Запрос и сравнение экспериментов и запусков с помощью MLflow
Эксперименты и задания (или запуски) в Машинное обучение Azure можно запрашивать с помощью MLflow. Вам не нужно устанавливать определенный пакет SDK для управления тем, что происходит внутри обучающего задания, создавая более простой переход между локальными запусками и облаком, удаляя облачные зависимости. В этой статье вы узнаете, как запрашивать и сравнивать эксперименты и выполняться в рабочей области с помощью Машинное обучение Azure и пакета SDK MLflow в Python.
MLflow позволяет выполнить следующие операции:
- Создание, запрос, удаление и поиск экспериментов в рабочей области.
- Запрос, удаление и поиск запусков в рабочей области.
- Отслеживайте и извлеките метрики, параметры, артефакты и модели из запусков.
Подробное сравнение MLflow с открытым исходным кодом и MLflow при подключении к Машинное обучение Azure см. в матрице поддержки для запросов и экспериментов в Машинное обучение Azure.
Примечание.
Пакет SDK для Python версии 2 Машинное обучение Azure не предоставляет собственные возможности ведения журнала или отслеживания. Это относится не только к ведению журнала, но и к запросу зарегистрированных метрик. Вместо этого используйте MLflow для управления экспериментами и запусками. В этой статье объясняется, как использовать MLflow для управления экспериментами и выполнениями в Машинное обучение Azure.
Вы также можете запрашивать и выполнять эксперименты и выполнять их с помощью REST API MLflow. Пример использования MLflow REST с Машинное обучение Azure см. в статье об использовании MLflow REST.
Необходимые компоненты
Установите пакет
mlflowSDK MLflow и подключаемый модуль Машинное обучение Azure для MLflowazureml-mlflow.pip install mlflow azureml-mlflowСовет
Вы можете использовать
mlflow-skinnyпакет, который является упрощенным пакетом MLflow без хранилища SQL, сервера, пользовательского интерфейса или зависимостей для обработки и анализа данных.mlflow-skinnyрекомендуется для пользователей, которым в первую очередь нужны возможности отслеживания и ведения журнала MLflow, не импортируя полный набор функций, включая развертывания.Рабочая область Машинного обучения Azure. Вы можете создать его, следуя руководству по созданию ресурсов машинного обучения.
Если вы выполняете удаленное отслеживание (то есть выполняется отслеживание экспериментов, выполняемых вне Машинное обучение Azure), настройте MLflow для указания URI отслеживания рабочей области Машинное обучение Azure. Дополнительные сведения о подключении MLflow к рабочей области см. в разделе "Настройка MLflow" для Машинное обучение Azure.
Запросы и поиск экспериментов
Используйте MLflow для поиска экспериментов в рабочей области. См. следующие примеры.
Получите все активные эксперименты:
mlflow.search_experiments()Примечание.
Вместо этого используйте метод
mlflow.list_experiments()в устаревших версиях MLflow (<2.0).Получите все эксперименты, включая архивированные:
from mlflow.entities import ViewType mlflow.search_experiments(view_type=ViewType.ALL)Получите конкретный эксперимент по имени:
mlflow.get_experiment_by_name(experiment_name)Получите конкретный эксперимент по идентификатору:
mlflow.get_experiment('1234-5678-90AB-CDEFG')
Поиск экспериментов
Методsearch_experiments(), доступный с версии Mlflow 2.0, позволяет искать эксперименты, соответствующие критериям.filter_string
Получение нескольких экспериментов на основе идентификаторов:
mlflow.search_experiments(filter_string="experiment_id IN (" "'CDEFG-1234-5678-90AB', '1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')" )Извлеките все эксперименты, созданные после заданного времени:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_experiments(filter_string=f"creation_time > {int(dt.timestamp())}")Получите все эксперименты с заданным тегом:
mlflow.search_experiments(filter_string=f"tags.framework = 'torch'")
Выполнение запросов и поиска
MLflow позволяет выполнять поиск в любом эксперименте, включая несколько экспериментов одновременно. Метод mlflow.search_runs() принимает аргумент experiment_ids и experiment_name указывает, какие эксперименты требуется выполнить поиск. Кроме того, можно указать search_all_experiments=True , нужно ли выполнять поиск по всем экспериментам в рабочей области:
По имени эксперимента:
mlflow.search_runs(experiment_names=[ "my_experiment" ])По идентификатору эксперимента:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ])Выполните поиск по всем экспериментам в рабочей области:
mlflow.search_runs(filter_string="params.num_boost_round='100'", search_all_experiments=True)
Обратите внимание, что experiment_ids поддерживает предоставление массива экспериментов, поэтому при необходимости можно выполнять поиск по нескольким экспериментам. Это может быть полезно в случае, если вы хотите сравнить запуски одной и той же модели при входе в разные эксперименты (например, различными людьми или различными итерациями проекта).
