Заметка
Доступ к этой странице требует авторизации. Вы можете попробовать войти в систему или изменить каталог.
Доступ к этой странице требует авторизации. Вы можете попробовать сменить директорию.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python azure-ai-ml версии 2 (current)
Пакет SDK для Python azure-ai-ml версии 2 (current)
В этом руководстве приведены общие сведения о некоторых наиболее используемых функциях службы Машинное обучение Azure. В нем вы создаете, регистрируете и развертываете модель. В этом руководстве вы узнаете о основных понятиях Машинное обучение Azure и их наиболее распространенном использовании.
Вы узнаете, как запустить задание обучения на масштабируемом вычислительном ресурсе, затем развернуть его и, наконец, протестировать развертывание.
Вы создаете скрипт обучения для обработки подготовки данных, обучения и регистрации модели. После обучения модели вы развернете ее как конечную точку, а затем вызовите конечную точку для вывода.
Теперь необходимо выполнить следующие шаги:
- Настройка дескриптора в рабочей области Машинное обучение Azure
- создать сценарий обучения;
- Создание масштабируемого вычислительного ресурса, вычислительного кластера
- Создайте и запустите задание команды, которое запустит скрипт обучения в вычислительном кластере, настроенное с соответствующей средой задания.
- Просмотр выходных данных скрипта обучения
- развертывание новой обученной модели в качестве конечной точки;
- Вызов конечной точки Машинное обучение Azure для вывода
Просмотрите это видео, чтобы просмотреть общие сведения о шагах, описанных в этом кратком руководстве.
Необходимые компоненты
-
Чтобы использовать Машинное обучение Azure, вам нужна рабочая область. Если у вас нет ресурсов, выполните инструкции по созданию рабочей области и узнайте больше об использовании.
Внимание
Если в рабочей области Машинное обучение Azure настроена управляемая виртуальная сеть, может потребоваться добавить правила для исходящего трафика, чтобы разрешить доступ к общедоступным репозиториям пакетов Python. Дополнительные сведения см. в статье "Сценарий: доступ к общедоступным пакетам машинного обучения".
-
Войдите в студию и выберите рабочую область, если она еще не открыта.
-
Откройте или создайте записную книжку в рабочей области:
- Если вы хотите скопировать и вставить код в ячейки, создайте новую записную книжку.
- Кроме того, откройте руководства/записные книжки для начала работы/quickstart.ipynb из раздела "Примеры " студии. Затем выберите "Клонировать", чтобы добавить записную книжку в файлы. Чтобы найти примеры записных книжек, ознакомьтесь с примерами записных книжек.
Установка ядра и открытие в Visual Studio Code (VS Code)
На верхней панели над открытой записной книжкой создайте вычислительный экземпляр, если у вас еще нет.

Если вычислительный экземпляр остановлен, нажмите кнопку "Пуск вычислений " и дождитесь, пока он не будет запущен.

Подождите, пока вычислительный экземпляр не будет запущен. Затем убедитесь, что ядро, найденное в правом верхнем углу, имеется
Python 3.10 - SDK v2. В противном случае используйте раскрывающийся список для выбора этого ядра.
Если вы не видите это ядро, убедитесь, что вычислительный экземпляр запущен. Если это так, нажмите кнопку "Обновить " в правом верхнем углу записной книжки.
Если вы видите баннер, который говорит, что необходимо пройти проверку подлинности, выберите "Проверка подлинности".
Вы можете запустить записную книжку здесь или открыть ее в VS Code для полной интегрированной среды разработки (IDE) с помощью Машинное обучение Azure ресурсов. Выберите "Открыть" в VS Code, а затем выберите вариант веб-приложения или рабочего стола. При запуске таким образом VS Code присоединяется к вычислительному экземпляру, ядру и файловой системе рабочей области.





Внимание
Остальная часть этого руководства содержит ячейки записной книжки учебника. Скопируйте и вставьте их в новую записную книжку или переключитесь на записную книжку, если она клонирована.
Создание дескриптора в рабочей области
Прежде чем мы рассмотрим код, вам потребуется способ ссылаться на рабочую область. Рабочая область — это ресурс верхнего уровня для Машинного обучения Azure, который обеспечивает централизованное расположение для работы со всеми артефактами, созданными в Машинном обучении Azure.
Вы создаете ml_client дескриптор для рабочей области. Затем вы используете ml_client для управления ресурсами и заданиями.
