Настройка AutoML для обучения моделей компьютерного зрения
ОБЛАСТЬ ПРИМЕНЕНИЯ: Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
В этой статье вы узнаете, как обучить модели компьютерного зрения на основе данных изображений с помощью автоматизированного машинного обучения. Модели можно обучить с помощью расширения CLI Машинное обучение Azure версии 2 или пакета SDK для Python Машинное обучение Azure версии 2.
Автоматизированное машинное обучение поддерживает обучение моделей для задач компьютерного зрения, например для классификация изображений, обнаружения объектов и сегментации экземпляров. Создание моделей AutoML для задач компьютерного зрения в настоящее время поддерживается на основе пакета SDK Машинного обучения Azure для Python. Результирующая пробная версия экспериментирования, модели и выходные данные доступны из пользовательского интерфейса Студия машинного обучения Azure. Дополнительные сведения об автоматизированном машинном обучении для задач компьютерного зрения на данных изображений.
Необходимые компоненты
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
- Рабочая область Машинного обучения Azure. Сведения о создании рабочей области см. в разделе Создание ресурсов рабочей области.
- Установите и настройте интерфейс командной строки (версии 2), а также установите для него расширение
ml.
Выберите тип задачи
Автоматизированное машинное обучение для изображений поддерживает следующие типы задач:
| Тип задачи | Синтаксис задания AutoML |
|---|---|
| классификация изображений. | CLI (версия 2): image_classification Пакет SDK (версия 2): image_classification() |
| классификация изображений с несколькими метками | CLI (версия 2): image_classification_multilabel Пакет SDK (версия 2): image_classification_multilabel() |
| обнаружение объектов изображений | CLI (версия 2): image_object_detection Пакет SDK (версия 2): image_object_detection() |
| сегментация экземпляров изображений | CLI (версия 2): image_instance_segmentation Пакет SDK (версия 2): image_instance_segmentation() |
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
Этот тип задачи является обязательным параметром и его можно задать с помощью ключа task.
Например:
task: image_object_detection
Данные для обучения и проверки
Чтобы создавать модели компьютерного зрения с помощью автоматизированного машинного обучения, необходимо добавить помеченные данные изображений в качестве входных данных для обучения модели в формате MLTable. Данные обучения в формате JSONL можно преобразовать в MLTable.
Если данные обучения имеют другой формат (например, pascal VOC или COCO), можно применить вспомогательные скрипты, входящие в пример записных книжек, чтобы преобразовать данные в JSONL. Дополнительные сведения о подготовке данных для задач компьютерного зрения с помощью автоматизированного машинного обучения.
Примечание.
Для отправки задания AutoML данные обучения должны иметь по крайней мере 10 изображений.
Предупреждение
Для этой возможности создание MLTable на основе данных в формате JSONL поддерживается только с использованием пакета SDK и CLI. Создание MLTable через пользовательский интерфейс в настоящее время не поддерживается.
Примеры схемы JSONL
Структура Табличных наборов данных зависит от поставленной задачи. Для типов задач компьютерного зрения она состоит из следующих полей:
| Поле | Description |
|---|---|
image_url |
Содержит путь к файлу в виде объекта StreamInfo |
image_details |
Сведения о метаданных изображения включают высоту, ширину и формат. Это поле является необязательным, поэтому оно может существовать или не существовать. |
label |
Представление JSON метки изображения на основе типа задачи. |
Следующий код представляет собой пример JSONL-файла для классификации изображений:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Нижеприведенный код представляет собой пример файла JSONL для классификации объектов:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Использование данных
Подготовив данные в формате JSONL, вы сможете создать обучение и проверку MLTable, как показано ниже.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Автоматизированное Машинное обучение не накладывают ограничений на размер данных для обучения или проверки в задачах компьютерного зрения. Максимальный размер набора данных ограничен только уровнем хранилища, лежащим в основе набора данных (например, хранилище BLOB-объектов). Не существует минимального требования к количеству изображений или меток. Но мы рекомендуем начинать не менее чем с 10–15 примеров на каждую метку, чтобы обеспечить достаточную точную модель. Чем больше общее количество меток и классов, тем больше примеров потребуется для каждой метки.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
Обучающие данные являются обязательным параметром и передаются с помощью training_data ключа. При желании вы можете указать другую таблицу MLtable в качестве проверочных данных с помощью ключа validation_data. Если данные проверки не указаны, 20% данных обучения используются для проверки по умолчанию, если аргумент не передается validation_data_size с другим значением.
Имя целевого столбца является обязательным параметром и используется в качестве целевого объекта для контролируемой задачи Машинного обучения. Он передается с помощью target_column_name ключа. Например,
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
Вычисление для запуска эксперимента
Предоставьте целевой объект вычислений для автоматизированного машинного обучения, чтобы провести обучение модели. Модели автоматизированного машинного обучения для задач компьютерного зрения нуждаются в SKU GPU и поддерживают семейства NC и ND. Для ускорения обучения мы рекомендуем использовать серию NCsv3 (с GPU версии 100). Целевой объект вычислений с номером SKU виртуальной машины с несколькими GPU использует несколько GPU для ускорения обучения. Кроме того, при настройке целевого объекта вычислений с несколькими узлами можно ускорить обучение модели с помощью параллелизма при настройке гиперпараметров для модели.
Примечание.
Если вы используете вычислительный экземпляр в качестве целевого объекта вычислений, убедитесь, что одновременно несколько заданий AutoML не выполняются. Кроме того, убедитесь, что max_concurrent_trials установлено значение 1 в ограничениях задания.
