Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python azure-ai-ml версии 2 (current)
Пакет SDK для Python azure-ai-ml версии 2 (current)
Примечание.
Руководство по созданию конвейера с помощью пакета SDK версии 1 см. в руководстве по созданию конвейера машинного обучения Azure для классификации изображений.
Конвейер машинного обучения разбивает полную задачу машинного обучения на многоэтапный рабочий процесс. Каждый шаг — это управляемый компонент, который можно разрабатывать, оптимизировать, настраивать и автоматизировать отдельно. Хорошо определённые интерфейсы связывают шаги. Служба конвейера машинного обучения Azure управляет всеми зависимостями между этапами конвейера.
Преимущества использования конвейера данных — это стандартизованные практики MLOps, масштабируемая совместная работа команды, повышение эффективности обучения и сокращение затрат. Дополнительные сведения о преимуществах конвейеров см. в статье "Что такое Машинное обучение Azure конвейеры".
В этом руководстве вы используете Машинное обучение Azure для создания проекта машинного обучения, готового к работе, с помощью пакета SDK Python для Машинного обучения Azure версии 2. После работы с этим руководством вы сможете использовать пакет SDK Для Python машинного обучения Azure для:
- Получение дескриптора в рабочую область Машинное обучение Azure
- Создание ресурсов данных Машинного обучения Azure
- Создание повторно используемых компонентов Машинное обучение Azure
- Создание, проверка и запуск конвейеров машинного обучения Azure
В этом руководстве вы создадите конвейер Машинное обучение Azure для обучения модели для прогнозирования по умолчанию кредита. Конвейер обрабатывает два шага:
- Подготовка данных
- Обучение и регистрация обученной модели
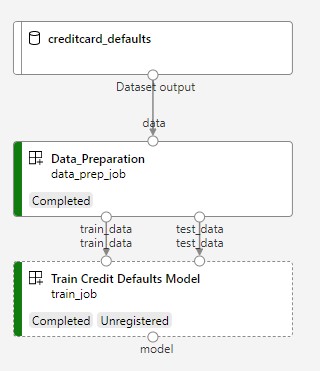
На следующем рисунке показан простой конвейер, как он отображается в студии Azure после отправки.
Два шага — подготовка данных и обучение.
В этом видео показано, как приступить к работе в Студия машинного обучения Azure, чтобы выполнить действия, описанные в руководстве. В видео показано, как создать записную книжку, создать вычислительный экземпляр и клонировать записную книжку. В следующих разделах также описаны эти действия.
Необходимые компоненты
-
Чтобы использовать Машинное обучение Azure, вам нужна рабочая область. Если у вас нет ресурсов, выполните инструкции по созданию рабочей области и узнайте больше об использовании.
Внимание
Если в рабочей области Машинное обучение Azure настроена управляемая виртуальная сеть, может потребоваться добавить правила для исходящего трафика, чтобы разрешить доступ к общедоступным репозиториям пакетов Python. Дополнительные сведения см. в статье "Сценарий: доступ к общедоступным пакетам машинного обучения".
-
Войдите в студию и выберите рабочую область, если она еще не открыта.
Выполните инструкции по отправке, доступу и изучению данных, чтобы создать ресурс данных , необходимый в этом руководстве. Убедитесь, что вы запускаете весь код для создания исходного ресурса данных. Вы можете изучить данные и пересмотреть их, если вы хотите, но вам нужны только исходные данные для этого руководства.
-
Откройте или создайте записную книжку в рабочей области:
- Если вы хотите скопировать и вставить код в ячейки, создайте новую записную книжку.
- Или откройте учебники/get-started-notebooks/pipeline.ipynb из раздела "Примеры " студии. Затем выберите "Клонировать", чтобы добавить записную книжку в файлы. Чтобы найти примеры записных книжек, ознакомьтесь с примерами записных книжек.
Установка ядра и открытие в Visual Studio Code (VS Code)
На верхней панели над открытой записной книжкой создайте вычислительный экземпляр, если у вас еще нет.

