В этой статье вы узнаете, как использовать Open Neural Network Exchange (ONNX) для прогнозирования моделей компьютерного зрения, созданных из автоматизированного машинного обучения (AutoML) в Машинное обучение Azure.
Чтобы использовать ONNX для прогнозов, необходимо:
Скачайте файлы модели ONNX из запуска обучения AutoML.
Изучите входные и выходные данные модели ONNX.
Подготовьте данные, чтобы они были в нужном формате для входных изображений.
Выполняйте вывод с помощью среды выполнения ONNX для Python.
Визуализируйте прогнозы для задач обнаружения объектов и сегментирования экземпляров.
ONNX — это открытый стандарт для моделей машинного обучения и глубокого обучения. Он обеспечивает импорт и экспорт модели (взаимодействие) на различных популярных платформах искусственного интеллекта. Для получения дополнительных сведений изучите проект ONNX GitHub.
Среда выполнения ONNX — это проект с открытым исходным кодом, поддерживающий межплатформенный вывод. Среда выполнения ONNX предоставляет API-интерфейсы на разных языках программирования (включая Python, C++, C#, C, Java и JavaScript). Эти API-интерфейсы можно использовать для вывода входных изображений. После экспорта модели в формат ONNX можно использовать эти API на любом языке программирования, который требуется вашему проекту.
В этом руководстве вы узнаете, как использовать API Python для среды выполнения ONNX для прогнозирования изображений для популярных задач визуального распознавания. Эти экспортированные модели ONNX можно использовать на разных языках.
Установите пакет onnxruntime. Методы в этой статье были протестированы с использованием версий от 1.3.0 до 1.8.0.
Скачивание файлов модели ONNX
Файлы модели ONNX можно скачать из AutoML с помощью пользовательского интерфейса студии Машинного обучения Azure или пакета SDK для языка Python для Машинного обучения Azure. Мы рекомендуем выполнить скачивание с помощью пакета SDK с именем эксперимента и идентификатором родительского запуска.
Студия машинного обучения Azure
В студии Машинного обучения Azure перейдите к эксперименту, используя гиперссылку на эксперимент, созданный в учебной записной книжке, или выберите имя эксперимента на вкладке Эксперименты в разделе Активы. Затем выберите лучший дочерний запуск.