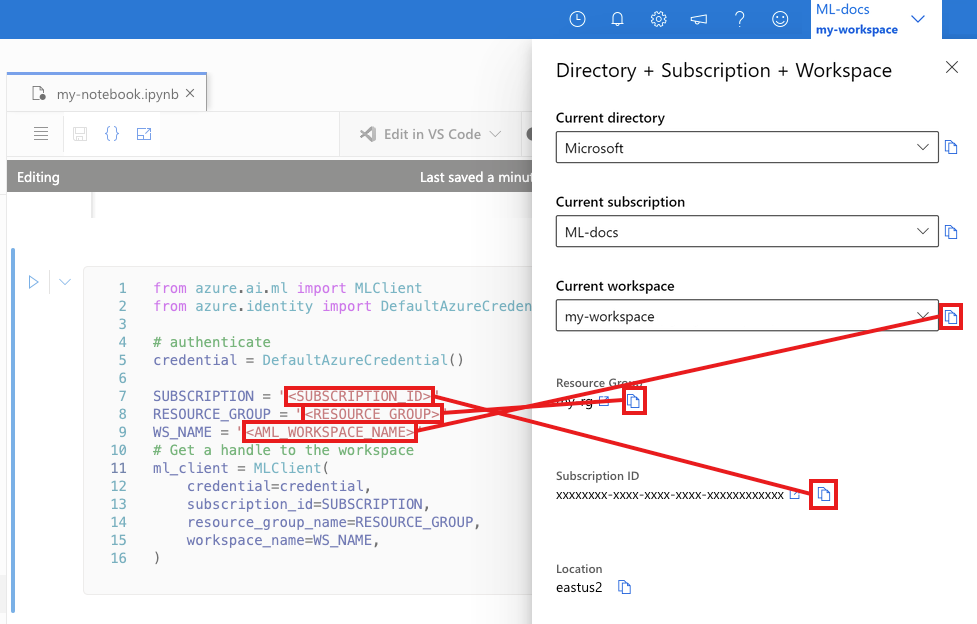
В следующей ячейке введите идентификатор подписки, имя группы ресурсов и имя рабочей области. Вот как найти эти значения:
- На панели инструментов в правом верхнем углу Студии машинного обучения Azure выберите имя рабочей области.
- Скопируйте значение для рабочей области, группы ресурсов и идентификатора подписки в код.
- Необходимо скопировать одно значение, закрыть область и вставить, а затем вернуться к следующей.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Примечание.
При создании клиента ML не будет выполняться подключение к рабочей области. Инициализация клиента отложена, она ожидает первого вызова (это произойдет в следующей ячейке кода).
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
Создание скрипта обучения
Начнем с создания скрипта обучения — файла main.py Python.
Сначала создайте исходную папку для скрипта:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Этот скрипт обрабатывает предварительную обработку данных, разделяя их на тестовые и обучающие данные. Затем он использует эти данные для обучения модели на основе дерева и возврата выходной модели.
MLFlow используется для регистрации параметров и метрик во время выполнения конвейера.
В приведенной ниже ячейке используется магия IPython для записи скрипта обучения в только что созданный каталог.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
# pin numpy
conda_env = {
'name': 'mlflow-env',
'channels': ['conda-forge'],
'dependencies': [
'python=3.10.15',
'pip<=21.3.1',
{
'pip': [
'mlflow==2.17.0',
'cloudpickle==2.2.1',
'pandas==1.5.3',
'psutil==5.8.0',
'scikit-learn==1.5.2',
'numpy==1.26.4',
]
}
],
}
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
conda_env=conda_env,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Как видно из этого сценария, после обучения модели файл модели сохраняется и регистрируется в рабочей области. Теперь вы можете использовать зарегистрированную модель в конечных точках вывода.
Возможно, потребуется выбрать "Обновить", чтобы увидеть новую папку и скрипт в файлах.
Настройка команды
Теперь, когда у вас есть скрипт, который может выполнять требуемые задачи и вычислительный кластер для запуска скрипта, используйте команду общего назначения, которая может выполнять действия командной строки. Эти действия в командной строке могут вызывать системные команды напрямую или запускать сценарии.
Здесь вы создадите входные переменные, чтобы указать входные данные, разделить соотношение, частоту обучения и зарегистрированное имя модели. Сценарий команды:
- Используйте среду, которая определяет библиотеки программного обеспечения и среды выполнения, необходимые для сценария обучения. Машинное обучение Azure предоставляет множество управляемых или готовых сред, которые полезны для распространенных сценариев обучения и вывода. Здесь вы используете одну из этих сред. В руководстве по обучению модели в Машинное обучение Azure вы узнаете, как создать настраиваемую среду.
- Настройте само действие командной строки —
python main.pyв данном случае. Входные и выходные данные доступны в команде${{ ... }}с помощью нотации. - В этом примере мы доступ к данным из файла в Интернете.