Целевой объект вычислений передается с помощью параметра compute. Например:
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
compute: azureml:gpu-cluster
Настройка экспериментов
Для задач компьютерного зрения можно запустить отдельные пробные версии, ручную очистку или автоматическую очистку. Мы рекомендуем начать с автоматической очистки, чтобы получить первую базовую модель. Затем можно попробовать отдельные пробные версии с определенными моделями и конфигурациями гиперпараметров. Наконец, с помощью ручной очистки можно изучить несколько значений гиперпараметра вблизи более перспективных моделей и конфигураций гиперпараметров. Этот трехэтапный рабочий процесс (автоматическая очистка, отдельные пробные версии, ручная очистка) избегает поиска всего пространства гиперпараметра, который увеличивается экспоненциально в количестве гиперпараметров.
Автоматические очистки могут дать конкурентные результаты для многих наборов данных. Кроме того, они не требуют расширенных знаний об архитектуре моделей, они учитывают корреляции гиперпараметров, и они легко работают в разных аппаратных настройках. Все эти причины делают их сильным вариантом для раннего этапа процесса экспериментирования.
Основная метрика
Задание обучения AutoML использует основную метрику для оптимизации модели и настройки гиперпараметров. Основная метрика зависит от типа задачи, как показано ниже; другие основные значения метрик в настоящее время не поддерживаются.
- Точность классификации изображений
- Пересечение между объединениями для классификации изображений с несколькими меткими
- Средняя точность для обнаружения объектов изображения
- Средняя точность для сегментации экземпляра изображения
Ограничения заданий
Вы можете управлять ресурсами, потраченными на задание обучения изображений AutoML, max_trialsmax_concurrent_trials указав timeout_minutesзадание в ограничениях, как описано в приведенном ниже примере.
| Параметр | Подробности |
|---|---|
max_trials |
Параметр для максимального количества пробных версий для очистки. Требуется целое число от 1 до 1000. При изучении только гиперпараметров по умолчанию для данной архитектуры модели задайте для этого параметра значение 1. Значение по умолчанию равно 1. |
max_concurrent_trials |
Максимальное количество пробных версий, которые могут выполняться одновременно. Значение должно быть целым числом от 1 до 100. Значение по умолчанию равно 1. ПРИМЕЧАНИЕ. max_concurrent_trials ограничивается max_trials внутренне. Например, если пользовательские наборы max_concurrent_trials=4, max_trials=2значения будут внутренне обновлены как max_concurrent_trials=2, . max_trials=2 |
timeout_minutes |
Время в минутах перед завершением эксперимента. Если этот параметр не указан, timeout_minutes по умолчанию — семь дней (максимум 60 дней) |
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
Автоматическое масштабирование гиперпараметров модели (AutoMode)
Важно!
Эта функция сейчас доступна в виде общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Трудно предсказать лучшую архитектуру модели и гиперпараметры для набора данных. Кроме того, в некоторых случаях время человека, выделенное для настройки гиперпараметров, может быть ограничено. Для задач компьютерного зрения можно указать любое количество пробных версий, а система автоматически определяет область пространства гиперпараметров для очистки. Вам не нужно определять пространство поиска гиперпараметров, метод выборки или политику раннего завершения.
Активация автомоде
Вы можете запускать автоматические очистки, задав max_trials значение больше 1 и limits не указывая пространство поиска, метод выборки и политику завершения. Мы вызываем эту функцию AutoMode; См. следующий пример.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
limits:
max_trials: 10
max_concurrent_trials: 2
Ряд проб от 10 до 20, вероятно, хорошо работает на многих наборах данных. Бюджет времени для задания AutoML по-прежнему может быть задан, но мы рекомендуем сделать это только в том случае, если каждая пробная версия может занять много времени.
Предупреждение
Запуск автоматической очистки через пользовательский интерфейс в настоящее время не поддерживается.
Отдельные пробные версии
В отдельных пробных версиях вы непосредственно управляете архитектурой модели и гиперпараметрами. Архитектура модели передается через model_name параметр.
Поддерживаемые архитектуры моделей
В следующей таблице перечислены поддерживаемые устаревшие модели для каждой задачи компьютерного зрения. Использование только этих устаревших моделей запускается с помощью устаревшей среды выполнения (где каждый отдельный запуск или пробная версия отправляется в качестве задания команды). См. ниже сведения о поддержке HuggingFace и MMDetection.
| Задача | Архитектуры моделей | Синтаксис строкового литералаdefault_model* обозначено звездочкой * |
|---|---|---|
| Классификация изображений (несколько классов и несколько меток) |
MobileNet: легкие модели для мобильных приложений ResNet: остаточные сети ResNeSt: сети разделенного внимания SE-ResNeXt50: сети сжатия и возбуждения ViT: сети преобразователя зрения |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (небольшой) vitb16r224* (базовая) vitl16r224 (крупный) |
| Обнаружение объектов |
YOLOv5: одна модель обнаружения объектов этапа Более быстрая версия RCNN ResNet FPN: две модели обнаружения объектов этапа RetinaNet ResNet FPN: дисбаланс класса адресов с фокусом потери Примечание: см. model_sizeгиперпараметр для размеров модели YOLOv5. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Сегментация экземпляров | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
Поддерживаемые архитектуры моделей — HuggingFace и MMDetection
С помощью новой серверной части, работающей на Машинное обучение Azure конвейерах, можно дополнительно использовать любую модель классификации изображений из Концентратора HuggingFace, которая входит в библиотеку преобразователей (например, microsoft/beit-base-patch16-224), а также любую модель обнаружения объектов или сегментации экземпляров из зоопарка моделей MMDetection версии 3.1.0 (напримерatss_r50_fpn_1x_coco).