Если вычислительный экземпляр остановлен, нажмите кнопку "Пуск вычислений " и дождитесь, пока он не будет запущен.

Подождите, пока вычислительный экземпляр не будет запущен. Затем убедитесь, что ядро, найденное в правом верхнем углу, имеется
Python 3.10 - SDK v2. В противном случае используйте раскрывающийся список для выбора этого ядра.
Если вы не видите это ядро, убедитесь, что вычислительный экземпляр запущен. Если это так, нажмите кнопку "Обновить " в правом верхнем углу записной книжки.
Если вы видите баннер, который говорит, что необходимо пройти проверку подлинности, выберите "Проверка подлинности".
Вы можете запустить записную книжку здесь или открыть ее в VS Code для полной интегрированной среды разработки (IDE) с помощью Машинное обучение Azure ресурсов. Выберите "Открыть" в VS Code, а затем выберите вариант веб-приложения или рабочего стола. При запуске таким образом VS Code присоединяется к вычислительному экземпляру, ядру и файловой системе рабочей области.





Внимание
Остальная часть этого руководства содержит ячейки записной книжки учебника. Скопируйте и вставьте их в новую записную книжку или переключитесь на записную книжку, если она клонирована.
Настройка ресурсов конвейера
Вы можете использовать платформу машинного обучения Azure из интерфейса командной строки Azure, пакета SDK для Python или интерфейса студии. В этом примере для создания конвейера используется пакет SDK для Python версии 2 Машинное обучение Azure.
Перед созданием конвейера вам потребуются следующие ресурсы:
- ресурс данных для обучения;
- программная среда для запуска конвейера;
- Вычислительный ресурс, в котором выполняется задание
Создание дескриптора в рабочей области
Прежде чем использовать код, вам потребуется способ указать на свою рабочую область. Создайте ml_client в качестве дескриптора рабочей области. Затем вы используете ml_client для управления ресурсами и заданиями.
В следующей ячейке введите идентификатор подписки, имя группы ресурсов и имя рабочей области. Вот как найти эти значения:
- На панели инструментов в правом верхнем углу Студии машинного обучения Azure выберите имя рабочей области.
- Скопируйте значение рабочей области, группы ресурсов и идентификатор подписки в код. Необходимо скопировать одно значение, закрыть область и вставить, а затем вернуться к следующему значению.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Справочник по пакету SDK:
Примечание.
Процесс создания MLClient не подключает к рабочей области. Инициализация клиента отложена. Он ждет, когда ему впервые потребуется сделать звонок. Инициализация происходит в следующей ячейке кода.
Проверьте подключение, выполнив вызов ml_client. Поскольку это первый вызов в рабочее пространство, возможно, вам потребуется пройти проверку подлинности.
# Verify that the handle works correctly.
# If you get an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
Справочник по пакету SDK:
Доступ к зарегистрированным ресурсу данных
Начните с получения данных, которые вы ранее зарегистрировали в руководстве: отправка, доступ и изучение данных в Машинном обучении Azure.
Примечание.
Машинное обучение Azure использует Data объект для регистрации переиспользуемого определения данных и использования данных в рамках конвейера.
# get a handle of the data asset and print the URI
credit_data = ml_client.data.get(name="credit-card", version="initial")
print(f"Data asset URI: {credit_data.path}")
Справочник по пакету SDK:
Создание среды задания для шагов конвейера
До сих пор вы создали среду разработки на вычислительном экземпляре, компьютере разработки. Для каждого шага конвейера также требуется среда. Каждый шаг может иметь собственную среду. Также можно использовать некоторые общие среды для нескольких шагов.
В этом примере создается среда conda для заданий с помощью файла conda yaml. Сначала создайте каталог для хранения файла.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Затем создайте файл в каталоге зависимостей.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.10
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=0.24.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- xlrd==2.0.1
- mlflow== 2.4.1
- azureml-mlflow==1.51.0
Спецификация содержит некоторые обычные пакеты, которые вы используете в конвейере (numpy, pip), а также некоторые пакеты машинного обучения Azure (azureml-mlflow).
