Преобразование данных в конструкторе Машинного обучения Azure
В этой статье вы узнаете, как преобразовать и сохранить наборы данных в конструкторе Машинное обучение Azure, чтобы подготовить собственные данные для машинного обучения.
Вы будете использовать образец набора данных двоичной классификации дохода взрослых для подготовки двух наборов данных: одного набора данных, включающего сведения о переписи взрослых только из США, и другого набора данных, включающего данные переписи от взрослых, не являющихся США.
В этой статье вы узнаете, как выполнять следующие задачи.
- Преобразование набора данных для подготовки к обучению.
- Экспорт полученных наборов данных в хранилище данных.
- Просмотрите результаты.
Ознакомление с этим руководством обязательно для изучения статьи Переобучение моделей конструктора. В этой статье вы узнаете, как использовать преобразованные наборы данных для обучения нескольких моделей с параметрами конвейера.
Внимание
Если графические элементы, упомянутые в этом документе, не отображаются, например кнопки в студии или конструкторе, у вас может не быть правильного уровня разрешений для рабочей области. Обратитесь к администратору подписки Azure, чтобы убедиться, что вам предоставлен правильный уровень доступа. Дополнительные сведения см. в статье "Управление пользователями и ролями".
Преобразование набора данных
В этом разделе вы узнаете, как импортировать образец набора данных и разделить данные на наборы данных, отличные от США. Узнайте , как импортировать данные для получения дополнительных сведений о том, как импортировать собственные данные в конструктор.
Импорт данных
Чтобы импортировать пример набора данных, выполните следующие действия.
Войдите в Студия машинного обучения Azure и выберите рабочую область, которую вы хотите использовать.
