Overview of Apache Spark Streaming (Общие сведения о потоковой передаче Apache Spark)
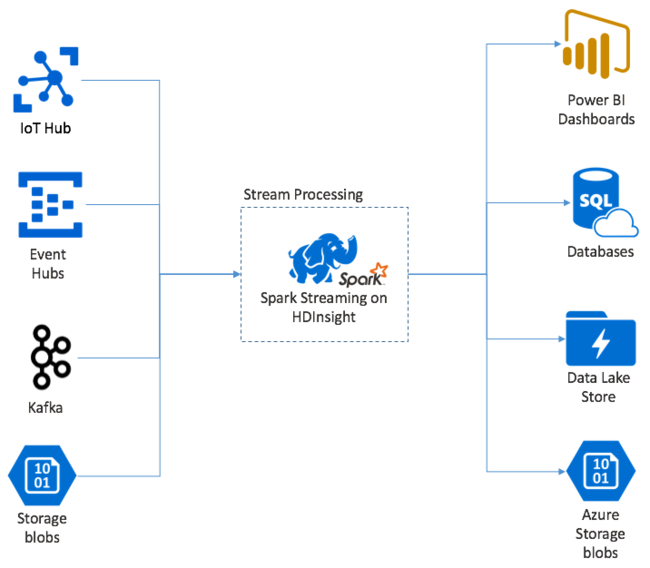
Потоковая передача Apache Spark обеспечивает обработку потока данных в кластерах HDInsight Spark. С гарантией, что любое входящее событие обрабатывается всего один раз, даже если происходит сбой узла. Потоковая передача Spark — это длительное задание, которое получает входные данные из самых разных источников, в том числе из Центров событий Azure. А также из центра Интернета вещей Azure, Apache Kafka, Apache Flume, Twitter, ZeroMQсокетов протокола прямого доступа TCP или из мониторинга файловых систем YARN Apache Hadoop. В отличие от процесса, управляемого только событиями, Потоковая передача Spark группирует входные данные в окна времени. Например, в двухсекундный сегмент, а затем преобразует каждый пакета данных с помощью операций сопоставления, сокращения, объединения и извлечения. Затем поток Spark записывает преобразованные данные в файловые системы, базы данных, панели мониторинга и консоль.
Приложениям потоковой передачи Spark необходимо подождать долю секунды, чтобы собрать каждый micro-batch событий, прежде чем отправить пакет на обработку. В свою очередь, приложение на основе событий обрабатывает каждое событие сразу же. Задержка при потоковой передаче Spark, как правило, не превышает несколько секунд. Преимущества подхода с использованием микропакетов заключаются в более эффективной обработке данных и более простых статистических вычислениях.
Общие сведения о DStream
Потоковая передача Spark представляет непрерывный поток входящих данных с использованием дискретизированного потока под названием DStream. DStream может быть создан из источников входных данных, таких как Центры событий или Kafka. Также его можно создать путем применения преобразований к другому потоку DStream.
Поток DStream обеспечивает уровень абстракции поверх необработанных данных событий.
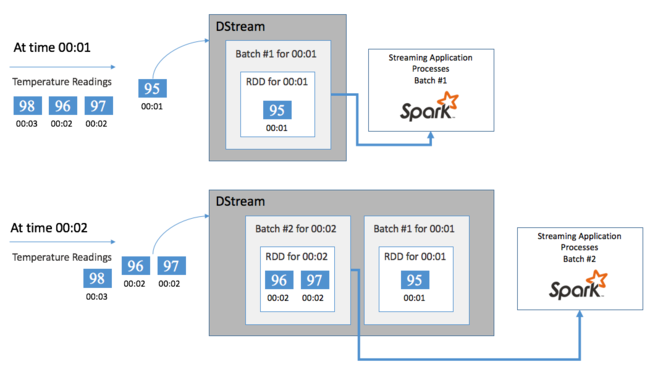
Начните с одиночного события, например с чтения температуры с подключенного термостата. При получении этого события в приложении потоковой передачи Spark оно сохраняется надежным способом, то есть реплицируется на нескольких узлах. Такая отказоустойчивость гарантирует, что сбой какого-либо узла не приведет к потере события. Ядро Spark использует структуру данных, которая позволяет распределять данные между несколькими узлами в кластере. Каждый узел обычно хранит собственные данные в памяти для лучшей производительности. Эта структура данных называется устойчивым распределенным набором данных (RDD).
Каждый набор RDD содержит события, собранные за определяемый пользователем период времени, называемый интервалом пакетной обработки. По окончании каждого интервала пакетов создается новый набор RDD, содержащий все данные из этого интервала. Этот непрерывный набор устойчивых распределенных наборов данных (RDD) собирается в поток DStream. Например, если интервал пакетов составляет одну секунду, ваш поток DStream каждую секунду выдает пакет, содержащий один набор RDD со всеми данными, полученными на протяжении этой секунды. При обработке потока DStream событие температуры появляется в одном из этих пакетов. Приложение потоковой передачи Spark обрабатывает пакеты, содержащие события, и в конечном счете работает с данными, хранящимися в каждом наборе RDD.
