Настройка AutoML для обучения модели прогнозирования временных рядов с помощью Python (SDKv1)
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python версии 1
Пакет SDK для Python версии 1
Из этой статьи вы узнаете, как настроить автоматизированное машинное обучение для моделей прогнозирования временных рядов с помощью автоматизированного ML Машинного обучения Azure в пакете SDK Python для Машинного обучения Azure.
Для этого сделайте следующее.
- Подготовьте данные для моделирования временных рядов.
- Настройте конкретные параметры временных рядов в объекте
AutoMLConfig. - Выполните прогноз с данными временных рядов.
Чтобы реализовывать эти возможности без написания большого объема кода, см. руководство по прогнозированию спроса с помощью автоматизированного машинного обучения, в котором приведен пример прогнозирования временных рядов с использованием автоматизированного машинного обучения в Студии машинного обучения Azure.
В отличие от классических методов использования временных рядов при автоматизированном машинном обучении прошлые значения временных рядов "сводятся" для создания дополнительных измерений для регрессоров вместе с другими прогностическими факторами. Этот подход предусматривает использование нескольких контекстных переменных и их связи друг с другом во время обучения. Так как на прогноз могут повлиять несколько факторов, этот метод хорошо согласуется с реальными сценариями прогнозирования. Например, при прогнозировании продаж их результат определяется взаимосвязью совокупности факторов: тенденций в предыдущие периоды, валютного курса и цены.
Необходимые компоненты
Для работы с этой статьей вам потребуется следующее:
Рабочая область Машинного обучения Azure. Сведения о создании рабочей области см. в разделе Создание ресурсов рабочей области.
В этой статье предполагается, что вам известны основные принципы настройки эксперимента автоматизированного машинного обучения. Следуйте инструкциям практического руководства, чтобы ознакомиться с основными конструктивными шаблонами экспериментов автоматизированного машинного обучения.
Внимание
Для выполнения команд Python из этой статьи требуется последняя версия пакета
azureml-train-automl.- Установите последнюю версию пакета
azureml-train-automlв локальной среде. - Сведения о последней версии пакета
azureml-train-automlсм. в заметках о выпуске.
- Установите последнюю версию пакета
Данные для обучения и проверки
Самое важное различие между задачами типа "регрессия прогнозирования" и "регрессия" в автоматизированном ML заключается во включении в учебные данные признака, представляющего допустимые временные ряды. Обычный временной ряд имеет четко определенную и постоянную периодичность, а также значение в каждой точке выборки в пределах непрерывного промежутка времени.
Внимание
При обучении модели для прогнозирования будущих значений убедитесь, что все признаки, используемые при обучении, можно применять при выполнении прогнозов для предполагаемого горизонта. Например, при создании прогноза спроса включение признака текущей цены акций может существенно повысить точность обучения. Однако если вы намерены выполнить прогнозирование с дальним горизонтом, возможно, вам не удастся точно предсказать будущую стоимость акций, соответствующую будущим точкам временного ряда, и точность модели может снизиться.
Можно указать отдельно учебные данные и проверочные данные непосредственно в объекте AutoMLConfig. Узнайте больше о AutoMLConfig.
При прогнозировании временных рядов для проверки по умолчанию используется только Перекрестная проверка источников скользящего прогноза (ROCV). ROCV делит ряд на данные для обучения и проверки с помощью временной точки источника. Скользящий во времени источник создает свертки перекрестной проверки. Эта стратегия сохраняет целостность данных временных рядов и устраняет риск утечки данных.