Перейдите в конструктор. Выберите " Создать новый конвейер" с помощью классических предварительно созданных компонентов для создания нового конвейера
Слева от холста конвейера на вкладке "Компонент " разверните узел "Пример данных "
Перетащите набор данных двоичной классификации дохода взрослого населения на холст
Щелкните правой кнопкой мыши компонент набора данных о доходах для взрослых и выберите предварительный просмотр данных
В окне предварительного просмотра данных экспортируйте набор данных. Обратите особое внимание на значения столбцов "родной страны"
Разделение данных
В этом разделе описано, как использовать компонент split Data для идентификации и разделения строк, содержащих "США" в столбце "native-country"
Слева от холста на вкладке компонента разверните раздел преобразования данных и найдите компонент split Data
Перетащите компонент split Data на холст и удалите этот компонент под компонентом набора данных.
Подключение компонента набора данных к компоненту split Data
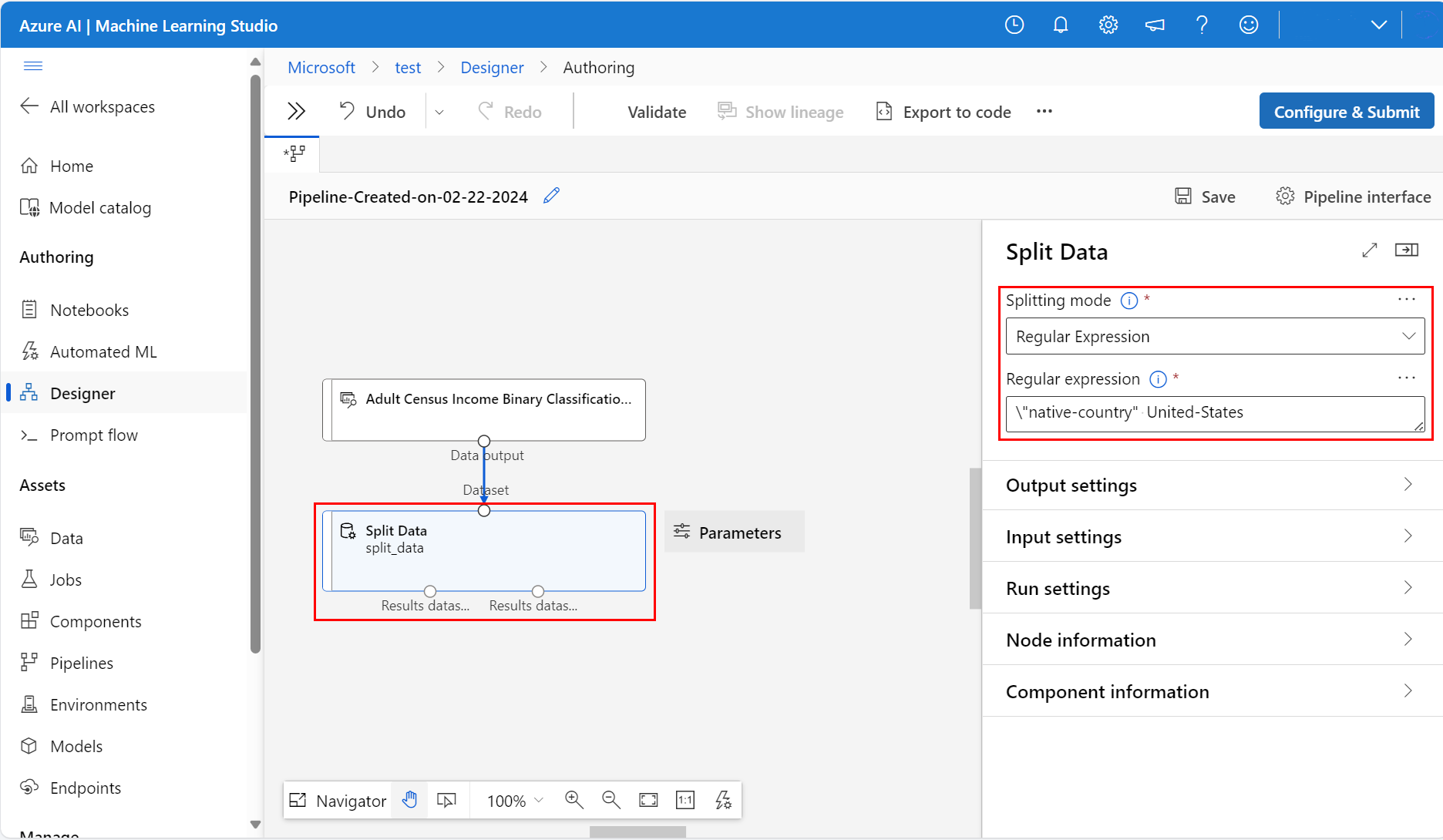
Выберите компонент "Разделить данные", чтобы открыть область "Разделение данных"
Справа от холста на значке "Параметры " задайте для режима разделения регулярное выражение
Введите регулярное выражение:
\"native-country" United-StatesРежим регулярное выражение проверяет значение в одном столбце. Дополнительные сведения о компоненте разделения данных см. на странице справки по компоненту компонента "Разделение данных"
Конвейер должен выглядеть следующим образом:
Сохранение наборов данных
Теперь, когда вы настроили конвейер для разделения данных, необходимо указать место хранения наборов данных. В этом примере используйте для сохранения набора данных в хранилище данных компонент "Экспорт данных". Дополнительные сведения о хранилищах см. в разделе "Подключение к службам хранилища Azure".
