Создание заданий и входных данных для пакетных конечных точек
Конечные точки пакетной службы позволяют выполнять длительные пакетные операции с большими объемами данных. Данные могут находиться в разных местах, например в разных регионах. Некоторые типы конечных точек пакетной службы также могут получать литеральные параметры в качестве входных данных.
В этой статье описывается, как указать входные данные параметров для конечных точек пакетной службы и создать задания развертывания. Процесс поддерживает работу с различными типами данных. Примеры см. в разделе "Общие сведения о входных и выходных данных".
Необходимые компоненты
Чтобы успешно вызвать конечную точку пакетной службы и создать задания, убедитесь, что выполнены следующие предварительные требования:
Конечная точка и развертывание пакетной службы. Если у вас нет этих ресурсов, см. статью "Развертывание моделей оценки в конечных точках пакетной службы" для создания развертывания.
Разрешения для запуска развертывания пакетной конечной точки. Роли Специалист по обработке и анализу данных, участника и владельца AzureML можно использовать для запуска развертывания. Сведения об определениях пользовательских ролей см. в разделе "Авторизация" в конечных точках пакетной службы для проверки конкретных необходимых разрешений.
Допустимый маркер идентификатора Microsoft Entra, представляющий субъект безопасности для вызова конечной точки. Этот субъект может быть субъектом-пользователем или субъектом-службой. После вызова конечной точки Машинное обучение Azure создает задание пакетного развертывания под удостоверением, связанным с маркером. Вы можете использовать собственные учетные данные для вызова, как описано в следующих процедурах.
Используйте Azure CLI для входа с помощью интерактивной проверки подлинности или кода устройства:
az loginДополнительные сведения о запуске заданий пакетного развертывания с помощью различных типов учетных данных см. в статье "Запуск заданий с помощью различных типов учетных данных".
Вычислительный кластер , в котором развернута конечная точка, имеет доступ для чтения входных данных.
Совет
Если вы используете хранилище данных без учетных данных или внешнюю учетную запись служба хранилища Azure в качестве входных данных, убедитесь, что вы настраиваете вычислительные кластеры для доступа к данным. Управляемое удостоверение вычислительного кластера используется для подключения учетной записи хранения. Удостоверение задания (вызывающего средства) по-прежнему используется для чтения базовых данных, что позволяет обеспечить детализированный контроль доступа.
Основы создания заданий
Чтобы создать задание из пакетной конечной точки, необходимо вызвать конечную точку. Вызов можно выполнить с помощью Azure CLI, пакета SDK Машинное обучение Azure для Python или вызова REST API. В следующих примерах показаны основы вызова для пакетной конечной точки, которая получает одну папку входных данных для обработки. Примеры с различными входными и выходными данными см. в разделе "Общие сведения о входных и выходных данных".
invoke Используйте операцию в конечных точках пакетной службы:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Вызов определенного развертывания
Конечные точки пакетной службы могут размещать несколько развертываний в одной конечной точке. Используется конечная точка по умолчанию, если пользователь не указывает в противном случае. Развертывание можно изменить для использования со следующими процедурами.
Используйте аргумент --deployment-name или -d укажите имя развертывания:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Настройка свойств задания
Вы можете настроить некоторые свойства в созданном задании во время вызова.
Примечание.
Возможность настройки свойств задания в настоящее время доступна только в пакетных конечных точках с развертываниями компонентов конвейера.
Настройка имени эксперимента
Чтобы настроить имя эксперимента, используйте следующие процедуры.
Используйте аргумент --experiment-name , чтобы указать имя эксперимента:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Общие сведения о входных и выходных данных
Конечные точки пакетной службы предоставляют устойчивый API, который потребители могут использовать для создания пакетных заданий. Тот же интерфейс можно использовать для указания входных и выходных данных, которые ожидает развертывание. Используйте входные данные для передачи сведений, необходимых конечной точке для выполнения задания.
