Использование кластера HDInsight Spark для анализа данных в Data Lake Storage 1-го поколения
В этой статье для выполнения задания, которое считывает данные из учетной записи Data Lake Storage, используется Jupyter Notebook с кластерами HDInsight Spark.
Необходимые компоненты
Учетная запись Azure Data Lake Storage 1-го поколения. Следуйте инструкциям из статьи Начало работы с Azure Data Lake Storage Gen1 с помощью портала Azure.
Кластер Azure HDInsight Spark с Data Lake Storage 1-го поколения в качестве хранилища. Следуйте инструкциям из статьи Краткое руководство по установке кластеров в HDInsight.
Подготовка данных
Примечание.
Этот шаг не нужно выполнять, если вы создали кластер HDInsight, использующий Data Lake Storage в качестве хранилища по умолчанию. Процесс создания кластера добавляет демонстрационные данные в учетную запись Data Lake Storage, указанную при создании кластера. Перейдите к разделу "Использование кластера HDInsight Spark с Data Lake Storage".
Если вы создали кластер HDInsight, использующий Data Lake Storage в качестве дополнительного хранилища и хранилище BLOB-объектов Azure как хранилище по умолчанию, то в учетную запись Data Lake Storage сначала следует скопировать демонстрационные данные. Вы можете использовать пример данных из хранилища BLOB-объектов Azure, связанного с кластером HDInsight.
Откройте командную строку и перейдите в каталог, в который установлено средство AdlCopy, обычно
%HOMEPATH%\Documents\adlcopy.Выполните следующую команду, чтобы скопировать заданный большой двоичный объект из контейнера-источника в Data Lake Storage.
AdlCopy /source https://<source_account>.blob.core.windows.net/<source_container>/<blob name> /dest swebhdfs://<dest_adls_account>.azuredatalakestore.net/<dest_folder>/ /sourcekey <storage_account_key_for_storage_container>Скопируйте пример файла данных HVAC.csv, расположенный в папке /HdiSamples/HdiSamples/SensorSampleData/hvac/, в учетную запись Azure Data Lake Storage. Фрагмент кода должен иметь следующий вид.
AdlCopy /Source https://mydatastore.blob.core.windows.net/mysparkcluster/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv /dest swebhdfs://mydatalakestore.azuredatalakestore.net/hvac/ /sourcekey uJUfvD6cEvhfLoBae2yyQf8t9/BpbWZ4XoYj4kAS5Jf40pZaMNf0q6a8yqTxktwVgRED4vPHeh/50iS9atS5LQ==Предупреждение
Убедитесь, что имена файла и пути используют правильный регистр.
Вам будет предложено ввести учетные данные для подписки Azure, в которой расположена учетная запись Data Lake Storage. Должен отобразиться результат, аналогичный приведенному ниже фрагменту кода.
Initializing Copy. Copy Started. 100% data copied. Copy Completed. 1 file copied.Файл данных (HVAC.csv) будет скопирован в папку /hvac в учетной записи Data Lake Storage.
Использование кластера HDInsight Spark с Data Lake Storage 1-го поколения
На начальной панели портала Azure щелкните плитку кластера Apache Spark (если она закреплена на начальной панели). Кроме того, вы можете перейти к кластеру, последовательно щелкнув Просмотреть все>Кластеры HDInsight.
В колонке кластера Spark щелкните Быстрые ссылки, затем в колонке Панель мониторинга кластера выберите Записная книжка Jupyter. При появлении запроса введите учетные данные администратора для кластера.
Примечание.
Также можно открыть Jupyter Notebook для своего кластера, открыв следующий URL-адрес в браузере. Замените CLUSTERNAME именем кластера:
https://CLUSTERNAME.azurehdinsight.net/jupyterСоздайте новую записную книжку. Щелкните Создать, а затем выберите PySpark.
Так как записная книжка была создана с помощью ядра PySpark, задавать контексты явно необязательно. Контексты Spark и Hive будут созданы автоматически при выполнении первой ячейки кода. Можно начать с импорта различных типов, необходимых для этого сценария. Для этого вставьте следующий фрагмент кода в ячейку и нажмите сочетание клавиш SHIFT+ВВОД.
from pyspark.sql.types import *При каждом запуске задания в Jupyter в заголовке окна веб-браузера будет отображаться состояние (Занято), а также название записной книжки. Кроме того, рядом с надписью PySpark в верхнем правом углу окна будет показан закрашенный кружок. После завершения задания этот значок изменится на кружок без заливки.

Загрузите пример данных во временную таблицу с помощью файла HVAC.csv, скопированного в учетную запись Data Lake Storage 1-го поколения. Получить доступ к данным в учетной записи Data Lake Storage можно с помощью следующего шаблона URL-адреса.
