Оценка результатов экспериментов с автоматизированным машинным обучением
Из этой статьи вы узнаете, как оценивать и сравнивать модели, обученные в ходе эксперимента с автоматизированным машинным обучением (автоматизированное ML). В ходе эксперимента с автоматизированным ML выполняется множество задания, и каждое задание создает модель. Для каждой модели автоматизированное ML создает метрики и диаграммы оценки, которые помогают измерять производительность модели. Вы можете также создать панель мониторинга ответственного искусственного интеллекта, чтобы выполнить целостную оценку и отладку рекомендуемой оптимальной модели по умолчанию. К ним относятся аналитические сведения, такие как объяснения модели, справедливость и обозреватель производительности, обозреватель данных, анализ ошибок модели. Узнайте больше о том, как создать панель мониторинга ответственного искусственного интеллекта.
Например, автоматизированное ML создает следующие диаграммы в зависимости от типа эксперимента.
Важно!
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Предварительная версия предоставляется без соглашения об уровне обслуживания и не рекомендована для производственных рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Необходимые компоненты
- Подписка Azure. (Если у вас еще нет подписки Azure, создайте бесплатную учетную запись, прежде чем начинать работу)
- Эксперимент Машинное обучение Azure, созданный с помощью одного из следующих вариантов:
- Студия машинного обучения Azure (программирование не требуется)
- Пакет SDK Python для машинного обучения Azure
Просмотр результатов заданий
После завершения эксперимента с автоматизированным ML журнал заданий можно найти следующим образом:
- Браузер в студии машинного обучения Azure
- Записная книжка Jupyter с мини-приложением JobDetails Jupyter
Следующие шаги и видео показывают, как просмотреть журнал выполнения, а также метрики и диаграммы оценки модели в студии:
- Войдите в студию и перейдите к рабочей области.
- В меню слева выберите "Задания".
- Выберите эксперимент из списка экспериментов.
- В таблице в нижней части страницы выберите выполнение задания автоматизированного ML.
- На вкладке Модели выберите Имя алгоритма для модели, которую необходимо оценить.
- На вкладке Метрики используйте флажки слева, чтобы просмотреть метрики и диаграммы.
Метрики классификации
Автоматизированное ML вычисляет метрики производительности для каждой модели классификации, создаваемой для вашего эксперимента. Эти метрики основаны на реализации Scikit-learn.
Многие метрики классификации определены для двоичной классификации в двух классах и требуют усреднения по классам для получения одной оценки для многоклассовой классификации. Scikit-learn предоставляет несколько методов усреднения, три из которых раскрываются при автоматизированном ML: макро, микро и взвешенный.
- Макро — вычисление метрики для каждого класса и получение невзвешенного среднего
- Микро — расчет метрики на глобальном уровне путем подсчета итоговых истинных положительных результатов, ложноотрицательных и ложноположительных результатов (независимо от классов).
- Взвешенный — вычисление метрик для каждого класса и получение взвешенного среднего по числу выборок на каждый класс.
Хотя каждый метод усреднения имеет свои преимущества, одним из общих соображений при выборе соответствующего метода является дисбаланс классов. Если у классов разное количество выборок, более информативным может быть использование макроусреднения, при котором классам меньшинства и большинства назначается одинаковый вес. Дополнительные сведения о двоичных и многоклассовых метриках в автоматизированном ML.
В следующей таблице перечислены метрики производительности модели, которые автоматизированное ML вычисляет для каждой модели классификации, создаваемой для вашего эксперимента. Дополнительные сведения см. в документации по scikit-learn, ссылка на которую приводится в поле Вычисление каждой метрики.
Примечание.
Дополнительные сведения о метриках для моделей классификации изображений см. в разделе Метрики изображений.
| Метрическая | Description | Вычисление |
|---|---|---|
| Авг | AUC представляет собой область под кривой рабочих характеристик приемника (ROC). Цель: ближе к 1 лучше Диапазон: [0, 1] Поддерживаемые имена метрик включают в себя: AUC_macro — среднее арифметическое значение AUC для каждого класса.AUC_micro — вычисляется путем подсчета общего числа истинно положительных, ложноотрицательных и истинно отрицательных результатов. AUC_weighted — среднее арифметическое значение оценки для каждого класса, взвешенное по числу истинных экземпляров в каждом классе. AUC_binary — значение AUC, рассматривая один конкретный класс как класс true и объединяя все остальные классы как класс false. |
Вычисление |
| accuracy | Точность — это доля прогнозов, которые точно соответствуют истинным меткам класса. Цель: ближе к 1 лучше Диапазон: [0, 1] |
Вычисление |
| average_precision | Для вычисления средней точности используется кривая точности и полноты в качестве взвешенного среднего значения точности, полученного для каждого порогового значения, с увеличением полноты за счет предыдущего порогового значения, используемого в качестве весового коэффициента. Цель: ближе к 1 лучше Диапазон: [0, 1] Поддерживаются следующие имена метрик: average_precision_score_macro — арифметическое среднее значение точности оценки каждого класса.average_precision_score_micro — вычисляется путем подсчета общего числа истинно положительных, ложноотрицательных и истинно отрицательных результатов.average_precision_score_weighted — среднее арифметическое значение для средней оценки точности для каждого класса, взвешенное по числу истинных экземпляров в каждом классе. average_precision_score_binary — значение средней точности, рассматривая один конкретный класс как класс true и объединяя все остальные классы как класс false. |
Вычисление |
| balanced_accuracy | Сбалансированная точность — это среднее арифметическое значение полноты для каждого класса. Цель: ближе к 1 лучше Диапазон: [0, 1] |
Вычисление |
| f1_score | Оценка F1 — это среднее гармоническое значение точности и полноты. Это хорошая сбалансированная мера как ложноположительных, так и ложноотрицательных результатов. Однако она не учитывает истинные отрицательные результаты. Цель: ближе к 1 лучше Диапазон: [0, 1] Поддерживаются следующие имена метрик: f1_score_macro — среднее арифметическое показателя F1 для каждого класса. f1_score_micro — вычисляется путем подсчета общего числа истинно положительных, ложноотрицательных и истинно отрицательных результатов. f1_score_weighted — взвешенное среднее значение по частоте показателя F1 для каждого класса. f1_score_binary — значение F1, рассматривая один конкретный класс как класс true и объединяя все остальные классы как класс false. |
Вычисление |
| log_loss | Это функция потерь, используемая в логистической регрессии (полиномиальной) и ее дополнениях, например нейронных сетях, которая определяется как вероятность логистических потерь истинных меток для заданных прогнозов вероятностного классификатора. Цель: ближе к 0 лучше Диапазон: [0, ∞) |
Вычисление |
| norm_macro_recall | Нормализованная полнота макрозначений — это полнота макрозначений, усредненная и нормализованная таким образом, чтобы случайному выполнению соответствовала оценка 0, а идеальному выполнению — оценка 1. Цель: ближе к 1 лучше Диапазон: [0, 1] |
(recall_score_macro - R) / (1 - R) где R — ожидаемое значение recall_score_macro для случайных прогнозов.R = 0.5 для двоичной классификации. R = (1 / C) для проблем классификации C-класса. |
| matthews_correlation | Коэффициент корреляции Мэтьюса — это сбалансированная мера правильности, которую можно использовать, даже если один класс содержит гораздо больше выборок, чем другой. Коэффициент 1 обозначает идеальный прогноз, 0 — случайный прогноз, а –1 — обратный прогноз. Цель: ближе к 1 лучше Диапазон: [-1, 1] |
Вычисление |
| точность | Точность — это способность модели избежать пометки отрицательных выборок как положительных. Цель: ближе к 1 лучше Диапазон: [0, 1] Поддерживаемые имена метрик включают в себя: precision_score_macro — это среднее арифметическое значение точности для каждого класса. precision_score_micro — вычисляется глобально путем подсчета общего числа истинно положительных и ложноотрицательных результатов. precision_score_weighted — среднее арифметическое значение точности для каждого класса, взвешенное по числу истинных экземпляров в каждом классе. precision_score_binary — значение точности, рассматривая один конкретный класс как класс true и объединяя все остальные классы как класс false. |
Вычисление |
| отзыв | Полнота — это способность модели обнаруживать все положительные выборки. Цель: ближе к 1 лучше Диапазон: [0, 1] Поддерживаемые имена метрик включают в себя: recall_score_macro — среднее арифметическое значение полноты для каждого класса. recall_score_micro — вычисляется глобально путем подсчета общего числа истинно положительных, ложноотрицательных и ложноположительных результатов.recall_score_weighted — среднее арифметическое значение полноты для каждого класса, взвешенное по числу истинных экземпляров в каждом классе. recall_score_binary — значение полноты, рассматривая один конкретный класс как класс true и объединяя все остальные классы как класс false. |
Вычисление |
| weighted_accuracy | Взвешенная правильность — правильность, в которой взвешивание каждой выборки выполняется по общему количеству выборок, принадлежащих одному и тому же классу. Цель: ближе к 1 лучше Диапазон: [0, 1] |
Вычисление |
Метрики двоичной и многоклассовой классификации
Автоматизированное машинное обучение автоматически определяет, являются ли данные двоичными, а также позволяет пользователям активировать метрики двоичной классификации, даже если данные являются многоклассовыми, указав класс true. Метрики многоклассовой классификации сообщаются, если набор данных имеет два или более классов. Метрики двоичной классификации сообщаются только в том случае, если данные являются двоичными.