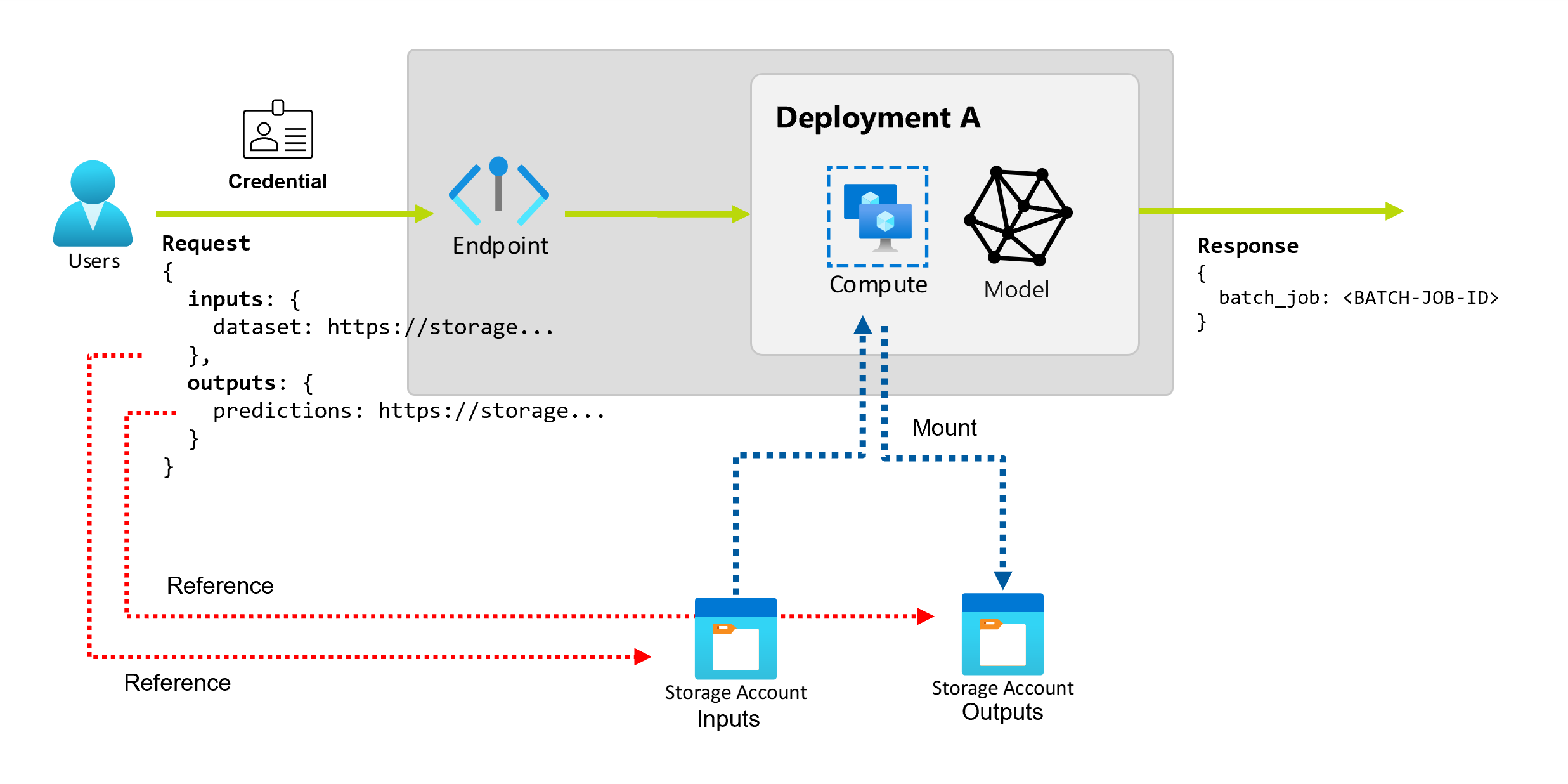
Конечные точки пакетной службы поддерживают два типа входных данных:
- Входные данные: указатели на определенное расположение хранилища или Машинное обучение Azure ресурс.