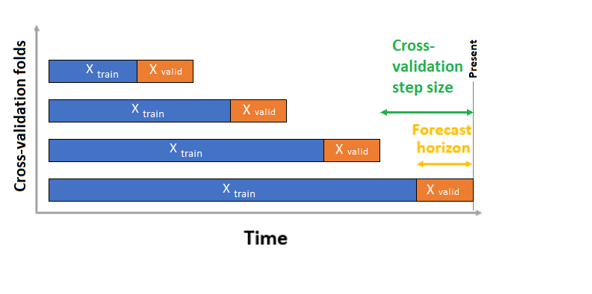
Передайте данные обучения и проверки в качестве одного набора данных параметру training_data. Задайте количество сверток перекрестной проверки с параметром n_cross_validations и задайте количество периодов между двумя последовательными перекрестными сверками.cv_step_size Вы также можете оставить либо оба параметра пустыми, и autoML автоматически задает их.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python версии 1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
Также можно воспользоваться собственными данными для проверки. Дополнительные сведения см. в статье Настройка разбиения и перекрестной проверки данных в AutoML.
Узнайте больше о том, как AutoML применяет перекрестную проверку, чтобы предотвратить возникновение лжевзаимосвязи в моделях.
Настройка эксперимента
Объект AutoMLConfig определяет параметры и данные, необходимые для задачи автоматизированного машинного обучения. Настройка модели прогнозирования сходна с настройкой стандартной регрессионной модели, но некоторые модели, параметры конфигурации и действия по конструированию признаков предусмотрены специально для данных временных рядов.
Поддерживаемые модели
Автоматизированное машинное обучение автоматически пытается применять различные модели и алгоритмы в ходе процесса создания и настройки модели. Как пользователь, вам не нужно указывать алгоритм. Для экспериментов прогнозирования как собственные модели временных рядов, так и модели глубокого обучения входят в состав системы рекомендаций.
Совет
В рамках системы рекомендаций для экспериментов прогнозирования также испытываются традиционные регрессионные модели. Полный список поддерживаемых моделей см. в справочной документации по пакету SDK.
Параметры конфигурации
Как и в случае с задачей регрессии, вы определяете стандартные параметры обучения, например тип задачи, число итераций, данные для обучения и число перекрестных проверок. Задачи прогнозирования требуют параметров time_column_name и forecast_horizon для настройки эксперимента. Если данные включают несколько временных рядов, например данные о продажах для нескольких магазинов или данных о потреблении в разных штатах, автоматизированное машинное обучение автоматически обнаруживает это и устанавливает для вас параметр time_series_id_column_names (предварительная версия). Можно также включить дополнительные параметры для более эффективной настройки запуска. Дополнительные сведения о том, что можно включить, см. в разделе "Дополнительные конфигурации".
Внимание
Автоматическая идентификация временных рядов в настоящее время доступна в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
| Наименование параметра | Description |
|---|---|
time_column_name |
Используется, чтобы задать столбец даты и времени во входных данных, используемых для создания временного ряда и выявления его периодичности. |
forecast_horizon |
Определяет, на сколько периодов в будущее следует выполнить прогноз. Горизонт указывается в единицах измерения частоты временных рядов. Единицы измерения определяются на основе интервала времени данных для обучения, например месяц или неделя, на который следует составить прогноз. |
Следующий код:
ForecastingParametersИспользует класс для определения параметров прогнозирования для обучения экспериментов- Задает
time_column_nameсоответствующим полюday_datetimeв наборе данных. - Задает для параметра
forecast_horizonзначение 50, чтобы прогнозирование проводилось по всему набору тестов.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
Затем эти параметры forecasting_parameters передаются в стандартный объект AutoMLConfig вместе с типом задачи forecasting, основной метрикой, условиями выхода и данными для обучения.
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
Объем данных, необходимый для успешного обучения модели прогнозирования с автоматизированным ML, зависит от значений forecast_horizon, n_cross_validations и target_lags или target_rolling_window_size, указанных при настройке AutoMLConfig.
Следующая формула вычисляет объем исторических данных, которые необходимы для создания признаков временных рядов.
Минимальное требуемое количество исторических данных: (2x forecast_horizon) + #n_cross_validations + max(max(target_lags), target_rolling_window_size)
Вызывается Error exception для любого ряда в наборе данных, который не соответствует требуемому количеству исторических данных для соответствующих параметров.