Обратите внимание, что метрики многоклассовой классификации предназначены для многоклассовой классификации. При применении к двоичному набору данных эти метрики не обрабатывают какой-либо класс как true класс, как можно ожидать. К метрикам, которые явно предназначены для многоклассовой классификации, добавляется суффикс micro, macro или weighted. Например, average_precision_score, f1_score, precision_score, recall_score и AUC. Например, вместо того, чтобы вычислять полноту как tp / (tp + fn), при многоклассовой средней полноте (micro, macro или weighted) усредняются оба класса в наборе данных двоичной классификации. Это эквивалентно вычислению полноты для класса true и класса false отдельно, а затем получению среднего от этих двух значений.
Кроме того, хотя автоматическое обнаружение двоичной классификации поддерживается, по-прежнему рекомендуется всегда указывать класс true вручную, чтобы обеспечить вычисление метрик двоичной классификации для правильного класса.
Чтобы активировать метрики для наборов данных двоичной классификации, когда сам набор данных является многоклассовым, пользователям нужно только указать класс, который будет рассматриваться как класс true, и эти метрики будут вычислены.
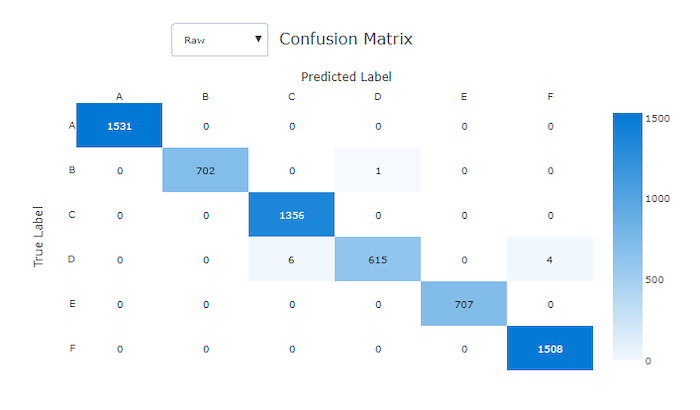
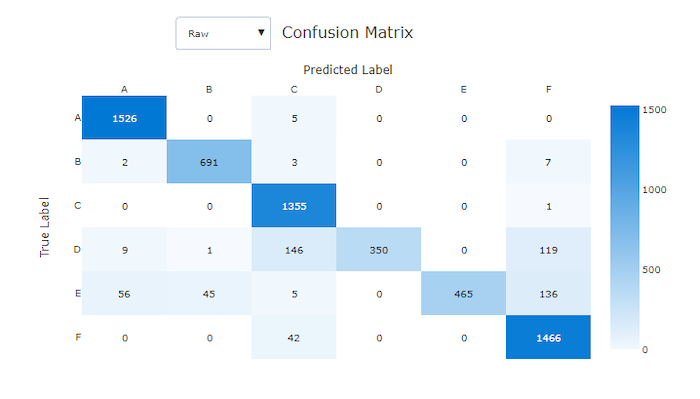
Матрица ошибок
Матрицы неточностей обеспечивают визуализацию того, как модель машинного обучения делает систематические ошибки в своих прогнозах для моделей классификации. Слово "неточность" в названии вызвано "неточностью" модели при распознавании или маркировке выборок. Ячейка в строке i и столбце j в матрице неточностей содержит количество выборок в наборе данных для оценки, принадлежащих классу C_i и отнесенных моделью к классу C_j.
В студии более темная ячейка указывает на большее число выборок. Выберите представление Нормализация в раскрывающемся списке, чтобы выполнить нормализацию каждой строки матрицы для отображения доли экземпляров класса C_i, которые по прогнозу считаются относящимися к классу C_j. Преимущество представления по умолчанию Без обработки состоит в том, что можно определить, является ли дисбаланс в распределении фактических классов причиной неправильной классификации выборок из класса меньшинства, что является распространенной проблемой в несбалансированных наборах данных.
В матрице несоответствия правильной модели большинство выборок будет находиться вдоль диагонали.
Матрица несоответствия для правильной модели
Матрица несоответствия для неправильной модели
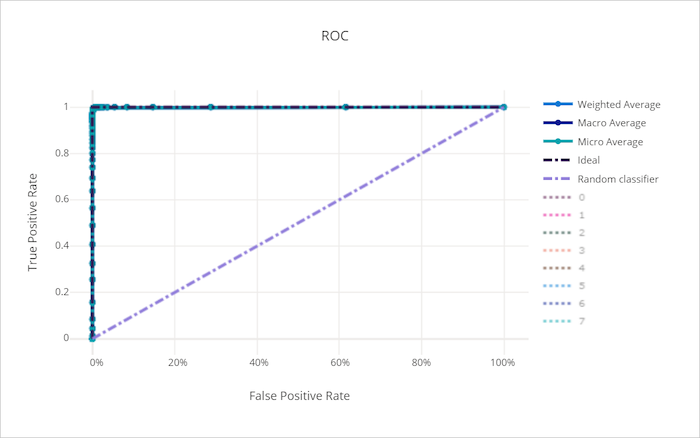
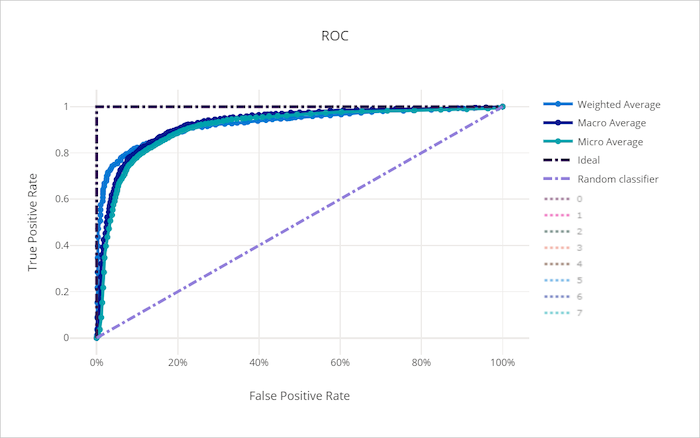
Кривая ROC
Кривая рабочей характеристики приемника (ROC) отображает связь между частотой истинно положительных результатов (TPR) и частотой ложноположительных результатов (FPR) при изменении порога принятия решения. Кривая ROC может быть менее информативной при обучении моделей на наборах данных с сильным дисбалансом классов, так как класс большинства может заглушать вклады из классов меньшинства.
Площадь под кривой (AUC) можно считать долей правильно классифицированных выборок. Точнее, AUC — вероятность того, что классификатор присвоит случайно выбранной положительной выборке более высокий приоритет, чем случайно выбранной отрицательной выборке. Форма кривой дает представление о взаимосвязи между TPR и FPR как о зависимости от порога классификации или границы принятия решения.