Пакеты машинного обучения Azure не требуются для запуска заданий машинного обучения Azure. Добавив эти пакеты, вы можете взаимодействовать с Машинным обучением Azure для ведения журнала метрик и регистрации моделей, все в задании машинного обучения Azure. Они используются в скрипте обучения далее в этом руководстве.
Используйте файл yaml для создания и регистрации этой настраиваемой среды в рабочей области:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
pipeline_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults pipeline",
tags={"scikit-learn": "0.24.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest",
version="0.2.0",
)
pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
print(
f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
)
Справочник по пакету SDK:
Создание конвейера обучения
Теперь, когда у вас есть все ресурсы, необходимые для запуска конвейера, пришло время создать сам конвейер.
Машинное обучение Azure конвейеры являются повторно используемыми рабочими процессами машинного обучения, которые обычно состоят из нескольких компонентов. Типичный жизненный цикл компонента:
- Напишите спецификацию YAML компонента или создайте ее программным способом с помощью
ComponentMethod. - При необходимости зарегистрируйте компонент с именем и версией в рабочей области, чтобы сделать его повторно используемым и общим.
- Загрузите этот компонент из кода конвейера.
- Реализуйте конвейер с помощью входных, выходных данных и параметров компонента.
- Отправьте конвейер.
Компонент можно создать двумя способами: программным определением и определением YAML. В следующих двух разделах описывается создание компонента обоими способами. Вы можете создать два компонента, попробовать оба варианта или выбрать предпочтительный метод.
Примечание.
В этом руководстве для простоты используются одни и те же вычислительные ресурсы для всех компонентов. Однако можно задать разные вычисления для каждого компонента. Например, можно добавить строку, например train_step.compute = "cpu-cluster". Пример создания конвейера с разными вычислениями для каждого компонента см . в разделе "Базовый задание конвейера" в руководстве по конвейеру cifar-10.
Создание компонента 1 "Подготовка данных" (с помощью программного определения)
Сначала создайте первый компонент. Этот компонент выполняет предварительную обработку данных. Задача предварительной обработки выполняется в файле data_prep.py Python.
Сначала создайте исходную папку для компонента data_prep:
import os
data_prep_src_dir = "./components/data_prep"
os.makedirs(data_prep_src_dir, exist_ok=True)
Этот сценарий выполняет простую задачу разделения данных на обучающие и тестовые наборы данных. Машинное обучение Azure подключает наборы данных в виде папок к вычислительным ресурсам. Вы создали вспомогательную select_first_file функцию для доступа к файлу данных в подключенной входной папке.
MLFlow используется для регистрации параметров и метрик во время выполнения пайплайна.
%%writefile {data_prep_src_dir}/data_prep.py
import os
import argparse
import pandas as pd
from sklearn.model_selection import train_test_split
import logging
import mlflow
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
credit_train_df, credit_test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
# output paths are mounted as folder, therefore, we are adding a filename to the path
credit_train_df.to_csv(os.path.join(args.train_data, "data.csv"), index=False)
credit_test_df.to_csv(os.path.join(args.test_data, "data.csv"), index=False)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Теперь, когда у вас есть скрипт, который может выполнить нужную задачу, создайте Машинное обучение Azure компонент из него.