Структура приложения потоковой передачи Spark
Приложение потоковой передачи Spark — это длительно выполняемое приложение, которое получает данные из источников передачи. Это приложение применяет преобразования для обработки данных, а затем отправляет данные в одно или несколько мест назначения. Структура приложения потоковой передачи Spark состоит из статической и динамической частей. Статическая часть определяет источник данных и способ обработки данных. А также пункт назначения результатов. Динамическая часть запускает приложение на неопределенный срок, ожидая сигнал об остановке.
Например, следующее простое приложение получает строку текста через TCP-сокет и подсчитывает количество появлений каждого слова.
Определение приложения
Определение логики приложения состоит из четырех шагов.
- Создание объекта StreamingContext.
- Создание потока DStream из StreamingContext.
- Применение преобразований к потоку DStream.
- Вывод результатов.
Это определение является статическим, обработка данных начинается только после запуска приложения.
Создание объекта StreamingContext
Создайте объект StreamingContext из объекта SparkContext, указывающего на ваш кластер. При создании объекта StreamingContext необходимо указать размер пакета в секундах, например:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
Создание потока DStream
С помощью экземпляра StreamingContext создайте входной поток DStream для источника входных данных. В этом случае приложение следит за появлением новых файлов в подключенном по умолчанию хранилище.
val lines = ssc.textFileStream("/uploads/Test/")
Применение преобразований
Обработка реализовывается путем применения преобразований к потоку DStream. Это приложение получает из файла по одной строке текста за раз, разделяя каждую строку на слова. А затем использует шаблон MapReduce, чтобы подсчитать, сколько раз появляется каждое слово.
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
Вывод результатов
Отправьте результаты преобразования в системы назначения, применив операции вывода. В этом случае результат каждого выполнения путем вычисления выводится в выходных данных консоли.
wordCounts.print()
Выполнение приложения
Запустите приложение потоковой передачи и продолжайте его работу, пока не будет получен сигнал завершения.
ssc.start()
ssc.awaitTermination()
Дополнительные сведения об API потоковой передачи Spark см. в руководстве по программированию потоковой передачи Apache Spark.
Следующий пример приложения является автономным, поэтому его можно запустить в блокноте Jupyter. В этом примере создается макет источника данных в классе DummySource, который выводит значение счетчика и текущее время в миллисекундах каждые пять секунд. Для нового объекта StreamingContext интервал пакетной обработки составляет 30 секунд. Каждый раз, когда создается пакет, приложение потоковой передачи проверяет созданный RDD. Затем преобразует RDD в Spark DataFrame и создает временную таблицу поверх DataFrame.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Подождите около 30 секунд после запуска указанного выше приложения. Затем можно периодически запрашивать DataFrame, чтобы просмотреть текущий набор значений в пакете, например с помощью следующего SQL-запроса:
%%sql
SELECT * FROM demo_numbers
Результат выглядит примерно так:
| значение | Время |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
Выводятся шесть значений, так как DummySource создает значение каждые 5 секунд, а пакет выпускается приложением каждые 30 секунд.
Скользящие окна
Чтобы выполнить статистические вычисления в потоке DStream за определенный период времени (например, чтобы получить значение средней температуры за последние две секунды), можно использовать операции sliding window, входящие в состав потоковой передачи Spark. Скользящее окно имеет продолжительность и интервал, во время которого вычисляется содержимое окна (интервал скольжения).
