Часто задаваемые вопросы о прогнозировании в AutoML
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python azure-ai-ml версии 2 (current)
Пакет SDK для Python azure-ai-ml версии 2 (current)
В этой статье приводятся ответы на распространенные вопросы о прогнозировании в автоматическом машинном обучении (AutoML). Общие сведения о методологии прогнозирования в AutoML см . в статье "Обзор методов прогнозирования" в статье AutoML .
Разделы справки начать создание моделей прогнозирования в AutoML?
Для начала ознакомьтесь со статьей о настройке AutoML для обучения статьи модели прогнозирования временных рядов. Примеры также можно найти в нескольких записных книжках Jupyter:
- Пример общего доступа к велосипеду
- Прогнозирование с помощью глубокого обучения
- Решение "Многие модели"
- Рецепты прогнозирования
- Сценарии расширенного прогнозирования
Почему AutoML медленно работает с данными?
Мы всегда работаем над тем, чтобы autoML быстрее и более масштабируемо. Чтобы работать в качестве общей платформы прогнозирования, AutoML выполняет обширные проверки данных и сложное проектирование функций, и выполняет поиск по большому пространству моделей. Эта сложность может потребовать много времени в зависимости от данных и конфигурации.
Одним из распространенных источников медленной среды выполнения является обучение AutoML с параметрами по умолчанию для данных, содержащих множество временных рядов. Стоимость многих методов прогнозирования масштабируется с числом рядов. Например, такие методы, как Экспоненциальная сглаживание и Пророк , обучают модель для каждого временных рядов в обучающих данных.
Функция "Многие модели" автоML масштабируется в этих сценариях путем распределения заданий обучения в вычислительном кластере. Он успешно применен к данным с миллионами временных рядов. Дополнительные сведения см. в разделе "Многие модели". Вы также можете ознакомиться с успехом многих моделей в высокопрофилном наборе данных конкуренции.
Как ускорить autoML?
Сведения о том, почему autoML медленно работает с данными? Чтобы понять, почему AutoML может быть медленным в вашем случае.
Рассмотрите следующие изменения конфигурации, которые могут ускорить задание.
- Блокировать модели временных рядов , такие как ARIMA и Пророк.
- Отключите функции обратного просмотра, такие как задержки и свернутые окна.
- Уменьшать:
- Количество проб/итераций.
- Время ожидания пробной итерации.
- Время ожидания эксперимента.
- Количество сверток перекрестной проверки.
- Убедитесь, что включено досрочное завершение работы.
Какую конфигурацию моделирования следует использовать?
Прогнозирование AutoML поддерживает четыре основные конфигурации:
| Настройка | Сценарий | Плюсы | Минусы |
|---|---|---|---|
| AutoML по умолчанию | Рекомендуется, если набор данных имеет небольшое количество временных рядов, которые имеют примерно аналогичное поведение журнала. | — Простая настройка из кода или пакета SDK или Студия машинного обучения Azure. — AutoML может учиться в разных временных рядах, так как пул моделей регрессии объединяет все ряды в обучении. Дополнительные сведения см. в разделе "Группирование моделей". |
— Модели регрессии могут быть менее точными, если временные ряды в обучающих данных имеют дивергентное поведение. — Модели временных рядов могут занять много времени для обучения, если данные обучения имеют большое количество рядов. Дополнительные сведения см. в ответе на ответ AutoML AutoML. |
| AutoML с глубоким обучением | Рекомендуется для наборов данных с более чем 1000 наблюдений и, возможно, многочисленных временных рядов, которые демонстрируют сложные шаблоны. Когда она включена, AutoML будет перебором временных сверточных моделей нейронной сети (TCN) во время обучения. Дополнительные сведения см. в разделе "Включение глубокого обучения". | — Простая настройка из кода или пакета SDK или Студия машинного обучения Azure. — Возможности перекрестного обучения, так как данные пулов TCN во всех рядах. — Потенциально более высокая точность из-за большой емкости моделей глубокой нейронной сети (DNN). Дополнительные сведения см. в разделе "Модели прогнозирования" в AutoML. |
— Обучение может занять гораздо больше времени из-за сложности моделей DNN. — Серии с небольшим количеством истории вряд ли будут воспользоваться этими моделями. |
| Многие модели | Рекомендуется обучать и управлять большим количеством моделей прогнозирования масштабируемым способом. Дополнительные сведения см. в разделе "Многие модели". | -Масштабируемый. — Потенциально более высокая точность, когда временные ряды имеют дивергентное поведение друг от друга. |
- Нет обучения в временных рядах. — Невозможно настроить или запустить задания "Многие модели" из Студия машинного обучения Azure. В настоящее время доступен только интерфейс кода или пакета SDK. |
| Иерархические временные ряды (HTS) | Рекомендуется, если ряд в данных содержит вложенную, иерархическую структуру, а также необходимо обучить или сделать прогнозы на агрегированных уровнях иерархии. Дополнительные сведения см. в разделе статьи по прогнозированию иерархических временных рядов . | — Обучение на агрегированных уровнях может снизить шум в временных рядах конечного узла и потенциально привести к более высокой точности моделей. — Вы можете получить прогнозы для любого уровня иерархии, агрегируя или разделяя прогнозы на уровне обучения. |
— Необходимо указать уровень агрегирования для обучения. AutoML в настоящее время не имеет алгоритма для поиска оптимального уровня. |
Примечание.