Кривая, которая приближается к левому верхнему углу графика, приближается к значениям 100 % TPR и 0 % FPR — наилучшая возможная модель. Случайная модель даст кривую ROC вдоль линии y = x из нижнего левого угла в верхний правый. В модели хуже случайной кривая ROC опустится ниже линии y = x.
Совет
Для экспериментов по классификации каждый из графиков, созданных для моделей автоматизированного машинного обучения, можно использовать для оценки модели по каждому классу или усреднения по всем классам. Можно переключаться между этими представлениями, нажимая на метки классов в условных обозначениях справа от графика.
Кривая ROC для правильной модели
Кривая ROC для неправильной модели
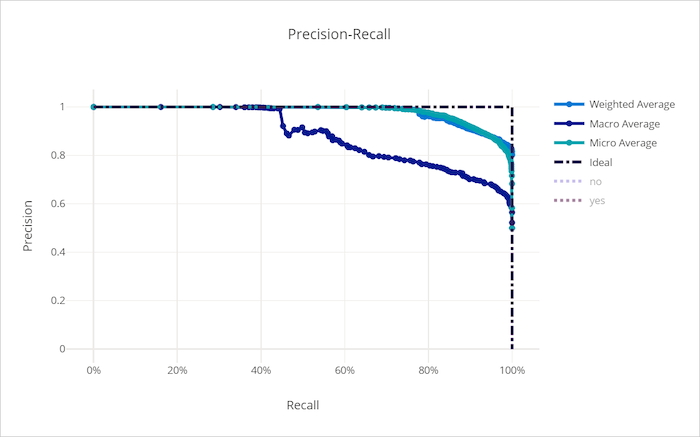
Кривая точность-полнота
Кривая точность-полнота отображает связь между точностью и полнотой при изменении порога принятия решения. Полнота — это способность модели обнаруживать все положительные выборки, а точность — это способность модели избежать пометки отрицательных выборок как положительных. Для решения некоторых бизнес-задач может потребоваться более высокая полнота, а для некоторых — более высокая точность, в зависимости от относительной важности предотвращения ложноотрицательных и ложноположительных результатов.
Совет
Для экспериментов по классификации каждый из графиков, созданных для моделей автоматизированного машинного обучения, можно использовать для оценки модели по каждому классу или усреднения по всем классам. Можно переключаться между этими представлениями, нажимая на метки классов в условных обозначениях справа от графика.
Кривая точность-полнота для правильной модели
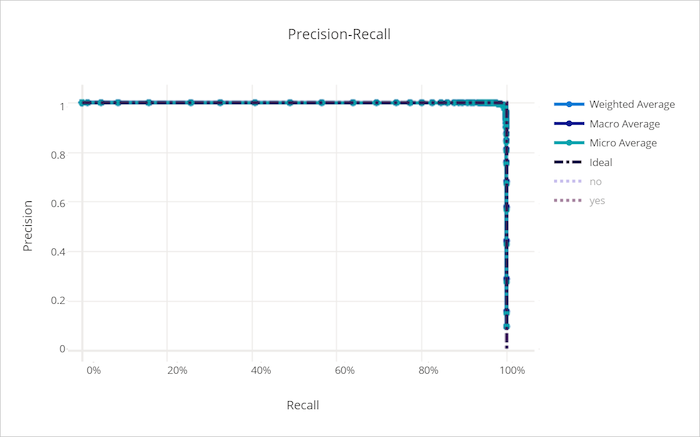
Кривая точность-полнота для неправильной модели
Кривая совокупного прироста
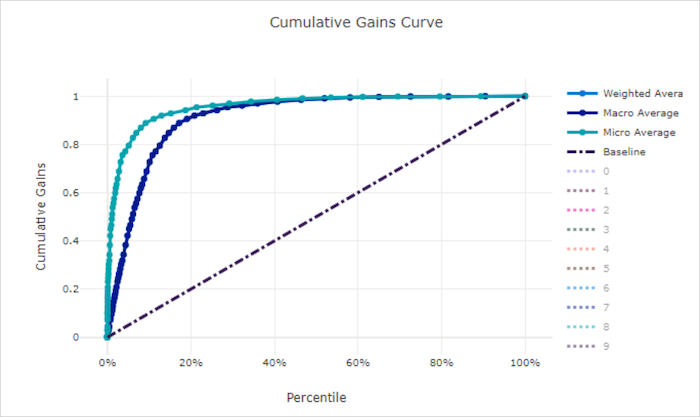
Кривая совокупного прироста отображает процент положительных выборок, которые правильно классифицированы среди рассмотренных выборок, если выборки рассматриваются в порядке уменьшения спрогнозированной вероятности.
Чтобы вычислить прирост, сначала отсортируйте все выборки по вероятности, спрогнозированной моделью, от наибольшей к наименьшей. Затем возьмите x% из наиболее достоверных прогнозов. Разделите число обнаруженных положительных выборок в x% на общее количество положительных выборок для получения прироста. Совокупный прирост — это процент положительных выборок, которые обнаруживаются при рассмотрении некоторого процента данных, которые, скорее всего, будут принадлежать к положительному классу.
Идеальная модель ранжирует все положительные выборки выше всех отрицательных выборок, давая кривую совокупного прироста, состоящую из двух прямых сегментов. Первый — это линия с наклоном 1 / x от (0, 0) до (x, 1), где x — доля выборок, принадлежащих к положительному классу (1 / num_classes, если классы сбалансированы). Второй — горизонтальная линия от (x, 1) до (1, 1). В первом сегменте все положительные выборки классифицируются правильно, а совокупный прирост становится равным 100% рамках первых x% рассматриваемых выборок.
В базовой случайной модели кривая совокупного прироста будет следовать y = x, тогда как для x% рассмотренных выборок было обнаружено только x% от общего количества положительных выборок. Идеальная модель для сбалансированного набора данных будет иметь кривую микросредних и линию макросредних, которая имеет наклон num_classes до тех пор, пока совокупный прирост не станет равен 100 %, а затем становится горизонтальной, пока доля данных не станет равна 100 %.
Совет
Для экспериментов по классификации каждый из графиков, созданных для моделей автоматизированного машинного обучения, можно использовать для оценки модели по каждому классу или усреднения по всем классам. Можно переключаться между этими представлениями, нажимая на метки классов в условных обозначениях справа от графика.
Кривая совокупного прироста для правильной модели
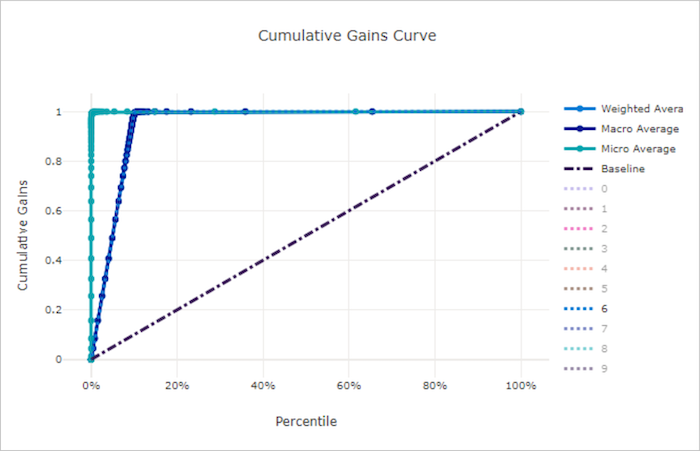
Кривая совокупного прироста для неправильной модели
кривая точности прогнозов;
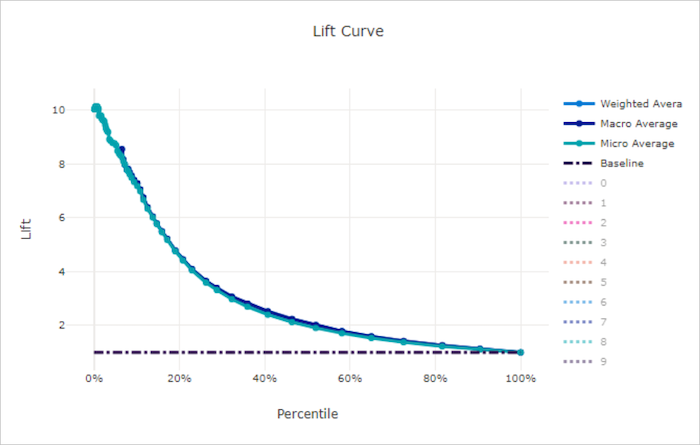
Кривая точности прогноза показывает, во сколько раз лучше работает модель по сравнению с случайной моделью. Точность прогноза определяется как отношение совокупного прироста к совокупному приросту случайной модели (который всегда должен быть равен 1).