Слева от холста в палитре компонентов разверните раздел "Входные и выходные данные" и найдите компонент "Экспорт данных"
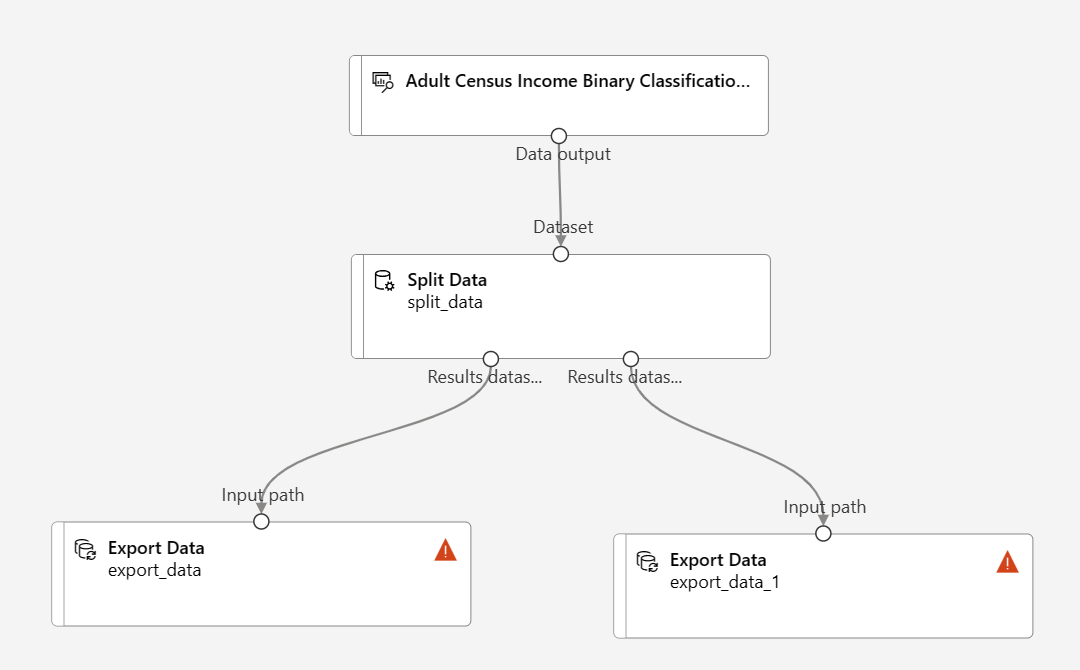
Перетащите два компонента экспорта данных под компонент "Разделение данных"
Подключение каждого выходного порта компонента split Data к другому компоненту экспорта данных
Конвейер должен выглядеть следующим образом:
Выберите компонент "Экспорт данных", подключенный к левому порту компонента "Разделить данные", чтобы открыть область "Конфигурация экспортируемых данных"
Для компонента split Data важно указать порядок портов вывода. Первый выходной порт содержит строки, в которых регулярное выражение имеет значение true. В этом случае первый порт содержит строки для дохода на основе США, а второй порт содержит строки для дохода, отличного от США.
В области сведений о компоненте справа от холста выберите следующие параметры:
Тип хранилища данных: Хранилище BLOB-объектов Azure
Хранилище данных: выберите существующее хранилище данных или нажмите кнопку "Создать хранилище данных", чтобы создать новую.
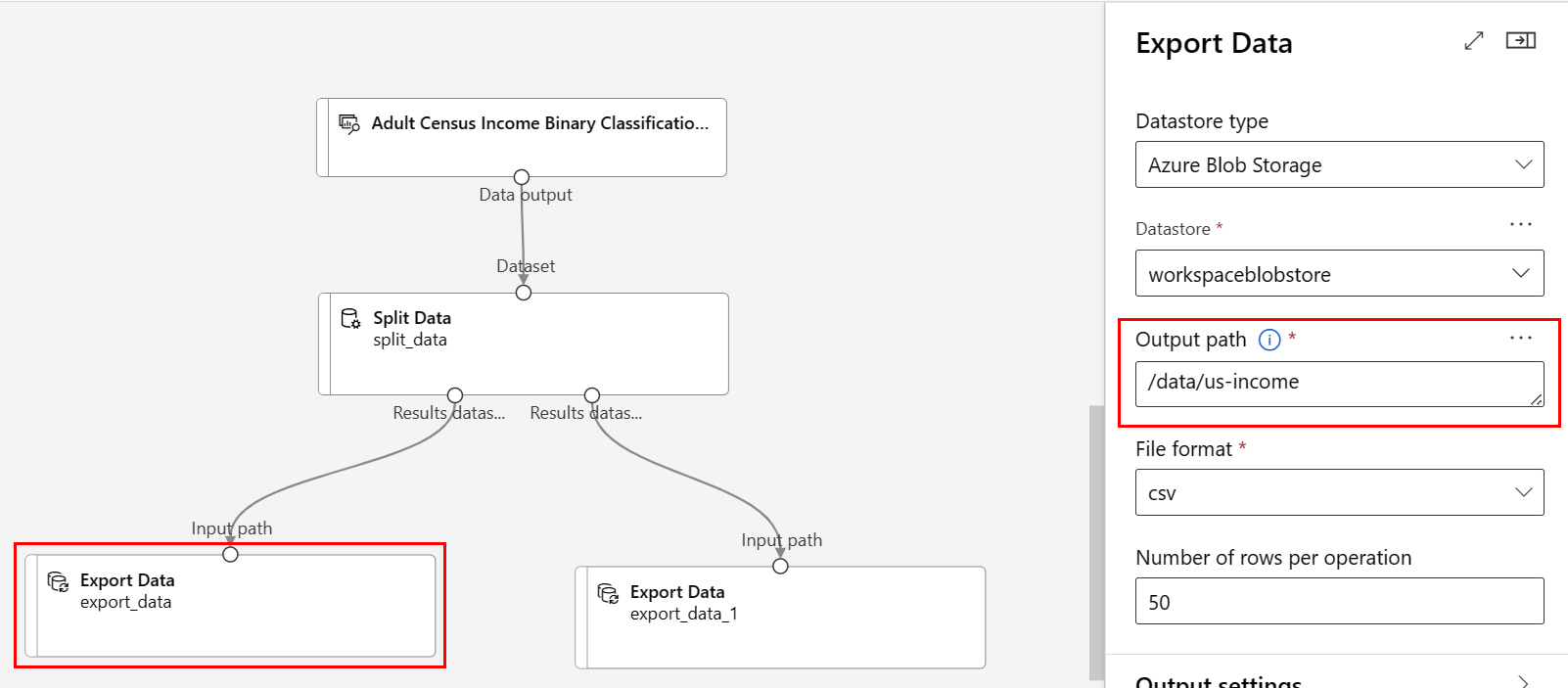
Путь:
/data/us-income.Формат файла: CSV.
Примечание.
В этой статье предполагается, что у вас есть доступ к хранилищу данных, зарегистрированному в текущей рабочей области Машинного обучения Azure. Ознакомьтесь со службами хранилища Azure для инструкций по настройке хранилища данных
Вы можете создать хранилище данных, если у вас нет хранилища данных. Например, эта статья сохраняет наборы данных в учетную запись хранения BLOB-объектов по умолчанию, связанную с рабочей областью. Он сохраняет наборы данных в
azuremlконтейнере в новой папке с именемdataВыберите компонент "Экспорт данных", подключенный к правому порту компонента "Разделить данные", чтобы открыть область конфигурации экспортируемых данных
Справа от холста в области сведений о компоненте задайте следующие параметры:
Тип хранилища данных: Хранилище BLOB-объектов Azure