Шаги конструирования признаков
В каждом эксперименте автоматизированного машинного обучения по умолчанию к вашим данным применяются методики автоматического масштабирования и нормализации. Эти методы являются разновидностями конструирования признаков, которые помогают некоторым алгоритмам, чувствительным к признакам на различных масштабах. Дополнительные сведения о шагах конструирования признаков по умолчанию см. в статье Конструирование признаков в AutoML
В то же время следующие шаги выполняются только для типов задач forecasting:
- определение периодичности выборки временных рядов (например, ежечасно, ежедневно, еженедельно) и создание новых записей для отсутствующих временных точек с целью обеспечения непрерывности ряда;
- аппроксимация отсутствующих значений в столбцах целевых значений (путем прямого заполнения) и признаков (по медиане столбцов);
- создание признаков на основе идентификаторов временных рядов для поддержки постоянных эффектов для различных рядов.
- Создание функций на основе времени для обучения сезонных шаблонов
- кодирование категориальных переменных в числовые величины.
- Определите нестационарные временные ряды и автоматически различайте их, чтобы снизить влияние корней единиц.
Полный список возможных сконструированных функций, созданных на основе данных временных рядов, см. в разделе "Класс TimeIndexFeaturizer".
Примечание.
Шаги конструирования признаков автоматизированного машинного обучения (нормализация признаков, обработка недостающих данных, преобразование текста в числовой формат и т. д.) становятся частью базовой модели. При использовании модели прогнозирования те же этапы конструирования признаков, которые выполнялись во время обучения, автоматически выполняются для входных данных.
Настройка конструирования признаков
Также доступна возможность индивидуальной настройки параметров конструирования признаков, чтобы обеспечить получение на основе данных и признаков, используемых для обучения модели ML, релевантных прогнозов.
Поддерживаемые настройки для задач forecasting включают следующие.
| Настройка | Определение |
|---|---|
| Обновление назначения столбца | Переопределение автоматически определенного типа признака для указанного столбца. |
| Обновление параметра преобразователя | Обновление параметров для указанного преобразователя. В настоящее время поддерживает Imputer (fill_value и median). |
| Удаление столбцов | Указывает столбцы, которые следует исключить из конструирования признаков. |
Чтобы настроить конструирование признаков с помощью пакета SDK, укажите "featurization": FeaturizationConfig в объекте AutoMLConfig. Дополнительные сведения о настраиваемом конструировании признаков.
Примечание.
Функциональность удаления столбцов является устаревшей начиная с версии 1.19 пакета SDK. Удаляйте столбцы из набора данных в ходе очистки данных до их использования в эксперименте автоматизированного ML.
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
Если вы используете для эксперимента Студию машинного обучения Azure, узнайте, как настроить конструирование признаков в Студии.
Необязательные конфигурации
Дополнительные дополнительные конфигурации доступны для задач прогнозирования, таких как включение глубокого обучения и указание агрегирования целевого скользящего окна. Полный список дополнительных параметров доступен в справочной документации по пакету SDK для ForecastingParameters.
Частота и агрегирование целевых данных
Используйте частоту, параметр, freqчтобы избежать сбоев, вызванных нерегулярными данными. Нерегулярные данные включают данные, которые не соответствуют заданной частотой, например почасовой или ежедневной.
Для данных с ярко выраженной нерегулярностью или для различных нужд бизнеса пользователи также могут устанавливать требуемую частоту прогнозирования, freq, и указать функцию target_aggregation_function для агрегирования целевого столбца во временных рядах. Используйте эти два параметра в объекте AutoMLConfig , чтобы сэкономить некоторое время на подготовке данных.
Поддерживаемые операции агрегирования для значений целевых столбцов включают следующие:
| Function | Description |
|---|---|
sum |
Сумма целевых значений |
mean |
Среднее или среднее от целевых значений |
min |
Минимальное значение целевого объекта |
max |
Максимальное значение целевого объекта |
Включение глубокого обучения
Примечание.