Помимо поддержки любой модели из HuggingFace Transfomers и MMDetection 3.1.0, мы также предлагаем список курируемых моделей из этих библиотек в реестре Azureml. Эти курированные модели тщательно протестированы и используют гиперпараметры по умолчанию, выбранные из обширного тестирования, чтобы обеспечить эффективное обучение. В приведенной ниже таблице перечислены эти курируемые модели.
| Задача | Архитектуры моделей | Синтаксис строкового литерала |
|---|---|---|
| Классификация изображений (несколько классов и несколько меток) |
Бейт Vit DeiT SwinV2 |
microsoft/beit-base-patch16-224-pt22k-ft22kgoogle/vit-base-patch16-224facebook/deit-base-patch16-224microsoft/swinv2-base-patch4-window12-192-22k |
| Обнаружение объектов |
Разреженный R-CNN Деформируемый DETR Виртуальная сеть YOLOF |
mmd-3x-sparse-rcnn_r50_fpn_300-proposals_crop-ms-480-800-3x_cocommd-3x-sparse-rcnn_r101_fpn_300-proposals_crop-ms-480-800-3x_coco mmd-3x-deformable-detr_refine_twostage_r50_16xb2-50e_coco mmd-3x-vfnet_r50-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-vfnet_x101-64x4d-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-yolof_r50_c5_8x8_1x_coco |
| Сегментация экземпляров | Маска R-CNN | mmd-3x-mask-rcnn_swin-t-p4-w7_fpn_1x_coco |
Мы постоянно обновляем список курируемых моделей. Вы можете получить самый актуальный список курируемых моделей для данной задачи с помощью пакета SDK для Python:
credential = DefaultAzureCredential()
ml_client = MLClient(credential, registry_name="azureml")
models = ml_client.models.list()
classification_models = []
for model in models:
model = ml_client.models.get(model.name, label="latest")
if model.tags['task'] == 'image-classification': # choose an image task
classification_models.append(model.name)
classification_models
Выходные данные:
['google-vit-base-patch16-224',
'microsoft-swinv2-base-patch4-window12-192-22k',
'facebook-deit-base-patch16-224',
'microsoft-beit-base-patch16-224-pt22k-ft22k']
Использование любой модели HuggingFace или MMDetection запускает запуск с помощью компонентов конвейера. Если используются устаревшие и устаревшие модели HuggingFace/MMdetection, все запуски и пробные версии будут активированы с помощью компонентов.
Помимо управления архитектурой модели, можно также настроить гиперпараметры, используемые для обучения моделей. Хотя многие из показанных гиперпараметров не зависят от модели, существуют экземпляры, в которых гиперпараметры зависят от конкретной задачи или конкретной модели. Дополнительные сведения о доступных гиперпараметрах для этих экземпляров.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
Если вы хотите использовать значения гиперпараметров по умолчанию для данной архитектуры (скажем yolov5), можно указать его с помощью ключа model_name в разделе training_parameters. Например,
training_parameters:
model_name: yolov5
Гиперпараметры модели вручную
При обучении моделей компьютерного зрения производительность модели в значительной степени зависит от выбранных значений гиперпараметров. Часто может потребоваться настроить гиперпараметры, чтобы добиться оптимальной производительности. Для задач компьютерного зрения можно выполнить очистку гиперпараметров, чтобы найти оптимальные параметры для модели. Эта функция применяет возможности настройки гиперпараметров в Машинном обучении Azure. Инструкции по настройке гиперпараметров.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
определение пространства поиска параметров;
Вы можете определить архитектуры модели и гиперпараметры для очистки пространства параметров. Можно указать одну архитектуру модели или несколько.
- Ознакомьтесь с отдельными пробными версиями для списка поддерживаемых архитектур моделей для каждого типа задачи.
- См. гиперпараметры для каждого типа задач компьютерного зрения в разделе Гиперпараметры для задач компьютерного зрения.
- См. дополнительные сведения о поддерживаемых дистрибутивах для дискретных и непрерывных гиперпараметров.
Методы выборки для очистки
При очистке гиперпараметров необходимо указать метод выборки, используемый для очистки заданного пространства параметров. Сейчас поддерживаются следующие методы выборки с параметром sampling_algorithm:
| Тип выборки | Синтаксис задания AutoML |
|---|---|
| Случайная выборка | random |
| Решетчатая выборка | grid |
| Байесовская выборка | bayesian |
Примечание.
В настоящее время только случайные выборки и выборка сетки поддерживают условные пространства гиперпараметров.
Политика преждевременного завершения
Вы можете автоматически завершить плохое выполнение пробных версий с помощью политики раннего завершения. Досрочное завершение повышает эффективность вычислений, экономя вычислительные ресурсы, которые в противном случае были бы потрачены на менее перспективные пробные версии. Автоматизированное ML для изображений поддерживают следующую политику досрочного завершения с помощью параметра early_termination. Если политика прекращения не указана, все пробные версии выполняются до завершения.
| Политика досрочного завершения | Синтаксис задания AutoML |
|---|---|
| Политика бандитов | CLI (версия 2): bandit Пакет SDK (версия 2): BanditPolicy() |
| Политика остановки медиана | CLI (версия 2): median_stopping Пакет SDK (версия 2): MedianStoppingPolicy() |
| Политика выбора усечения | CLI (версия 2): truncation_selection Пакет SDK (версия 2): TruncationSelectionPolicy() |
Дополнительные сведения о настройке политики досрочного завершения для очистки гиперпараметров.
Примечание.
Пример конфигурации полной очистки см. в этом учебнике.