Хранилище данных: выбор предыдущего хранилища данных
Путь:
/data/non-us-income.Формат файла: CSV.
Убедитесь, что компонент экспорта данных , подключенный к левому порту разделенных данных , имеет путь
/data/us-incomeУбедитесь, что компонент экспорта данных , подключенный к правому порту, имеет путь
/data/non-us-incomeТеперь конвейер и параметры будут выглядеть следующим образом:
отправить задание.
Теперь, когда конвейер настроен для разделения и экспорта данных, отправьте задание конвейера.
Выберите " Настройка" и "Отправить " в верхней части холста
Выберите параметр Create new в области "Основы" задания конвейера "Настройка конвейера", чтобы создать эксперимент
Эксперименты логически группирует связанные задания конвейера вместе. При запуске этого конвейера в будущем следует использовать тот же эксперимент для ведения журнала и отслеживания.
Укажите описательное имя эксперимента, например "split-census-data"
Выберите "Рецензирование и отправка", а затем нажмите кнопку "Отправить"
Показать результаты
После завершения работы конвейера можно перейти к хранилищу больших двоичных объектов портал Azure, чтобы просмотреть результаты. Вы также можете просмотреть промежуточные результаты компонента split Data , чтобы убедиться в правильности разделения данных.
Выберите компонент "Разделить данные"
В области сведений о компоненте справа от холста выберите вкладку "Выходные данные и журналы"
Выберите раскрывающийся список "Показать выходные данные"
Щелкните значок
 визуализации рядом с набором данных результатов1
визуализации рядом с набором данных результатов1Убедитесь, что столбец "native-country" содержит только значение "Соединенные Штаты"
Щелкните значок
визуализации рядом с набором данных Результатов2Убедитесь, что столбец "native-country" не содержит значение "Соединенные Штаты"
Очистка ресурсов
Чтобы продолжить работу с двумя частью этих моделей повторного обучения с помощью Машинное обучение Azure конструктора, пропустите этот раздел.