Поддержка глубоких нейронных сетей для прогнозирования в автоматизированном машинном обучении доступна в предварительной версии и не поддерживается для локальных запусков или запусков в Databricks.
Кроме того, можно применять глубокое обучение в сочетании с глубокими нейронными сетями (DNN), чтобы улучшить выдаваемые моделью оценки. Глубокое обучение при автоматизированном машинном обучении позволяет прогнозировать данные одномерных и многомерных временных рядов.
Моделям глубокого обучения присущи три характерные особенности.
- Они могут обучаться на произвольных сопоставлениях входных данных с выходными.
- Они поддерживают несколько входов и выходов.
- Они могут автоматически извлекать закономерности во входных данных, проявляющиеся на длинных последовательностях.
Чтобы включить глубокое обучение, задайте enable_dnn=True в объекте AutoMLConfig.
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
Предупреждение
При включении глубокой нейронной сети для экспериментов, созданных с помощью пакета SDK, лучшие объяснения моделей отключены.
Сведения о включении глубокой нейронной сети для эксперимента AutoML, созданного в Студии машинного обучения Azure, см. в параметрах типов задач в практическом руководстве по пользовательскому интерфейсу студии.
Целевой агрегат со скользящим окном
Часто лучшие сведения для прогнозировщика — это последнее значение целевого объекта. Целевой агрегат со скользящим окном позволяет добавлять скользящие агрегаты значений данных в качестве признаков. Создание и использование этих признаков в качестве дополнительных контекстных данных повышает точность обучения модели.
Например, предположим, что требуется прогнозировать спрос на энергию. Можно выбрать добавление в качестве признака скользящего трехдневного окна, чтобы учитывать температурные изменения в отапливаемых помещениях. Создайте такое окно в этом примере, установив target_rolling_window_size= 3 в конструкторе AutoMLConfig.
В таблице ниже показано конструирование признаков, получаемое при использовании агрегата с окном. Значения в столбцах минимума, максимума и суммы создаются по скользящему окну размером в три показания на основе заданных параметров. У каждой из строк есть новый вычисляемый признак. В случае строки с меткой времени за 8 сентября 2017 г., 4:00, значения максимума, минимума и суммы вычисляются на основе значений спроса за 8 сентября 2017 г., за период с 1:00 по 3:00. Это окно размером три смещается во времени для заполнения данными оставшихся строк.

Просмотрите пример кода Python, в котором применяется признак целевого агрегата со скользящим окном.
Обработка коротких рядов
Автоматизированное машинное обучение считает временный ряд коротким рядом, если недостаточно точек данных для проведения обучения и проверки этапов разработки моделей. Количество точек данных различается в каждом из экспериментов и зависит от значения max_horizon, количества разделений перекрестной проверки, длины между проверками и длины ретроспективного обзора в модели, т. е. максимального количества исторических данных, необходимого для построения признаков временных рядов.
Автоматизированное ML обеспечивает поддержку обработки коротких циклов по умолчанию с помощью параметра short_series_handling_configuration в объекте ForecastingParameters.
Для включения обработки коротких циклов также должен быть определен параметр freq. Чтобы определить почасовую частоту, мы установим freq='H'. Просмотрите параметры частотной строки, перейдя к разделу объектов DataOffset страницы смещения временных рядов Pandas. Чтобы изменить поведение по умолчанию, short_series_handling_configuration = 'auto', измените параметр short_series_handling_configuration в объекте ForecastingParameter.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
Доступные варианты значений short_series_handling_configкратко описаны в следующей таблице.