Внимание
Если experiment_ids, experiment_namesили search_all_experiments не указано, MLflow выполняет поиск по умолчанию в текущем активном эксперименте. Вы можете задать активный эксперимент с помощью mlflow.set_experiment().
По умолчанию MLflow возвращает данные в формате Pandas Dataframe, что упрощает дальнейший анализ запусков. Возвращаемые данные содержат столбцы со следующими сведениями:
- Базовая информация о запуске.
- Параметры с именем столбца
params.<parameter-name>. - Метрики (последнее зарегистрированное значение каждой метрики) с именем столбца
metrics.<metric-name>.
Все метрики и параметры также возвращаются при выполнении запросов. Однако для метрик, содержащих несколько значений (например, кривую потери или кривую PR), возвращается только последнее значение метрики. Если вы хотите получить все значения заданной метрики, используйте метод mlflow.get_metric_history. Пример см. в статье "Получение парам и метрик" из запуска .
Запуски заказа
По умолчанию эксперименты находятся в порядке убывания по времени, по которому эксперимент был помещен в очередь start_timeв Машинное обучение Azure. Однако это можно изменить с помощью параметра order_by.
Порядок выполняется по атрибутам, например
start_time:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.start_time DESC"])Заказ выполняется и ограничивает результаты. В следующем примере возвращается последний один запуск в эксперименте:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["attributes.start_time DESC"])Порядок выполняется атрибутом
duration:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.duration DESC"])Совет
attributes.durationне присутствует в MLflow OSS, но предоставляется в Машинное обучение Azure для удобства.Порядок выполняется по значениям метрик:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ]).sort_values("metrics.accuracy", ascending=False)Предупреждение
Использование
order_byс выражениями, содержащимиmetrics.*,params.*илиtags.*в параметреorder_byв настоящее время не поддерживается. Вместо этого используйтеorder_valuesметод из Pandas, как показано в примере.
Фильтрация запусков
Также можно выполнить поиск запуска с определенным сочетанием гиперпараметров. Для этого используется параметр filter_string. Используйте params для доступа к параметрам запуска, для доступа к метрикам, metrics вошедшего в систему, и attributes для доступа к сведениям о выполнении. MLflow поддерживает выражения, присоединенные ключевым словом AND (синтаксис не поддерживает OR):
Поиск выполняется на основе значения параметра:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="params.num_boost_round='100'")Предупреждение
Только операторы
=иlike!=поддерживаются для фильтрацииparameters.Поиск выполняется на основе значения метрики:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="metrics.auc>0.8")Поиск выполняется с заданным тегом:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="tags.framework='torch'")Выполнение поиска, созданное заданным пользователем:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.user_id = 'John Smith'")Поиск выполняется сбоем. Сведения о возможных значениях см. в разделе " Фильтр" по состоянию :
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.status = 'Failed'")Выполнение поиска, созданное после заданного времени:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.creation_time > '{int(dt.timestamp())}'")Совет
Для ключа
attributesзначения всегда должны быть строками и поэтому кодируются между кавычками.Выполнение поиска, которое занимает больше одного часа:
duration = 360 * 1000 # duration is in milliseconds mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.duration > '{duration}'")Совет
attributes.durationне присутствует в MLflow OSS, но предоставляется в Машинное обучение Azure для удобства.Выполняется поиск с идентификатором в заданном наборе:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.run_id IN ('1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')")
Фильтрация запусков по состоянию
При фильтрации по состоянию MLflow использует другое соглашение для именования другого возможного состояния выполнения по сравнению с Машинное обучение Azure. В таблице ниже приведены возможные значения.
| состояние задания Машинное обучение Azure | Атрибут attributes.status MLFlow |
Значение |
|---|---|---|
| Не начато | Scheduled |
Задание или выполнение получено Машинное обучение Azure. |
| Queue | Scheduled |
Задание или запуск были запланированы для выполнения, но еще не были запущены. |
| Подготовка | Scheduled |
Задание или запуск еще не запущено, но вычисление было выделено для его выполнения, и он готовит среду и его входные данные. |
| Выполняется | Running |
Задание или запуск сейчас находятся в состоянии активного выполнения. |
| Завершено | Finished |
Задание или выполнение выполнено без ошибок. |
| Неудачно | Failed |
Задание или выполнение было завершено с ошибками. |
| Отменено | Killed |
Задание или выполнение было отменено пользователем или завершено системой. |
Пример:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="attributes.status = 'Failed'")
Получение метрик, параметров, артефактов и моделей
search_runs Метод возвращает PandasDataframe, содержащий ограниченный объем информации по умолчанию. При необходимости можно получить объекты Python, которые могут быть полезны для получения сведений о них. Используйте параметр output_format для управления способом возврата выходных данных:
runs = mlflow.search_runs(
experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="params.num_boost_round='100'",
output_format="list",
)
Для доступа к сведениям используется элемент info. В следующем примере показано, как получить run_id:
last_run = runs[-1]
print("Last run ID:", last_run.info.run_id)
Получение парам и метрик из запуска
При возврате запусков с помощью output_format="list"можно легко получить доступ к параметрам с помощью ключа data:
last_run.data.params
Таким же образом можно запрашивать метрики:
last_run.data.metrics
Для метрик, содержащих несколько значений (например, кривой потери или кривой PR), возвращается только последнее зарегистрированное значение метрики. Если вы хотите получить все значения заданной метрики, используйте метод mlflow.get_metric_history. Для этого метода требуется использовать MlflowClient:
client = mlflow.tracking.MlflowClient()
client.get_metric_history("1234-5678-90AB-CDEFG", "log_loss")
Получение артефактов из запуска
MLflow может запрашивать любой артефакт, записанный в журнал с помощью запуска. Артефакты не могут быть доступны с помощью самого объекта выполнения, а клиент MLflow следует использовать вместо этого:
client = mlflow.tracking.MlflowClient()
client.list_artifacts("1234-5678-90AB-CDEFG")
В предыдущем методе перечислены все артефакты, зарегистрированные в ходе выполнения, но они сохраняются в хранилище артефактов (Машинное обучение Azure хранилище). Чтобы скачать любой из них, используйте метод download_artifact:
file_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path="feature_importance_weight.png"
)
Примечание.
В устаревших версиях MLflow (<2.0) используйте метод MlflowClient.download_artifacts() .
Получение моделей из запуска
Модели также могут быть зарегистрированы в запуске, а затем получены непосредственно из него. Чтобы получить модель, необходимо знать путь к артефакту, в котором он хранится. Этот метод list_artifacts можно использовать для поиска артефактов, представляющих модель, так как модели MLflow всегда являются папками. Вы можете скачать модель, указав путь, в котором хранится модель, с помощью download_artifact метода:
artifact_path="classifier"
model_local_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path=artifact_path
)
Затем можно загрузить модель обратно из скачанных артефактов с помощью типичной функции load_model в пространстве имен для конкретного вкуса. В следующем примере используется xgboost.
model = mlflow.xgboost.load_model(model_local_path)
MLflow также позволяет одновременно выполнять обе операции, а также загружать и загружать модель в одной инструкции. MLflow загружает модель во временную папку и загружает ее из нее. Метод load_model использует формат URI для указания места извлечения модели. В случае загрузки модели из запуска структура URI выглядит следующим образом:
model = mlflow.xgboost.load_model(f"runs:/{last_run.info.run_id}/{artifact_path}")
Совет
Сведения о запросах и загрузке моделей, зарегистрированных в реестре моделей, см. в разделе "Управление реестрами моделей" в Машинное обучение Azure с помощью MLflow.
Получение дочерних (вложенных) запусков
MLflow поддерживает концепцию дочерних (вложенных) запусков. Эти запуски полезны, если вам нужно отключить подпрограммы обучения, которые должны отслеживаться независимо от основного процесса обучения. Процессы оптимизации гиперпараметров или конвейеры Машинное обучение Azure являются типичными примерами заданий, которые создают несколько дочерних запусков. Вы можете запросить все дочерние запуски для определенного запуска с помощью тега свойства mlflow.parentRunId, содержащего идентификатор родительского запуска.
hyperopt_run = mlflow.last_active_run()
child_runs = mlflow.search_runs(
filter_string=f"tags.mlflow.parentRunId='{hyperopt_run.info.run_id}'"
)
Сравнение заданий и моделей в Студия машинного обучения Azure (предварительная версия)
Чтобы сравнить и оценить качество заданий и моделей в Студия машинного обучения Azure, используйте панель предварительного просмотра, чтобы включить эту функцию. После включения можно сравнить параметры, метрики и теги между выбранными заданиями и /или моделями.
Внимание
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Предварительная версия предоставляется без соглашения об уровне обслуживания и не рекомендована для производственных рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
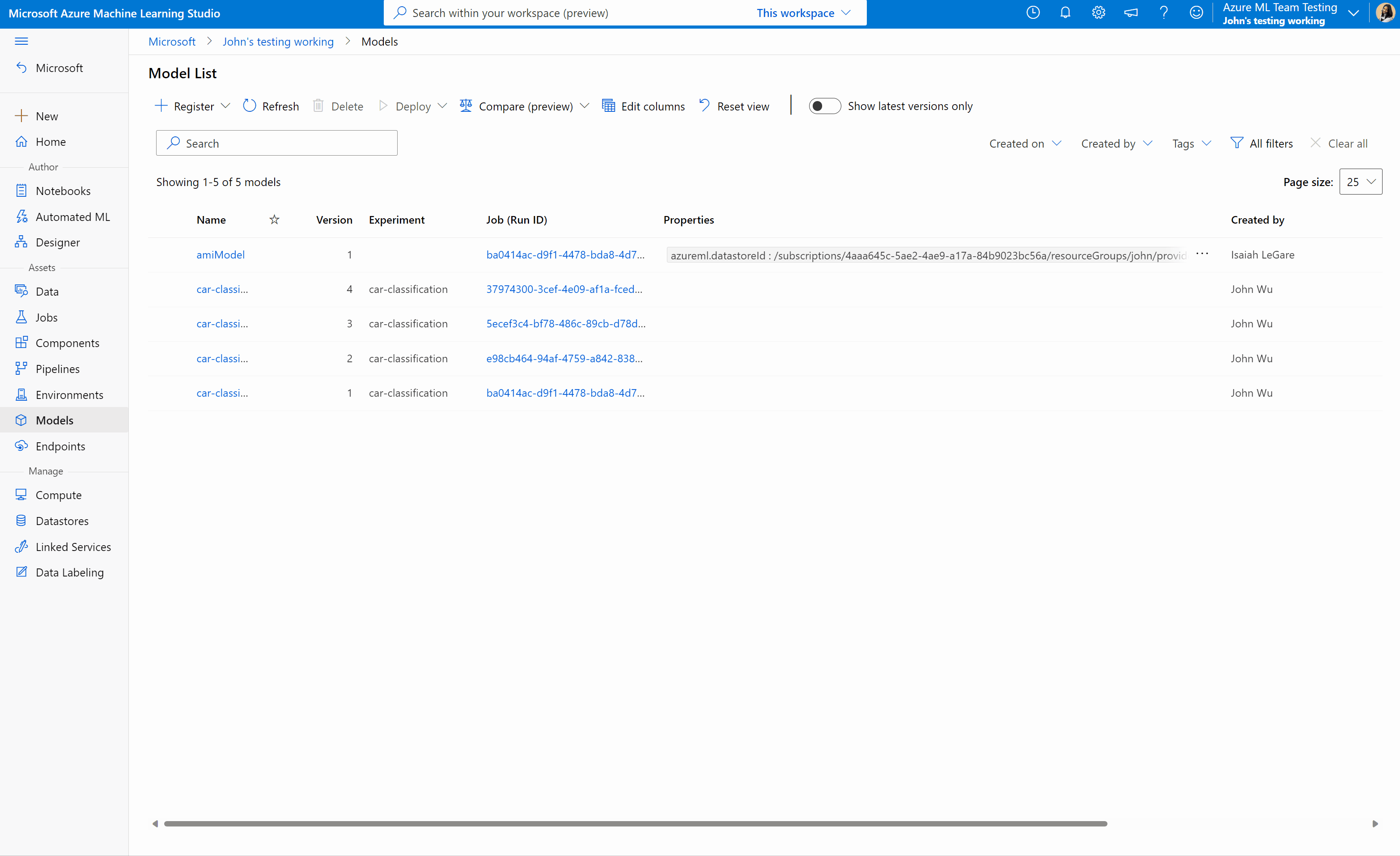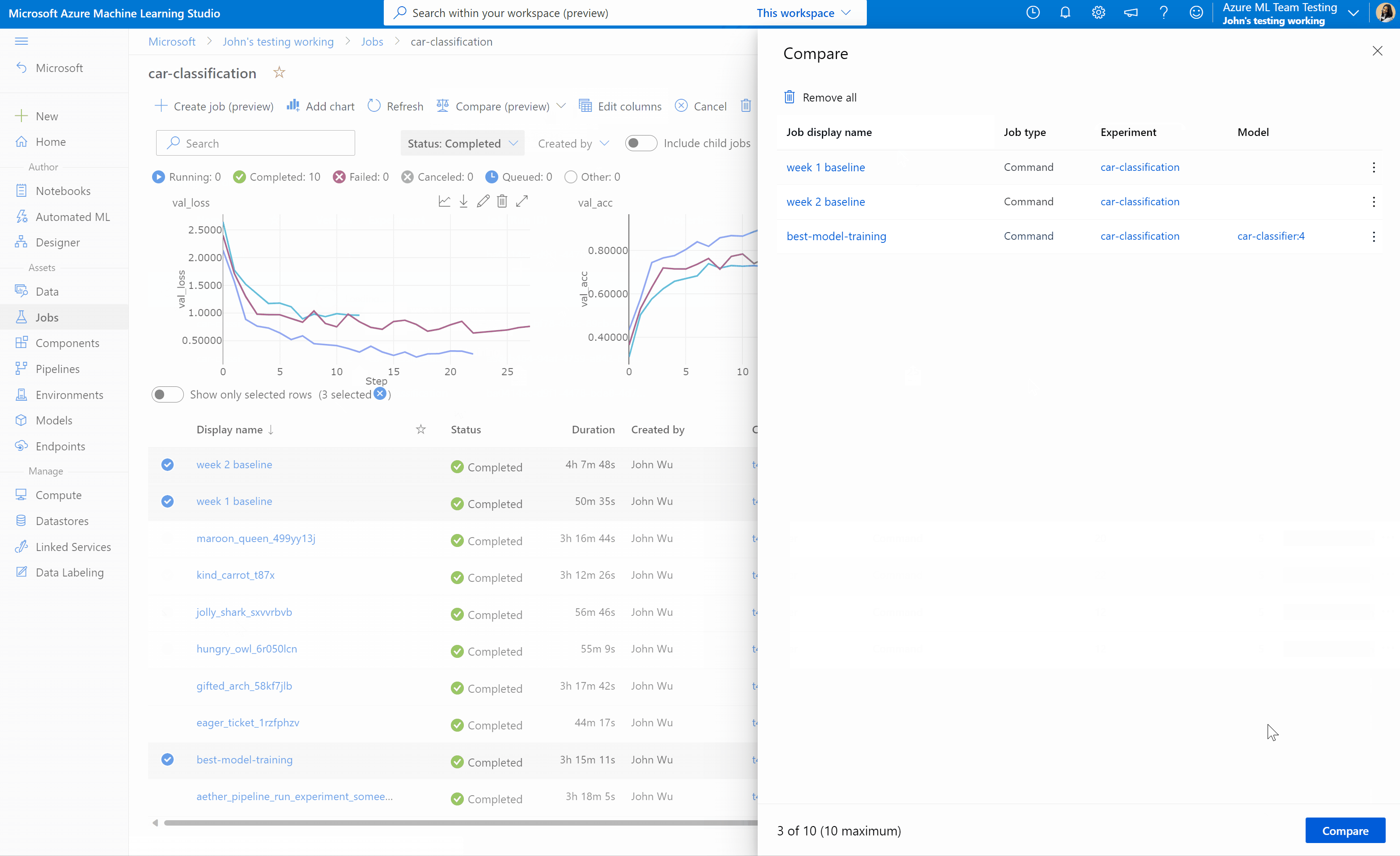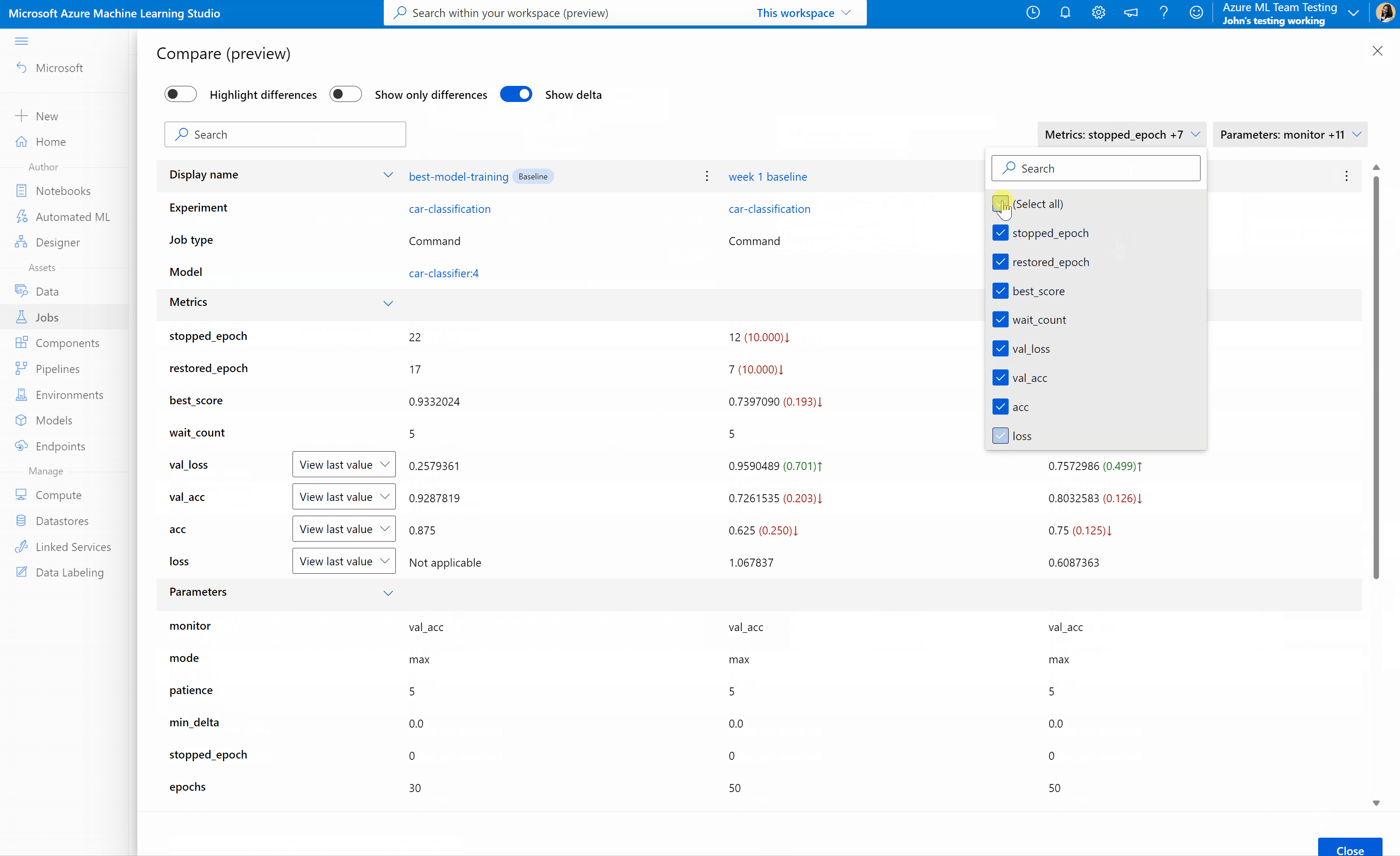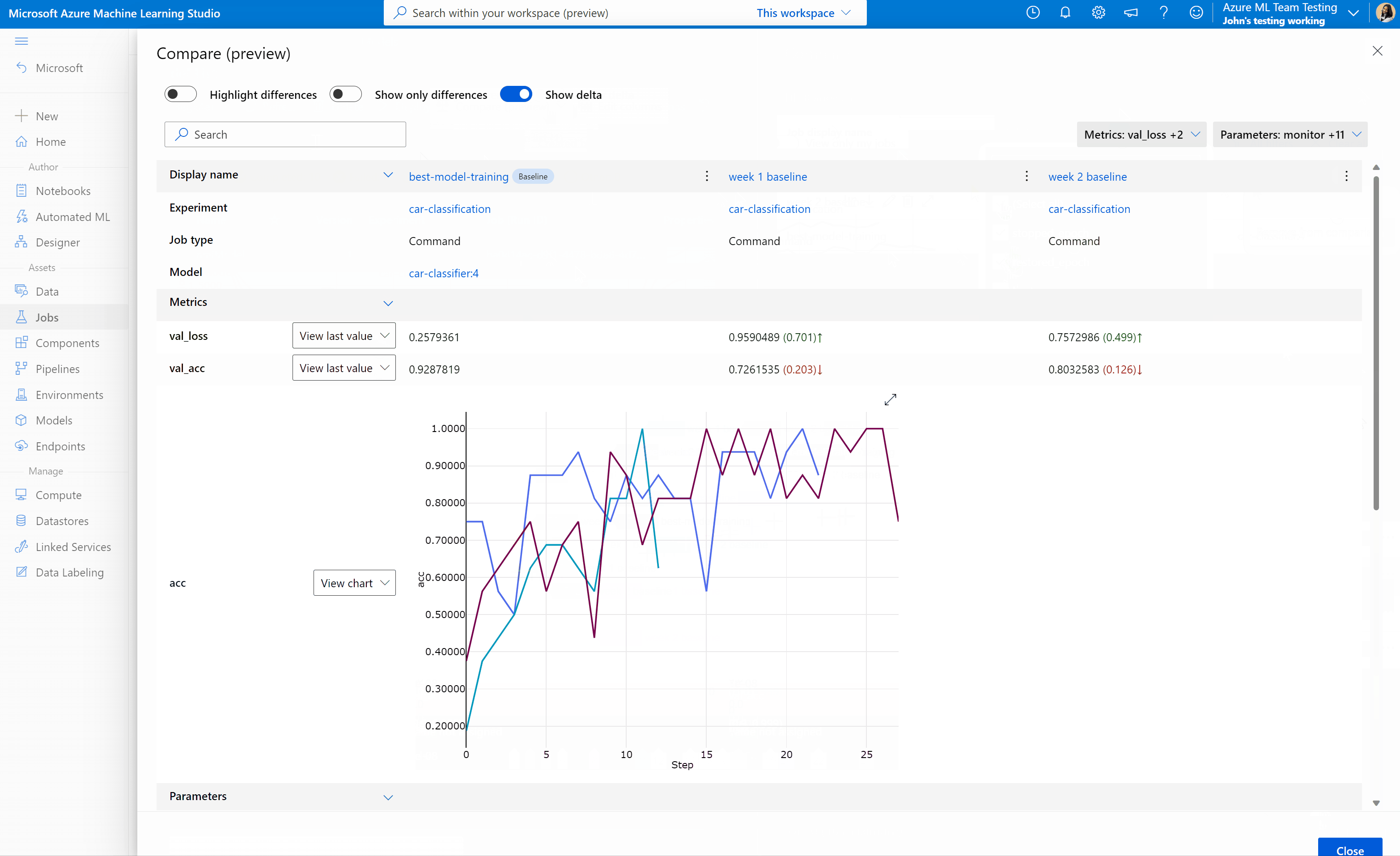
В примере MLflow с записными книжками Машинного обучения Azure демонстрируются и поясняются основные понятия, представленные в этой статье.
- Обучение и отслеживание классификатора с помощью MLflow. Демонстрируется отслеживание экспериментов с помощью MLflow, моделей журналов и объединение нескольких вкусов в конвейеры.
- Управление экспериментами и запусками с помощью MLflow: демонстрирует, как запрашивать эксперименты, запуски, метрики, параметры и артефакты из Машинное обучение Azure с помощью MLflow.
Матрица поддержки для отправки запросов к запускам и экспериментам
Пакет SDK MLflow предоставляет несколько методов для получения запусков, в том числе позволяющих контролировать, какие данные возвращаются и каким образом. В следующей таблице показано, какие из этих методов сейчас поддерживаются в MLflow при подключении к Машинному обучению Azure:
| Функция | Поддерживается MLflow | Поддерживается Машинное обучение Azure |
|---|---|---|
| Упорядочивание запусков по атрибутам | ✓ | ✓ |
| Упорядочивание запусков по метрикам | ✓ | 1 |
| Упорядочивание запусков по параметрам | ✓ | 1 |
| Упорядочивание запусков по тегам | ✓ | 1 |
| Фильтрация запусков по атрибутам | ✓ | ✓ |
| Фильтрация запусков по метрикам | ✓ | ✓ |
| Фильтрация запусков по метрикам с помощью специальных символов (escape-символов) | ✓ | |
| Фильтрация запусков по параметрам | ✓ | ✓ |
| Фильтрация запусков по тегам | ✓ | ✓ |
Фильтрация запусков с помощью числовых компараторов (метрик), включая =, !=, >, >=, < и <= |
✓ | ✓ |
Фильтрация запусков с помощью компараторов строк (параметров, тегов и атрибутов): = и != |
✓ | ✓2 |
Фильтрация запусков с помощью компараторов строк (параметров, тегов и атрибутов): LIKE/ILIKE |
✓ | ✓ |
Фильтрация запусков с помощью компраторов AND |
✓ | ✓ |
Фильтрация запусков с помощью компраторов OR |
||
| Переименование экспериментов | ✓ |
Примечание.
- 1 Проверьте, как выполнить упорядочивание разделов для инструкций и примеров достижения той же функциональности в Машинное обучение Azure.
- 2
!=для тегов, которые не поддерживаются.
Связанный контент
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по