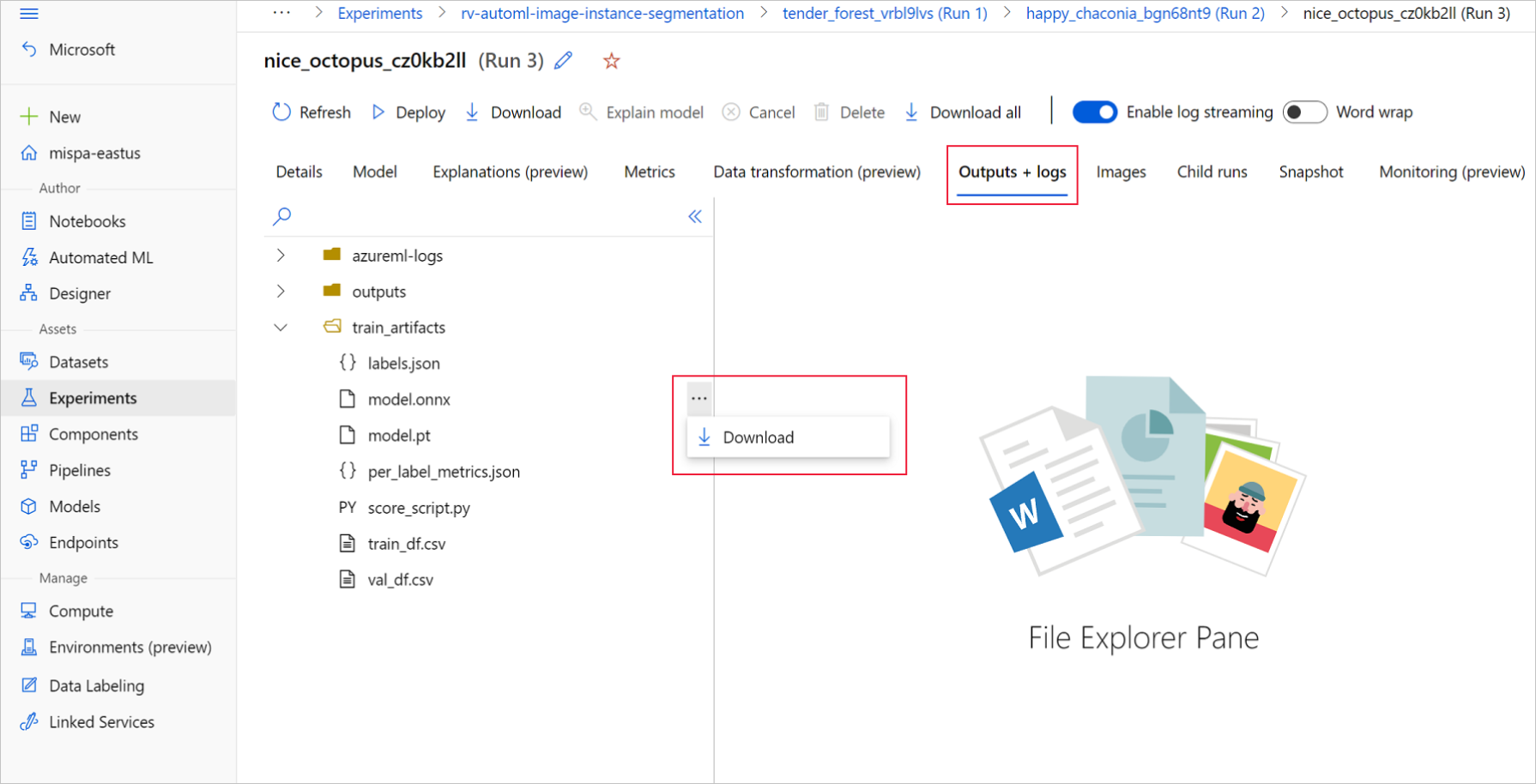
В рамках лучшего дочернего запуска перейдите к разделу Выходы и журналы>train_artifacts. Используйте кнопку Скачать, чтобы вручную скачать следующие файлы:
labels.json:файл, содержащий все классы или метки в наборе данных для обучения.
model.onnx: модель в формате ONNX.
Сохраните скачанные файлы модели в каталоге. В примере в этой статье используется каталог ./automl_models.
Пакет SDK Python для Машинного обучения Azure
С помощью пакета SDK можно выбрать лучший дочерний запуск (по основной метрике) с именем эксперимента и идентификатором родительского запуска. Затем можно скачать файлы labels.json и model.onnx.
Следующий код возвращает лучший дочерний запуск, основанный на соответствующей основной метрике.
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
mlflow_client = MlflowClient()
credential = DefaultAzureCredential()
ml_client = None
try:
ml_client = MLClient.from_config(credential)
except Exception as ex:
print(ex)
# Enter details of your Azure Machine Learning workspace
subscription_id = ''
resource_group = ''
workspace_name = ''
ml_client = MLClient(credential, subscription_id, resource_group, workspace_name)
import mlflow
from mlflow.tracking.client import MlflowClient
# Obtain the tracking URL from MLClient
MLFLOW_TRACKING_URI = ml_client.workspaces.get(
name=ml_client.workspace_name
).mlflow_tracking_uri
mlflow.set_tracking_uri(MLFLOW_TRACKING_URI)
# Specify the job name
job_name = ''
# Get the parent run
mlflow_parent_run = mlflow_client.get_run(job_name)
best_child_run_id = mlflow_parent_run.data.tags['automl_best_child_run_id']
# get the best child run
best_run = mlflow_client.get_run(best_child_run_id)
Скачайте файл labels.json, который содержит все классы и метки в наборе данных для обучения.
local_dir = './automl_models'
if not os.path.exists(local_dir):
os.mkdir(local_dir)
labels_file = mlflow_client.download_artifacts(
best_run.info.run_id, 'train_artifacts/labels.json', local_dir
)
В случае вывода пакета для обнаружения объектов и сегментации экземпляров с помощью моделей ONNX см. раздел о создании моделей для пакетной оценки.