| Параметр | Description |
|---|---|
auto |
Значение по умолчанию для обработки коротких рядов. - Если все ряды являются короткими, производится заполнение данных. - Если не все ряды являются короткими, то короткие ряды удаляются. |
pad |
Если short_series_handling_config = pad, то автоматизированное ML добавляет случайные значения в каждый обнаруженный короткий ряд. Ниже перечислены типы столбцов и их заполнение. - Столбцы объектов с naNs — числовые столбцы с 0 — логические столбцы или столбцы логики со значением False — Целевой столбец заполняется случайными значениями со средним значением нулевого и стандартного отклонения от 1. |
drop |
Если short_series_handling_config = drop, то автоматизированное ML удаляет короткие ряды и они не будут использоваться для обучения или прогнозирования. Прогнозы для этих рядов возвращают naN. |
None |
Ряды не заполняются и не удаляются |
Предупреждение
Заполнение может негативно повлиять на точность результирующей модели, поскольку мы вносим искусственные данные в модель лишь для того, чтобы обучение прошло без сбоев. Если коротких рядов много, также возможно некоторое негативное влияние на результаты возможностей объяснения.
Обнаружение и обработка нестационарных временных рядов
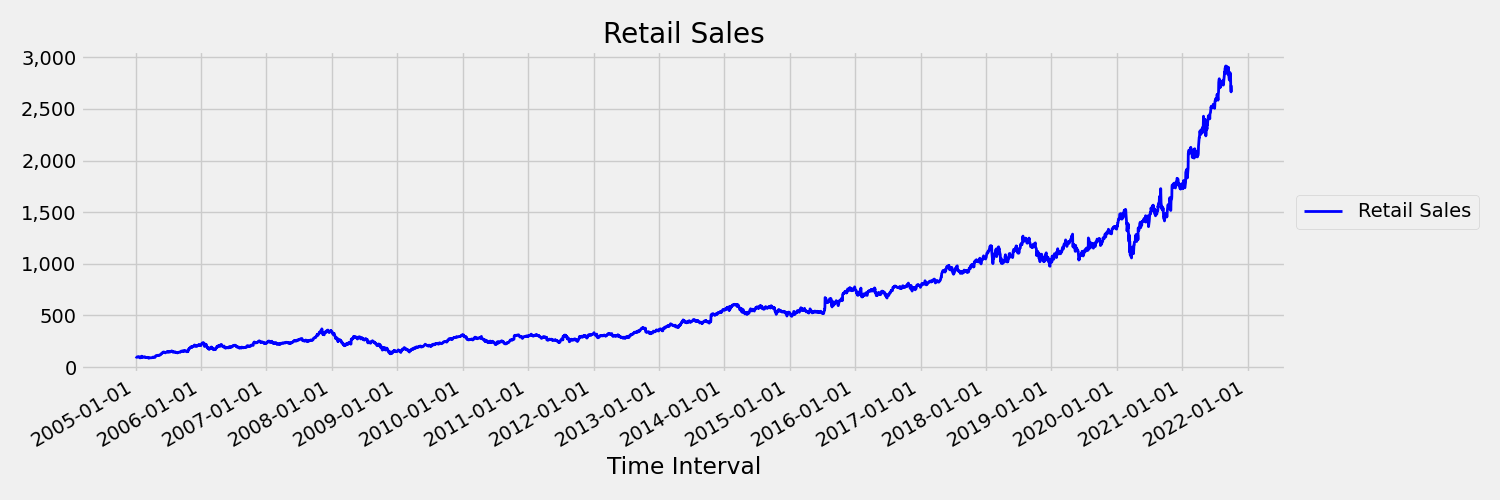
Временный ряд, моменты которого (средние и дисперсии) меняются с течением времени, называется нестанционным. Например, временные ряды, которые демонстрируют стохастические тенденции, являются нестановными по природе. Чтобы визуализировать это, на приведенном ниже изображении показан ряд, который, как правило, тренируется вверх. Теперь вычислить и сравнить средние (средние) значения для первой и второй половины ряда. Они одинаковы? Здесь среднее значение серии в первой половине сюжета меньше, чем во второй половине. Тот факт, что среднее значение ряда зависит от интервала времени, на который смотрит, является примером временных переменных моментов. Здесь среднее значение серии является первым моментом.