Этот относительный показатель учитывает тот факт, что классификация усложняется по мере увеличения числа классов. (Случайная модель неправильно прогнозирует бОльшую долю выборок из набора данных с 10 классами по сравнению с набором данных с двумя классами)
Базовая кривая точности прогноза — это линия y = 1, для которой качество модели согласуется с качеством случайной модели. В целом, кривая точности прогноза для правильной модели будет выше на этой диаграмме и дальше от оси X. Это значит, что когда модель дает наиболее надежные прогнозы, она работает во много раз лучше, чем случайное угадывание.
Совет
Для экспериментов по классификации каждый из графиков, созданных для моделей автоматизированного машинного обучения, можно использовать для оценки модели по каждому классу или усреднения по всем классам. Можно переключаться между этими представлениями, нажимая на метки классов в условных обозначениях справа от графика.
Кривая точности прогноза для правильной модели
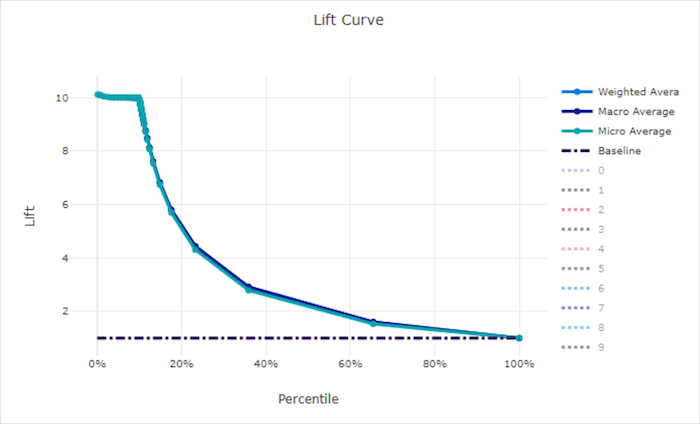
Кривая точности прогноза для неправильной модели
Кривая калибровки
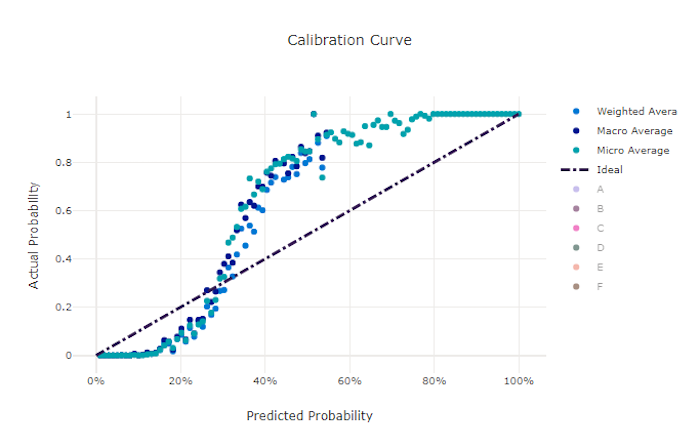
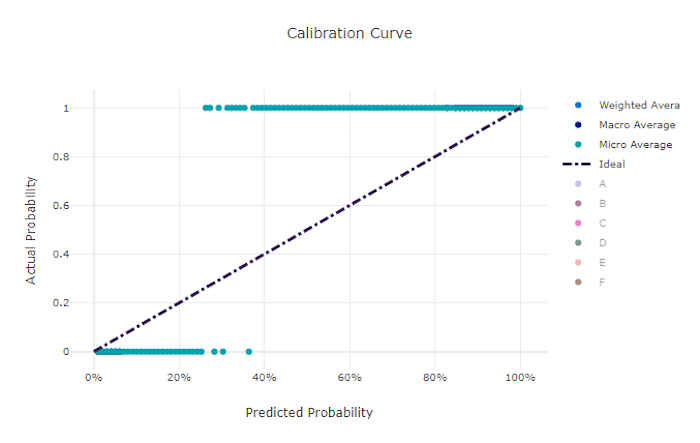
Кривая калибровки отображает уверенность модели в своих прогнозах относительно пропорции положительных выборок на каждом доверительном уровне. Хорошо откалиброванная модель правильно классифицирует 100 % прогнозов, которым она назначает достоверность 100 %, 50 % прогнозов, которым она назначает достоверность 50 %, 20 % прогнозов, которым она назначает достоверность 20 %, и т. д. Кривая калибровки идеально откалиброванной модели будет совпадать с линией y = x, причем модель будет идеально прогнозировать вероятность того, что выборки принадлежат к каждому классу.
Модель с избыточной достоверностью будет слишком часто прогнозировать вероятности, близкие к нулю и единице, и редко не будет уверена насчет класса каждой выборки, а кривая калибровки будет выглядеть как перевернутая буква "S". Модель с недостаточной достоверностью будет назначать в среднем меньшую вероятность классу, который она прогнозирует, и связанная кривая калибровки будет выглядеть примерно как буква "S". Кривая калибровки описывает не способность модели правильно выполнять классификацию, а ее способность правильно назначать достоверность своих прогнозов. Неправильная модель по-прежнему может иметь хорошую кривую калибровки, если модель правильно назначает низкую достоверность и высокую неопределенность.
Примечание.
Кривая калибровки чувствительна к числу выборок, поэтому небольшое валидационное множество может привести к результатам с большим количеством шумов, которые трудно интерпретировать. Это не обязательно означает, что модель неправильно откалибрована.
Кривая калибровки для правильной модели
Кривая калибровки для неправильной модели
Метрики регрессии / прогнозирования
Автоматизированное ML вычисляет одинаковые метрики качества для каждой создаваемой модели как для регрессионного, так и для прогнозного эксперимента. Эти метрики также прошли нормализацию, чтобы обеспечить сравнение моделей, обученных на данных с разными диапазонами. Дополнительные сведения см. в разделе Нормализация метрик.
В следующей таблице перечислены метрики качества модели, созданные для регрессионных и прогнозных экспериментов. Подобно метрикам классификации, эти метрики также основываются на реализациях scikit-learn. Ссылки на соответствующую документацию по scikit-learn приведены в поле Вычисление.