Создание моделей для пакетной оценки
По умолчанию AutoML для образов поддерживает пакетную оценку для классификации. Однако модели ONYX для сегментации экземпляров и обнаружения объектов не поддерживают вывод пакетов. В случае вывода пакета для обнаружения объектов и сегментации экземпляров используйте следующую процедуру, чтобы создать модель ONNX для требуемого размера пакета. Модели, созданные для определенного размера пакета, не работают для других размеров пакетов.
Скачайте файл среды conda и создайте объект среды, который будет использоваться с командным заданием.
# Download conda file and define the environment
conda_file = mlflow_client.download_artifacts(
best_run.info.run_id, "outputs/conda_env_v_1_0_0.yml", local_dir
)
from azure.ai.ml.entities import Environment
env = Environment(
name="automl-images-env-onnx",
description="environment for automl images ONNX batch model generation",
image="mcr.microsoft.com/azureml/openmpi4.1.0-cuda11.1-cudnn8-ubuntu18.04",
conda_file=conda_file,
)
Чтобы получить значения аргументов, необходимые для создания модели пакетной оценки, обратитесь к скриптам оценки, созданным в папке выходных данных выполнения обучения AutoML. Используйте значения параметров, доступные в переменной настройки модели в файле оценки, для лучшего дочернего запуска.
Для классификации многоклассовых образов созданная модель ONNX для лучшего дочернего запуска по умолчанию поддерживает оценку пакетов. Поэтому для этого типа задачи не требуются аргументы конкретной модели. Можно перейти к разделу Загрузка файлов меток и модели ONNX.
Для классификации образов с несколькими метками созданная модель ONNX для лучшего дочернего запуска по умолчанию поддерживает оценку пакетов. Поэтому для этого типа задачи не требуются аргументы конкретной модели. Можно перейти к разделу Загрузка файлов меток и модели ONNX.
inputs = {'model_name': 'fasterrcnn_resnet34_fpn', # enter the faster rcnn or retinanet model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
inputs = {'model_name': 'yolov5', # enter the yolo model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 640, # enter the height of input to ONNX model
'width_onnx': 640, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'img_size': 640, # image size for inference
'model_size': 'small', # size of the yolo model
'box_score_thresh': 0.1, # threshold to return proposals with a classification score > box_score_thresh
'box_iou_thresh': 0.5
}
inputs = {'model_name': 'maskrcnn_resnet50_fpn', # enter the maskrcnn model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-instance-segmentation',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
Скачайте и сохраните файл ONNX_batch_model_generator_automl_for_images.py в текущем каталоге для отправки скрипта. Используйте следующее командное задание для отправки скрипта ONNX_batch_model_generator_automl_for_images.py, доступного в репозитории GitHub примеров AzureML, чтобы создать модель ONNX для определенного размера пакета. В следующем коде среда обученной модели используется для отправки этого скрипта для создания и сохранения модели ONNX в каталоге выходных данных.
Для классификации многоклассовых образов созданная модель ONNX для лучшего дочернего запуска по умолчанию поддерживает оценку пакетов. Поэтому для этого типа задачи не требуются аргументы конкретной модели. Можно перейти к разделу Загрузка файлов меток и модели ONNX.
Для классификации образов с несколькими метками созданная модель ONNX для лучшего дочернего запуска по умолчанию поддерживает оценку пакетов. Поэтому для этого типа задачи не требуются аргументы конкретной модели. Можно перейти к разделу Загрузка файлов меток и модели ONNX.