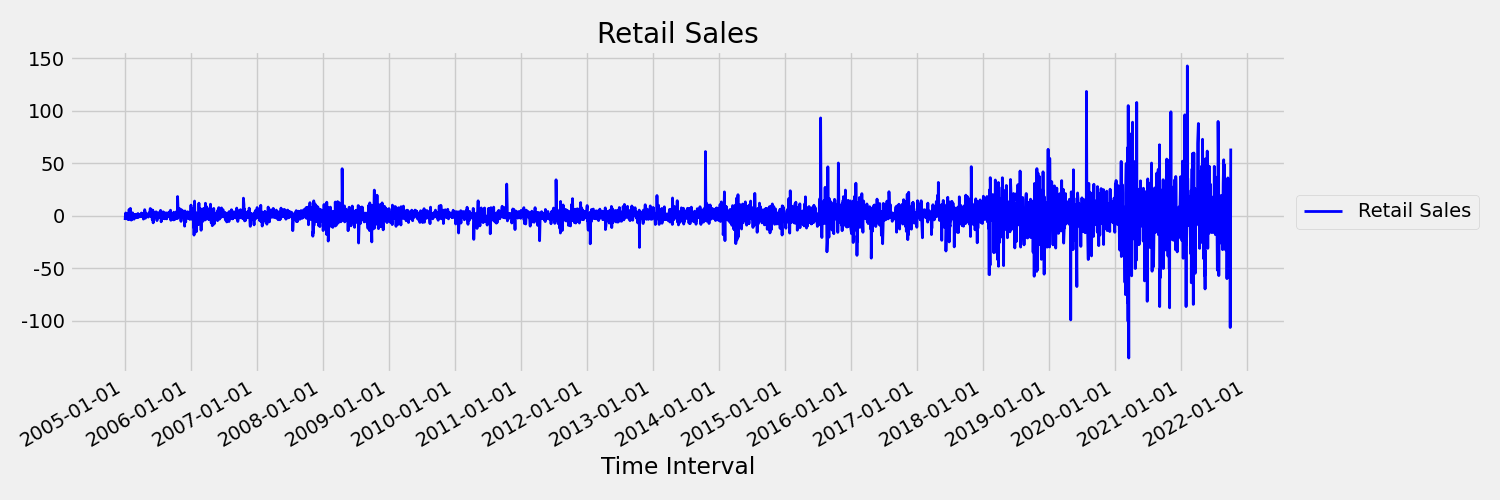
Далее давайте рассмотрим изображение, которое отображает исходную серию в первых различиях, $x_t = y_t - y_{t-1}$, где $x_t$ является изменением розничных продаж и $y_t$ и $y_{t-1}$ представляют исходную серию и ее первую задержку соответственно. Среднее значение серии грубо констант независимо от времени, на который смотрит один. Это пример первой последовательности временных рядов. Причина, по которой мы добавили первый термин заказа, заключается в том, что первый момент (среднее) не изменяется с интервалом времени, то же самое нельзя сказать о дисперсии, которая является вторым моментом.
Модели машинного обучения AutoML не могут по сути справиться с стохастических тенденций или другими известными проблемами, связанными с нестановными временными рядами. В результате их точность прогноза является "плохой", если существуют такие тенденции.
AutoML автоматически анализирует набор данных временных рядов, чтобы проверить, является ли он стационарным или нет. При обнаружении нестанционных временных рядов автоматическое преобразование AutoML применяет разностное преобразование, чтобы снизить влияние нестанционных временных рядов.
Выполнение эксперимента
Когда объект AutoMLConfig будет готов, можно отправлять эксперимент. После завершения моделирования извлеките наиболее подходящую итерацию выполнения.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
Прогнозирование с использованием лучшей модели
Используйте лучшую итерацию модели для прогнозирования значений данных, которые не использовались для обучения модели.