| Метрическая | Description | Вычисление |
|---|---|---|
| Объясненная дисперсия | Объяснимая дисперсия измеряет степень, в которой модель учитывает вариацию целевой переменной. Это процент уменьшения дисперсии исходных данных по отношению к дисперсии ошибок. Если среднее по ошибкам равно 0, то она равна коэффициенту детерминации (см. r2_score ниже). Цель: ближе к 1 лучше Диапазон: (-∞, 1] |
Вычисление |
| Средняя абсолютная погрешность | Средняя абсолютная погрешность — это оценочная величина абсолютного отклонения между целевым и прогнозируемым значениями. Цель: ближе к 0 лучше Диапазон: [0, inf) Типы: mean_absolute_error normalized_mean_absolute_error — mean_absolute_error, деленная на диапазон данных. |
Вычисление |
| Средняя абсолютная погрешность в процентах | Средняя абсолютная ошибка в процентах (MAPE) — это мера среднего различия между спрогнозированным значением и фактическим значением. Цель: ближе к 0 лучше Диапазон: [0, ∞) |
|
| Медианная абсолютная погрешность | Медиана абсолютной погрешности — это медиана всех абсолютных отклонений между целевым и прогнозируемым значениями. Такая потеря устойчива к выбросам. Цель: ближе к 0 лучше Диапазон: [0, ∞) Типы: median_absolute_errornormalized_median_absolute_error — median_absolute_error, деленная на диапазон данных. |
Вычисление |
| r2_score; | R2 (коэффициент детерминации) измеряет пропорциональное уменьшение в среднеквадратической погрешности (СКП) относительно общей дисперсии наблюдаемых данных. Цель: ближе к 1 лучше Диапазон: [-1, 1] Примечание. R2 часто находится в диапазоне (-∞, 1]. СКП может быть больше наблюдаемой дисперсии, поэтому R2 может иметь произвольно большие отрицательные значения в зависимости от данных и прогнозов модели. Автоматизированное ML ограничивает оценки R2 значением –1, поэтому значение –1 для R2, скорее всего, означает, что истинная оценка R2 меньше –1. Изучите значения других метрик и свойства данных при интерпретации отрицательной оценки R2. |
Вычисление |
| Среднеквадратическая погрешность | Корень среднеквадратической погрешности (КСКП) — это квадратный корень ожидаемого квадратичного отклонения между целевым и прогнозируемыми значениями. Для оценщика без смещения КСКП равен стандартному отклонению. Цель: ближе к 0 лучше Диапазон: [0, ∞) Типы: root_mean_squared_error normalized_root_mean_squared_error: root_mean_squared_error, деленная на диапазон данных. |
Вычисление |
| Среднеквадратическая логарифмическая погрешность | Среднеквадратическая логарифмическая погрешность — это квадратный корень ожидаемой квадратичной логарифмической погрешности. Цель: ближе к 0 лучше Диапазон: [0, inf) Типы: root_mean_squared_log_error normalized_root_mean_squared_log_error: root_mean_squared_log_error, деленная на диапазон данных. |
Вычисление |
| spearman_correlation | Корреляция Спирмена — это непараметрическая мера монотонности связи между двумя наборами данных. В отличие от корреляции Пирсона, для корреляции Спирмена не предполагается, что оба набора данных используют нормальное распределение. Как и другие коэффициенты корреляции, коэффициент Спирмена принимает значения от –1 до 1. Значение 0 означает отсутствие корреляции. Значения корреляции –1 и 1 означают точную монотонную взаимосвязь. Метрика Спирмена — это метрика упорядоченной корреляции, которая означает, что изменения в прогнозируемых или фактических значениях не будут приводить к изменению результата Спирмена, если они не меняют ранговый порядок прогнозируемых или фактических значений. Цель: ближе к 1 лучше Диапазон: [-1, 1] |
Вычисление |
Нормализация метрик
Автоматизированное машинное обучение нормализует регрессию и прогнозируемые метрики, которые позволяют сравнивать модели, обучаемые на данных с различными диапазонами. Модель, обученная на данных с большим диапазоном, имеет более высокую погрешность, чем та же модель, обученная на данных с меньшим диапазоном, если эта погрешность не нормализована.
Несмотря на то, что стандартный метод нормализации метрик погрешностей не существует, автоматизированное ML использует общий подход к разделению погрешностей по диапазону данных: normalized_error = error / (y_max - y_min)
Примечание.
Диапазон данных не сохраняется вместе с моделью. Если вы делаете вывод с одной и той же моделью в контрольном тестовом наборе, y_min и y_max могут измениться в соответствии с тестовыми данными, а нормализованные метрики могут не использоваться напрямую для сравнения производительности модели в обучающем и тестовом наборах. Вы можете передать значения y_min и y_max из обучающего набора, чтобы сравнение было адекватным.
Прогнозируемые метрики: нормализация и агрегирование
Вычисление метрик для оценки модели прогнозирования требует некоторых особых соображений, когда данные содержат несколько временных рядов. Существует два естественных варианта для агрегирования метрик в нескольких рядах:
- Средний макрос , в котором метрики оценки из каждой серии получают равный вес.
- Микро средний показатель , в котором метрики оценки для каждого прогноза имеют равный вес.
В этих случаях имеются прямые аналогии с макросами и микровредацией в многоклассовой классификации.
Различие между макросами и микросреднированием может быть важно при выборе основной метрики для выбора модели. Например, рассмотрим сценарий розничной торговли, в котором требуется прогнозировать спрос на выбор потребительских продуктов. Некоторые продукты продаются на гораздо более высоких объемах, чем другие. Если вы выберете микросреденную RMSE в качестве основной метрики, возможно, что элементы с большим объемом будут способствовать большинству ошибок моделирования и, следовательно, доминируют в метрике. Затем алгоритм выбора модели может использовать модели с более высокой точностью для элементов с большим объемом, чем на низком объеме. В отличие от этого, нормализованный RMSE макросов дает элементы с низким объемом примерно равный вес элементам с большим объемом.
В следующей таблице показано, какие метрики прогнозирования AutoML используют макрос и микро в среднем.
| Среднее значение макроса | Микросредн |
|---|---|
normalized_mean_absolute_error, normalized_median_absolute_error, normalized_root_mean_squared_error, normalized_root_mean_squared_log_error |
mean_absolute_error, median_absolute_error, root_mean_squared_error, root_mean_squared_log_error, r2_score, explained_variance, spearman_correlation, mean_absolute_percentage_error |
Обратите внимание, что метрики, усредненные макросами, нормализуют каждую серию отдельно. Нормализованные метрики из каждой серии затем усреднены, чтобы дать окончательный результат. Правильный выбор макроса и микро зависит от бизнес-сценария, но обычно рекомендуется использовать normalized_root_mean_squared_error.
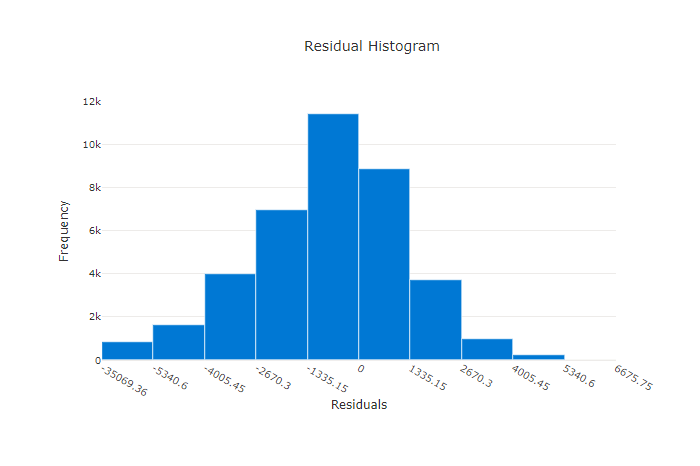
Остатки
Диаграмма остатков представляет собой гистограмму погрешностей прогнозов (остатков), созданных для экспериментов по регрессии и прогнозированию. Остатки рассчитываются как y_predicted - y_true для всех выборок, а затем отображаются в виде гистограммы для отображения смещения модели.
В этом примере обратите внимание, что обе модели немного смещены для прогнозирования значений ниже фактических. Такой принцип редко используется для набора данных с асимметричным распределением фактических целевых значений, но указывает на более низкое качество модели. Пик распределения остатков в правильной модели находится на нуле, а несколько остатков — на крайних значениях. Распределение остатков в менее качественной модели будет широким с меньшим числом выборок около нуля.
Диаграмма остатков для правильной модели
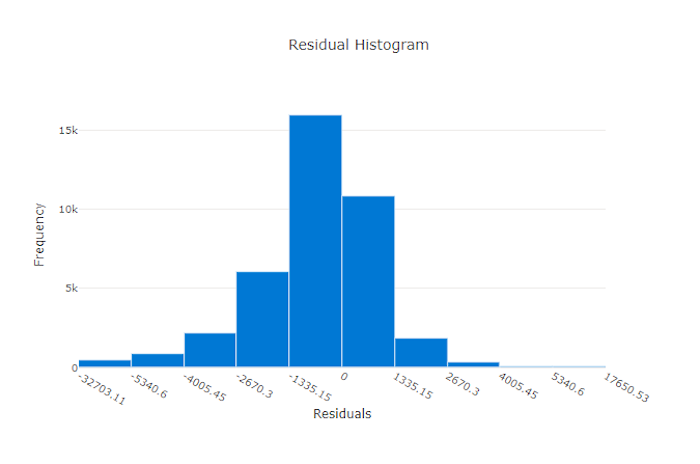
Диаграмма остатков для неправильной модели
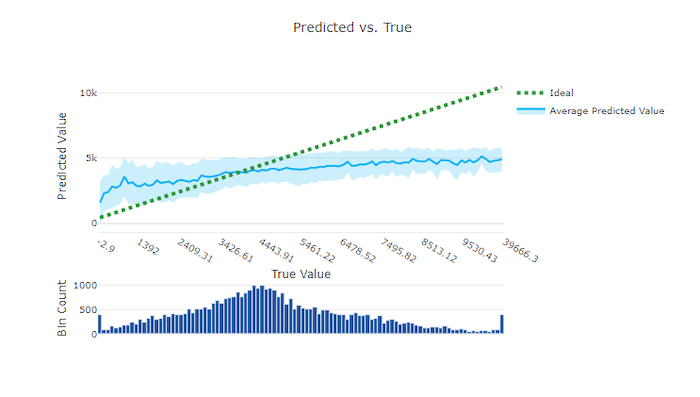
Прогнозируемые и истинные значения
Для эксперимента по регрессии и прогнозированию на диаграмме прогнозируемых и истинных значений видна связь между целевым признаком (истинными/фактическими значениями) и прогнозами модели. Истинные значения сгруппированы по оси X, и для каждой группы построено среднее спрогнозированное значение с планками погрешностей. Это позволяет определить, является ли модель более смещенной в сторону прогнозирования определенных значений. Линия показывает средний прогноз, а затененная область — дисперсию прогнозов вокруг этого среднего.