Все связанные параметры очистки можно настроить, как показано в следующем примере.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
Фиксированные параметры
Вы можете передать фиксированные параметры или параметры, которые не изменяются во время очистки пространства параметров, как показано в следующем примере.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
training_parameters:
early_stopping: True
evaluation_frequency: 1
Дополнение данных
Как правило, производительность модели глубокого обучения часто можно повысить за счет дополнительных данных. Расширение данных — это практический метод для повышения размера и изменчивости набора данных, что помогает предотвратить переполнение и повысить общую способность модели к невидимым данным. Автоматизированное машинное обучение применяет различные методы приращения данных на основе задачи компьютерного зрения, прежде чем передать входные изображения в модель. В настоящее время отсутствует видимый гиперпараметр для управления приращениями данных.
| Задача | Затронутый набор данных | Примененные методики приращения данных |
|---|---|---|
| Классификации изображений (с несколькими классами и с несколькими метками) | Обучение Проверка и проверка |
Случайное изменение размера и обрезка, горизонтальное переворачивание, изменение цвета (яркость, контрастность, насыщенность и оттенок), нормализация с использованием среднего и стандартного отклонения ImageNet с помощью среднего и стандартного отклонения ImageNet Изменение размера, обрезка по центру, нормализация |
| Обнаружение объектов, сегментация экземпляров | Обучение Проверка и проверка |
Случайное обрезка вокруг ограничивающих прямоугольник, развертывание, горизонтальное перевернутое, нормализация, изменение размера Нормализация, изменение размера |
| Обнаружение объектов с использованием yolov5 | Обучение Проверка и проверка |
Мозаика, случайные аффины (поворот, перевод, масштабирование, стриж), горизонтальный перевернутый Изменение размера киноформата "Letterbox" |
В настоящее время расширения, определенные выше, применяются по умолчанию для задания автоматизированного машинного обучения для задания образа. Чтобы обеспечить контроль над расширением, автоматизированное машинное обучение для изображений предоставляет ниже двух флагов для отключения определенных дополнений. В настоящее время эти флаги поддерживаются только для задач обнаружения объектов и сегментации экземпляров.
- apply_mosaic_for_yolo. Этот флаг относится только к модели Yolo. При задании значение False отключает расширение данных мозаики, которое применяется во время обучения.
-
apply_automl_train_augmentations. Установка этого флага на значение false отключает расширение, примененное во время обучения для моделей обнаружения объектов и сегментации экземпляров. Дополнительные сведения см. в приведенной выше таблице.
- Для модели обнаружения объектов, отличных от yolo, и моделей сегментации экземпляров этот флаг отключает только первые три расширения. Например, случайный обрез вокруг ограничивающих прямоугольников, разверните, горизонтальное перевернуть. Нормализация и изменение размера расширения по-прежнему применяются независимо от этого флага.
- Для модели Yolo этот флаг отключает случайные аффины и горизонтальные расширения переворачивания.
Эти два флага поддерживаются с помощью advanced_settings в training_parameters и могут управляться следующим образом.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
Обратите внимание, что эти два флага не зависят друг от друга, а также могут использоваться в сочетании с помощью следующих параметров.
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
В наших экспериментах мы обнаружили, что эти расширения помогают модели лучше обобщать. Таким образом, если эти расширения отключены, мы рекомендуем пользователям объединять их с другими автономными расширениями, чтобы получить лучшие результаты.
Добавочное обучение (необязательно)
После завершения обучения можно выбрать дальнейшее обучение модели, загрузив обученную модель проверка point. Для добавочного обучения можно использовать тот же набор данных или другой. Если вы удовлетворены моделью, вы можете остановить обучение и использовать текущую модель.
Передача проверка point с помощью идентификатора задания
Вы можете передать идентификатор задания, с которого вы хотите загрузить точку проверка.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
Отправка задания AutoML
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
Чтобы отправить задание AutoML, выполните следующую команду CLI версии 2 и укажите для нее путь к YML-файлу, имя рабочей области, группу ресурсов и идентификатор подписки.
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Выходные данные и метрики вычисления
Автоматические задания обучения машинного обучения создают файлы выходной модели, метрики оценки, журналы и артефакты развертывания, такие как файл оценки и файл среды. Эти файлы и метрики можно просмотреть на вкладке выходных данных и журналов и метрик дочерних заданий.
Совет
Узнайте, как перейти к результатам задания из раздела "Просмотр результатов задания".
Определения и примеры диаграмм производительности и метрик, предоставляемых для каждого задания, см. в статье Оценка результатов экспериментов автоматического машинного обучения.
регистрация и развертывание модели.
После завершения задания можно зарегистрировать модель, созданную из лучшей пробной версии (конфигурация, которая привела к лучшей первичной метрике). Вы можете зарегистрировать модель после скачивания или указать путь к azureml с соответствующим идентификатором задания (jobid). Примечание. Если вы хотите изменить параметры вывода, описанные ниже, необходимо скачать модель и изменить settings.json и зарегистрировать с помощью обновленной папки модели.
Получите лучшую пробную версию
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
CLI example not available, please use Python SDK.
Регистрация модели
Зарегистрируйте модель, используя путь к azureml или путь к локальной скачанной копии.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Завершив регистрацию модели, которую вы хотите использовать, вы можете развернуть ее с помощью управляемой сетевой конечной точки deploy-managed-online-endpoint.