Оценка точности модели с помощью скользящего прогноза
Прежде чем поместить модель в рабочую среду, необходимо оценить ее точность в тестовом наборе, проведенном из обучающих данных. Рекомендуемая процедура — это так называемая скользякая оценка, которая выполняет переадресацию обученного прогнозировщика во времени по тестовому набору, усреднение метрик ошибок в нескольких окнах прогнозирования для получения статистически надежных оценок для определенного набора выбранных метрик. В идеале набор тестов для оценки длинен относительно горизонта прогноза модели. Оценки ошибки прогнозирования могут быть статистически шумными и, следовательно, менее надежными.
Например, предположим, что вы обучаете модель по ежедневным продажам для прогнозирования спроса до двух недель (14 дней) в будущем. Если есть достаточные исторические данные, вы можете зарезервировать последние несколько месяцев даже в год данных для тестового набора. Скользящей оценки начинается с создания прогноза на 14 дней вперед в течение первых двух недель тестового набора. Затем прогнозировщик передвигается на некоторое количество дней в тестовом наборе, и вы создаете еще один 14-дневный прогноз из новой позиции. Процесс продолжается до конца тестового набора.
Чтобы выполнить последовательное вычисление, вызовите rolling_forecast метод метода fitted_model, а затем вычисляете требуемые метрики в результате. Например, предположим, что в объекте test_features_df DataFrame pandas есть функции набора тестов, а также фактические значения целевого объекта в массиве numpy.test_target Последовательное вычисление с помощью среднеквадратической ошибки отображается в следующем примере кода:
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
В этом примере размер шага для скользящего прогноза имеет значение один, что означает, что прогнозировщик продвинут один период или один день в нашем примере прогнозирования спроса при каждой итерации. Общее количество прогнозов, возвращаемых rolling_forecast таким образом, зависит от длины тестового набора и размера этого шага. Дополнительные сведения и примеры см. в документации по rolling_forecast() и прогнозированию от записной книжки для обучения.
Прогнозирование в будущем
Функция forecast_quantiles() позволяет указать, когда должны начинаться прогнозы, в отличие от метода predict(), который обычно используется для задач классификации и регрессии. Метод forecast_quantiles() по умолчанию создает прогноз точки или средний или средний прогноз, который не имеет конуса неопределенности вокруг него. Дополнительные сведения см. в статье "Прогнозирование с помощью записной книжки для обучения".
В следующем примере сначала все значения в y_pred заменяются на NaN. В этом случае источник прогноза находится в конце данных для обучения. Однако если заменить только вторую половину y_pred на NaN, функция оставит числовые значения в первой половине неизменными и будет прогнозировать значения NaN во второй половине. Функция возвращает как прогнозируемые значения, так и выровненные признаки.
Для прогнозирования значений до указанной даты в функции forecast_quantiles() можно также использовать параметр forecast_destination.
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Клиентам часто нужны прогнозы для определенного квантиля распределения, например если прогнозирование используется для контроля запасов товаров в продуктовом магазине или виртуальных машин для облачной службы. В таких случаях используется контрольная точка вида “мы хотим, чтобы товар оставался в ассортименте и заканчивался 99 % времени”. Ниже показано, как указать нужные количества для прогнозов, например 50-й или 95-й процентиль. Если не указать квантиль, как в вышеупомянутом примере кода, то создаются прогнозы только для 50-го процентиля.
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Вы можете вычислить метрики модели, например, корень среднеквадратической погрешности (КСКП) или среднюю абсолютную процентную ошибку (MAPE), чтобы оценить производительность моделей. См. например, раздел "Оценка" записной книжки спроса на прокат велосипедов.
После определения точности общей модели, наиболее реалистичным следующим шагом будет использование модели для прогнозирования неизвестных будущих значений.
Укажите набор данных в том же формате, что и набор для тестирования test_dataset, но с будущими значениями даты и времени. Результирующим набором прогнозов будут прогнозируемые значения для каждого шага временного ряда. Предположим, что последние записи временных рядов в наборе данных датированы 31.12.2018. Чтобы спрогнозировать спрос на следующий день (или столько периодов, сколько необходимо для прогнозирования, <= forecast_horizon), создайте одну запись одиночного временного ряда для каждого магазина на 01.01.2019.
