче данные обрабатываются по мере их поступления. Однако можно также настроить триггер для выполнения в течение более длительного интервала, что позволит обрабатывать данные потоковой передачи в пакетах на основе времени. Данные в таблице результатов могут обновляться каждый раз, когда поступают новые данные, благодаря чему таблица будет включать все выходные данные с момента отправки запроса потоковой передачи (полный режим) или же содержать только новые данные, поступившие после последней обработки запроса (режим добавления).
Создание отказоустойчивых заданий стриминга в Spark
Чтобы создать высокодоступную среду для заданий потоковой передачи Spark, сначала напишите для отдельных заданий код, обеспечивающий их восстановление в случае сбоя. Задания, для которых доступно самостоятельное восстановление, являются отказоустойчивыми.
Наборы данных RDD имеют несколько свойств, которые способствуют высокой доступности и отказоустойчивости заданий потоковой передачи Spark:
- Пакеты входных данных, сохраненные в RDD как поток DStream, автоматически реплицируются в памяти для обеспечения отказоустойчивости.
- Данные, потерянные из-за сбоя рабочего узла, можно восстановить по реплицированным входным данным, которые сохраняются на других рабочих узлах, если они доступны.
- Быстрое восстановление после сбоя может занять не более секунды, так как при восстановлении после сбоев или других ошибок выполняется вычисление в памяти.
Семантика обработки "только один раз" в приложении потоковой передачи Spark
Чтобы создать приложение, обрабатывающее каждое событие только один раз, нужно учитывать, как все системные точки отказа перезапускаются после сбоя, а также как избежать потери данных. Семантика обработки "только один раз" требует, чтобы ни на каких этапах не терялись данные, а обработка сообщений всегда перезапускалась, независимо от места сбоя. Дополнительные сведения см. в статье Создание заданий потоковой передачи Spark со строго однократной обработкой событий.
Spark Streaming и Apache Hadoop YARN
В HDInsight работа кластера координируется распределителем ресурсов Yet Another Resource Negotiator (YARN). Проектирование обеспечения высокой доступности для потоковой передачи Spark включает методы как для потоковой передачи Spark, так и для компонентов YARN. Ниже приведен пример конфигурации, в которой используется YARN.

В следующих разделах описываются рекомендации по проектированию этой конфигурации.
Планирование на случай сбоев
Чтобы создать конфигурацию YARN для обеспечения высокого уровня доступности, следует учесть возможные сбои исполнителя или драйвера. Некоторые задания потоковой передачи Spark также имеют требования гарантии в отношении данных, для чего требуется дополнительная конфигурация и настройка. Например, приложение потоковой передачи может включать бизнес-требование, которое заключается в гарантии отсутствия потерь данных, независимо от типа ошибки, произошедшей в системе размещения потоковой передачи или кластере HDInsight.
Если работа исполнителя завершается ошибкой, Spark автоматически перезапускает его задачи и получатели, поэтому изменения конфигурации не требуются.
Однако если происходит сбой драйвера, работа его связанных исполнителей также завершается сбоем, что приводит к потере всех полученных блоков и результатов вычислений. Чтобы выполнить восстановление после сбоя драйвера, используйте чекпоинтинг DStream, как описано в Создание заданий потоковой передачи в Spark со строго однократной обработкой событий. При этом периодически сохраняется направленный ациклический граф (DAG) потоков DStream в отказоустойчивое хранилище, например службу хранилища Azure. Контрольные точки позволяют Spark Structured Streaming перезапускать драйвер, работа которого завершилась ошибкой, используя данные контрольной точки. Повторный запуск такого драйвера приводит к запуску новых исполнителей, а также повторному запуску получателей.
Выполните действия ниже для восстановления драйверов, используя контрольные точки DStream.