Настройка сетевой конечной точки
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
Создание конечной точки
Используя созданную MLClient ранее конечную точку, мы создадим конечную точку в рабочей области. Эта команда запускает создание конечной точки и возвращает ответ подтверждения во время создания конечной точки.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Настройка сетевого развертывания
Развертывание представляет собой набор ресурсов, необходимых для размещения модели, которая выполняет процесс вывода. Мы создадим развертывание для нашей конечной точки с помощью класса ManagedOnlineDeployment. Для кластера развертывания можно использовать номера SKU для виртуальных машин GPU или процессора.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
Создание развертывания
С помощью созданного ранее объекта MLClient мы создадим развертывание в рабочей области. Эта команда запустит создание развертывания и вернет ответ с подтверждением во время создания.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Обновление трафика:
По умолчанию текущее развертывание получает 0 % трафика. Вы можете задать процент трафика, который будет направляться в текущее развертывание. Сумма трафика всех развертываний для одной конечной точки не должна превышать 100 %.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Кроме того, можно развернуть модель из пользовательского интерфейса студии Машинного обучения Azure. Перейдите к модели, которую вы хотите развернуть на вкладке "Модели" автоматизированного задания машинного обучения и выберите "Развернуть" и выберите "Развернуть в конечной точке в режиме реального времени".
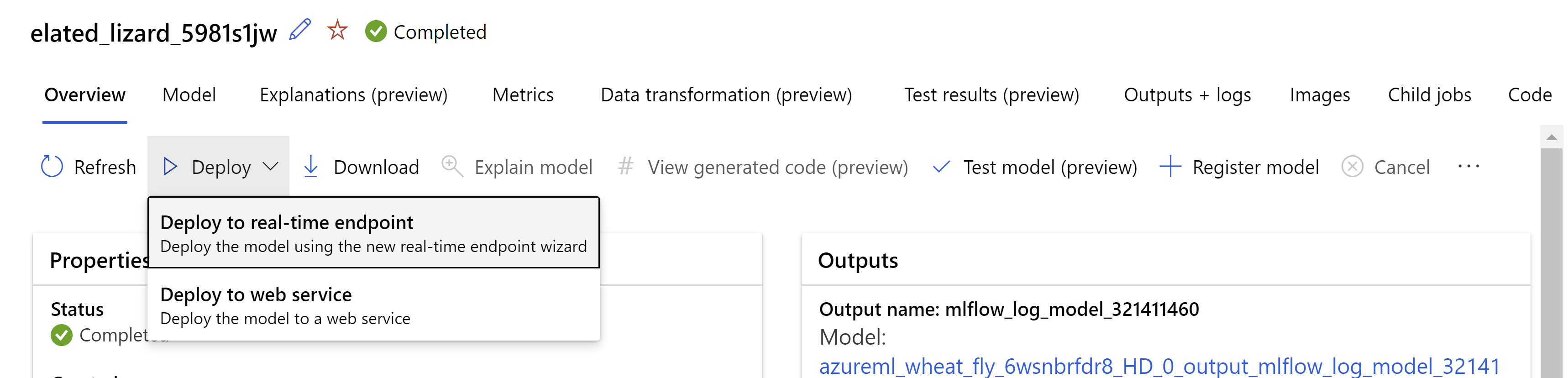 .
.
А так выглядит страница проверки данных. Мы можем выбрать тип экземпляра, количество экземпляров и процент трафика для текущего развертывания.
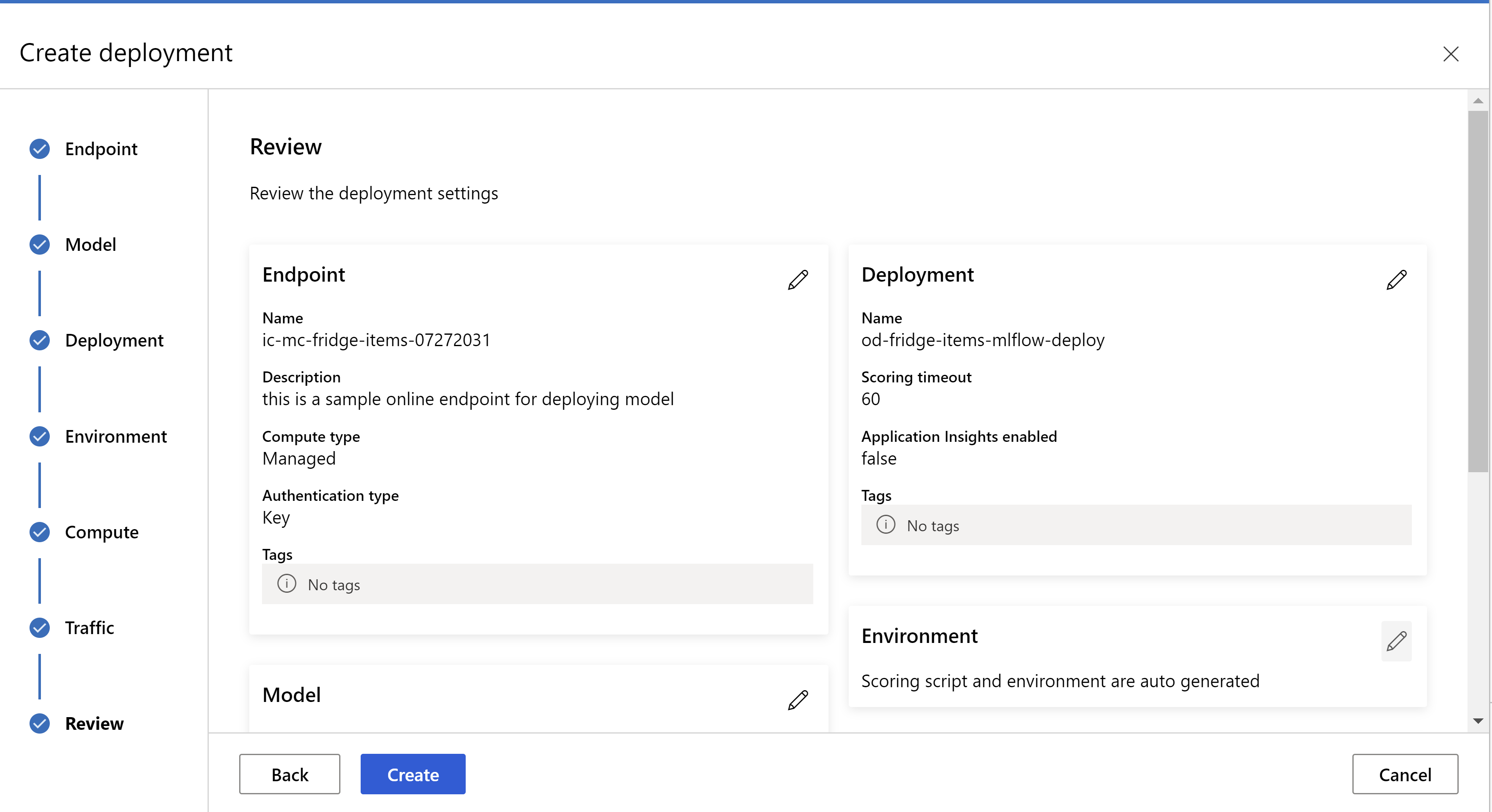 .