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
Повторите необходимые шаги, чтобы загрузить эти будущие данные в объект DataFrame, а затем запустите best_run.forecast_quantiles(test_dataset) для прогнозирования будущих значений.
Примечание.
Прогнозы внутри выборок не поддерживаются при прогнозировании с помощью автоматизированного ML, когда включены параметры target_lags и (или) target_rolling_window_size.
Прогнозирование в большом масштабе
Существуют сценарии, в которых одна модель машинного обучения недостаточна и требуется несколько моделей машинного обучения. Например, прогнозирование продаж для каждого отдельного магазина для торговой марки или настройка взаимодействия с отдельными пользователями. Создание модели для каждого экземпляра может привести к повышению результатов многих проблем машинного обучения.
Группирование — это понятие прогнозирования временных рядов, которое позволяет объединять временные ряды для обучения отдельных моделей в каждой группе. Этот подход может быть особенно полезен при наличии временных рядов, требующих сглаживания, заполнения или сущностей в группе, которые могут выиграть от истории или трендов от других сущностей. Многие модели и иерархические прогнозы временных рядов — это решения на базе автоматизированного машинного обучения для этих сценариев прогнозирования в большом масштабе.
Многие модели
Решение "Машинное обучение Azure" со многими моделями с автоматизированным машинным обучением позволяет пользователям параллельно обучать миллионы моделей и управлять ими. Многие модели Акселератор решений использует конвейеры Машинное обучение Azure для обучения модели. В частности, используется объект "Конвейер и ParalleRunStep, и для них требуются определенные параметры конфигурации, задаваемые через ParallelRunConfig.
На следующей диаграмме показан рабочий процесс для решения со многими моделями.

В следующем коде показаны ключевые параметры, необходимые пользователям для настройки запуска своих многих моделей. Пример прогнозирования со многими моделями см. в записной книжке по автоматизированному машинному обучению со многими моделями
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
Прогнозирование иерархических временных рядов
В большинстве приложений клиентам требуется понять свои прогнозы на макросе и микроуровневом уровне бизнеса. Forcasts может быть прогнозирование продаж продуктов в разных географических местах или понимание ожидаемого спроса на рабочую силу для различных организаций в компании. Возможность обучения модели машинного обучения для интеллектуального прогнозирования данных иерархии очень важно.
Иерархический временный ряд — это структура, в которой каждая из уникальных рядов организована в иерархию на основе таких измерений, как география или тип продукта. В следующем примере показаны данные с уникальными атрибутами, которые формируют иерархию. Наша иерархия определяется следующим образом: тип продукта, например наушники или планшеты, категория продукта, которая разделяет типы продуктов на аксессуары и устройства, а также регион, в котором продаются продукты.

Чтобы продолжить визуализацию, конечные уровни иерархии содержат все временные ряды с уникальными сочетаниями значений атрибутов. Каждый более высокий уровень иерархии рассматривает одно меньшее измерение для определения временных рядов и объединяет каждый набор дочерних узлов с более низкого уровня в родительский узел.

Иерархическое решение временных рядов построено на основе решения со многими моделями и имеет аналогичную настройку конфигурации.
В следующем коде показаны ключевые параметры для настройки иерархических запусков прогнозирования временных рядов. Сквозной пример см. в записной книжке по автоматизированному машинному обучению с иерархическими временными рядами.
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
Примеры записных книжек
Подробные примеры кода для расширенной настройки прогнозирования см. в записных книжках примеров прогнозирования, в том числе:
- контроль сплошности и конструирование признаков;
- перекрестная проверка источников скользящего прогноза;
- настраиваемые задержки;
- признаки для скользящих агрегатов значений окна;
Следующие шаги
- Узнайте больше о развертывании модели AutoML в подключенной конечной точке.
- Узнайте о том, что такое интерпретируемость: пояснения к модели в автоматизированном машинном обучении (предварительная версия).
- Узнайте, как AutoML создает модели прогнозирования.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по