Часто наиболее распространенное истинное значение будет иметь наиболее точные прогнозы с наименьшей дисперсией. Расстояние от линии тренда от идеальной линии y = x, где существует несколько истинных значений, является хорошим показателем качества работы модели в отношении выбросов. Вы можете использовать гистограмму в нижней части графика, чтобы рассуждать о фактическом распределении данных. Дополнительные выборки данных, в которых распределение является разреженным, могут повысить качество модели на невидимых данных.
В этом примере обратите внимание, что у чем лучше модель, тем линия "прогнозируемые и истинные значения" ближе к идеальной линии y = x.
График "прогнозируемые и истинные значения" для правильной модели
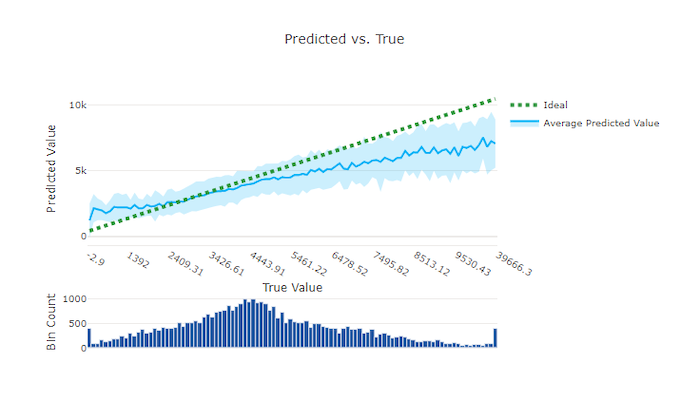
График "прогнозируемые и истинные значения" для неправильной модели
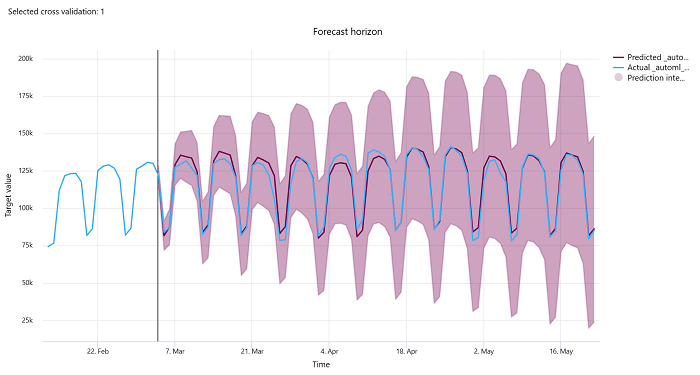
Горизонт прогнозирования
Для экспериментов прогнозирования диаграмма горизонта прогноза показывает связь между прогнозируемым значением моделей и фактическими значениями, сопоставленными со временем на свертывание перекрестной проверки со свертыванием, до 5 свертываний. Ось X сопоставляет время на основе частоты, предоставленной во время настройки обучения. Вертикальная линия на диаграмме помечает точку горизонта прогноза, которая также называется линией горизонта, то есть периодом времени, с которого вы хотите начать создавать прогнозы. Слева от линии горизонта прогноза можно просмотреть исторические данные обучения, чтобы лучше визуализировать прошлые тенденции. Справа от горизонта прогноза можно визуализировать прогнозы (фиолетовой линией) по фактическим данным (синей линией) для различных свертываний перекрестной проверки и идентификаторов временных рядов. Затененные фиолетовые области указывают доверительные интервалы или дисперсию прогнозов вокруг этого значения.
Чтобы выбрать комбинации идентификаторов временных рядов и свертываний перекрестной проверки, щелкните значок редактирования в виде карандаша в правом верхнем углу диаграммы. Сделайте выбор, просмотрев первые 5 свертываний перекрестной проверки и до 20 различных идентификаторов временных рядов, чтобы визуализировать диаграмму для различных временных рядов.
Важно!
Эта диаграмма доступна в ходе обучения для моделей, созданных из данных обучения и проверки, а также в тестовом запуске на основе обучающих данных и тестовых данных. Мы разрешаем до 20 точек данных до источника прогноза и до 80 точек данных после источника прогноза. Для моделей DNN эта диаграмма в ходе обучения показывает данные из последней эпохи, т. е. после полного обучения модели. Эта диаграмма в тестовом запуске может иметь разрыв до линии горизонта, если данные проверки были явно предоставлены во время обучения. Это связано с тем, что данные обучения и тестовые данные используются в тестовом запуске, оставляя данные проверки, что приводит к разрыву.
Метрики для моделей изображений (предварительная версия)
Автоматизированное ML использует изображения из проверочного набора данных для оценки производительности модели. Производительность модели измеряется на уровне эпохи, чтобы понять, как выполняется обучение. Эпоха проходит, когда весь набор данных передается вперед и назад по нейронной сети ровно один раз.
Метрики классификации изображений
Основной метрикой для оценки является точность для двоичных и многоклассовых моделей классификации и IoU (пересечение по объединению) для моделей классификации по нескольким меткам. Метрики классификации для моделей классификации изображений аналогичны тем, которые определены в разделе метрики классификации. Также регистрируются значения потерь, связанные с эпохой, что может помочь отслеживать ход обучения и определять, является ли модель переобученной или недообученной.
Каждый прогноз из модели классификации связан с оценкой достоверности, которая указывает уровень достоверности, с которой был сделан прогноз. Модели классификации изображений по нескольким меткам по умолчанию оцениваются с пороговым значением 0,5, что означает, что только прогнозы, имеющие как минимум такой уровень достоверности, будут рассматриваться как положительный прогноз для связанного класса. Многоклассовая классификация не использует пороговое значение оценки, вместо этого в качестве прогноза рассматривается класс с максимальной оценкой достоверности.