.
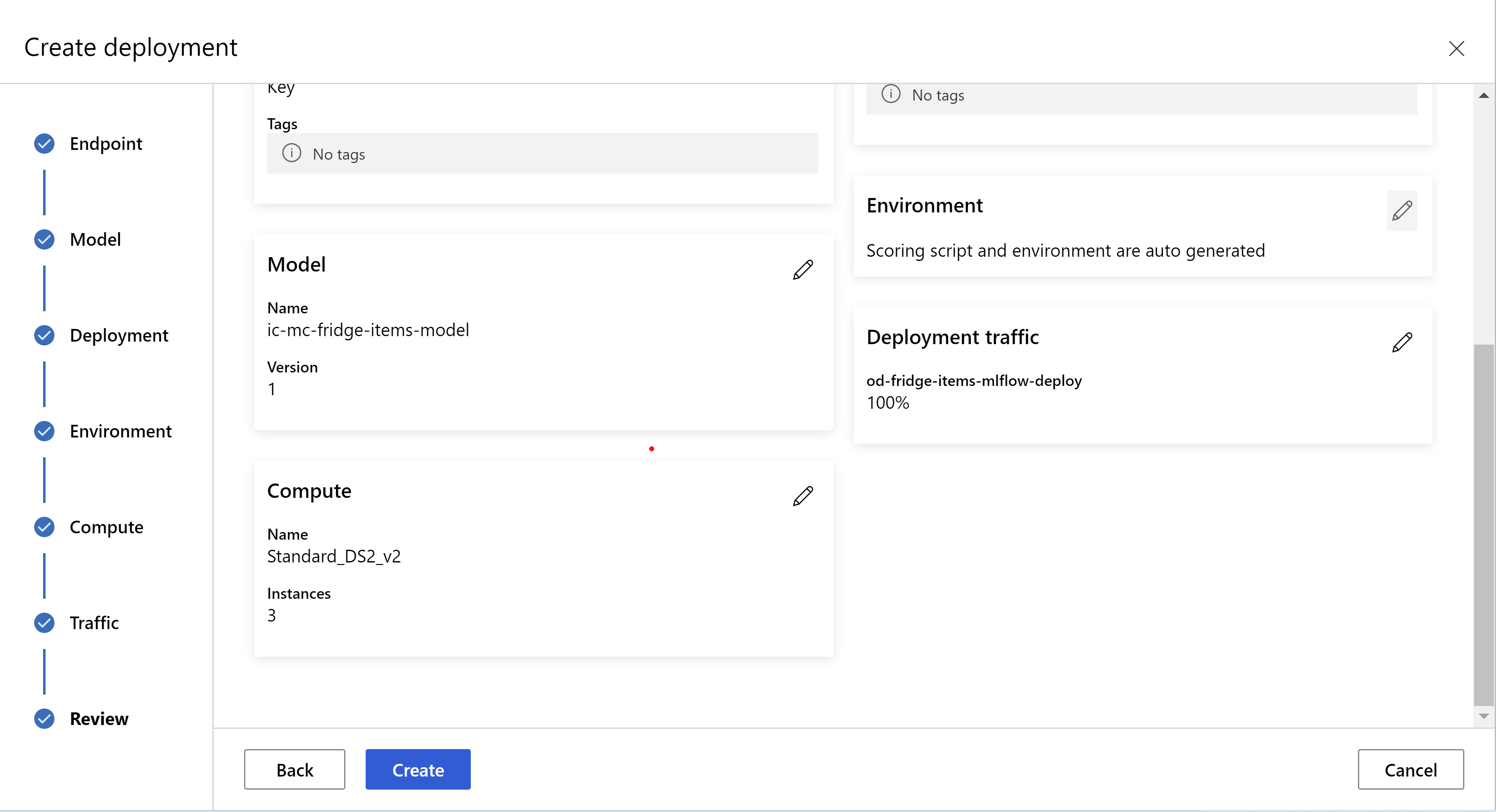 .
.
Обновление параметров вывода
На предыдущем шаге мы скачали файл mlflow-model/artifacts/settings.json из лучшей модели. Теперь мы можем применить его для обновления параметров вывода, прежде чем регистрировать модель. Хотя рекомендуется использовать те же параметры, что и обучение для оптимальной производительности.