Мы рекомендуем использовать вычислительные узлы с графическими процессорами, если глубокое обучение включено для лучшего использования высокой емкости DNN. Время обучения может быть гораздо быстрее по сравнению с узлами с только ЦП. Дополнительные сведения см. в статье о размерах виртуальных машин, оптимизированных для GPU.
Примечание.
HTS предназначен для задач, в которых обучение или прогнозирование требуется на агрегированных уровнях иерархии. Для иерархических данных, требующих только обучения и прогнозирования конечных узлов, используйте вместо этого множество моделей .
Как предотвратить переполнение и утечку данных?
AutoML использует рекомендации по машинному обучению, такие как перекрестная выборка модели, которые устраняют многие проблемы с избыточным оборудованием. Однако существуют и другие потенциальные источники переполнения:
Входные данные содержат столбцы признаков, производные от целевого объекта с помощью простой формулы. Например, функция, которая является точной частью целевого объекта, может привести к почти идеальной оценке обучения. Однако модель, скорее всего, не обобщает выборку данных. Мы советуем изучить данные до обучения модели и удалить столбцы, которые "утечка" целевой информации.
Данные обучения используют функции, которые не известны в будущем, вплоть до горизонта прогнозирования. Модели регрессии AutoML в настоящее время предполагают, что все функции известны горизонту прогнозирования. Мы советуем изучить данные перед обучением и удалить все столбцы признаков, известные только исторически.
Существуют значительные структурные различия (изменения режима) между учебными, проверяющими или тестируемыми частями данных. Например, рассмотрим влияние пандемии COVID-19 на спрос почти на любой хороший в течение 2020 и 2021 года. Это классический пример изменения режима. Переполнение из-за изменения режима является самой сложной проблемой для решения, так как это очень зависит от сценария и может требовать глубоких знаний для выявления.
В качестве первой линии защиты попробуйте зарезервировать 10–20 процентов от общей истории для данных проверки или перекрестной проверки данных. Это не всегда возможно, чтобы зарезервировать этот объем данных проверки, если история обучения коротка, но это рекомендуется. Дополнительные сведения см. в разделе "Обучение и проверка данных".
Что означает, если моя учебная работа достигает идеальных показателей проверки?
Вы можете увидеть идеальные оценки при просмотре метрик проверки из задания обучения. Идеальная оценка означает, что прогноз и фактические данные набора проверки одинаковы или почти одинаковы. Например, у вас есть корень среднеквадратической ошибки, равной 0,0 или оценке R2 1,0.
Идеальная оценка проверки обычно указывает на то, что модель сильно перегружена, скорее всего, из-за утечки данных. Лучше всего проверить данные для утечки и удалить столбцы, вызывающие утечку.
Что делать, если данные временных рядов не имеют регулярных наблюдений?