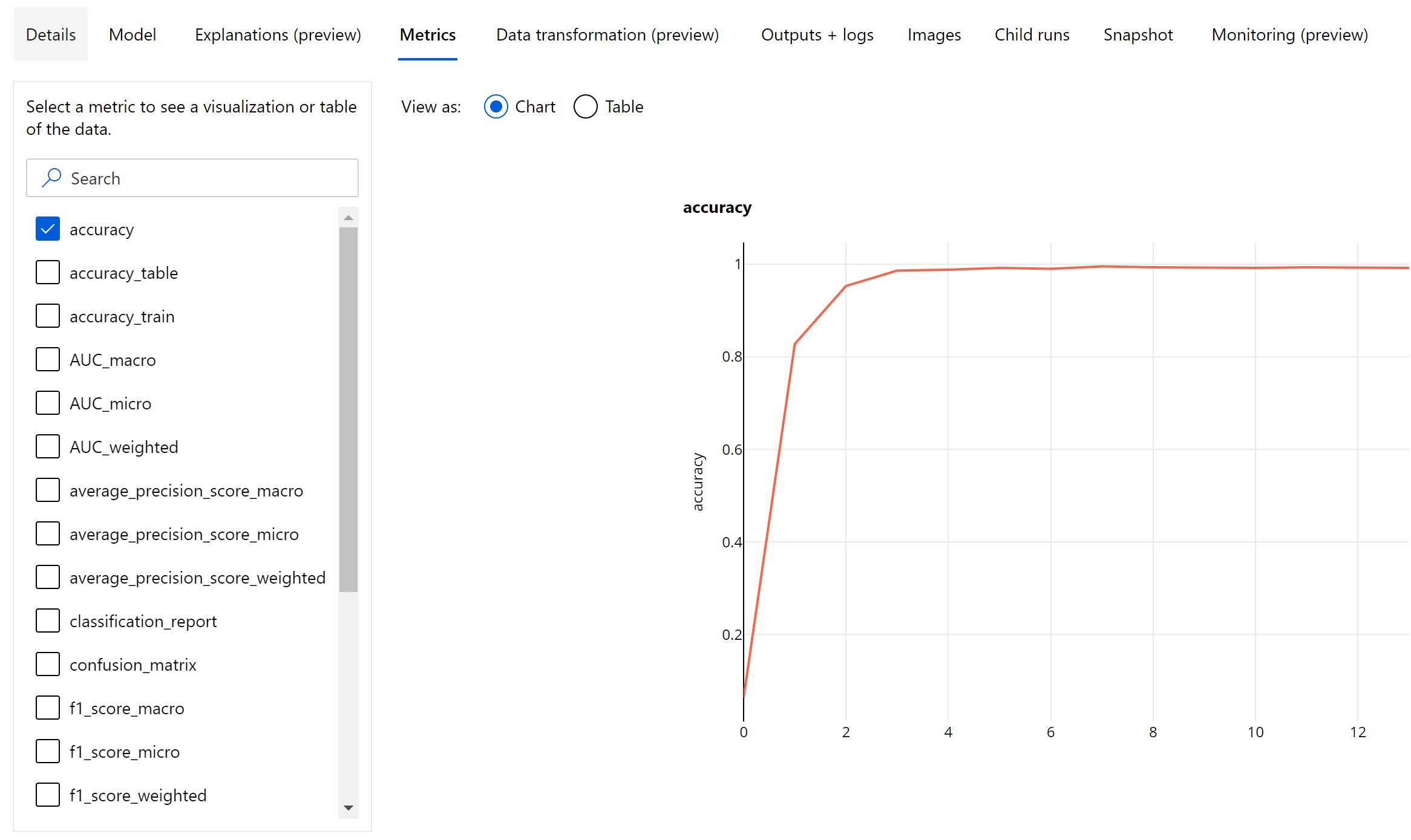
Метрики уровня эпохи для классификации изображений
В отличие от метрик классификации для табличных наборов данных, модели классификации изображений регистрируют все метрики классификации на уровне эпохи, как показано ниже.
Сводные метрики для классификации изображений
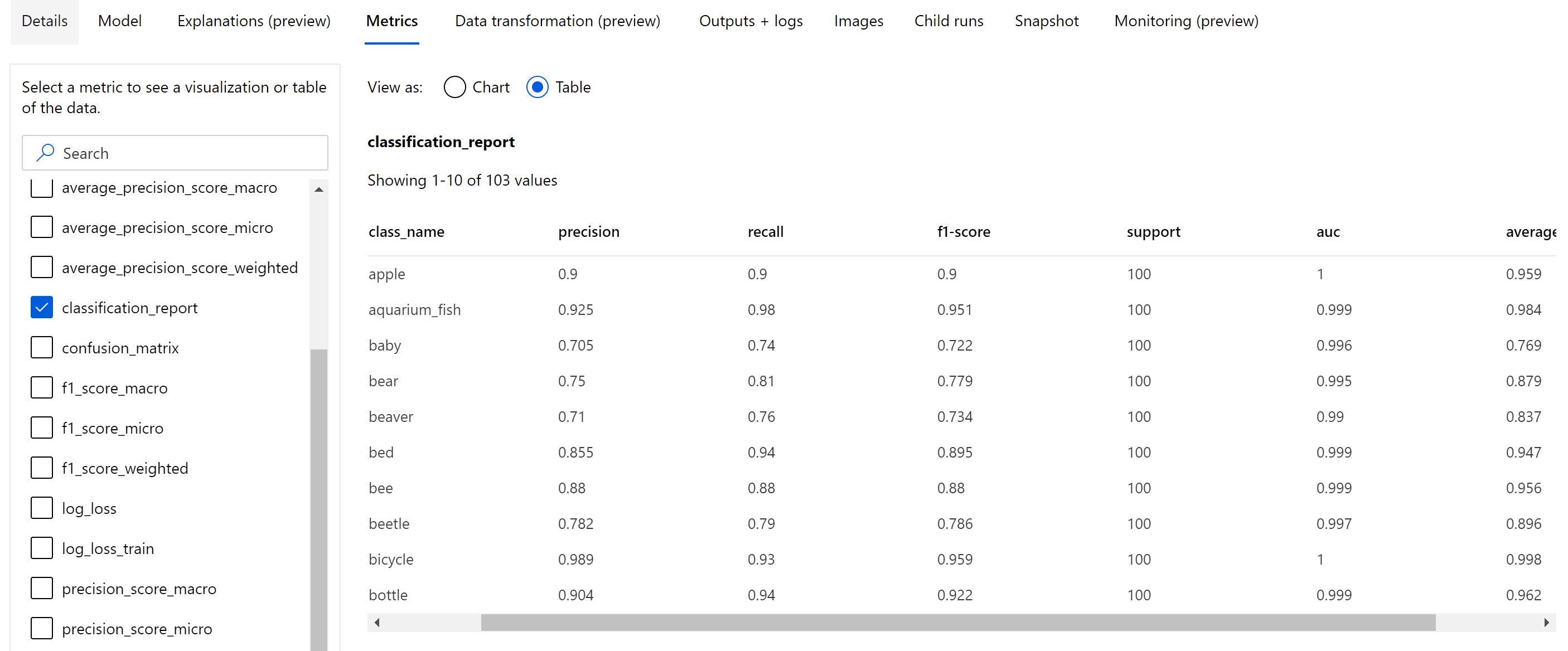
Помимо скалярных метрик, которые регистрируются на уровне эпохи, модель классификации изображений также регистрирует сводные метрики, такие как матрица неточностей, диаграммы классификации, включая кривую ROC, кривую точности-полноты и отчет о классификации для модели из лучшей эпохи, в которой мы получаем наивысшую оценку основной метрики (точности).
Отчет о классификации предоставляет значения на уровне класса для таких метрик, как точность, полнота, показатель f1, поддержка, auc и average_precision с различным уровнем усреднения — микро-, макро- и взвешенным, как показано ниже. См. определения метрик в разделе Метрики классификации.
Метрики обнаружения объектов и сегментации экземпляров
Каждый прогноз из модели обнаружения объектов изображений или сегментации экземпляров связан с оценкой достоверности.
Прогнозы с оценкой достоверности, превышающей пороговое значение, выводятся в виде прогнозов и используются при вычислении метрики, значение по умолчанию которой зависит от модели и может быть указано на странице Настройка гиперпараметров (гиперпараметр box_score_threshold).
Вычисление метрик модели обнаружения объектов изображений и сегментации экземпляров основано на измерении перекрытия, определяемом метрикой, называемой IoU (пересечение по объединению), которая вычисляется путем деления области перекрытия между наземной истиной и прогнозами на область объединения наземной истины и прогнозов. Показатель IoU, вычисляемый из каждого прогноза, сравнивается с пороговым значением перекрытия, называемым пороговым значением IoU, которое определяет, насколько прогноз должен перекрываться с аннотированной пользователем наземной истиной, чтобы считаться положительным прогнозом. Если IoU, вычисленный из прогноза, меньше порогового значения перекрытия, прогноз не будет рассматриваться как положительный прогноз для связанного класса.
Основной метрикой для оценки моделей обнаружения объектов изображений и сегментации экземпляров является усредненная точность (mAP). mAP — это среднее значение средней точности (AP) по всем классам. Модели обнаружения объектов автоматизированного ML поддерживают вычисление mAP с использованием следующих двух популярных методов.