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-rcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --img_size ${{inputs.img_size}} --model_size ${{inputs.model_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_iou_thresh ${{inputs.box_iou_thresh}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-maskrcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
После создания модели пакетной службы загрузите ее из раздела Выходные данные и журналы>выходные данные вручную через пользовательский интерфейс или используйте следующий метод:
batch_size = 8 # use the batch size used to generate the model
returned_job_run = mlflow_client.get_run(returned_job.name)
# Download run's artifacts/outputs
onnx_model_path = mlflow_client.download_artifacts(
returned_job_run.info.run_id, 'outputs/model_'+str(batch_size)+'.onnx', local_dir
)
После завершения загрузки модели используйте пакет Python для среды выполнения ONNX для выполнения вывода с использованием файла model.onnx. В демонстрационных целях в этой статье используются наборы данных из раздела Порядок подготовки наборов данных образа для каждой задачи службы зрения.
Мы обучили модели для всех задач визуального зрения с соответствующими наборами данных, чтобы продемонстрировать вывод модели ONNX.
Загрузка файлов меток и модели ONNX
Следующий фрагмент кода загружает labels.json, где имена классов упорядочены. То есть, если модель ONNX прогнозирует идентификатор метки как 2, то она соответствует имени метки, заданному в третьем индексе в файле labels.json.
import json
import onnxruntime
labels_file = "automl_models/labels.json"
with open(labels_file) as f:
classes = json.load(f)
print(classes)
try:
session = onnxruntime.InferenceSession(onnx_model_path)
print("ONNX model loaded...")
except Exception as e:
print("Error loading ONNX file: ", str(e))
Получение ожидаемых входных и выходных данных для модели ONNX
При наличии модели важно иметь представление о некоторых особенностях конкретной модели и конкретных задач. Эти сведения включают число входов и количество выходов, ожидаемую форму входных данных или формат для предварительной обработки изображения и формы выходных данных, чтобы узнать, какие выходные данные относятся к конкретной модели или задаче.
sess_input = session.get_inputs()
sess_output = session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
for idx, input_ in enumerate(range(len(sess_input))):
input_name = sess_input[input_].name
input_shape = sess_input[input_].shape
input_type = sess_input[input_].type
print(f"{idx} Input name : { input_name }, Input shape : {input_shape}, \
Input type : {input_type}")
for idx, output in enumerate(range(len(sess_output))):
output_name = sess_output[output].name
output_shape = sess_output[output].shape
output_type = sess_output[output].type
print(f" {idx} Output name : {output_name}, Output shape : {output_shape}, \
Output type : {output_type}")
Ожидаемые форматы входных и выходных данных для модели ONNX
Каждая модель ONNX имеет предопределенный набор форматов входных и выходных данных.
В этом примере применяется модель, обученная на наборе данных fridgeObjects с 134 изображениями и 4 классами и метками для объяснения вывода модели ONNX. Дополнительные сведения о обучении задачи классификации изображений см. в записной книжке классификации образов.
Формат входных данных
Входные данные представляют собой предварительно обработанный образ.
Ввод имени
Форма входных данных
Тип Ввода
Description
Входные данные 1
(batch_size, num_channels, height, width)
Ndarray(float)
Входные данные — это предварительно обработанное изображение с фигурой (1, 3, 224, 224) для размера пакета 1, а также высотой и шириной 224. Эти числа соответствуют значениям, используемым для crop_size в примере обучения.
Формат вывода
Выходные данные представляют собой массив логитс для всех классов и меток.
Имя вывода
Форма выходных данных
Тип выходных данных
Description
Выходные данные 1
(batch_size, num_classes)
Ndarray(float)
Модель возвращает логитс (без softmax ). Например, для классов с размером 1 и 4 он возвращает (1, 4).
Входные данные представляют собой предварительно обработанный образ.