- Литеральные входные данные: литеральные значения, такие как числа или строки, которые необходимо передать в задание.
Количество и тип входных и выходных данных зависит от типа пакетного развертывания. Для развертываний моделей всегда требуется один вход данных и вывод одного выходных данных. Литеральные входные данные не поддерживаются. Однако развертывания компонентов конвейера предоставляют более общую конструкцию для создания конечных точек и позволяют указать любое количество входных данных (данных и литерала) и выходных данных.
В следующей таблице перечислены входные и выходные данные для пакетных развертываний:
| Тип развертывания | Количество входных данных | Поддерживаемые типы входных данных | Количество выходных данных | Поддерживаемые типы вывода |
|---|---|---|---|---|
| Развертывание модели | 1 | Входные данные | 1 | Выходные данные |
| Развертывание компонента конвейера | [0.N] | Входные данные и литеральные входные данные | [0.N] | Выходные данные |
Совет
Входные и выходные данные всегда именуются. Имена служат ключами для идентификации данных и передачи фактического значения во время вызова. Так как развертывания модели всегда требуют одного входного и выходного данных, имя игнорируется во время вызова. Вы можете назначить имя, которое лучше всего описывает вариант использования, например "sales_estimation".
Изучение входных данных
Входные данные ссылаются на входные данные, указывающие на расположение размещения данных. Так как конечные точки пакетной службы обычно используют большие объемы данных, входные данные не передаются в рамках запроса на вызов. Вместо этого необходимо указать расположение, в котором должна находиться конечная точка пакетной службы. Входные данные подключены и передаются в целевой вычислительный ресурс для повышения производительности.
Конечные точки пакетной службы поддерживают чтение файлов, расположенных в следующих вариантах хранения:
- Машинное обучение Azure ресурсы данных, включая папку (
uri_folder) и файл (uri_file). - Машинное обучение Azure хранилища данных, включая Хранилище BLOB-объектов Azure, Data Lake Storage 1-го поколения Azure и Azure Data Lake Storage 2-го поколения.
- учетные записи служба хранилища Azure, включая Data Lake Storage 1-го поколения Azure, Azure Data Lake Storage 2-го поколения и Хранилище BLOB-объектов Azure.
- Локальные папки и файлы данных (Машинное обучение Azure CLI или пакет SDK Машинное обучение Azure для Python). Однако эта операция приводит к отправке локальных данных в хранилище данных по умолчанию Машинное обучение Azure хранилища данных рабочей области, над которым вы работаете.
Внимание
Уведомление об отмене: наборы данных типа FileDataset (V1) устарели и будут прекращены в будущем. Существующие конечные точки пакетной службы, использующие эту функцию, будут продолжать работать. Конечные точки пакетной службы, созданные с помощью общедоступной версии CLIv2 (2.4.0 и более поздней версии) или REST API GA (2022-05-01 и более поздней версии) не поддерживают набор данных версии 1.
Изучение входных данных литерала
Литеральные входные данные относятся к входным данным, которые могут представляться и разрешаться во время вызова, например строк, чисел и логических значений. Обычно используются литеральные входные данные для передачи параметров в конечную точку в рамках развертывания компонента конвейера. Конечные точки пакетной службы поддерживают следующие литеральные типы:
stringbooleanfloatinteger
Входные данные литерала поддерживаются только в развертываниях компонентов конвейера. Сведения о том, как их указать, см. в статье "Создание заданий с помощью литеральных входных данных".
Изучение выходных данных
Выходные данные ссылаются на расположение, в котором должны размещаться результаты пакетного задания. Каждый вывод имеет идентифицируемое имя, и Машинное обучение Azure автоматически назначает уникальный путь каждому именованному выходу. При необходимости можно указать другой путь.