- Так как вычислительный ресурс не указан, скрипт запускается в бессерверном вычислительном кластере , который создается автоматически.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="azureml://registries/azureml/environments/sklearn-1.5/labels/latest",
display_name="credit_default_prediction",
)
отправить задание.
Теперь пришло время отправить задание для выполнения в Машинное обучение Azure. На этот раз вы используете create_or_updateml_client.
ml_client.create_or_update(job)
Просмотр выходных данных задания и ожидание завершения задания
Просмотрите задание в Студия машинного обучения Azure, выбрав ссылку в выходных данных предыдущей ячейки.
Выходные данные этого задания выглядят следующим образом в Студия машинного обучения Azure. Ознакомьтесь с вкладками для различных сведений, таких как метрики, выходные данные и т. д. После завершения задание регистрирует модель в рабочей области в результате обучения.
Внимание
Дождитесь завершения состояния задания, прежде чем вернуться к этой записной книжке. Выполнение задания займет от 2 до 3 минут. Это может занять больше времени (до 10 минут), если вычислительный кластер был масштабирован до нуля узлов и настраиваемая среда по-прежнему строится.
Развертывание модели в качестве подключенной конечной точки
Теперь разверните модель машинного обучения в качестве веб-службы в облаке Azure (online endpoint).
Чтобы развернуть службу машинного обучения, используйте зарегистрированную модель.
Создание подключенной конечной точки
Теперь, когда у вас есть зарегистрированная модель, пришло время создать свою конечную точку в Сети. Имя конечной точки должно быть уникальным в пределах всего региона Azure. В этом руководстве вы создадите уникальное имя с помощью UUID.
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Создание конечной точки:
# Expect the endpoint creation to take a few minutes
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
"model_type": "sklearn.GradientBoostingClassifier",
},
)
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
print(f"Endpoint {endpoint.name} provisioning state: {endpoint.provisioning_state}")
Примечание.
Ожидается, что создание конечной точки займет несколько минут.
После создания конечной точки его можно получить следующим образом:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Развертывание модели в конечной точке
После создания конечной точки разверните модель с помощью сценария входа. Каждая конечная точка может иметь несколько развертываний. Прямой трафик к этим развертываниям можно указать с помощью правил. Здесь вы создадите одно развертывание, которое обрабатывает 100 % входящего трафика. Мы выбрали цветное имя развертывания, например синее, зеленое, красное развертывание, которое является произвольным.
Вы можете проверить страницу "Модели" на Студия машинного обучения Azure, чтобы определить последнюю версию зарегистрированной модели. Кроме того, приведенный ниже код извлекает последний номер версии для использования.
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(f'Latest model is version "{latest_model_version}" ')
Разверните последнюю версию модели.
# picking the model to deploy. Here we use the latest version of our registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# Expect this deployment to take approximately 6 to 8 minutes.
# create an online deployment.
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()
Примечание.
Ожидается, что развертывание займет около 6–8 минут.
Когда развертывание будет выполнено, вы можете протестировать его.
Тестирование с использованием примера запроса
После развертывания модели в конечной точке можно выполнить вывод с ним.
Создайте пример файла запроса в соответствии с ожидаемой архитектурой в методе запуска сценария оценки.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
deployment_name="blue",
)
Очистка ресурсов
Если вы не собираетесь использовать конечную точку, удалите ее, чтобы остановить использование ресурса. Перед удалением убедитесь, что другие развертывания не используют эту конечную точку.
Примечание.
Ожидается, что полное удаление займет около 20 минут.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
Остановка вычислительного экземпляра
Если вы сейчас не планируете использовать вычислительный экземпляр, остановите его, выполнив следующие действия:
- В студии в левой области выберите "Вычисления".
- Из вкладок вверху выберите Вычислительные экземпляры.
- Выберите вычислительный экземпляр из списка.
- В верхней панели инструментов выберите Остановить.
Удаление всех ресурсов
Внимание
Созданные вами ресурсы могут использоваться в качестве необходимых компонентов при работе с другими руководствами по Машинному обучению Azure.
Если вы не планируете использовать созданные вами ресурсы, удалите их, чтобы с вас не взималась плата:
В портал Azure в поле поиска введите группы ресурсов и выберите его из результатов.
Выберите созданную группу ресурсов из списка.
На странице "Обзор" выберите "Удалить группу ресурсов".