Ввод имени
Форма входных данных
Тип Ввода
Description
Входные данные 1
(batch_size, num_channels, height, width)
Ndarray(float)
Входные данные — это предварительно обработанное изображение с фигурой (1, 3, 224, 224) для размера пакета 1, а также высотой и шириной 224. Эти числа соответствуют значениям, используемым для crop_size в примере обучения.
Формат вывода
Выходные данные представляют собой массив логитс для всех классов и меток.
Имя вывода
Форма выходных данных
Тип выходных данных
Description
Выходные данные 1
(batch_size, num_classes)
Ndarray(float)
Модель возвращает логитс (без sigmoid ). Например, для классов с размером 1 и 4 он возвращает (1, 4).
Этот пример обнаружения объектов использует модель, обученную на основе набора данных fridgeObjects 128 образов и 4 классов или меток, чтобы объяснить вывод модели ONNX. В этом примере выполняется обучение более быстрой модели R-CNN для демонстрации этапов вывода. Дополнительные сведения об обучении моделей обнаружения объектов, см. в разделе Записная книжка обнаружения объектов.
Формат входных данных
Входные данные представляют собой предварительно обработанный образ.
Ввод имени
Форма входных данных
Тип Ввода
Description
Входные данные
(batch_size, num_channels, height, width)
Ndarray(float)
Входные данные — это предварительно обработанное изображение с фигурой (1, 3, 600, 800) для размера пакета 1, а также высотой 600 и шириной 800.
Формат вывода
Выходные данные представляют собой кортеж output_names и прогнозы. Здесь output_names и predictions представляют собой списки длиной 3 * batch_size каждый. Для ускорения R-CNN порядок выходных данных — это поля, метки и оценки, тогда как для RetinaNet выходные данные представляют собой поля, оценки и метки.
Имя вывода
Форма выходных данных
Тип выходных данных
Description
output_names
(3*batch_size)
Список ключей
Размер пакета составляет 2. output_names['boxes_0', 'labels_0', 'scores_0', 'boxes_1', 'labels_1', 'scores_1']
predictions
(3*batch_size)
Перечень ndarray(float)
Для размера пакета размером 2 predictions принимает форму [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n2_boxes, 4), (n2_boxes), (n2_boxes)]. Здесь значения в каждом индексе соответствуют индексу в output_names.
В следующей таблице описываются поля, метки и оценки, возвращаемые для каждого примера в пакете изображений.
Имя.
Фигура
Тип
Описание
Коробки
(n_boxes, 4), где каждое поле имеет x_min, y_min, x_max, y_max
Ndarray(float)
Модель возвращает n полей с координатами верхнего и нижнего правого угла.
Наклейки
(n_boxes)
Ndarray(float)
Метка или идентификатор класса объекта в каждом поле.
Оценки
(n_boxes)
Ndarray(float)
Оценка достоверности объекта в каждом поле.
Этот пример обнаружения объектов использует модель, обученную на основе набора данных fridgeObjects 128 образов и 4 классов или меток, чтобы объяснить вывод модели ONNX. В этом примере выполняется обучение моделей для демонстрации этапов вывода. Дополнительные сведения об обучении моделей обнаружения объектов, см. в разделе Записная книжка обнаружения объектов.
Формат входных данных
Входные данные — это предварительно обработанное изображение с фигурой (1, 3, 640, 640) для размера пакета 1, а также высотой и шириной 640. Эти числа соответствуют значениям, используемым в примере обучения.
Ввод имени
Форма входных данных
Тип Ввода
Description
Входные данные
(batch_size, num_channels, height, width)
Ndarray(float)
Входные данные — это предварительно обработанное изображение с фигурой (1, 3, 640, 640) для размера пакета 1, а также высотой 640 и шириной 640.
Формат вывода
Прогнозы модели ONNX содержат различные выходные данные. Первые выходные данные необходимы для выполнения подавления немаксических данных для обнаружения. Для простоты использования автоматизированное ML отображает формат выходных данных после этапа последующей обработки NMS. Выходные данные после NMS — это список полей, меток и оценок для каждого примера в пакете.