Используйте общую цель CommandComponent , которая может выполнять действия командной строки. Эти действия в командной строке могут вызывать системные команды напрямую или запускать сценарии. Входные и выходные данные указываются в командной строке с помощью ${{ ... }} нотации.
from azure.ai.ml import command
from azure.ai.ml import Input, Output
data_prep_component = command(
name="data_prep_credit_defaults",
display_name="Data preparation for training",
description="reads a .xl input, split the input to train and test",
inputs={
"data": Input(type="uri_folder"),
"test_train_ratio": Input(type="number"),
},
outputs=dict(
train_data=Output(type="uri_folder", mode="rw_mount"),
test_data=Output(type="uri_folder", mode="rw_mount"),
),
# The source folder of the component
code=data_prep_src_dir,
command="""python data_prep.py \
--data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} \
--train_data ${{outputs.train_data}} --test_data ${{outputs.test_data}} \
""",
environment=f"{pipeline_job_env.name}:{pipeline_job_env.version}",
)
Справочник по пакету SDK:
При необходимости зарегистрируйте компонент в рабочей области для дальнейшего повторного использования.
# Now register the component to the workspace
data_prep_component = ml_client.create_or_update(data_prep_component.component)
# Create and register the component in your workspace
print(
f"Component {data_prep_component.name} with Version {data_prep_component.version} is registered"
)
Справочник по пакету SDK:
Создание компонента 2 "Обучение" (с помощью определения YAML)
Второй компонент, который вы создаете, использует обучающие и тестовые данные, обучает модель на основе дерева и возвращает выходную модель. Используйте Машинное обучение Azure возможности ведения журнала для записи и визуализации хода обучения.
Вы использовали класс CommandComponent для создания первого компонента. На этот раз для определения второго компонента используется определение yaml. У каждого метода свои преимущества. Определение yaml можно добавить вместе с исходным кодом и использовать для наглядного отслеживания истории изменений. Программный метод с использованием CommandComponent может упростить создание документации внутри класса и обработку завершений кода.
Создайте каталог для этого компонента:
import os
train_src_dir = "./components/train"
os.makedirs(train_src_dir, exist_ok=True)
Создайте сценарий обучения в каталоге:
%%writefile {train_src_dir}/train.py
import argparse
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
import os
import pandas as pd
import mlflow
def select_first_file(path):
"""Selects first file in folder, use under assumption there is only one file in folder
Args:
path (str): path to directory or file to choose
Returns:
str: full path of selected file
"""
files = os.listdir(path)
return os.path.join(path, files[0])
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
os.makedirs("./outputs", exist_ok=True)
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
parser.add_argument("--model", type=str, help="path to model file")
args = parser.parse_args()
# paths are mounted as folder, therefore, we are selecting the file from folder
train_df = pd.read_csv(select_first_file(args.train_data))
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# paths are mounted as folder, therefore, we are selecting the file from folder
test_df = pd.read_csv(select_first_file(args.test_data))
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.model, "trained_model"),
)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Как видно в этом сценарии обучения, после обучения модели файл модели сохраняется и регистрируется в рабочей области. Теперь вы можете использовать зарегистрированную модель в конечных точках вывода.
Для среды этого шага используется одна из встроенных (курированных) сред Машинное обучение Azure. Тег azureml указывает системе искать имя в преднастроенных средах.
Сначала создайте файл yaml, описывающий компонент:
%%writefile {train_src_dir}/train.yml
# <component>
name: train_credit_defaults_model
display_name: Train Credit Defaults Model
# version: 1 # Not specifying a version will automatically update the version
type: command
inputs:
train_data:
type: uri_folder
test_data:
type: uri_folder
learning_rate:
type: number
registered_model_name:
type: string
outputs:
model:
type: uri_folder
code: .
environment:
# for this step, we'll use an AzureML curate environment
azureml://registries/azureml/environments/sklearn-1.0/labels/latest
command: >-
python train.py
--train_data ${{inputs.train_data}}
--test_data ${{inputs.test_data}}
--learning_rate ${{inputs.learning_rate}}
--registered_model_name ${{inputs.registered_model_name}}
--model ${{outputs.model}}
# </component>
Теперь создайте и зарегистрируйте компонент. Регистрация позволяет повторно использовать его в других конвейерах. Любой пользователь с доступом к рабочей области также может использовать зарегистрированный компонент.