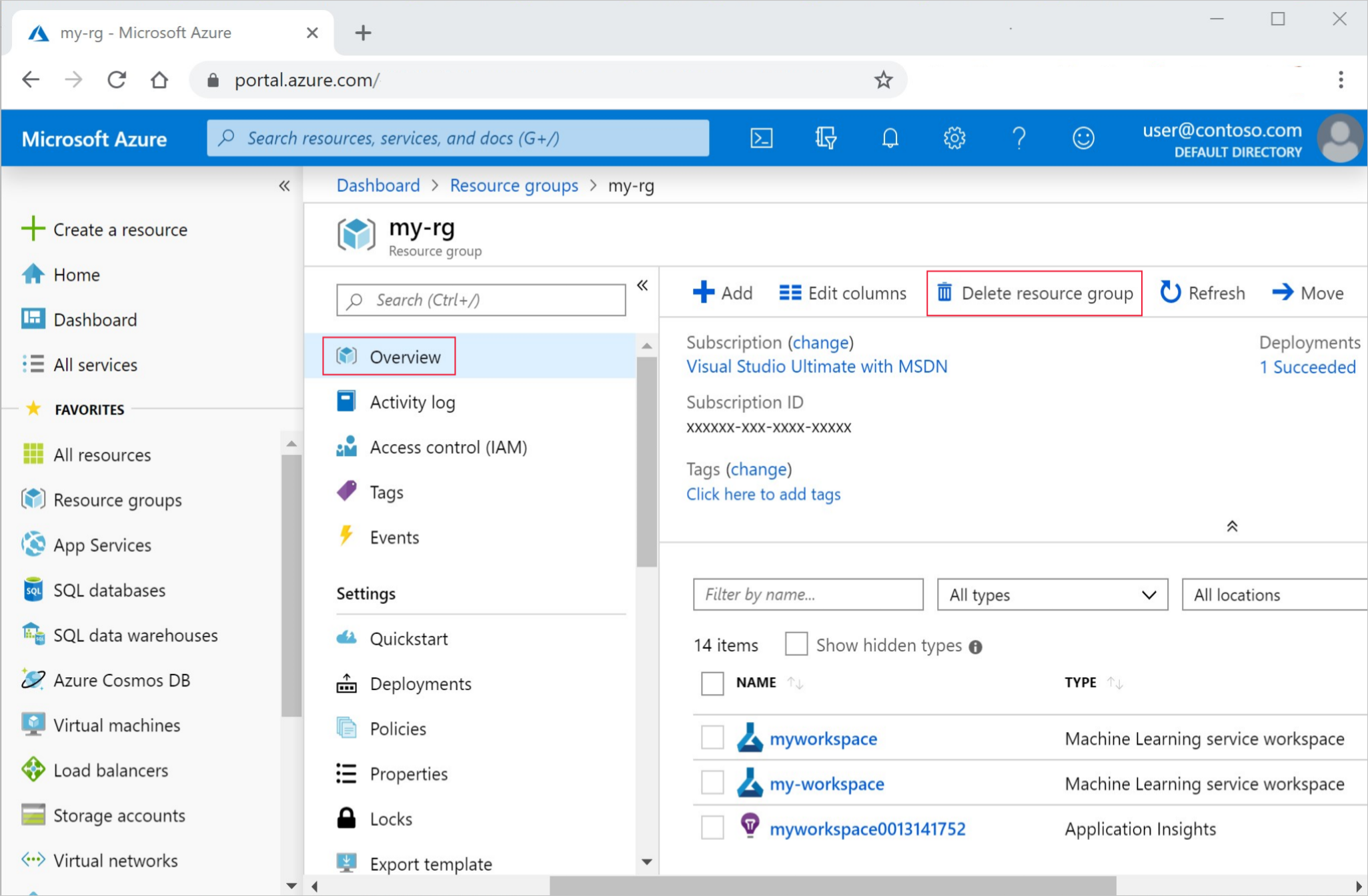
Введите имя группы ресурсов. Затем выберите Удалить.
Следующие шаги
Теперь, когда у вас есть представление о том, что участвует в обучении и развертывании модели, узнайте больше о процессе в следующих руководствах:
| Учебник | Описание |
|---|---|
| Отправка, доступ и изучение данных в Машинное обучение Azure | Хранение больших данных в облаке и его извлечение из записных книжек и скриптов |
| Разработка моделей на облачной рабочей станции | Начало разработки прототипов и разработки моделей машинного обучения |
| Обучение модели в Машинное обучение Azure | Подробные сведения о обучении модели |
| Развертывание модели в качестве сетевой конечной точки | Подробные сведения о развертывании модели |
| Создание конвейеров машинного обучения | Разбиение полной задачи машинного обучения на многоэтапный рабочий процесс. |