Каждая из задач (и некоторые модели) имеет некоторый набор параметров. По умолчанию мы используем те же значения для параметров, которые использовались во время обучения и проверки. В зависимости от реакции на события, которая требуется при использовании модели для вывода, мы можем менять эти параметры. Ниже можно найти список параметров для каждого типа задачи и для каждой модели.
| Задача | Наименование параметра | По умолчанию |
|---|---|---|
| Классификации изображений (с несколькими классами и с несколькими метками) | valid_resize_sizevalid_crop_size |
256 224 |
| Обнаружение объектов | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0,3 0,5 100 |
Обнаружение объектов с использованием yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 medium 0,1 0,5 |
| Сегментация экземпляров | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0,3 0,5 100 0,5 100 False JPG |
Подробное описание конкретных гиперпараметров задачи см . в гиперпараметрах для задач компьютерного зрения в автоматизированном машинном обучении.
Если вы хотите использовать мозаичное заполнение и хотите управлять поведением мозаичного заполнения, доступны следующие параметры: tile_grid_size, tile_overlap_ratio и tile_predictions_nms_thresh. Дополнительные сведения об этих параметрах проверка обучение небольшой модели обнаружения объектов с помощью AutoML.
Тестирование развертывания
Проверьте этот раздел тестирования развертывания, чтобы протестировать развертывание и визуализировать обнаружения из модели.
Создание объяснений для прогнозов
Важно!
Эти параметры в настоящее время находятся в общедоступной предварительной версии. Они предоставляются без соглашения об уровне обслуживания. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Предупреждение
Объяснение модели поддерживается только для классификации с несколькими классами и классификации с несколькими метками.
Некоторые из преимуществ использования объясняемого искусственного интеллекта (XAI) с autoML для изображений:
- Повышение прозрачности в прогнозах сложной модели визуального зрения
- Помогает пользователям понять важные функции и пиксели во входном изображении, которые способствуют прогнозированию модели.
- Помогает устранить неполадки моделей
- Помогает обнаружить предвзятость
Пояснения
Объяснения — это атрибуты и весы, предоставленные каждому пикселю в входном изображении на основе его вклада в прогнозирование модели. Каждый вес может быть отрицательным (отрицательно коррелируемым с прогнозом) или положительным (положительно коррелируемым с прогнозом). Эти атрибуты вычисляются в отношении прогнозируемого класса. Для классификации с несколькими классами создается ровно одна матрица присвоения размера [3, valid_crop_size, valid_crop_size] для каждого образца, в то время как для классификации с несколькими метками матрица атрибуции размера [3, valid_crop_size, valid_crop_size] создается для каждого прогнозируемого метки или класса для каждого примера.
С помощью объясняемого искусственного интеллекта в AutoML для изображений на развернутой конечной точке пользователи могут получать визуализации объяснений (наложения на входном изображении) и /или атрибуции (многомерный массив размера [3, valid_crop_size, valid_crop_size]) для каждого изображения. Помимо визуализаций, пользователи также могут получить матрицы атрисы для получения большего контроля над объяснениями (например, создание пользовательских визуализаций с помощью атрибуции или проверки сегментов атрибуции). Все алгоритмы объяснения используют обрезанные квадратные изображения с размером valid_crop_size для создания атрибутов.
Объяснения можно создать из веб-конечной точки или пакетной конечной точки. После завершения развертывания эту конечную точку можно использовать для создания объяснений прогнозов. В сетевых развертываниях обязательно передайте request_settings = OnlineRequestSettings(request_timeout_ms=90000) параметр ManagedOnlineDeployment и задайте request_timeout_ms максимальное значение, чтобы избежать проблем с временем ожидания при создании объяснений (см . раздел о регистрации и развертывании модели). Некоторые методы объясняемости (XAI), такие как xrai использование большего времени (специально для классификации нескольких меток, так как нам нужно создать атрибуцию и /или визуализации для каждой прогнозируемой метки). Таким образом, мы рекомендуем любой экземпляр GPU для более быстрых объяснений. Дополнительные сведения о схеме ввода и вывода для создания объяснений см. в документации по схеме.
Мы поддерживаем следующие алгоритмы объясняемости в AutoML для изображений:
- XRAI (xrai )
- Интегрированные градиенты (integrated_gradients)
- Руководство по GradCAM (guided_gradcam)
- Интерактивное использование backPropagation (guided_backprop)
В следующей таблице описаны параметры настройки алгоритма объяснимости для XRAI и интегрированных градиентов. Для управляемой обратной поддержки и управляемой gradcam не требуются параметры настройки.
| Алгоритм XAI | Определенные параметры алгоритма | Значения по умолчанию |
|---|---|---|
xrai |
1. n_stepsЧисло шагов, используемых методом приближения. Большее количество шагов приводит к улучшению приближения атрибутов (объяснений). Диапазон n_steps равен [2, inf), но производительность атрибуции начинает конвергентироваться после 50 шагов. Optional, Int 2. xrai_fastСледует ли использовать более быструю версию XRAI. Если True, то время вычисления для объяснений быстрее, но приводит к менее точным объяснениям (атрибуциям) Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. n_stepsЧисло шагов, используемых методом приближения. Большее количество шагов приводит к улучшению возмездия (объяснения). Диапазон n_steps равен [2, inf), но производительность атрибуции начинает конвергентироваться после 50 шагов.Optional, Int 2. approximation_methodМетод для приближения целочисленного. Доступные методы приближения:riemann_middlegausslegendreOptional, String |
n_steps = 50 approximation_method = riemann_middle |
Для внутреннего алгоритма XRAI используются интегрированные градиенты. Таким образом, параметр требуется как интегрированными градиентами, n_steps так и алгоритмами XRAI. Большее количество шагов потребляет больше времени для приближения объяснений, и это может привести к проблемам времени ожидания в сетевой конечной точке.
