Отслеживание экспериментов машинного обучения Azure Synapse Analytics с помощью MLflow и Машинного обучения Azure
В этой статье описано, как включить MLflow для подключения к Машинному обучению Azure при работе в рабочей области Azure Synapse Analytics. Эту конфигурацию можно использовать для отслеживания, управления моделями и развертывания моделей.
MLflow — это библиотека с открытым кодом для управления жизненным циклом экспериментов машинного обучения. MLFlow Tracking — это компонент MLflow, который осуществляет мониторинг и ведение журнала метрик выполнения обучения и артефактов моделей. См. дополнительные сведения об MLflow.
Если вам нужно обучить проект MLflow с помощью Машинного обучения Azure, ознакомьтесь со статьей Обучение моделей машинного обучения с помощью проектов MLflow и Машинного обучения Azure (предварительная версия).
Необходимые компоненты
Установка библиотек
Чтобы установить библиотеки в выделенном кластере в Azure Synapse Analytics:
Создайте файл
requirements.txtс пакетами, которые требуются для ваших экспериментов, но убедитесь, что он также включает следующие пакеты:requirements.txt
mlflow azureml-mlflow azure-ai-mlПерейдите на портал рабочей области Azure Analytics.
Перейдите на вкладку Управление и выберите Пулы Apache Spark.
Щелкните три точки рядом с именем кластера и выберите Пакеты.
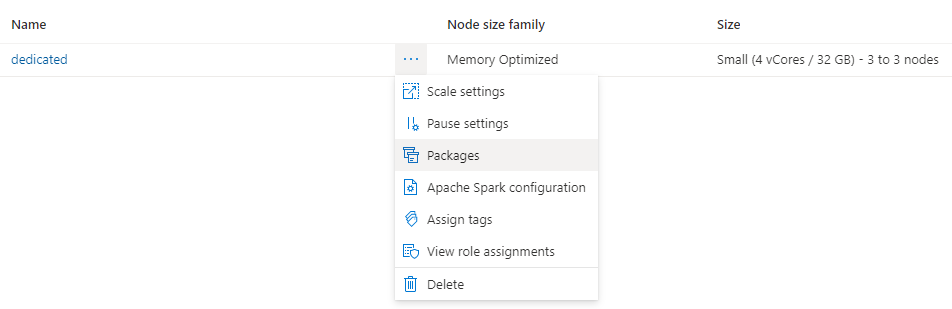
В разделе Файлы требований щелкните Отправить.
Отправьте файл
requirements.txt.Дождитесь перезапуска кластера.
Отслеживание экспериментов с помощью потока ML
Azure Synapse Analytics можно настроить для отслеживания экспериментов с помощью MLflow в рабочей области Машинного обучения Azure. Машинное обучение Azure предоставляет централизованный репозиторий для управления жизненным циклом экспериментов, моделей и развертываний. Преимущество этого решения состоит также в том, что оно упрощает развертывание с помощью вариантов развертывания Машинного обучения Azure.
Настройка записных книжек для использования MLflow с подключением к Машинному обучению Azure
Чтобы применять Машинное обучение Azure в качестве централизованного репозитория для экспериментов, можно использовать MLflow. В каждой записной книжке, над которой вы работаете, необходимо настроить URI отслеживания, чтобы он указывал на используемую рабочую область. В следующем примере показано, как это можно сделать.
Настройка URI отслеживания
Получите URI отслеживания для рабочей области:
ОБЛАСТЬ ПРИМЕНЕНИЯ:
 расширение машинного обучения Azure CLI версии 2 (текущее)
расширение машинного обучения Azure CLI версии 2 (текущее)Войдите и настройте рабочую область:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>URI отслеживания можно получить с помощью
az ml workspaceкоманды:az ml workspace show --query mlflow_tracking_uri
Настройка URI отслеживания:
Затем метод
set_tracking_uri()указывает этот URI в качестве URI отслеживания MLFLow.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)Совет
При работе с общими средами, например в кластере Azure Databricks, кластере Azure Synapse Analytics или аналогичном, рекомендуется настроить переменную
MLFLOW_TRACKING_URIсреды на уровне кластера, чтобы автоматически настроить URI отслеживания MLflow, чтобы указывать на Машинное обучение Azure для всех сеансов, выполняемых в кластере, а не для каждого сеанса.
Настройка проверки подлинности
После настройки отслеживания необходимо также настроить, как проверка подлинности должна произойти с связанной рабочей областью. По умолчанию подключаемый модуль Машинное обучение Azure для MLflow будет выполнять интерактивную проверку подлинности, открыв браузер по умолчанию для запроса учетных данных. Сведения о настройке MLflow для Машинное обучение Azure: настройте проверку подлинности для дополнительных способов настройки проверки подлинности для MLflow в Машинное обучение Azure рабочих областях.
Для интерактивных заданий, в которых есть пользователь, подключенный к сеансу, можно полагаться на интерактивную проверку подлинности, поэтому дальнейшие действия не требуются.
Предупреждение
Интерактивная проверка подлинности браузера блокирует выполнение кода при запросе учетных данных. Этот подход не подходит для проверки подлинности в автоматических средах, таких как задания обучения. Рекомендуется настроить другой режим проверки подлинности.