Если Data Lake Storage 1-го поколения используется в качестве хранилища по умолчанию, путь к файлу HVAC.csv будет похож на следующий URL-адрес.
adl://<data_lake_store_name>.azuredatalakestore.net/<cluster_root>/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvМожно также использовать сокращенный формат, как показано ниже.
adl:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvЕсли Data Lake Storage используется в качестве дополнительного хранилища, файл HVAC.csv будет находиться в расположении, куда он был скопирован. Например:
adl://<data_lake_store_name>.azuredatalakestore.net/<path_to_file>вставьте приведенный ниже код в пустую ячейку, замените MYDATALAKESTORE именем учетной записи Data Lake Storage и нажмите клавиши SHIFT + ВВОД. Этот пример кода регистрирует данные во временной таблице с именем hvac.
# Load the data. The path below assumes Data Lake Storage is default storage for the Spark cluster hvacText = sc.textFile("adl://MYDATALAKESTORazuredatalakestore. net/cluster/mysparkclusteHdiSamples/HdiSamples/ SensorSampleData/hvac/HVAC.csv") # Create the schema hvacSchema = StructType([StructField("date", StringTy(), False) ,StructField("time", StringType(), FalseStructField ("targettemp", IntegerType(), FalseStructField("actualtemp", IntegerType(), FalseStructField("buildingID", StringType(), False)]) # Parse the data in hvacText hvac = hvacText.map(lambda s: s.split(",")).filt(lambda s: s [0] != "Date").map(lambda s:(str(s[0]), s(s[1]), int(s[2]), int (s[3]), str(s[6]) )) # Create a data frame hvacdf = sqlContext.createDataFrame(hvac,hvacSchema) # Register the data fram as a table to run queries against hvacdf.registerTempTable("hvac")
Так как вы используете ядро PySpark, вы можете отправить SQL-запрос непосредственно к временной таблице hvac, которую вы только что создали с помощью магической команды
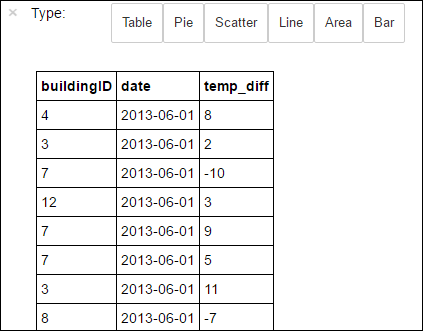
%%sql. Дополнительные сведения о магической команде%%sqlи о других магических командах, доступных в ядре PySpark, приведены в статье Ядра для записной книжки Jupyter Notebook в кластерах Apache Spark в Azure HDInsight.%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"После успешного выполнения задания по умолчанию будет показаны следующие табличные данные.
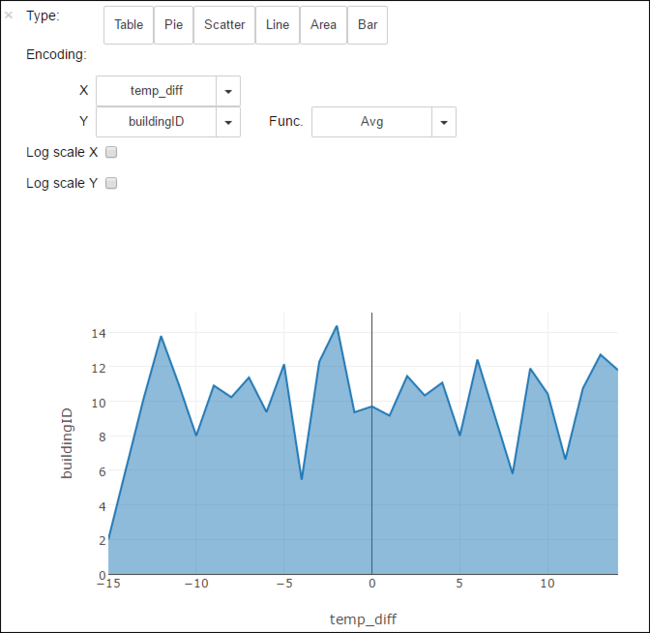
Результаты также можно просмотреть и в других визуализациях. Например, диаграмма областей для тех же выходных данных будет выглядеть следующим образом.
Завершив работу с приложением, следует закрыть записную книжку, чтобы освободить ресурсы. Для этого в записной книжке в меню Файл выберите пункт Close and Halt (Закрыть и остановить). Это завершит работу записной книжки и закроет ее.
Следующие шаги
- Создание автономного приложения Scala для работы в кластере Apache Spark в HDInsight на платформе Linux
- Создание приложений Apache Spark для кластера HDInsight с помощью набора средств Azure Toolkit for IntelliJ
- Создание приложений Apache Spark для кластера HDInsight с помощью Azure Toolkit for Eclipse
- Использование Azure Data Lake Storage Gen2 с кластерами Azure HDInsight