Скользящие окна могут перекрывать друг друга. Например, можно определить окно с продолжительностью две секунды и интервалом скольжения в одну секунду. Это действие означает, что каждый раз при выполнении статического вычисления в окне будут содержаться данные последней секунды предыдущего окна. А также новые данные следующей секунды
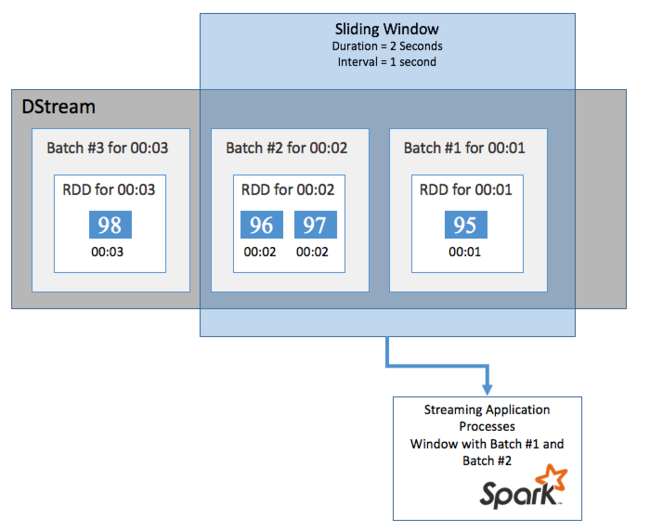
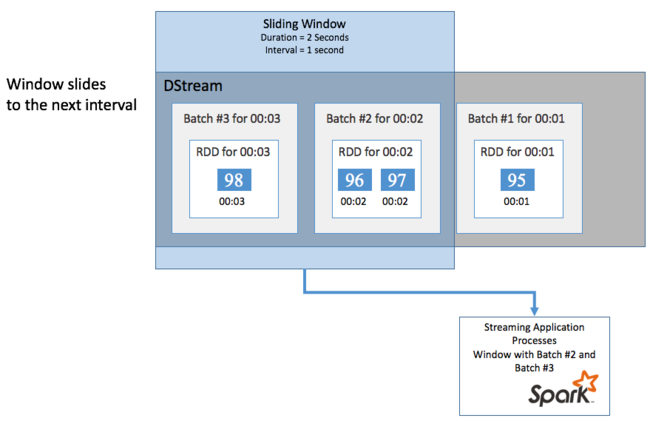
В следующем примере обновляется код, который использует DummySource для сбора пакетов в окно длительностью в одну минуту и интервалом скольжения в одну минуту.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
После истечения первой минуты будут получены 12 записей — по шесть записей из каждого из двух пакетов, собранных в окне.
| значение | Время |
|---|---|
| 1 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
В функции скользящего окна, доступные в API потоковой передачи Spark, входит window, countByWindow, reduceByWindow и countByValueAndWindow. Дополнительные сведения об этих функциях см. в разделе Transformations on DStreams (Преобразования в потоках DStream).
Назначение контрольных точек
Для обеспечения отказоустойчивости в потоковой передаче Spark используются контрольные точки, позволяющие гарантировать, что потоки обрабатываются непрерывно даже при сбоях узлов. Spark создает контрольные точки в долговременном хранилище (служба хранилища Azure или Data Lake Storage). Эти контрольные точки хранят метаданные приложения потоковой передачи, например конфигурацию и операции, определенные приложением. А также все пакеты, которые были поставлены в очередь, но еще не были обработаны. В некоторых случаях контрольные точки также включают сохранение данных в наборах RDD. Это позволяет быстрее перестраивать состояние данных из содержимого в наборах RDD, управляемых с помощью Spark.
Развертывание приложений потоковой передачи Spark
Обычно приложение потоковой передачи Spark создается локально в JAR-файле. После того, как приложение будет создано, разверните его в Spark в HDInsight, скопировав JAR-файл в подключенное по умолчанию хранилище. Можно запустить приложение с использованием интерфейсов REST API LIVY, к которым можно получить доступ в кластере с помощью операции POST. Основной текст процедуры Post включает документ JSON, который предоставляет путь к JAR-файлу. Также он предоставляет имя класса, основной метод которого определяет и запускает приложение потоковой передачи, и (необязательно) требования к ресурсам задания (например, количество исполнителей, памяти и ядер). Кроме того, он предоставляет любые параметры конфигурации, необходимые для кода приложения.
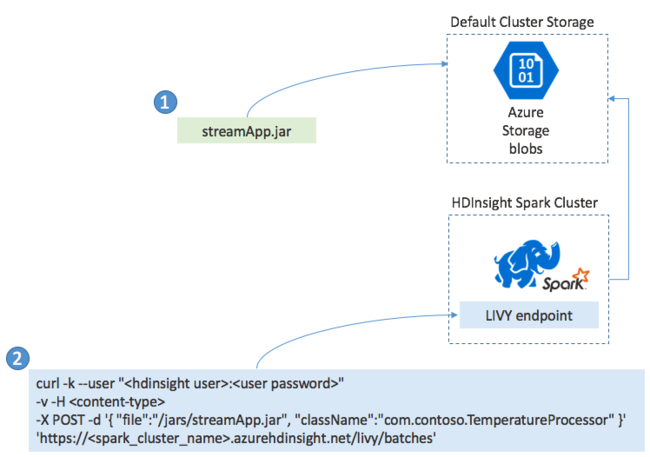
Состояние всех приложений можно также проверить с помощью запроса GET к конечной точке LIVY. Наконец, можно закрыть работающее приложение, выполнив запрос DELETE к конечной точке LIVY. Дополнительные сведения об API LIVY см. в статье Удаленная отправка заданий Spark в кластер Azure HDInsight с помощью Apache Spark REST API.
Следующие шаги
- Создание кластеров под управлением Linux в HDInsight с помощью портала Azure
- Руководство по программированию потоковой передачи Apache Spark
- Overview of Apache Spark Structured Streaming (Обзор структурированной потоковой передачи Apache Spark)