Для моделей прогнозирования AutoML все требуется, чтобы обучающие данные регулярно размещали наблюдения относительно календаря. Это требование включает такие случаи, как ежемесячные или ежегодные наблюдения, в которых количество дней между наблюдениями может отличаться. Данные, зависящие от времени, могут не соответствовать этому требованию в двух случаях:
Данные имеют четко определенную частоту, но отсутствующие наблюдения создают пробелы в серии. В этом случае AutoML попытается обнаружить частоту, заполнить новые наблюдения за пробелами и ввести отсутствующие значения целевого объекта и признаков. При необходимости пользователь может настроить методы импутации с помощью параметров пакета SDK или через веб-интерфейс. Дополнительные сведения см. в разделе "Пользовательские признаки".
Данные не имеют четко определенной частоты. То есть длительность между наблюдениями не имеет четкого шаблона. Транзакционные данные, такие как из системы точки продаж, являются одним из примеров. В этом случае можно настроить AutoML для агрегирования данных на выбранную частоту. Вы можете выбрать обычную частоту, которая лучше всего подходит для данных и целей моделирования. Дополнительные сведения см. в разделе "Агрегирование данных".
Разделы справки выбрать основную метрику?
Основная метрика важна, так как ее значение в данных проверки определяет лучшую модель во время очистки и выбора. Нормализованная средняя квадратная ошибка (NRMSE) и нормализованная средняя абсолютная ошибка (NMAE) обычно являются лучшим выбором для основной метрики в задачах прогнозирования.
Чтобы выбрать между ними, обратите внимание, что NRMSE наказывает выливание в обучающих данных больше, чем NMAE, так как он использует квадрат ошибки. NMAE может быть лучшим выбором, если вы хотите, чтобы модель была менее чувствительной к выбросам. Дополнительные сведения см. в разделе "Регрессия" и "Прогнозирование метрик".
Примечание.
Мы не рекомендуем использовать оценку R2 или R2 в качестве основной метрики для прогнозирования.
Примечание.
AutoML не поддерживает пользовательские или пользовательские функции для основной метрики. Необходимо выбрать одну из предопределенных основных метрик, поддерживаемых AutoML.
Как повысить точность модели?
- Убедитесь, что вы настраиваете AutoML лучшим способом для данных. Дополнительные сведения см. в ответе на вопрос о конфигурации моделирования.
- Ознакомьтесь с записной книжкой по прогнозированию рецептов для пошагового руководства по созданию и улучшению моделей прогнозирования.
- Оцените модель с помощью обратных тестов в течение нескольких циклов прогнозирования. Эта процедура дает более надежную оценку ошибок прогнозирования и дает базовые показатели для оценки улучшений. Пример см. в записной книжке обратного тестирования.
- Если данные шумные, рассмотрите возможность агрегирования его на грубой частоте, чтобы увеличить коэффициент сигнала к шуму. Дополнительные сведения см. в разделе "Частота" и агрегирование целевых данных.
- Добавьте новые функции, которые помогут прогнозировать целевой объект. Опыт в области предметов может значительно помочь при выборе обучающих данных.
- Сравните значения метрики проверки и тестирования и определите, не подходит ли выбранная модель или перенагрузка данных. Эти знания помогут вам улучшить конфигурацию обучения. Например, вы можете определить, что необходимо использовать более перекрестные свертки в ответ на избыточность.
Будет ли AutoML всегда выбирать одну и ту же лучшую модель из одних и того же обучающих данных и конфигурации?
Процесс поиска модели AutoML не детерминирован, поэтому он не всегда выбирает одну и ту же модель из одних и того же данных и конфигурации.
Разделы справки исправить ошибку вне памяти?
Существует два типа ошибок памяти:
- ОЗУ вне памяти
- Диск вне памяти
Во-первых, убедитесь, что вы настраиваете AutoML наилучшим образом для ваших данных. Дополнительные сведения см. в ответе на вопрос о конфигурации моделирования.
Для параметров AutoML по умолчанию можно исправить ошибки озу вне памяти с помощью вычислительных узлов с большим объемом ОЗУ. Общее правило заключается в том, что объем свободного ОЗУ должен быть не менее 10 раз больше, чем размер необработанных данных для запуска AutoML с параметрами по умолчанию.