Внимание
Конечные точки пакетной службы поддерживают только запись выходных данных в Хранилище BLOB-объектов Azure хранилищах данных. Если необходимо записать в учетную запись хранения с включенными иерархическими пространствами имен (также известными как Azure Datalake 2-го поколения или ADLS 2-го поколения), вы можете зарегистрировать службу хранения в качестве хранилища Хранилище BLOB-объектов Azure, так как службы полностью совместимы. Таким образом можно записывать выходные данные из пакетных конечных точек в ADLS 2-го поколения.
Создание заданий с входными данными
В следующих примерах показано, как создавать задания, принимать входные данные из ресурсов данных, хранилищ данных и учетных записей служба хранилища Azure.
Использование входных данных из ресурса данных
Машинное обучение Azure ресурсы данных (ранее известные как наборы данных) поддерживаются в качестве входных данных для заданий. Выполните следующие действия, чтобы выполнить задание пакетной конечной точки с помощью данных, хранящихся в зарегистрированном ресурсе данных в Машинное обучение Azure.
Предупреждение
Ресурсы данных типа Table (MLTable) в настоящее время не поддерживаются.
Сначала создайте ресурс данных. Этот ресурс данных состоит из папки с несколькими CSV-файлами, которые обрабатываются параллельно с помощью конечных точек пакетной службы. Этот шаг можно пропустить, если данные уже зарегистрированы в качестве ресурса данных.
Создание определения ресурса данных в
YAML:heart-dataset-unlabeled.yml
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-dataset-unlabeled description: An unlabeled dataset for heart classification. type: uri_folder path: heart-classifier-mlflow/dataЗатем создайте ресурс данных:
az ml data create -f heart-dataset-unlabeled.ymlСоздайте входные данные или запрос:
Запустите конечную точку:
--setИспользуйте аргумент для указания входных данных:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$DATASET_IDДля конечной точки, которая служит развертыванием модели, можно использовать
--inputаргумент для указания входных данных, так как для развертывания модели всегда требуется только один вход данных.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATASET_IDАргумент
--set, как правило, создает длинные команды при указании нескольких входных данных. В таких случаях поместите входные данные вYAMLфайл и используйте--fileаргумент для указания входных данных, необходимых для вызова конечной точки.inputs.yml
inputs: heart_dataset: azureml:/<datasset_name>@latestВыполните следующую команду:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Использование входных данных из хранилищ данных
Вы можете напрямую ссылаться на данные из Машинное обучение Azure зарегистрированных хранилищ данных с заданиями пакетных развертываний. В этом примере сначала вы отправляете некоторые данные в хранилище данных по умолчанию в рабочей области Машинное обучение Azure, а затем запускаете пакетное развертывание. Выполните следующие действия, чтобы выполнить задание пакетной конечной точки с помощью данных, хранящихся в хранилище данных.
Доступ к хранилищу данных по умолчанию в рабочей области Машинное обучение Azure. Если данные хранятся в другом хранилище, вместо этого можно использовать это хранилище. Не требуется использовать хранилище данных по умолчанию.
DATASTORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')Идентификатор хранилища данных выглядит следующим образом
/subscriptions/<subscription>/resourceGroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/datastores/<data-store>.Совет
Хранилище данных BLOB-объектов по умолчанию в рабочей области называется workspaceblobstore. Этот шаг можно пропустить, если вы уже знаете идентификатор ресурса хранилища данных по умолчанию в рабочей области.
Отправьте некоторые примеры данных в хранилище данных.