Настройте автоматический повторный запуск драйвера в YARN с помощью параметра конфигурации
yarn.resourcemanager.am.max-attempts.Настройте каталог контрольных точек в файловой системе, совместимой с HDFS, с помощью
streamingContext.checkpoint(hdfsDirectory).Реструктурируйте исходный код, чтобы использовать контрольные точки для восстановления, например:
def creatingFunc() : StreamingContext = { val context = new StreamingContext(...) val lines = KafkaUtils.createStream(...) val words = lines.flatMap(...) ... context.checkpoint(hdfsDir) } val context = StreamingContext.getOrCreate(hdfsDir, creatingFunc) context.start()Настройте восстановление потерянных данных, включив упреждающее протоколирование (WAL) с помощью
sparkConf.set("spark.streaming.receiver.writeAheadLog.enable","true"), и отключите репликацию в памяти для входящих потоков DStream с помощьюStorageLevel.MEMORY_AND_DISK_SER.
Таким образом, использование контрольных точек, упреждающего протоколирования (WAL) и надежных получателей позволяет обеспечить гарантию восстановления данных хотя бы один раз.
- Только один раз, если полученные данные не теряются, а выходные данные являются либо идемпотентными, либо сохраняются в транзакциях.
- Ровно один раз, если используется новый подход Kafka Direct, при котором Kafka работает как реплицированный журнал без использования получателей или упреждающего протоколирования (WAL).
Типичные проблемы при обеспечении высокой доступности
Задания потоковой передачи отслеживать сложнее, чем пакетные задания. Задания потоковой передачи Spark обычно выполняются длительное время, и YARN выполняет статистическую обработку журналов только после завершения задания. Во время обновления Spark или приложения контрольные точки Spark теряются, поэтому вам нужно очистить каталог контрольных точек во время обновления.
Настройте такой режим кластера YARN, при котором драйверы запускаются даже в случае сбоя клиента. Чтобы настроить автоматический перезапуск драйверов, выполните команду ниже:
spark.yarn.maxAppAttempts = 2 spark.yarn.am.attemptFailuresValidityInterval=1hУ Spark и пользовательского интерфейса потоковой передачи Spark есть настраиваемая система метрик. Вы можете также использовать дополнительные библиотеки, такие как Graphite или Grafana, для получения метрик панели мониторинга, например, по числу обработанных записей, использованию памяти и сборке мусора (GC) на драйвере и исполнителях, общему времени задержки, использованию кластера и т. д. В структурированной потоковой передаче версии 2.1 или выше для сбора дополнительных метрик можно использовать
StreamingQueryListener.Долго выполняющиеся задания необходимо сегментировать. Когда приложение потоковой передачи Spark отправляется в кластер, необходимо определить очередь YARN, где будет запущено задание. Чтобы отправить долго выполняющиеся задания в отдельные очереди, можно использовать Планировщик емкости YARN.
Корректно завершите работу приложения для потокового вещания. Если известны смещения и все состояние приложения хранится извне, вы можете программным способом остановить приложение потоковой передачи в соответствующем месте. Один из способов — использовать «перехватчики потока» в Spark, проверяя внешние флаги каждые n секунд. Вы можете также использовать файл маркера, который создается в HDFS при запуске приложения и удаляется по завершении его работы. В случае подхода с использованием файла-маркера используйте отдельный поток в вашем приложении Spark, который вызывает код, подобный следующему:
streamingContext.stop(stopSparkContext = true, stopGracefully = true) // to be able to recover on restart, store all offsets in an external database
Следующие шаги
- Общие сведения о потоковой передаче Apache Spark
- Создание заданий потоковой передачи Apache Spark со строго однократной обработкой событий
- Long-running Apache Spark Streaming Jobs on YARN (Задания потоковой передачи Apache Spark, выполняющиеся долгое время в YARN)
- Structured Streaming: Fault Tolerant Semantics (Структурированная потоковая передача: отказоустойчивая семантика)
- Discretized Streams: A Fault-Tolerant Model for Scalable Stream Processing (Дискретизированные потоки: отказоустойчивая модель для обработки масштабируемого потока)