Вы можете устранить ошибки, связанные с диском вне памяти, удалив вычислительный кластер и создав новый.
Какие расширенные сценарии прогнозирования поддерживают AutoML?
AutoML поддерживает следующие расширенные сценарии прогнозирования:
- Прогнозы квантиля
- Надежная оценка модели с помощью скользящего прогноза
- Прогнозирование за пределами горизонта прогнозирования
- Прогнозирование времени между периодами обучения и прогнозирования
Примеры и сведения см. в записной книжке для расширенных сценариев прогнозирования.
Разделы справки просматривать метрики из заданий обучения прогнозирования?
Чтобы найти значения метрик обучения и проверки, см. сведения о заданиях или запусках в студии. Вы можете просматривать метрики для любой модели прогнозирования, обученной в AutoML, перейдя в модель из пользовательского интерфейса задания AutoML в студии и выбрав вкладку "Метрики ".
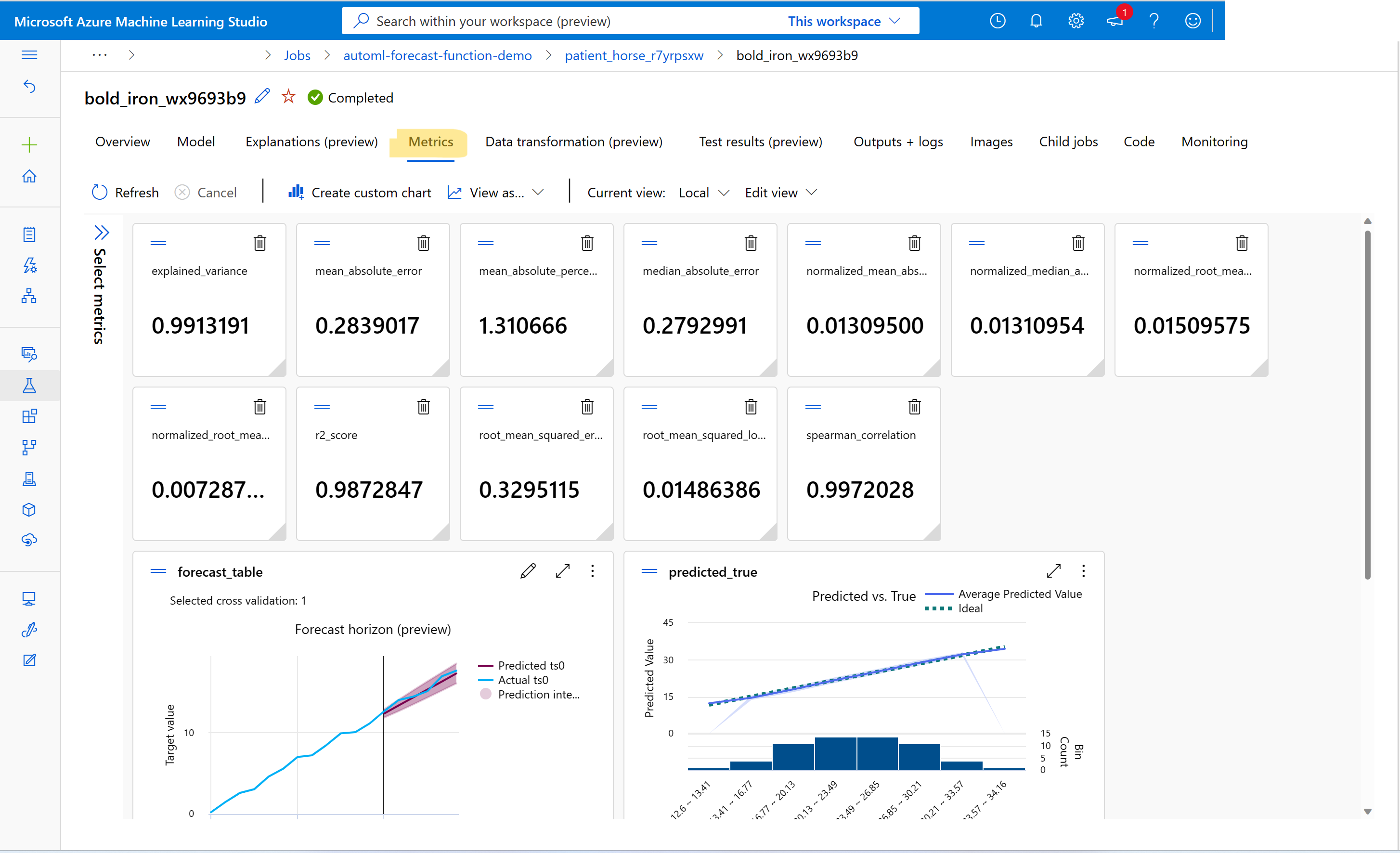
Разделы справки сбои отладки с заданиями обучения прогнозирования?