Мы рекомендуем использовать > встроенные алгоритмы GradCAM GradCAM с управляемыми градиентами для более эффективного объяснения, в то время как управляемый управляемый GradAGation > GradCAM Integrated GradCAM >> Integrated Gradients >> XRAI рекомендуется для более быстрых объяснений в указанном порядке.
Пример запроса к конечной точке в Сети выглядит следующим образом. Этот запрос создает объяснения, если model_explainability задано значение True. Следующий запрос создает визуализации и атрибуции с помощью более быстрой версии алгоритма XRAI с 50 шагами.
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
Дополнительные сведения о создании объяснений см . в репозитории записных книжек GitHub для примеров автоматизированного машинного обучения.
Интерпретация визуализаций
Развернутая конечная точка возвращает строку образа в кодировке Base64, если и то, model_explainability и visualizations другое.True Декодируйте строку base64, как описано в записных книжках или используйте следующий код для декодирования и визуализации строк изображения base64 в прогнозе.
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
На следующем рисунке описывается визуализация объяснений для примера входного изображения.

Декодированные фигуры base64 содержат четыре раздела изображения в сетке 2 x 2.
- Изображение в левом верхнем углу (0, 0) — это обрезанный входной образ
- Изображение в правом верхнем углу (0, 1) — это тепловая карта на цветной шкале bgyw (синий зеленый желтый белый), где вклад белых пикселей в прогнозируемый класс является самым высоким и голубым пикселями является самым низким.
- Изображение в левом нижнем углу (1, 0) смешано тепловой карты возмездий на обрезанное входное изображение
- Изображение в правом нижнем углу (1, 1) — это обрезанный входной образ с верхним 30 процентами пикселей на основе показателей атрибуции.
Интерпретация атрибуции
Развернутая конечная точка возвращает атрибуцию, если model_explainability и то, и attributions другое.True Дополнительные сведения см. в многоклассовой классификации и записных книжках классификации с несколькими метками.
Эти атрибуции дают пользователям больше контроля, чтобы создавать пользовательские визуализации или проверять уровень пикселя на оценках. В следующем фрагменте кода описывается способ создания пользовательских визуализаций с помощью матрицы атрибуции. Дополнительные сведения о схеме атрибуции для классификации нескольких классов и классификации с несколькими метками см. в документации по схеме.
Используйте точные valid_resize_size и valid_crop_size значения выбранной модели для создания объяснений (значения по умолчанию — 256 и 224 соответственно). Следующий код использует функции визуализации Captum для создания пользовательских визуализаций. Пользователи могут использовать любую другую библиотеку для создания визуализаций. Дополнительные сведения см. в служебных программе визуализации captum.
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
Большие наборы данных
Если вы используете AutoML для обучения на больших наборах данных, существуют некоторые экспериментальные параметры, которые могут быть полезны.
Важно!
Эти параметры в настоящее время находятся в общедоступной предварительной версии. Они предоставляются без соглашения об уровне обслуживания. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Обучение с несколькими GPU и несколькими узлами
По умолчанию каждая модель обучается на одной виртуальной машине. Если обучение модели занимает слишком много времени, использование виртуальных машин, содержащих несколько GPU, может помочь. Время обучения модели на больших наборах данных должно уменьшиться примерно линейной пропорции к количеству используемых GPU. (Например, модель должна обучаться примерно в два раза быстрее на виртуальной машине с двумя GPU, как на виртуальной машине с одним GPU.) Если время обучения модели по-прежнему высоко на виртуальной машине с несколькими GPU, можно увеличить количество виртуальных машин, используемых для обучения каждой модели. Аналогично обучению с несколькими GPU, время обучения модели на больших наборах данных также должно уменьшиться примерно линейной пропорции к количеству используемых виртуальных машин. При обучении модели на нескольких виртуальных машинах обязательно используйте номер SKU вычислений, поддерживающий InfiniBand для получения наилучших результатов. Можно настроить количество виртуальных машин, используемых для обучения одной модели, задав node_count_per_trial свойство задания AutoML.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
properties:
node_count_per_trial: "2"
Потоковая передача файлов изображений из хранилища
По умолчанию все файлы изображений загружаются на диск до обучения модели. Если размер файлов образа превышает доступное место на диске, задание завершается сбоем. Вместо скачивания всех образов на диск можно выбрать потоковую передачу файлов изображений из хранилища Azure по мере их необходимости во время обучения. Файлы изображений передаются из хранилища Azure непосредственно в системную память, обходя диск. В то же время максимальное количество файлов из хранилища кэшируются на диске, чтобы свести к минимуму количество запросов к хранилищу.
Примечание.
Если потоковая передача включена, убедитесь, что учетная запись хранения Azure находится в том же регионе, что и вычислительные ресурсы, чтобы свести к минимуму затраты и задержки.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
training_parameters:
advanced_settings: >
{"stream_image_files": true}
Примеры записных книжек
Изучите подробные примеры кода и варианты использования в репозитории записных книжек GitHub для автоматизированных примеров машинного обучения. Проверьте папки с префиксом automl-image-, чтобы получить примеры, относящиеся к созданию моделей компьютерного зрения.
Примеры кода
Изучите подробные примеры кода и варианты использования в репозитории azureml-examples для примеров автоматизированного машинного обучения.