Метрики Pascal VOC:
mAP Pascal VOC — это способ вычисления mAP по умолчанию для моделей обнаружения объектов или сегментации экземпляров. Способ вычисления mAP в стиле Pascal VOC вычисляет площадь под версией кривой точности-полноты. Сначала показатель p (rᵢ), который представляет собой точность при полноте i, вычисляется для всех уникальных значений полноты. Затем p (rᵢ) заменяется максимальным значением точности, полученным для любого значения полноты r '> = rᵢ. Значение точности монотонно уменьшается в этой версии кривой. Метрика mAP для Pascal VOC по умолчанию вычисляется с пороговым значением IoU, равным 0,5. Подробное описание этой концепции можно найти в этом блоге.
Метрики COCO:
Метод оценки COCO использует метод интерполяции по 101 точке для расчета AP, а также усреднение по десяти пороговым значениям IoU. AP@[.5:.95] соответствует среднему AP для IoU от 0,5 до 0,95 с размером шага 0,05. Автоматизированное машинное обучение регистрирует все двенадцать метрик, определенных методом COCO, включая AP и AR (средняя полнота) на различных шкалах в журналах приложений, в то время как пользовательский интерфейс метрик показывает только mAP при пороговом значении IoU, равным 0,5.
Совет
Оценка модели обнаружения объектов изображений может использовать метрики COCO, если для гиперпараметра validation_metric_type задано значение COCO, как описано в разделе Настройка гиперпараметров.
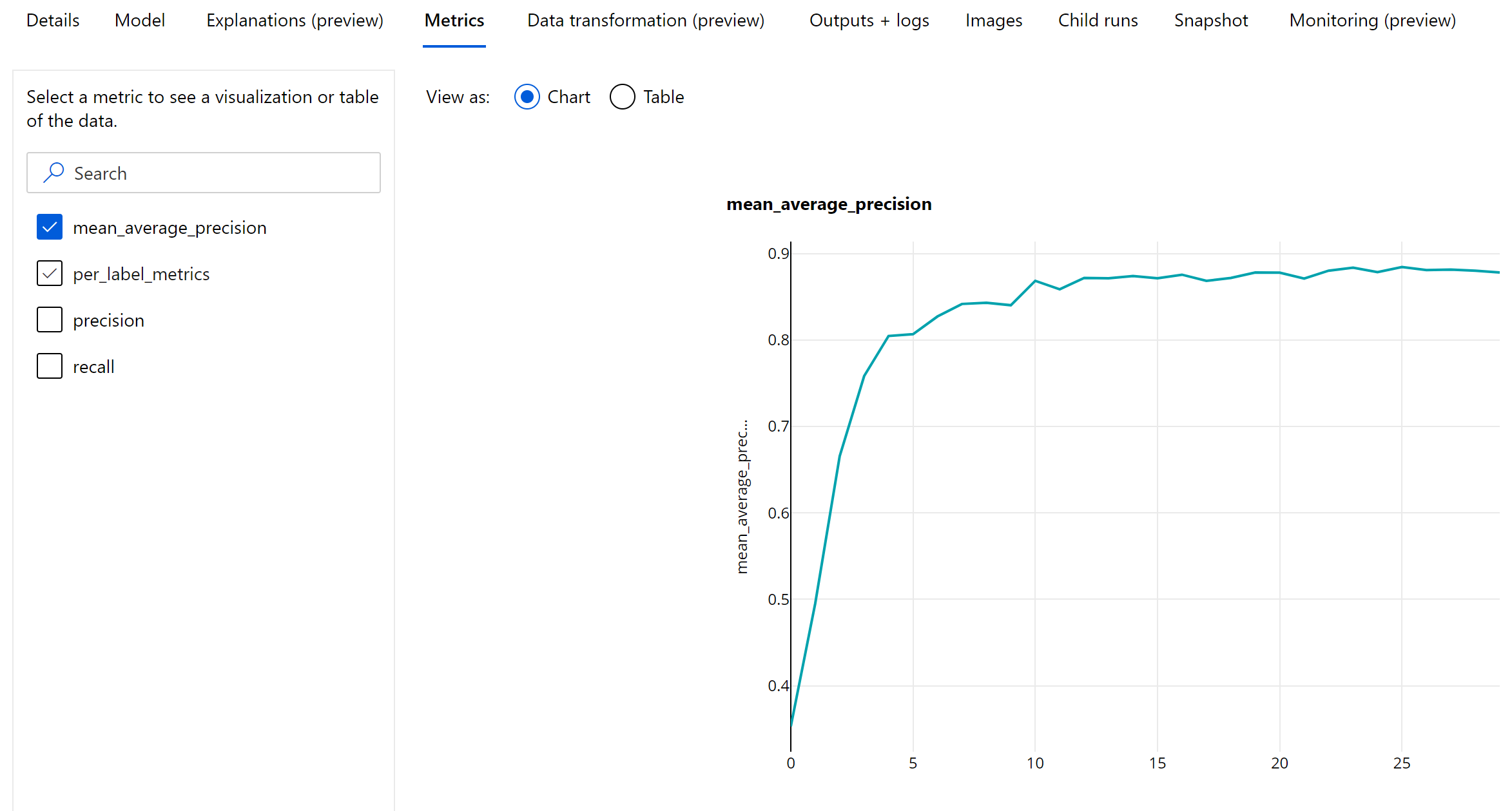
Метрики уровня эпохи для обнаружения объектов и сегментации экземпляров
Значения mAP, точности и полноты регистрируются на уровне эпохи для моделей обнаружения объектов изображений или сегментации экземпляров. Метрики mAP, точности и полноты также регистрируются на уровне класса с именем per_label_metrics. Per_label_metrics следует просматривать в виде таблицы.
Примечание.
Метрики уровня эпохи для точности, полноты и per_label_metrics недоступны при использовании метода COCO.
Информационная панель ответственного искусственного интеллекта для оптимальной рекомендуемой модели AutoML (предварительная версия)
Панель мониторинга ответственного ИИ Машинное обучение Azure предоставляет единый интерфейс для эффективного и эффективного внедрения ответственного ИИ. Панель мониторинга ответственного искусственного интеллекта поддерживается только с использованием табличных данных и поддерживается только в моделях классификации и регрессии. Она объединяет несколько зрелых средств ответственного искусственного интеллекта в областях:
- Оценка производительности и справедливости модели
- изучение данных
- Интерпретация машинного обучения
- Анализ ошибок
Хотя метрики и диаграммы оценки модели хорошо подходят для измерения общего качества модели, такие операции, как проверка справедливости модели, просмотр его объяснений (также известных как функции набора данных, используемого для прогнозирования), проверка ошибок и потенциальных слепых пятен важны при практике ответственного ИИ. Поэтому автоматизированное машинное обучение предоставляет панель мониторинга ответственного искусственного интеллекта, которая поможет вам наблюдать за различными аналитическими сведениями для модели. Узнайте, как просмотреть панель мониторинга ответственного ИИ в Студия машинного обучения Azure.
Узнайте, как создать эту панель мониторинга с помощью пользовательского интерфейса или пакета SDK.
Пояснения к модели и важность признаков
Хотя метрики и диаграммы оценки модели хорошо подходят для измерения общего качества модели, проверяя, какие функции набора данных используются для прогнозирования, важно при практике ответственного ИИ. Именно поэтому автоматизированное Машинное обучение предоставляет панель мониторинга пояснений модели, чтобы измерить и сообщить об относительных вкладах признаков набора данных. См. сведения о Просмотре панели мониторинга "пояснений" в Студии машинного обучения Azure.
Примечание.
Интерпретируемость, объяснение для наилучшей модели недоступно для экспериментов по прогнозированию автоматизированного машинного обучения, для которых рекомендуются следующие алгоритмы в качестве наилучшей модели или ансамбля:
- TCNForecaster
- AutoArima
- ExponentialSmoothing
- Prophet
- Average
- Naive
- Seasonal Average
- Seasonal Naive
Следующие шаги
- Попробуйте объяснение модели автоматизированного машинного обучения — выборка записных книжек.
- Чтобы получить ответы на конкретные вопросы по автоматизированному ML, обратитесь в askautomatedml@microsoft.com.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по