Если задание прогнозирования AutoML завершается сбоем, сообщение об ошибке в пользовательском интерфейсе студии поможет вам диагностировать и устранить проблему. Лучший источник сведений об ошибке за пределами сообщения об ошибке — это журнал драйвера для задания. Инструкции по поиску журналов драйверов см. в разделе Просмотр сведений о заданиях и запусках с помощью MLflow.
Примечание.
Для задания "Многие модели" или "HTS" обучение обычно выполняется в вычислительных кластерах с несколькими узлами. Журналы для этих заданий присутствуют для каждого IP-адреса узла. В этом случае необходимо искать журналы ошибок на каждом узле. Журналы ошибок, а также журналы драйверов находятся в папке user_logs для каждого IP-адреса узла.
Разделы справки развернуть модель из заданий обучения прогнозирования?
Вы можете развернуть модель из заданий обучения прогнозирования в любом из следующих способов:
- Конечная точка в Сети: проверьте файл оценки, используемый в развертывании, или перейдите на вкладку "Тест " на странице конечной точки в студии, чтобы понять структуру входных данных, которые ожидает развертывание. Пример см . в этой записной книжке . Дополнительные сведения о сетевом развертывании см. в разделе "Развертывание модели AutoML" в конечную точку в сети.
- Конечная точка пакетной службы. Этот метод развертывания требует разработки пользовательского скрипта оценки. Пример см. в этой записной книжке . Дополнительные сведения о пакетном развертывании см. в разделе "Использование конечных точек пакетной службы" для оценки пакетной службы.
Для развертываний пользовательского интерфейса рекомендуется использовать любой из следующих вариантов:
- Конечная точка реального времени
- Конечная точка пакетной службы
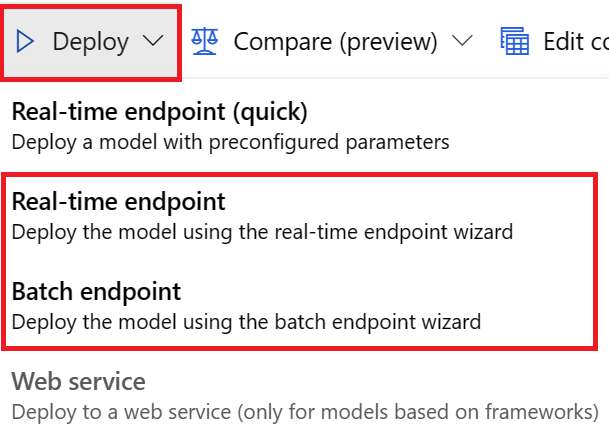
Не используйте первый вариант, конечная точка в режиме реального времени (быстрая).
Примечание.
По состоянию на данный момент мы не поддерживаем развертывание модели MLflow от прогнозирования заданий обучения с помощью пакета SDK, CLI или пользовательского интерфейса. При попытке вы получите ошибки.
Что такое рабочая область, среда, эксперимент, вычислительный экземпляр или целевой объект вычислений?
Если вы не знакомы с понятиями Машинное обучение Azure, начните с статьи "Что такое Машинное обучение Azure?" И что такое Машинное обучение Azure рабочая область?
Следующие шаги
- Узнайте больше о настройке AutoML для обучения модели прогнозирования временных рядов.
- Сведения о функциях календаря для прогнозирования временных рядов в AutoML.
- Узнайте, как AutoML использует машинное обучение для создания моделей прогнозирования.
- Узнайте о прогнозировании AutoML для отложенных функций.