Внимание
Созданные ресурсы можно использовать в качестве необходимых компонентов для других учебников и статей с практическими рекомендациями по Машинному обучению Azure.
Удаление всех ресурсов
Если вы не планируете использовать созданные ресурсы, удалите всю группу ресурсов, чтобы с вас не взималась плата.
На портале Azure слева выберите Группы ресурсов.
В списке выберите созданную группу ресурсов.
Выберите команду Удалить группу ресурсов.
При удалении группы ресурсов будут также удалены все ресурсы, созданные в конструкторе.
Удаление отдельных ресурсов
В конструкторе, в котором вы создали эксперимент, удалите отдельные ресурсы, выбрав их и нажав кнопку Удалить.
Созданный вами целевой объект вычислений автоматически масштабируется до нуля узлов, когда он не используется. Это действие предпринимается для снижения расходов. Чтобы удалить целевой объект вычислений, сделайте следующее:
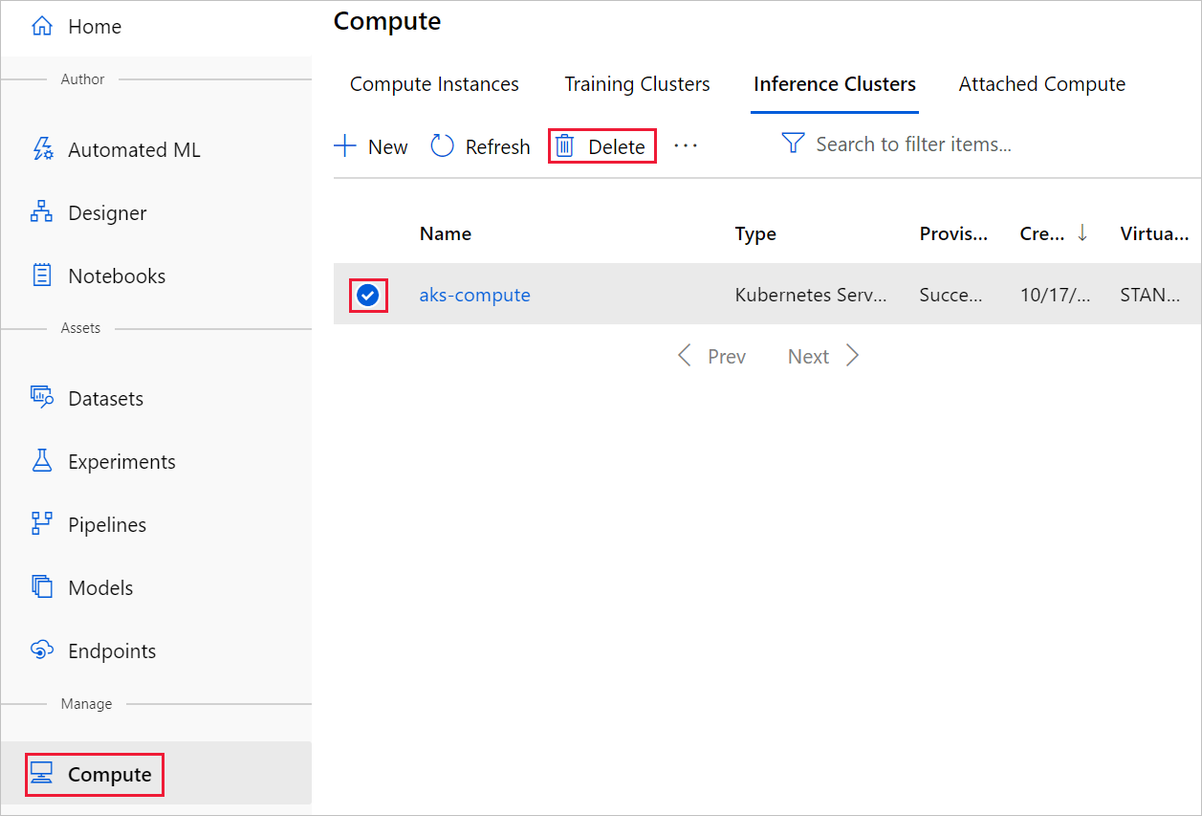
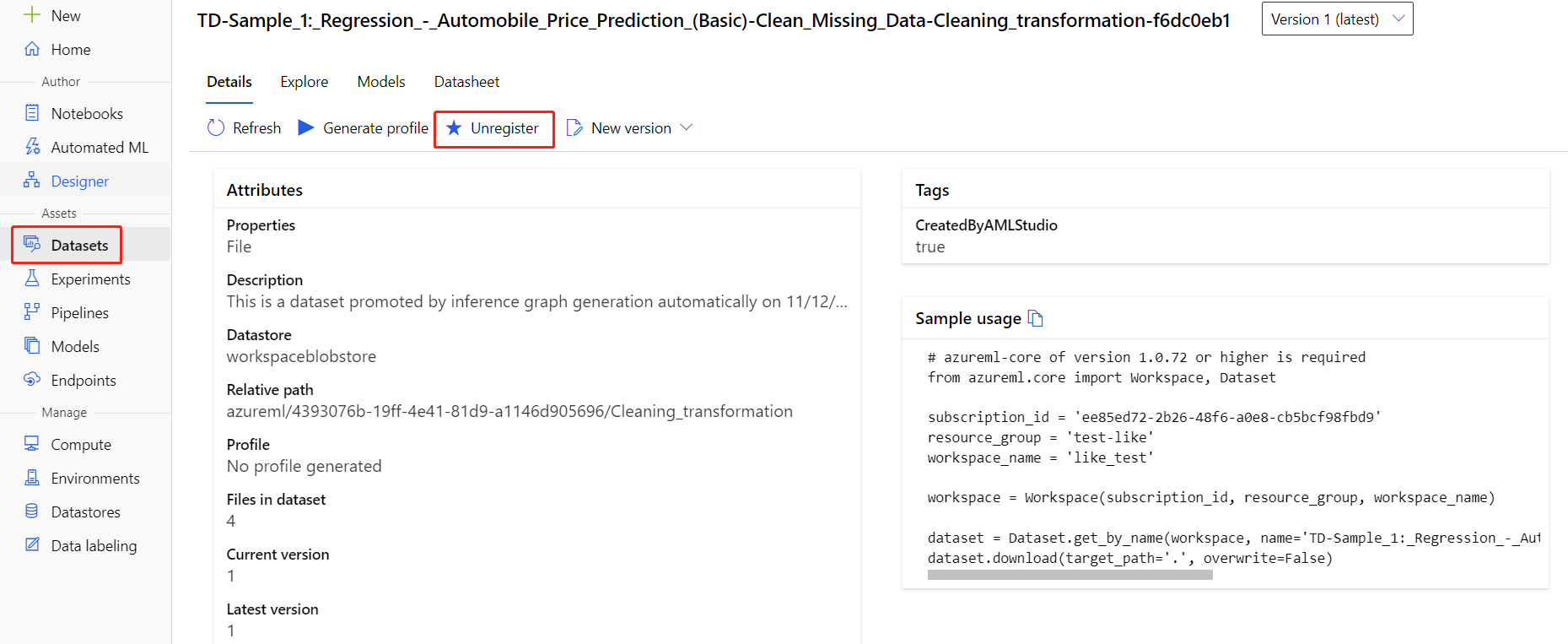
Вы можете отменить регистрацию наборов данных в рабочей области. Для этого выберите каждый набор данных и щелкните Отменить регистрацию.
Чтобы удалить набор данных, перейдите к учетной записи хранения на портале Azure или в приложении "Обозреватель службы хранилища Azure", а затем вручную удалите эти ресурсы.
Следующие шаги
Из этой статьи вы узнали, как преобразовать набор данных и сохранить его в зарегистрированном хранилище данных.
Перейдите к следующей части этой серии инструкций с переобучением моделей с помощью конструктора Машинное обучение Azure, чтобы использовать преобразованные наборы данных и параметры конвейера для обучения моделей машинного обучения.