Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описывается, как автоматизированное машинное обучение (AutoML) в Машинное обучение Azure ищет и выбирает модели прогнозирования. Если вы хотите узнать больше о методологии прогнозирования в AutoML, ознакомьтесь с общими сведениями о методах прогнозирования в AutoML. Сведения о примерах обучения для моделей прогнозирования в AutoML см. в статье Настройка AutoML для обучения модели прогнозирования временных рядов с помощью пакета SDK и CLI.
Очистка модели в AutoML
Основная задача AutoML — обучение и оценка нескольких моделей и выбор лучшего в отношении заданной первичной метрики. Слово "model" в этом случае относится как к классу модели, например ARIMA или Случайному лесу, так и к определенным параметрам гиперпараметров, которые различают модели в классе. Например, ARIMA относится к классу моделей, которые совместно используют математический шаблон и набор статистических предположений. Для обучения или настройки модели ARIMA требуется список положительных целых чисел, определяющих точную математическую форму модели. Эти значения являются гиперпараметров. Модели ARIMA(1, 0, 1) и ARIMA(2, 1, 2) имеют один и тот же класс, но разные гиперпараметров. Эти определения можно по отдельности соответствовать данным обучения и оценивать друг с другом. АвтоML выполняет поиск по разным классам модели и в классах путем изменения гиперпараметров.
Методы очистки гиперпараметров
В следующей таблице показаны различные методы очистки гиперпараметров, которые AutoML использует для различных классов моделей:
| Группа классов модели | Тип модели | Метод очистки гиперпараметров |
|---|---|---|
| Наивный, сезонный наивный, средний, сезонный средний | Временной ряд | Без развертки в классе из-за простоты модели |
| Экспоненциальное сглаживание, ARIMA(X) | Временной ряд | Поиск сетки для развертки внутри класса |
| Пророк | Регрессия | Нет развертки в классе |
| Линейный КОД, LARS LASSO, Elastic Net, K ближайших соседей, дерево принятия решений, случайный лес, чрезвычайно случайные деревья, градиентные увеличенные деревья, LightGBM, XGBoost | Регрессия | Служба рекомендаций по модели AutoML динамически изучает пространства гиперпараметров |
| ForecastTCN | Регрессия | Статический список моделей, за которым следует случайный поиск по размеру сети, коэффициенту выпадения и скорости обучения |
Описание различных типов моделей см . в разделе "Прогнозирование" в разделе "АвтоML " статьи обзора методов прогнозирования.
Объем очистки с помощью AutoML зависит от конфигурации задания прогнозирования. Вы можете указать условия остановки в виде ограничения времени или ограничения на количество проб или эквивалентное количество моделей. Логику раннего завершения можно использовать в обоих случаях для остановки очистки, если основная метрика не улучшается.
Выбор модели в AutoML
AutoML следует трехэтапной процедуре поиска и выбора моделей прогнозирования:
Этап 1. Перебор моделей временных рядов и выбор оптимальной модели из каждого класса с помощью методов оценки максимальной вероятности .
Этап 2. Перебор моделей регрессии и их ранжирование вместе с лучшими моделями временных рядов с этапа 1 в соответствии со своими основными значениями метрик из наборов проверки.
Этап 3. Создание модели ансамбля из лучших ранжированных моделей, вычисление ее метрики проверки и ранжирование ее с другими моделями.
Модель с значением метрики верхнего ранжированного уровня в конце этапа 3 назначается лучшей моделью.
Внимание
На этапе 3 AutoML всегда вычисляет метрики для не примерных данных, которые не используются для соответствия моделям. Такой подход помогает защититься от чрезмерной адаптации.
Конфигурации проверки
AutoML имеет две конфигурации проверки: перекрестную проверку и явные данные проверки.
В случае перекрестной проверки AutoML использует входную конфигурацию для создания данных, разделенных на обучающие и проверяющие свертки. Порядок времени должен быть сохранен в этих разбиениях. AutoML использует так называемую перекрестную проверку скользящего источника, которая делит ряд на данные обучения и проверки с помощью точки времени источника. Скользящий во времени источник создает свертки перекрестной проверки. Каждая сверка проверки содержит следующий горизонт наблюдений сразу после положения источника для заданного свертывания. Эта стратегия сохраняет целостность данных временных рядов и снижает риск утечки информации.
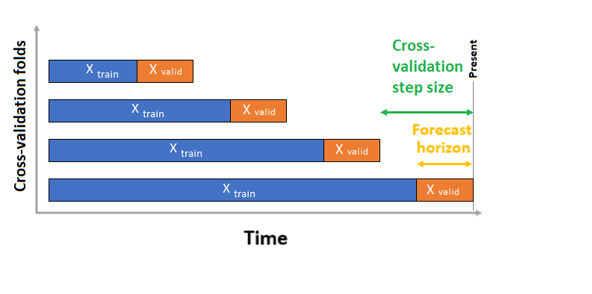
AutoML следует обычной процедуре перекрестной проверки, обучая отдельную модель для каждого свертывания и усреднения метрик проверки со всех сверток.
Перекрестная проверка заданий прогнозирования настраивается путем установки количества разных перекрестных проверок и, при необходимости, количества периодов времени между двумя последовательными перекрестными свертками. Дополнительные сведения и пример настройки перекрестной проверки для прогнозирования см. в разделе "Пользовательские параметры перекрестной проверки".
Вы также можете принести собственные данные проверки. Дополнительные сведения см. в статье "Настройка обучения, проверки, перекрестной проверки и тестирования данных в AutoML (sdk версии 1)".