В этом примере предполагается, что вы уже отправили примеры данных, включенные в репозиторий в папке в папке
sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/dataheart-disease-uci-unlabeledв учетной записи хранения BLOB-объектов. Прежде чем продолжить, обязательно выполните этот шаг.Создайте входные данные или запрос:
Поместите путь к файлу
INPUT_PATHв переменную:DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"Обратите внимание, как
pathsпеременная пути добавляется к идентификатору ресурса хранилища данных. Этот формат указывает, что следующее значение — путь.Совет
Можно также использовать формат
azureml://datastores/<data-store>/paths/<data-path>для указания входных данных.Запустите конечную точку:
--setИспользуйте аргумент для указания входных данных:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_PATHДля конечной точки, которая служит развертыванием модели, можно использовать
--inputаргумент для указания входных данных, так как для развертывания модели всегда требуется только один вход данных.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folderАргумент
--set, как правило, создает длинные команды при указании нескольких входных данных. В таких случаях поместите входные данные вYAMLфайл и используйте--fileаргумент для указания входных данных, необходимых для вызова конечной точки.inputs.yml
inputs: heart_dataset: type: uri_folder path: azureml://datastores/<data-store>/paths/<data-path>Выполните следующую команду:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlЕсли данные являются файлом, используйте
uri_fileвместо него тип входных данных.
Использование входных данных из учетных записей служба хранилища Azure
Машинное обучение Azure конечные точки пакетной службы могут считывать данные из облачных расположений в учетных записях служба хранилища Azure, как общедоступных, так и частных. Выполните следующие действия, чтобы запустить задание пакетной конечной точки с данными, хранящимися в учетной записи хранения.
Дополнительные сведения о дополнительной требуемой конфигурации для чтения данных из учетных записей хранения см. в разделе "Настройка вычислительных кластеров для доступа к данным".
Создайте входные данные или запрос:
INPUT_DATAЗадайте переменную:INPUT_DATA = "https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Если данные являются файлом, задайте переменную в следующем формате:
INPUT_DATA = "https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"Запустите конечную точку:
--setИспользуйте аргумент для указания входных данных:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_DATAДля конечной точки, которая служит развертыванием модели, можно использовать
--inputаргумент для указания входных данных, так как для развертывания модели всегда требуется только один вход данных.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderАргумент
--set, как правило, создает длинные команды при указании нескольких входных данных. В таких случаях поместите входные данные вYAMLфайл и используйте--fileаргумент для указания входных данных, необходимых для вызова конечной точки.inputs.yml
inputs: heart_dataset: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataВыполните следующую команду:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlЕсли данные являются файлом, используйте
uri_fileвместо него тип входных данных.
Создание заданий с помощью литеральных входных данных
Развертывания компонентов конвейера могут принимать литеральные входные данные. В следующем примере показано, как указать входные данные с именем score_modeтипа stringс значением append:
Поместите входные данные в файл и используйте --file для указания входных данных, необходимых для вызова конечной YAML точки.
inputs.yml
inputs:
score_mode:
type: string
default: append
Выполните следующую команду:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Аргумент можно также использовать --set для указания значения. Однако этот подход, как правило, создает длинные команды при указании нескольких входных данных:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Создание заданий с выходными данными
В следующем примере показано, как изменить расположение размещения выходных данных score . Для полноты эти примеры также настраивают входные данные с именем heart_dataset.
Сохраните выходные данные с помощью хранилища данных по умолчанию в рабочей области Машинное обучение Azure. Вы можете использовать любое другое хранилище данных в рабочей области, если это учетная запись хранения BLOB-объектов.
DATASTORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')Идентификатор хранилища данных выглядит следующим образом
/subscriptions/<subscription>/resourceGroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/datastores/<data-store>.Создайте выходные данные:
OUTPUT_PATHЗадайте переменную:DATA_PATH="batch-jobs/my-unique-path" OUTPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"Для полноты также создайте входные данные:
INPUT_PATH="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Примечание.
Обратите внимание, как
pathsпеременная пути добавляется к идентификатору ресурса хранилища данных. Этот формат указывает, что следующее значение — путь.Запустите развертывание: