Настройка обучения автоматизированного машинного обучения без кода для табличных данных с помощью пользовательского интерфейса студии
В этой статье описано, как настроить автоматизированные задания обучения машинного обучения с помощью Машинное обучение Azure автоматизированного машинного обучения в Студия машинного обучения Azure. Такой подход позволяет настроить задание без написания одной строки кода. Автоматизированное машинное обучение — это процесс, в котором Машинное обучение Azure выбирает лучший алгоритм машинного обучения для конкретных данных. Этот процесс позволяет быстро создавать модели машинного обучения. Дополнительные сведения см. в обзоре процесса автоматизированного машинного обучения.
В этом руководстве представлен общий обзор работы с автоматизированным машинным обучением в студии. В следующих статьях приведены подробные инструкции по работе с определенными моделями машинного обучения:
- Классификация. Руководство. Обучение модели классификации с помощью автоматизированного машинного обучения в студии
- Прогнозирование временных рядов: руководство. Прогнозирование спроса с помощью автоматизированного машинного обучения в студии
- Обработка естественного языка (NLP): настройка автоматизированного машинного обучения для обучения модели NLP (Azure CLI или пакета SDK для Python)
- Компьютерное зрение. Настройка AutoML для обучения моделей компьютерного зрения (Azure CLI или Python SDK)
- Регрессия: обучение модели регрессии с помощью автоматизированного машинного обучения (пакет SDK для Python)
Необходимые компоненты
Подписка Azure. Вы можете создать бесплатную или платную учетную запись для Машинное обучение Azure.
Машинное обучение Azure рабочей области или вычислительного экземпляра. Сведения о подготовке этих ресурсов см. в кратком руководстве по началу работы с Машинное обучение Azure.
Ресурс данных, используемый для задания обучения автоматизированного машинного обучения. В этом руководстве описывается, как выбрать существующий ресурс данных или создать ресурс данных из источника данных, например локальный файл, url-адрес или хранилище данных. Дополнительные сведения см. в статье "Создание ресурсов данных и управление ими".
Внимание
Существует два требования для обучающих данных:
- Данные должны находиться в табличной форме.
- Значение для прогнозирования (целевого столбца) должно присутствовать в данных.
Создание эксперимента
Создайте и запустите эксперимент, выполнив следующие действия.
Войдите в Студия машинного обучения Azure и выберите подписку и рабочую область.
В меню слева выберите "Автоматизированное машинное обучение" в разделе "Разработка ".
При первом работе с экспериментами в студии вы увидите пустой список и ссылки на документацию. В противном случае отображается список последних экспериментов автоматизированного машинного обучения, включая элементы, созданные с помощью пакета SDK Машинное обучение Azure.
Выберите новое автоматическое задание машинного обучения для запуска процесса отправки автоматизированного задания машинного обучения.
По умолчанию процесс выбирает параметр "Обучение автоматически" на вкладке "Метод обучения" и продолжается в параметрах конфигурации.
На вкладке "Основные параметры " введите значения необходимых параметров, включая имя задания и имя эксперимента . Кроме того, можно указать значения для необязательных параметров.
Выберите Далее для продолжения.

Определение ресурса данных
На вкладке "Тип задачи" и "Данные " укажите ресурс данных для эксперимента и модель машинного обучения, используемую для обучения данных.
В этом руководстве можно использовать существующий ресурс данных или создать новый ресурс данных из файла на локальном компьютере. Страницы пользовательского интерфейса студии изменяются на основе выбранного источника данных и типа модели обучения.
Если вы решили использовать существующий ресурс данных, перейдите к разделу "Настройка модели обучения".
Чтобы создать новый ресурс данных, выполните следующие действия.
Чтобы создать новый ресурс данных из файла на локальном компьютере, нажмите кнопку "Создать".
На странице типа данных:
- Введите имя ресурса данных.
- В поле "Тип" выберите табличный элемент в раскрывающемся списке.
- Выберите Далее.
На странице источника данных выберите "Из локальных файлов".
Машинное обучение Studio добавляет дополнительные параметры в меню слева, чтобы настроить источник данных.
Нажмите кнопку "Далее" на странице типа хранилища назначения, где указывается служба хранилища Azure расположение для отправки ресурса данных.
Вы можете указать контейнер хранилища по умолчанию, автоматически созданный в рабочей области, или выбрать контейнер хранилища, используемый для эксперимента.
- Для типа хранилища данных выберите Хранилище BLOB-объектов Azure.
- В списке хранилищ данных выберите workspaceblobstore.
- Выберите Далее.
На странице выбора файлов и папок используйте раскрывающееся меню "Отправить файлы" или "Отправить файлы" и выберите параметр "Отправить файлы" или "Отправить папку".
- Перейдите к расположению данных для отправки и нажмите кнопку "Открыть".
- После отправки файлов нажмите кнопку "Далее".
Машинное обучение Studio проверяет и отправляет данные.
Примечание.
Если данные стоят за виртуальной сетью, необходимо включить функцию "Пропустить проверку ", чтобы обеспечить доступ к данным рабочей области. Дополнительные сведения см. в статье Использование Студии машинного обучения Azure в виртуальной сети Azure.
Проверьте отправленные данные на странице "Параметры" для точности. Поля на странице предварительно заполнены на основе типа файла данных:
Поле Description Формат файлов Свойство определяет структуру и тип данных, хранящихся в файле. Разделитель Определяет один или несколько символов для указания границы между отдельными, независимыми регионами в виде обычного текста или других потоков данных. Кодирование Определяет, какой бит следует использовать в таблице схемы символов, чтобы считать набор данных. Заголовки столбцов Указывает, как обрабатываются заголовки набора данных, если таковые имеются. Пропуск строк Указывает, сколько строк, если таковые имеются, пропускается в наборе данных. Нажмите кнопку "Далее ", чтобы перейти на страницу схемы . Эта страница также предварительно заполнена на основе выбранных параметров . Вы можете настроить тип данных для каждого столбца, просмотреть имена столбцов и управлять столбцами:
- Чтобы изменить тип данных для столбца, используйте раскрывающееся меню "Тип " для выбора параметра.
- Чтобы исключить столбец из ресурса данных, переключите параметр "Включить " для столбца.
Нажмите кнопку "Далее ", чтобы продолжить просмотр страницы. Просмотрите сводку параметров конфигурации для задания и нажмите кнопку "Создать".
Настройка модели обучения
Когда ресурс данных готов, Машинное обучение studio возвращается на вкладку "Тип задачи" и "Данные" для процесса отправки автоматизированного задания машинного обучения. Новый ресурс данных отображается на странице.
Выполните следующие действия, чтобы завершить настройку задания:
Разверните раскрывающееся меню "Выбор типа задачи" и выберите модель обучения, используемую для эксперимента. К ним относятся классификация, регрессия, прогнозирование временных рядов, обработка естественного языка (NLP) или компьютерное зрение. Дополнительные сведения об этих параметрах см. в описаниях поддерживаемых типов задач.
После указания модели обучения выберите набор данных в списке.
Нажмите кнопку "Далее ", чтобы перейти на вкладку "Параметры задачи".
В раскрывающемся списке целевого столбца выберите столбец , используемый для прогнозирования модели.
В зависимости от модели обучения настройте следующие необходимые параметры:
Классификация: выберите, следует ли включить глубокое обучение.
Прогнозирование временных рядов: выберите, следует ли включить глубокое обучение и подтвердить параметры необходимых параметров:
Используйте столбец time, чтобы указать данные времени, используемые в модели.
Выберите, следует ли включить один или несколько параметров автоматического набора . При отмене выбора параметра автодететирования, например горизонта прогнозирования автодететов, можно указать определенное значение. Значение горизонта прогнозирования указывает, сколько единиц времени (минуты/часы/дни/недели/месяцы/годы) модель может прогнозировать в будущем. Далее в будущее модель требуется для прогнозирования, чем меньше точность модели становится.
Дополнительные сведения о настройке этих параметров см. в статье "Использование автоматизированного машинного обучения" для обучения модели прогнозирования временных рядов.
Обработка естественного языка: подтвердите параметры необходимых параметров:
Используйте параметр "Выбор подтипа", чтобы настроить тип подкласса для модели NLP. Вы можете выбрать классификацию нескольких классов, классификацию многометок и распознавание именованных сущностей (NER).
В разделе "Параметры очистки" укажите значения для алгоритма slack factor и выборки.
В разделе "Пространство поиска" настройте набор параметров алгоритма модели.
Дополнительные сведения о настройке этих параметров см. в статье Настройка автоматизированного машинного обучения для обучения модели NLP (Azure CLI или пакета SDK для Python).
Компьютерное зрение: выберите, следует ли включить очистку вручную и подтвердить параметры необходимых параметров:
- Используйте параметр "Выбрать подтип", чтобы настроить тип подкласса для модели компьютерного зрения. Вы можете выбрать классификацию изображений (мультикласс) или (многоэтапную), обнаружение объектов и многоугольник (сегментацию экземпляров).
Дополнительные сведения о настройке этих параметров см. в статье Настройка AutoML для обучения моделей компьютерного зрения (Azure CLI или Python SDK).
Указание необязательных параметров
Машинное обучение Studio предоставляет дополнительные параметры, которые можно настроить на основе выбора модели машинного обучения. В следующих разделах описаны дополнительные параметры.
Настройка дополнительных параметров
Вы можете выбрать параметр "Просмотреть дополнительные параметры конфигурации" , чтобы просмотреть действия для выполнения данных в подготовке к обучению.
На странице "Дополнительная конфигурация" отображаются значения по умолчанию на основе выбора и данных эксперимента. Значения по умолчанию можно использовать или настроить следующие параметры:
| Параметр | Description |
|---|---|
| Первичная метрика | Определите основную метрику для оценки модели. Дополнительные сведения см. в разделе метрики модели. |
| Включение стека ансамбля | Разрешить обучение ансамблям и улучшить результаты машинного обучения и прогнозную производительность путем объединения нескольких моделей в отличие от использования отдельных моделей. Дополнительные сведения см. в моделях ансамбля. |
| Использование всех поддерживаемых моделей | Используйте этот параметр, чтобы указать автоматизированному машинному обучению, следует ли использовать все поддерживаемые модели в эксперименте. Дополнительные сведения см. в поддерживаемых алгоритмах для каждого типа задачи. — выберите этот параметр, чтобы настроить параметр заблокированных моделей. — отмените выбор этого параметра, чтобы настроить параметр разрешенных моделей. |
| Заблокированные модели | (Доступно, когда Выбраны все поддерживаемые модели ) Используйте раскрывающийся список и выберите модели для исключения из задания обучения. |
| Разрешенные модели | (Доступно, когда Использовать все поддерживаемые модели не выбраны) Используйте раскрывающийся список и выберите модели, используемые для задания обучения. Важно. Доступно только для экспериментов пакета SDK. |
| Объяснить лучшую модель | Выберите этот параметр, чтобы автоматически показать объяснимость для оптимальной модели, созданной автоматизированным машинным обучением. |
| Метка положительного класса | Введите метку автоматизированного машинного обучения, используемую для вычисления двоичных метрик. |
Настройка параметров признаков
Вы можете выбрать параметр "Параметры представления признаков" , чтобы просмотреть действия для выполнения данных в подготовке к обучению.
На странице "Признаки" показаны методы инициализации признаков по умолчанию для столбцов данных. Вы можете включить и отключить автоматическую поддержку признаков и настроить параметры автоматической инициализации для эксперимента.

Выберите параметр "Включить признаки", чтобы разрешить настройку.
Внимание
Если данные содержат нечисловые столбцы, функция признаков всегда включена.
Настройте каждый доступный столбец по мере необходимости. В следующей таблице приведены сводные данные по настройкам, доступным в данный момент в студии.
Column Пользовательская настройка Тип компонента Изменение типа значения для выбранного столбца. Impute with Выбор того, какое значение будет использоваться для подстановки отсутствующих значений в данных. 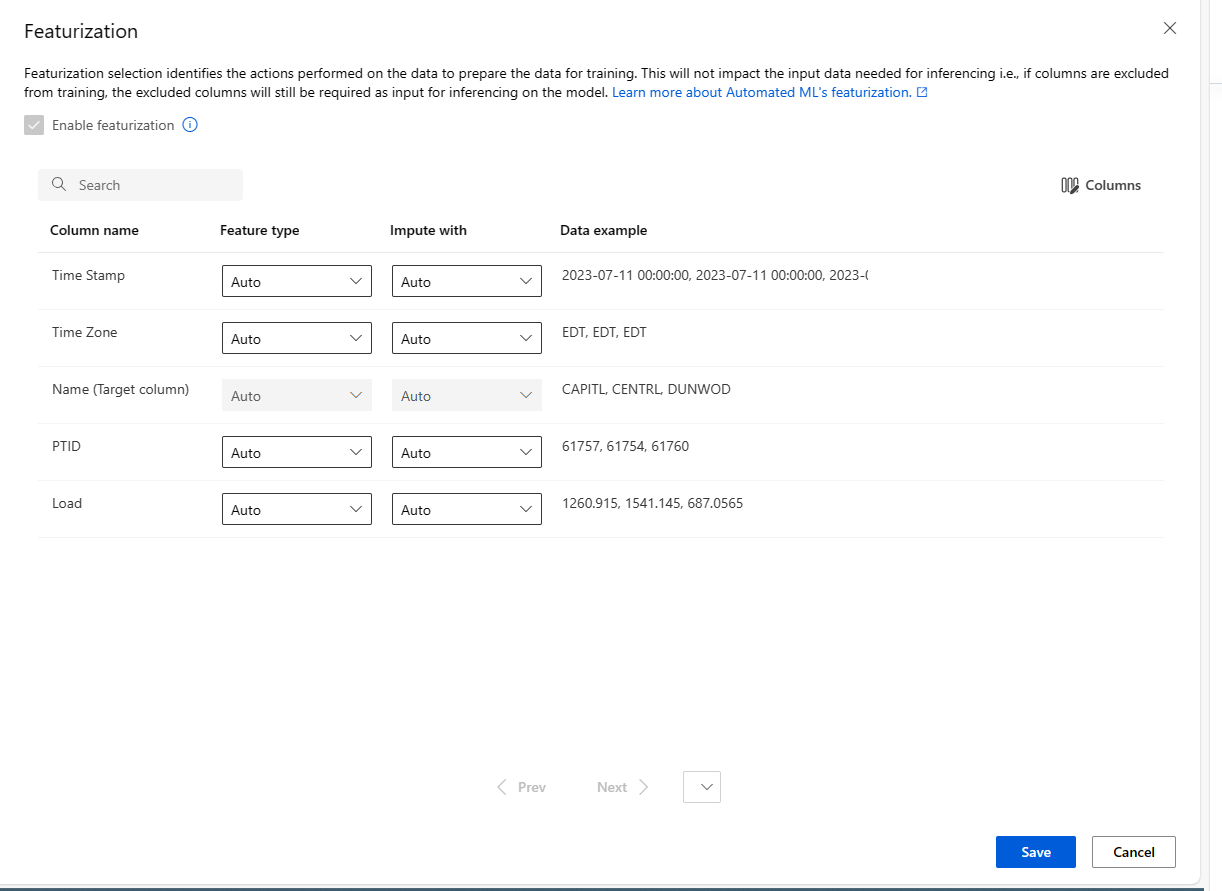

Параметры признаков не влияют на входные данные, необходимые для вывода. Если вы исключите столбцы из обучения, исключенные столбцы по-прежнему требуются в качестве входных данных для вывода в модели.
Настройка ограничений для задания
Раздел "Ограничения" предоставляет параметры конфигурации для следующих параметров:
| Параметр | Description | Значение |
|---|---|---|
| Максимальное количество пробных версий | Укажите максимальное количество проб, которые необходимо попробовать во время задания автоматизированного машинного обучения, где каждая пробная версия имеет разные сочетания алгоритмов и гиперпараметров. | Целое число от 1 до 1000 |
| Максимальное число параллельных пробных версий | Укажите максимальное количество заданий пробной версии, которые можно выполнять параллельно. | Целое число от 1 до 1000 |
| Максимальное число узлов | Укажите максимальное количество узлов, которые это задание может использовать из выбранного целевого объекта вычислений. | 1 или более в зависимости от конфигурации вычислений |
| Пороговое значение оценки метрик | Введите пороговое значение метрики итерации. Когда итерация достигает порогового значения, задание обучения завершается. Помните, что значимые модели имеют корреляцию больше нуля. В противном случае результат совпадает с угадыванием. | Среднее пороговое значение метрики между границами [0, 10] |
| Время ожидания эксперимента (минуты) | Укажите максимальное время выполнения всего эксперимента. После достижения ограничения система отменяет задание автоматизированного машинного обучения, включая все его пробные версии (дочерние задания). | Количество минут |
| Время ожидания итерации (минуты) | Укажите максимальное время выполнения каждого задания пробной версии. Когда задание пробной версии достигнет этого ограничения, система отменяет пробную версию. | Количество минут |
| Включение раннего завершения | Используйте этот параметр, чтобы завершить задание, если оценка не улучшается в краткосрочной перспективе. | Выберите параметр, чтобы включить раннее завершение задания |
Проверка и тестирование
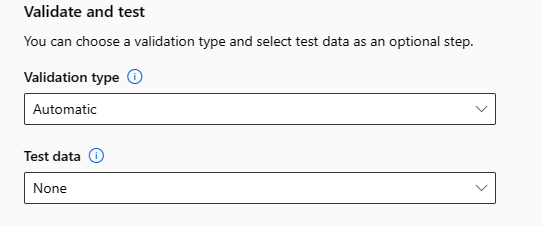
В разделе "Проверка и проверка " приведены следующие параметры конфигурации:
Укажите тип проверки, используемый для задания обучения. Если вы явно не укажете либо
validation_datan_cross_validationsпараметр, автоматизированное машинное обучение применяет методы по умолчанию в зависимости от количества строк, предоставленных в одном набореtraining_dataданных.Объем данных обучения Метод проверки Более 20 000 строк Применяется разбиение данных по обучению и проверке. Значение по умолчанию — использовать 10 % начального набора данных для обучения в качестве набора проверки. В свою очередь, этот набор проверки используется для вычисления метрик. Меньше 20 000 строк Применяется подход перекрестной проверки. Стандартное количество сверток зависит от числа строк.
- Набор данных с менее чем 1000 строк: используются 10 сверток
- Набор данных с 1000 до 20 000 строк: используются три свертыванияПредоставьте тестовые данные (предварительная версия) для оценки рекомендуемой модели, которую автоматизированное машинное обучение создает в конце эксперимента. При предоставлении тестового набора данных задание теста автоматически активируется в конце эксперимента. Это тестовое задание является единственным заданием в оптимальной модели, рекомендуемой автоматизированным машинным обучением. Дополнительные сведения см. в разделе Просмотр результатов удаленного тестового задания (предварительная версия).
Внимание
Предоставление тестового набора данных для оценки созданных моделей доступно как предварительная версия функции. Эта возможность является экспериментальной функцией предварительной версии и может изменяться в любое время.
Тестовые данные считаются отдельными от обучения и проверки, поэтому не следует предвзять результаты тестового задания рекомендуемой модели. Дополнительные сведения см. в разделе "Обучение", "Проверка" и "Тестовые данные".
Вы можете предоставить собственный тестовый набор данных или использовать часть учебного набора данных. Тестовые данные должны находиться в виде набора данных таблицы Машинное обучение Azure.
Схема тестового набора данных должна соответствовать тестовому набору данных. Целевой столбец необязателен, но если целевой столбец не указан, тестовые метрики не вычисляются.
Тестовый набор данных не должен совпадать с набором данных обучения или набором данных проверки.
Задания прогнозирования не поддерживают разделение обучения и тестирования.
Настройка вычислений
Выполните следующие действия и настройте вычислительные ресурсы:
Нажмите кнопку "Далее ", чтобы перейти на вкладку "Вычисления ".
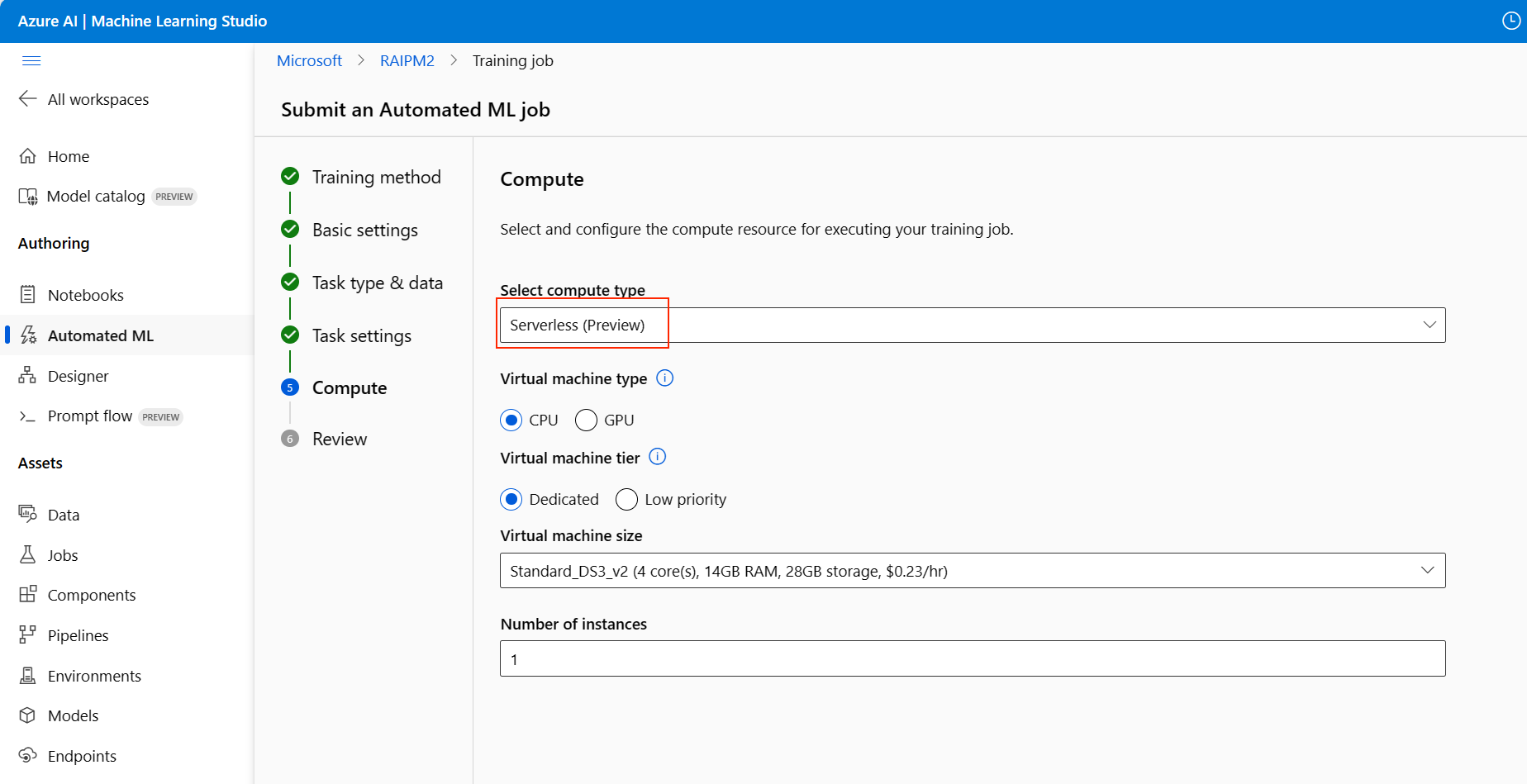
Используйте раскрывающийся список "Выбор типа вычислений", чтобы выбрать параметр для задания профилирования и обучения данных. К ним относятся вычислительный кластер, вычислительный экземпляр или бессерверный экземпляр.
После выбора типа вычислений другой пользовательский интерфейс на странице изменяется на основе выбранного варианта:
Бессерверный режим: параметры конфигурации отображаются на текущей странице. Перейдите к следующему шагу для описания параметров, которые необходимо настроить.
Вычислительный кластер или вычислительный экземпляр: выберите один из следующих вариантов:
Используйте раскрывающийся список вычислений автоматизированного машинного обучения, чтобы выбрать существующие вычислительные ресурсы для рабочей области, а затем нажмите кнопку "Далее". Перейдите к разделу "Запуск эксперимента" и просмотрите результаты .
Выберите "Создать" , чтобы создать новый вычислительный экземпляр или кластер. Откроется страница создания вычислений. Перейдите к следующему шагу для описания параметров, которые необходимо настроить.
Для бессерверных вычислений или новых вычислений настройте все необходимые (*) параметры:
Параметры конфигурации различаются в зависимости от типа вычислений. В следующей таблице приведены различные параметры, которые может потребоваться настроить:
Поле Description Имя вычислений Введите уникальное имя для идентификации контекста вычислительной среды. Местонахождение Укажите регион для компьютера. Приоритет виртуальной машины Низкоприоритетные виртуальные машины дешевле, но не гарантируют доступность вычислительных узлов. Тип виртуальной машины Выберите ЦП или GPU для типа виртуальной машины. Уровень виртуальной машины Выберите приоритет для эксперимента. Размер виртуальной машины Выберите размер виртуальной машины для вычислительной среды. Минимальное или максимальное количество узлов Чтобы профилировать данные, необходимо указать один или несколько узлов. Введите максимальное число узлов для вычислительной среды. Значение по умолчанию — шесть узлов для Машинное обучение Azure вычислений. Простой секунды до уменьшения масштаба Укажите время простоя, прежде чем кластер автоматически масштабируется до минимального количества узлов. Дополнительные настройки Эти параметры позволяют настроить учетную запись пользователя и существующую виртуальную сеть для эксперимента. После настройки необходимых параметров нажмите кнопку "Далее" или "Создать", как это необходимо.
Создание вычислительной среды может занять несколько минут. После завершения создания нажмите кнопку "Далее".
Запуск эксперимента и просмотр результатов
Выберите Готово, чтобы запустить эксперимент. Подготовка эксперимента может занять до 10 мин. Выполнение заданий обучения может занять еще 2–3 минуты для завершения работы каждого конвейера. Если вы указали для создания панели мониторинга RAI для лучшей рекомендуемой модели, это может занять до 40 минут.
Примечание.
Алгоритмы автоматизированного машинного обучения используют встроенную случайность, которая может привести к небольшим вариациям в конечной оценке метрик рекомендуемой модели, например точности. Автоматизированное машинное обучение также выполняет операции с данными, такими как разделение обучения, разделение обучения или перекрестная проверка. Если вы выполняете эксперимент с одинаковыми параметрами конфигурации и первичной метрикой несколько раз, скорее всего, вы увидите изменения в итоговой оценке метрик каждого эксперимента из-за этих факторов.
Просмотр сведений об эксперименте
Откроется экран Сведения о задании на вкладке Сведения. На этом экране отображается сводка по заданию эксперимента, в том числе строка состояния в верхней части рядом с номером задания.
Вкладка Модели содержит список созданных моделей в порядке оценки метрики. По умолчанию модель с наивысшей оценкой, полученной на основе выбранной метрики, будет в верхней части списка. По мере того как задание обучения пытается больше моделей, в список добавляются упражнение модели. Используйте этот подход для быстрого сравнения метрик для моделей, созданных до сих пор.
Просмотр сведений о задании обучения
Подробные сведения о любой из завершенных моделей для подробных сведений о задании обучения. Диаграммы метрик производительности отображаются на вкладке "Метрики" на вкладке "Метрики ". Дополнительные сведения см. в разделе "Оценка результатов эксперимента автоматизированного машинного обучения". На этой странице также можно найти сведения обо всех свойствах модели вместе с связанным кодом, дочерними заданиями и изображениями.
Просмотр результатов удаленного тестового задания (предварительная версия)
Если вы указали тестовый набор данных или решили разделить обучение или тест во время настройки эксперимента в форме проверки и тестирования , автоматизированное машинное обучение автоматически проверяет рекомендуемую модель по умолчанию. В результате автоматизированное машинное обучение вычисляет тестовые метрики для определения качества рекомендуемой модели и ее прогнозов.
Внимание
Тестирование моделей с помощью тестового набора данных для оценки созданных моделей доступно как предварительная версия функции. Эта возможность является экспериментальной функцией предварительной версии и может изменяться в любое время.
Эта функция недоступна для следующих сценариев автоматического машинного обучения:
- Задачи компьютерного зрения
- Многие модели и иерархическая подготовка по прогнозированию временных рядов (предварительная версия)
- Задачи прогнозирования, в которых активировано использование глубоких нейронных сетей обучения (DNN)
- Задания автоматизированного машинного обучения из локальных вычислений или кластеров Azure Databricks
Выполните следующие действия, чтобы просмотреть метрики тестового задания рекомендуемой модели:
В студии перейдите на страницу "Модели " и выберите лучшую модель.
Выберите вкладку Результаты теста (предварительная версия).
Выберите нужное задание и просмотрите вкладку метрик :
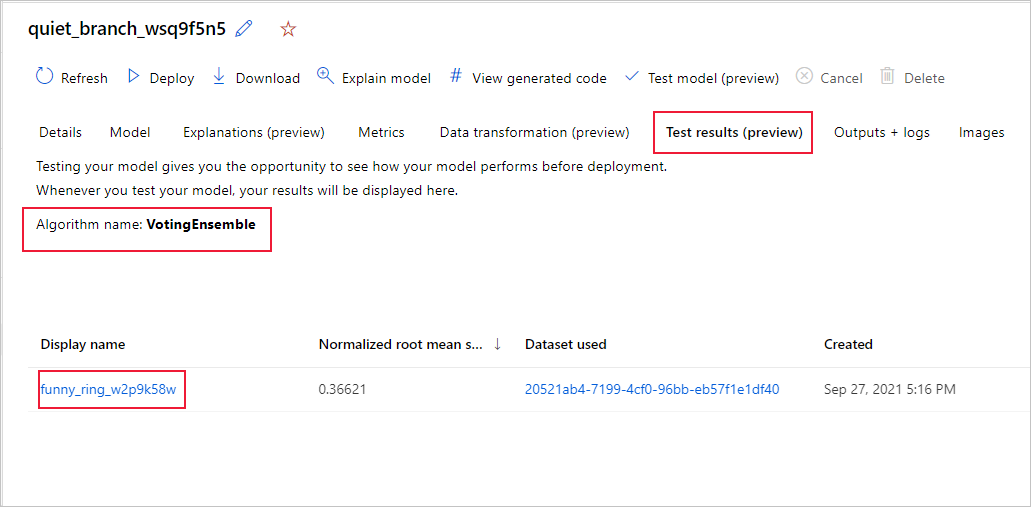
Просмотрите прогнозы теста, используемые для вычисления метрик теста, выполнив следующие действия.
В нижней части страницы выберите ссылку в разделе "Выходные данные" , чтобы открыть набор данных.
На странице Наборы данных откройте вкладку Обзор, чтобы просмотреть прогнозы из тестового задания.
Файл прогнозирования также можно просмотреть и скачать на вкладке "Выходные данные и журналы". Разверните папку "Прогнозы", чтобы найти файл prediction.csv.
Тестовое задание модели создает файл predictions.csv , хранящийся в хранилище данных по умолчанию, созданном в рабочей области. Это хранилище могут видеть все пользователи с одинаковой подпиской. Тестовые задания не рекомендуется использовать для сценариев, если какая-либо информация, используемая для или созданная тестовой задачей, должна оставаться закрытой.
Тестирование существующей модели автоматизированного машинного обучения (предварительная версия)
После завершения эксперимента можно протестировать модели автоматизированного машинного обучения, создаваемые для вас.
Внимание
Тестирование моделей с помощью тестового набора данных для оценки созданных моделей доступно как предварительная версия функции. Этот возможность является предварительной версией экспериментальной функции и может быть изменена в любое время.
Эта функция недоступна для следующих сценариев автоматического машинного обучения:
- Задачи компьютерного зрения
- Многие модели и иерархическая подготовка по прогнозированию временных рядов (предварительная версия)
- Задачи прогнозирования, в которых активировано использование глубоких нейронных сетей обучения (DNN)
- Задания автоматизированного машинного обучения из локальных вычислений или кластеров Azure Databricks
Если вы хотите протестировать другую созданную автоматизированную модель машинного обучения, а не рекомендуемую модель, выполните следующие действия.
Выберите существующее задание эксперимента автоматизированного машинного обучения.
Перейдите на вкладку "Модели" задания и выберите завершенную модель, которую вы хотите протестировать.
На странице сведений о модели выберите параметр "Тестовая модель " (предварительная версия), чтобы открыть область "Тестовые модели".
На панели Тестовая модель выберите нужный кластер и тестовый набор данных, которые хотите использовать для тестового задания.
Выберите параметр "Тест". Схема тестового набора данных должна соответствовать набору обучающих данных, но целевой столбец является необязательным.
После успешного создания тестового задания модели на странице Сведения появится сообщение об успешном выполнении. Откройте вкладку Результаты теста, чтобы увидеть ход выполнения задания.
Чтобы просмотреть результаты тестового задания, откройте страницу сведений и выполните действия, описанные в разделе "Просмотр результатов удаленного тестового задания (предварительная версия).
Панель мониторинга ответственного искусственного интеллекта (предварительная версия)
Чтобы лучше понять свою модель, вы можете просмотреть различные аналитические сведения о модели с помощью панели мониторинга ответственного искусственного интеллекта. Этот пользовательский интерфейс позволяет оценивать и отлаживать лучшую модель автоматизированного машинного обучения. Панель мониторинга ответственного искусственного интеллекта оценивает ошибки модели и проблемы справедливости, диагностировать причины возникновения ошибок путем оценки данных обучения и (или) тестирования и наблюдения за моделями. Вместе эти аналитические сведения помогут вам создать доверие с моделью и передать процессы аудита. Не удается создать панели мониторинга ИИ для существующей модели автоматизированного машинного обучения. Панель мониторинга создается только для лучшей рекомендуемой модели при создании нового задания автоматизированного машинного обучения. Пользователи должны продолжать использовать объяснения модели (предварительная версия), пока поддержка не будет предоставлена для существующих моделей.
Создайте панель мониторинга ответственного ИИ для конкретной модели, выполнив следующие действия.
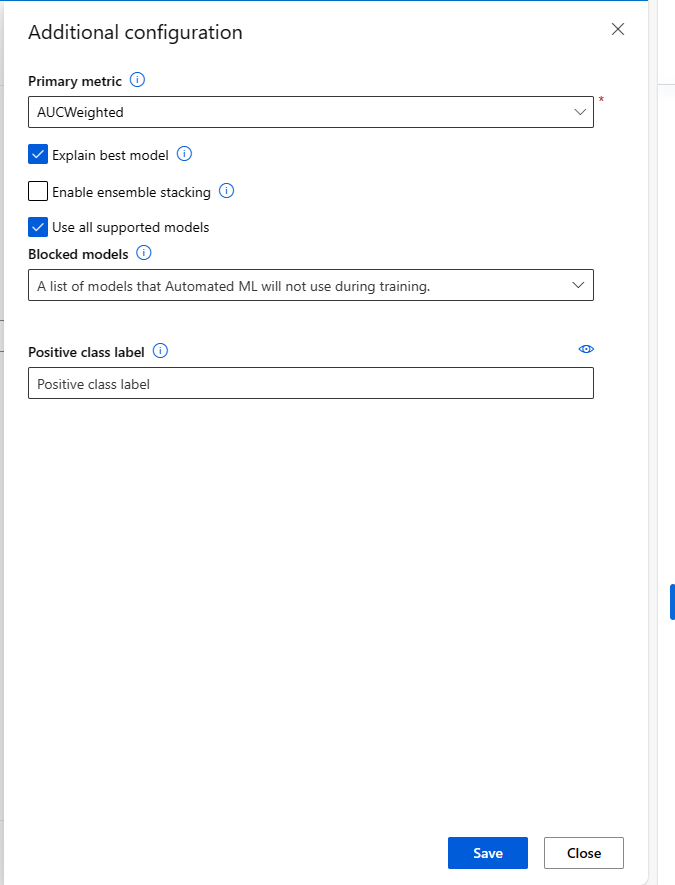
При отправке задания автоматизированного машинного обучения перейдите к разделу "Параметры задачи" в меню слева и выберите параметр "Просмотреть дополнительные параметры конфигурации ".
На странице "Дополнительная конфигурация" выберите вариант "Объяснить лучшую модель":
Перейдите на вкладку "Вычисления" и выберите бессерверный параметр для вычислений:
После завершения операции перейдите на страницу "Модели " задания автоматизированного машинного обучения, которая содержит список обученных моделей. Выберите ссылку панели мониторинга "Просмотр ответственного ИИ ":
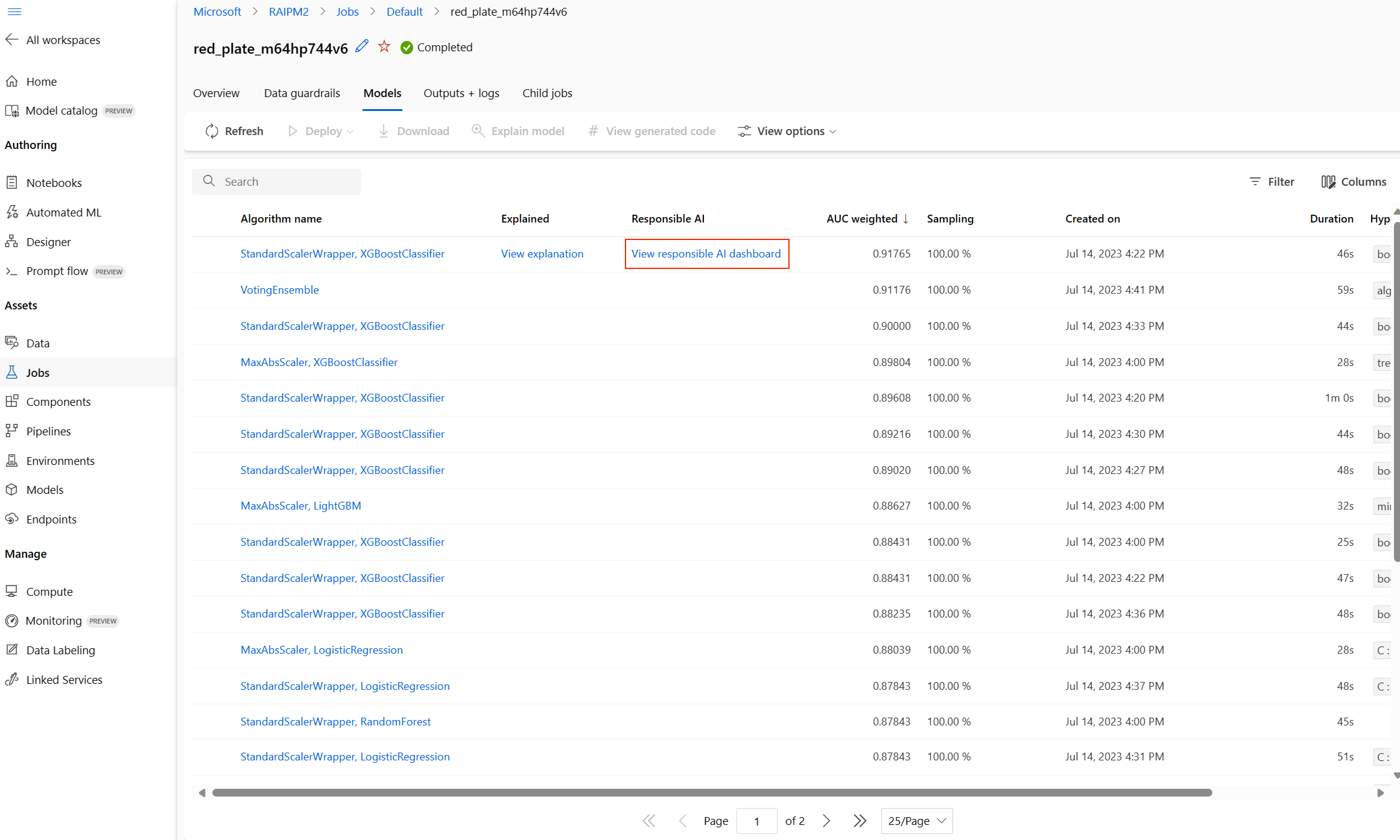
Панель мониторинга ответственного искусственного интеллекта отображается для выбранной модели:
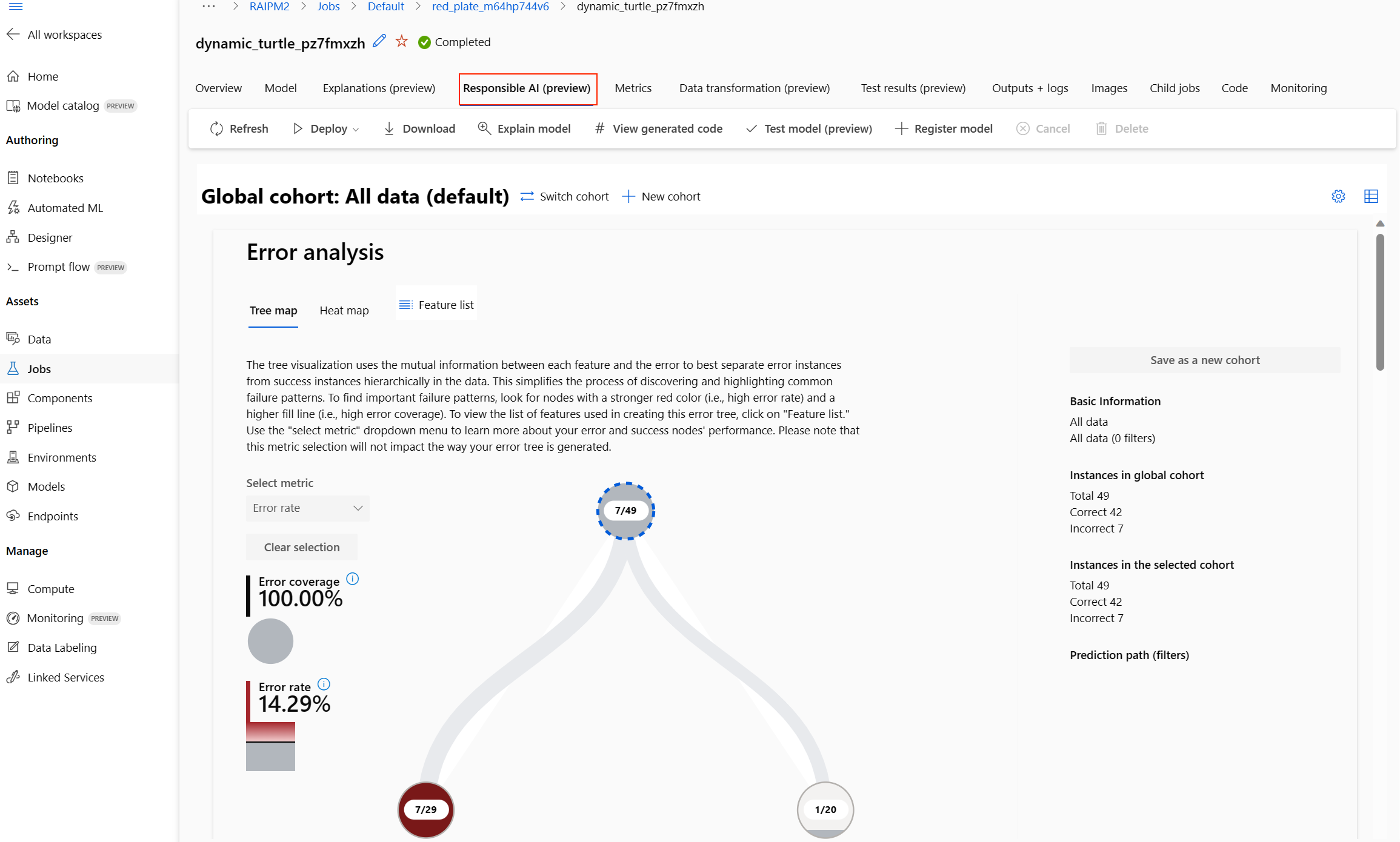
На панели мониторинга отображаются четыре компонента, активированные для оптимальной модели автоматизированного машинного обучения:
Компонент Что показывает компонент? Как прочитать диаграмму? Анализ ошибок Используйте анализ ошибок при необходимости:
— Получите глубокое представление о том, как ошибки модели распределяются по набору данных и нескольким измерениям входных и функций.
— Разбивайте статистические метрики производительности, чтобы автоматически обнаруживать ошибочные когорты, чтобы сообщить о целевых шагах по устранению рисков.Диаграммы анализа ошибок Обзор модели и справедливость Используйте этот компонент для:
— Получите глубокое представление о производительности модели в разных когортах данных.
— Понять проблемы справедливости модели, глядя на метрики неравенства. Эти метрики могут оценивать и сравнивать поведение модели между подгруппами, идентифицированными с точки зрения конфиденциальных (или нечувствительных) функций.Общие сведения о модели и диаграммы справедливости Объяснения модели Используйте компонент объяснения модели для создания понятных для человека описаний прогнозов модели машинного обучения.
- Глобальные объяснения: например, какие функции влияют на общее поведение модели распределения кредитов?
- Местные объяснения: например, почему утверждение или отклонение заявки на кредит клиента?Диаграммы объясняемости модели Анализ данных Используйте анализ данных при необходимости:
— Изучите статистику набора данных, выбрав различные фильтры, чтобы срезать данные в разные измерения (также известные как когорты).
— Общие сведения о распределении набора данных в разных группах и группах компонентов.
— Определите, являются ли ваши выводы, связанные с справедливостью, анализом ошибок и причинностью (производными от других компонентов панели мониторинга), результатом распределения набора данных.
— Определите, в каких областях требуется собирать больше данных для устранения ошибок, возникающих из проблем с представлением, шума меток, шума признаков, смещения меток и аналогичных факторов.Диаграммы обозревателя данных Кроме того, можно создать когорты (подгруппы точек данных, которые совместно используют указанные характеристики), чтобы сосредоточить анализ каждого компонента на разных когортах. Имя когорты, применяемой к панели мониторинга, всегда отображается в левом верхнем углу панели мониторинга. Представление по умолчанию на панели мониторинга — это весь набор данных с заголовком "Все данные " по умолчанию. Дополнительные сведения см. в разделе "Глобальные элементы управления " для панели мониторинга.


Изменение и отправка заданий (предварительная версия)
В сценариях, где требуется создать эксперимент на основе параметров существующего эксперимента, автоматизированное машинное обучение предоставляет параметр "Изменить и отправить " в пользовательском интерфейсе студии. Эта функция доступна только для тех экспериментов, которые инициируются из пользовательского интерфейса студии, и требует, чтобы схема данных для нового эксперимента соответствовала схеме исходного эксперимента.
Внимание
Возможность копирования, редактирования и отправки нового эксперимента на основе существующего эксперимента — это предварительная версия. Эта возможность является экспериментальной функцией предварительной версии и может изменяться в любое время.
Параметр "Изменить и отправить " открывает мастер создания нового задания автоматизированного машинного обучения с предварительно заполненными параметрами данных, вычислений и экспериментов. Вы можете настроить параметры на каждой вкладке мастера и изменить выбранные варианты при необходимости для нового эксперимента.
Развертывание модели
После получения оптимальной модели можно развернуть модель как веб-службу для прогнозирования новых данных.
Примечание.
Чтобы развернуть модель, созданную с помощью пакета с помощью automl пакета SDK для Python, необходимо зарегистрировать модель в рабочей области.
После регистрации модели можно найти модель в студии, выбрав "Модели " в меню слева. На странице обзора модели можно выбрать параметр "Развернуть " и перейти к шагу 2 в этом разделе.
Автоматизированное машинное обучение помогает развертывать модель без написания кода.
Инициируйте развертывание с помощью одного из следующих методов:
Разверните лучшую модель с заданными критериями метрик:
После завершения эксперимента выберите задание 1 и перейдите на родительскую страницу задания.
Выберите модель, указанную в разделе "Сводка по оптимальной модели", а затем нажмите кнопку "Развернуть".
Разверните итерацию конкретной модели из этого эксперимента:
- Выберите нужную модель на вкладке "Модели ", а затем нажмите кнопку "Развернуть".
Заполните область Развернуть модель:
Поле Значение Имя Введите уникальное имя развертывания. Description Введите описание, чтобы лучше определить назначение развертывания. Тип вычислений Выберите тип конечной точки для развертывания: Azure Kubernetes Service (AKS) или Экземпляр контейнера Azure (ACI). Имя вычислений (Применяется только к AKS) Выберите имя кластера AKS, в котором вы хотите развернуть. Включение проверки подлинности Выберите этот параметр, чтобы разрешить проверку подлинности на основе токенов или на основе ключей. Использование настраиваемых ресурсов развертывания Включите пользовательские ресурсы, если вы хотите отправить собственный скрипт оценки и файл среды. В противном случае автоматизированное машинное обучение предоставляет эти ресурсы по умолчанию. Дополнительные сведения см. в статье "Развертывание и оценка модели машинного обучения с помощью сетевой конечной точки". Внимание
Имена файлов должны быть от 1 до 32 символов. Имя должно начинаться и заканчиваться буквенно-цифровыми буквами, а также включать дефисы, символы подчеркивания, точки и буквенно-цифровые символы между ними. Пробелы не допускаются.
Меню "Дополнительно" предлагает функции развертывания по умолчанию, такие как сбор данных и параметры использования ресурсов. Параметры в этом меню можно использовать для переопределения этих значений по умолчанию. Дополнительные сведения см. в статье Отслеживание сетевых конечных точек.
Выберите Развернуть. Развертывание может занять около 20 минут.
После запуска развертывания откроется вкладка сводки модели. Ход развертывания можно отслеживать в разделе " Состояние развертывания".
Теперь у вас есть рабочая веб-служба для создания прогнозов! Вы можете протестировать прогнозы, запросив службу из комплексных примеров ИИ в Microsoft Fabric.