Для таких сценариев, когда требуется автоматическое выполнение, необходимо настроить субъект-службу для взаимодействия с Машинное обучение Azure.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Совет
При работе с общими средами рекомендуется настроить эти переменные среды на вычислительных ресурсах. Рекомендуется управлять ими в качестве секретов в экземпляре Azure Key Vault.
Например, в Azure Databricks можно использовать секреты в переменных среды, как показано в конфигурации кластера. AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}} Дополнительные сведения о реализации этого подхода в Azure Databricks см. в статье "Справочник по секрету в переменной среды" или в документации по вашей платформе.
Имена экспериментов в Машинном обучении Azure
По умолчанию Машинное обучение Azure отслеживает выполнение в эксперименте по умолчанию, который называется Default. Обычно рекомендуется настроить эксперимент, над которым вы собираетесь работать. Используйте следующий синтаксис, чтобы задать имя эксперимента:
mlflow.set_experiment(experiment_name="experiment-name")
Отслеживание параметров, метрик и артефактов
Затем вы можете использовать MLflow в Azure Synapse Analytics так же, как и раньше. Дополнительные сведения см. в разделе "Журнал и просмотр метрик" и файлов журналов.
Регистрация моделей в реестре с помощью MLflow
Модели можно зарегистрировать в рабочей области Машинного обучения Azure, которая предлагает централизованный репозиторий для управления их жизненным циклом. В следующем примере модель, обученная с помощью Spark MLLib, записывается в журнал и регистрируется в реестре.
mlflow.spark.log_model(model,
artifact_path = "model",
registered_model_name = "model_name")
Если зарегистрированная модель с именем не существует, метод регистрирует новую модель, создает версию 1 и возвращает объект ModelVersion MLflow.
Если зарегистрированная модель с таким именем уже существует, метод создает новую версию модели и возвращает объект Version.
Вы можете управлять моделями, зарегистрированными в Машинном обучении Azure, с помощью MLflow. Дополнительные сведения см. в статье Управление реестрами моделей в Машинном обучении Azure с помощью MLflow.
Развертывание и использование моделей, зарегистрированных в Машинном обучении Azure
Модели, зарегистрированные в службе "Машинное обучение Azure" с помощью MLflow, могут использоваться следующим образом:
Конечная точка Машинного обучения Azure (для использования в реальном времени и в пакетном режиме): это развертывание позволяет использовать возможности развертывания Машинного обучения Azure для получения вывода как в реальном времени, так и в пакетном режиме в Экземплярах контейнеров Azure (ACI), Azure Kubernetes (AKS) и управляемых конечных точках.
Объекты модели MLFlow или определяемые пользователем функции Pandas, которые можно использовать в записных книжках Azure Synapse Analytics в потоковых или пакетных конвейерах.
Развертывание моделей в конечных точках Машинного обучения Azure
Вы можете использовать подключаемый модуль azureml-mlflow для развертывания модели в рабочей области Машинного обучения Azure. Подробную информацию о том, как развернуть модели MLflow в разных целевых объектах, смотрите на странице Развертывание моделей MLflow.
Внимание
Чтобы развернуть модели, их необходимо зарегистрировать в реестре Машинного обучения Azure. Развертывание незарегистрированных моделей в Машинном обучении Azure не поддерживается.
Развертывание моделей для пакетной оценки с помощью определяемых пользователем функций
Вы можете выбрать кластеры Azure Synapse Analytics для пакетной оценки. Модель MLflow загружается и используется в качестве пользовательской функции Spark Pandas для оценки новых данных.
from pyspark.sql.types import ArrayType, FloatType
model_uri = "runs:/"+last_run_id+ {model_path}
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Очистка ресурсов
Если вы хотите сохранить рабочую область Azure Synapse Analytics, но больше не требуется Машинное обучение Azure рабочей области, можно удалить рабочую область Машинное обучение Azure. Если вы не планируете использовать зарегистрированные метрики и артефакты в рабочей области, то вам нужно знать, что удалять такие ресурсы по отдельности в настоящее время нельзя. Вместо этого вам нужно удалить группу ресурсов, содержащую учетную запись хранения и рабочую область, и таким образом избежать ненужных расходов.
На портале Azure выберите Группы ресурсов в левой части окна.
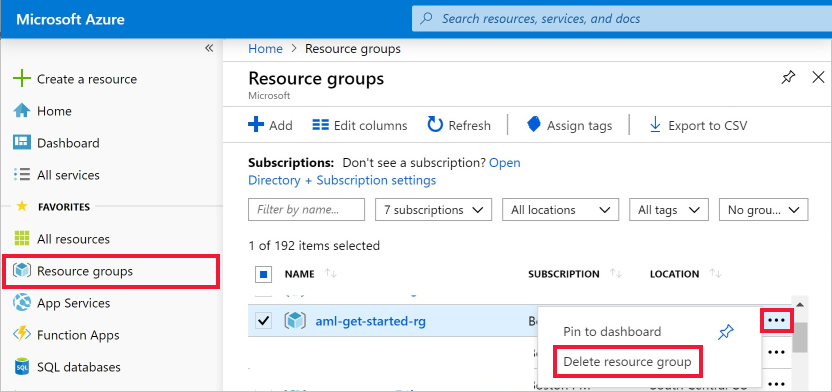
В списке выберите созданную группу ресурсов.
Выберите команду Удалить группу ресурсов.
Введите имя группы ресурсов. Затем выберите Удалить.