Имя вывода
Форма выходных данных
Тип выходных данных
Description
Выходные данные
(batch_size)
Перечень ndarray(float)
Модель возвращает обнаружение флажков для каждого примера в пакете
Каждая ячейка в списке указывает на обнаружение флажков для образца с фигурой (n_boxes, 6), где каждое поле имеет x_min, y_min, x_max, y_max, confidence_score, class_id.
В этом примере сегментации экземпляров используется модель Маски R-CNN , которая была обучена на наборе данных fridgeObjects с 128 изображениями и 4 классами и метками для объяснения вывода модели ONNX. Дополнительные сведения об обучении модели сегментирования экземпляров см. в записной книжке для сегментирования экземпляров.
Внимание
Для задач сегментации экземпляров поддерживается только маска R-CNN. Форматы входных и выходных данных основаны только на маске R-CNN.
Формат входных данных
Входные данные представляют собой предварительно обработанный образ. Модель ONNX для маски R-CNN была экспортирована для работы с изображениями различных фигур. Рекомендуется изменить размер до фиксированного размера, который соответствует размерам учебных изображений, для повышения производительности.
Ввод имени
Форма входных данных
Тип Ввода
Description
Входные данные
(batch_size, num_channels, height, width)
Ndarray(float)
Входные данные — это предварительно обработанное изображение с фигурой (1, 3, input_image_height, input_image_width) для размера пакета 1, а также высотой и шириной аналогично входному изображению.
Формат вывода
Выходные данные представляют собой кортеж output_names и прогнозы. Здесь output_names и predictions представляют собой списки длиной 4 * batch_size каждый.
Имя вывода
Форма выходных данных
Тип выходных данных
Description
output_names
(4*batch_size)
Список ключей
Размер пакета составляет 2. output_names['boxes_0', 'labels_0', 'scores_0', 'masks_0', 'boxes_1', 'labels_1', 'scores_1', 'masks_1']
predictions
(4*batch_size)
Перечень ndarray(float)
Для размера пакета размером 2 predictions принимает форму [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n1_boxes, 1, height_onnx, width_onnx), (n2_boxes, 4), (n2_boxes), (n2_boxes), (n2_boxes, 1, height_onnx, width_onnx)]. Здесь значения в каждом индексе соответствуют индексу в output_names.
Имя.
Фигура
Тип
Описание
Коробки
(n_boxes, 4), где каждое поле имеет x_min, y_min, x_max, y_max
Ndarray(float)
Модель возвращает n полей с координатами верхнего и нижнего правого угла.
Наклейки
(n_boxes)
Ndarray(float)
Метка или идентификатор класса объекта в каждом поле.
Оценки
(n_boxes)
Ndarray(float)
Оценка достоверности объекта в каждом поле.
Маски
(n_boxes, 1, height_onnx, width_onnx)
Ndarray(float)
Маски (многоугольники) обнаруженных объектов с высотой и шириной фигуры входного изображения.
Выполните следующие шаги предварительной обработки для вывода модели ONNX:
Преобразуйте изображения в RGB.
Измените размер изображения до значений valid_resize_size и valid_resize_size, которые соответствуют значениям, используемым при преобразовании набора данных проверки во время обучения. Значение по умолчанию для valid_resize_size равно 256.
Центрирование обрезки изображения до height_onnx_crop_size и width_onnx_crop_size. Он соответствует valid_crop_size со значением по умолчанию 224.
Измените HxWxC на CxHxW.
Преобразуйте в тип float.
Нормализация с помощью mean = [0.485, 0.456, 0.406] и std = [0.229, 0.224, 0.225] ImageNet.
Если вы выбрали разные значения для гиперпараметровvalid_resize_size и valid_crop_size во время обучения, то должны использоваться эти значения.
Получите входную фигуру, необходимую для модели ONNX.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
С PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Выполните следующие шаги предварительной обработки для вывода модели ONNX. Эти действия одинаковы для многоклассовой классификации образов.
Преобразуйте изображения в RGB.
Измените размер изображения до значений valid_resize_size и valid_resize_size, которые соответствуют значениям, используемым при преобразовании набора данных проверки во время обучения. Значение по умолчанию для valid_resize_size равно 256.
Центрирование обрезки изображения до height_onnx_crop_size и width_onnx_crop_size. Он соответствует valid_crop_size со значением по умолчанию 224.
Измените HxWxC на CxHxW.
Преобразуйте в тип float.
Нормализация с помощью mean = [0.485, 0.456, 0.406] и std = [0.229, 0.224, 0.225] ImageNet.
Если вы выбрали разные значения для гиперпараметровvalid_resize_size и valid_crop_size во время обучения, то должны использоваться эти значения.
Получите входную фигуру, необходимую для модели ONNX.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
С PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Для обнаружения объектов с помощью более быстрой архитектуры R-CNN выполните те же шаги предварительной обработки, что и классификация изображений, за исключением обрезки изображений. Можно изменить размер изображения, по высоте 600 и ширине 800. Вы можете получить ожидаемую высоту и ширину входных данных с помощью следующего кода.
Затем выполните действия предварительной обработки.
import glob
import numpy as np
from PIL import Image
def preprocess(image, height_onnx, width_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param height_onnx: expected height of an input image in onnx model
:type height_onnx: Int
:param width_onnx: expected width of an input image in onnx model
:type width_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((width_onnx, height_onnx))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_od/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Для обнаружения объектов с помощью архитектуры YOLO выполните те же шаги предварительной обработки, что и классификация изображений, за исключением обрезки изображений. Можно изменить размер изображения с высотой 600 и шириной 800, и получить ожидаемую высоту и ширину входных данных с помощью следующего кода.
import glob
import numpy as np
from yolo_onnx_preprocessing_utils import preprocess
# use height and width based on the generated model
test_images_path = "automl_models_od_yolo/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
pad_list = []
for i in range(batch_size):
img_processed, pad = preprocess(image_files[i])
img_processed_list.append(img_processed)
pad_list.append(pad)
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Внимание
Для задач сегментации экземпляров поддерживается только маска R-CNN. Этапы предварительной обработки основаны только на Маске R-CNN.
Выполните следующие шаги предварительной обработки для вывода модели ONNX:
Преобразуйте изображения в RGB.
Измените размер изображения.
Измените HxWxC на CxHxW.
Преобразуйте в тип float.
Нормализация с помощью mean = [0.485, 0.456, 0.406] и std = [0.229, 0.224, 0.225] ImageNet.
Для resize_height и resize_width можно также использовать значения, которые использовались во время обучения, ограниченные гиперпараметрами min_sizemin_size и max_sizeдля Маски R-CNN.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_height, resize_width):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_height: resize height of an input image
:type resize_height: Int
:param resize_width: resize width of an input image
:type resize_width: Int
:return: pre-processed image in numpy format
:rtype: ndarray of shape 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((resize_width, resize_height))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
# use height and width based on the trained model
# use height and width based on the generated model
test_images_path = "automl_models_is/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Вывод с помощью среды выполнения ONNX
Вывод с использованием среды выполнения ONNX для каждой задачи службы зрения компьютера различается.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session, img_data):
"""perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
(No. of boxes, 4) (No. of boxes,) (No. of boxes,)
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""perform predictions with ONNX Runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
:rtype: list
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
pred = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return pred[0]
result = get_predictions_from_ONNX(session, img_data)
Модель сегментирования экземпляров прогнозирует рамки, метки, оценки и маски. ONNX выводит прогнозируемую маску на экземпляр, а также соответствующие ограничивающие прямоугольники и оценку достоверности класса. При необходимости может потребоваться преобразование из двоичной маски в многоугольник.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores , masks with shapes
(No. of instances, 4) (No. of instances,) (No. of instances,)
(No. of instances, 1, HEIGHT, WIDTH))
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
Примените softmax() к более прогнозируемым значениям, чтобы получить показатели достоверности классификации (вероятностные) для каждого класса. Затем прогноз будет классом с наибольшей вероятностью.
conf_scores = torch.nn.functional.softmax(torch.from_numpy(scores), dim=1)
class_preds = torch.argmax(conf_scores, dim=1)
print("predicted classes:", ([(class_idx.item(), classes[class_idx]) for class_idx in class_preds]))
Этот шаг отличается от многоклассовой классификации. Чтобы получить показатели достоверности для классификации изображений с несколькими метками, необходимо применить sigmoid к логитс (выходные данные ONNX).
Без PyTorch
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = sigmoid(scores)
image_wise_preds = np.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
С PyTorch
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = torch.sigmoid(torch.from_numpy(scores))
image_wise_preds = torch.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
Для классификации с несколькими классами и несколькими метками можно выполнить те же действия, которые упоминание ранее для всех поддерживаемых архитектур моделей в AutoML.
Для обнаружения объектов прогнозы автоматически применяются к шкале height_onnx, width_onnx. Чтобы преобразовать координаты прогнозируемого поля в исходные измерения, можно реализовать следующие вычисления.
Xmin * original_width/width_onnx
Ymin * original_height/height_onnx
Xmax * original_width/width_onnx
Ymax * original_height/height_onnx
Другой вариант — использовать следующий код для масштабирования размеров прямоугольника в диапазоне [0, 1]. Это позволяет умножить координаты прямоугольника на исходные высоту и ширину изображения с соответствующими координатами (как описано в разделе визуализации прогнозов) для получения прямоугольников в исходных измерениях изображения.
def _get_box_dims(image_shape, box):
box_keys = ['topX', 'topY', 'bottomX', 'bottomY']
height, width = image_shape[0], image_shape[1]
box_dims = dict(zip(box_keys, [coordinate.item() for coordinate in box]))
box_dims['topX'] = box_dims['topX'] * 1.0 / width
box_dims['bottomX'] = box_dims['bottomX'] * 1.0 / width
box_dims['topY'] = box_dims['topY'] * 1.0 / height
box_dims['bottomY'] = box_dims['bottomY'] * 1.0 / height
return box_dims
def _get_prediction(boxes, labels, scores, image_shape, classes):
bounding_boxes = []
for box, label_index, score in zip(boxes, labels, scores):
box_dims = _get_box_dims(image_shape, box)
box_record = {'box': box_dims,
'label': classes[label_index],
'score': score.item()}
bounding_boxes.append(box_record)
return bounding_boxes
# Filter the results with threshold.
# Please replace the threshold for your test scenario.
score_threshold = 0.8
filtered_boxes_batch = []
for batch_sample in range(0, batch_size*3, 3):
# in case of retinanet change the order of boxes, labels, scores to boxes, scores, labels
# confirm the same from order of boxes, labels, scores output_names
boxes, labels, scores = predictions[batch_sample], predictions[batch_sample + 1], predictions[batch_sample + 2]
bounding_boxes = _get_prediction(boxes, labels, scores, (height_onnx, width_onnx), classes)
filtered_bounding_boxes = [box for box in bounding_boxes if box['score'] >= score_threshold]
filtered_boxes_batch.append(filtered_bounding_boxes)
В следующем коде создаются поля, метки и оценки. Используйте эти сведения об ограничивающем прямоугольнике для выполнения тех же этапов обработки, что и для модели Ускорения R-CNN.
Вы можете использовать действия, описанные для ускорения R-CNN (в случае маски R-CNN, каждый пример содержит четыре поля элементов, метки, оценки, маски) или см. раздел Визуализация прогнозов для сегментирования экземпляров.
 Пакет SDK для Python azure-ai-ml версии 2 (current)
Пакет SDK для Python azure-ai-ml версии 2 (current)