# importing the Component Package
from azure.ai.ml import load_component
# Loading the component from the yml file
train_component = load_component(source=os.path.join(train_src_dir, "train.yml"))
# Now register the component to the workspace
train_component = ml_client.create_or_update(train_component)
# Create and register the component in your workspace
print(
f"Component {train_component.name} with Version {train_component.version} is registered"
)
Справочник по пакету SDK:
Создание конвейера на основе компонентов
После определения и регистрации компонентов начните реализацию конвейера.
Функции Python, которые возвращает load_component(), работают как обычные функции Python. Используйте их в конвейере для вызова каждого шага.
Чтобы закодировать конвейер, используйте конкретный @dsl.pipeline декоратор, определяющий конвейеры машинного обучения Azure. В декораторе укажите описание конвейера и ресурсы по умолчанию, такие как вычислительные ресурсы и хранилище. Как и функция Python, конвейеры могут иметь входные данные. Можно создать несколько экземпляров одного конвейера с различными входными данными.
В следующем примере используйте входные данные, разделение изарегистрированное имя модели в качестве входных переменных. Затем вызовите компоненты и подключите их с помощью их входных и выходных идентификаторов. Доступ к выходным данным каждого шага с помощью .outputs свойства.
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
from azure.ai.ml import dsl, Input, Output
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E data_perp-train pipeline",
)
def credit_defaults_pipeline(
pipeline_job_data_input,
pipeline_job_test_train_ratio,
pipeline_job_learning_rate,
pipeline_job_registered_model_name,
):
# using data_prep_function like a python call with its own inputs
data_prep_job = data_prep_component(
data=pipeline_job_data_input,
test_train_ratio=pipeline_job_test_train_ratio,
)
# using train_func like a python call with its own inputs
train_job = train_component(
train_data=data_prep_job.outputs.train_data, # note: using outputs from previous step
test_data=data_prep_job.outputs.test_data, # note: using outputs from previous step
learning_rate=pipeline_job_learning_rate, # note: using a pipeline input as parameter
registered_model_name=pipeline_job_registered_model_name,
)
# a pipeline returns a dictionary of outputs
# keys will code for the pipeline output identifier
return {
"pipeline_job_train_data": data_prep_job.outputs.train_data,
"pipeline_job_test_data": data_prep_job.outputs.test_data,
}
Справочник по пакету SDK:
Теперь используйте определение конвейера, чтобы создать экземпляр конвейера с набором данных, скоростью разделения и именем, выбранным для модели.
registered_model_name = "credit_defaults_model"
# Let's instantiate the pipeline with the parameters of our choice
pipeline = credit_defaults_pipeline(
pipeline_job_data_input=Input(type="uri_file", path=credit_data.path),
pipeline_job_test_train_ratio=0.25,
pipeline_job_learning_rate=0.05,
pipeline_job_registered_model_name=registered_model_name,
)
Справочник по пакету SDK:
отправить задание.
Теперь отправьте задание для запуска в Машинном обучении Azure. На этот раз используйте create_or_updateml_client.jobs.
Передайте имя эксперимента. Эксперимент — это контейнер для всех итерации, которые выполняется в определенном проекте. Все задания, отправленные под тем же именем эксперимента, отображаются рядом друг с другом в студии машинного обучения Azure.
После завершения конвейер регистрирует модель в рабочей области как результат этого обучения.
# submit the pipeline job
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_registered_components",
)
ml_client.jobs.stream(pipeline_job.name)
Справочник по пакету SDK:
Ход выполнения конвейера можно отслеживать с помощью ссылки, созданной в предыдущей ячейке. При первом выборе этой ссылки может показаться, что конвейер по-прежнему запущен. По завершении можно проверить результаты каждого компонента.
Дважды щелкните компонент модели " Обучение кредитов по умолчанию".
Два важных результата, которые вы хотите увидеть о обучении:
Просмотр журналов:
- Перейдите на вкладку "Выходные данные и журналы ".
- Откройте папки в
user_logs>std_log.txtэтом разделе, где показано выполнение скрипта stdout.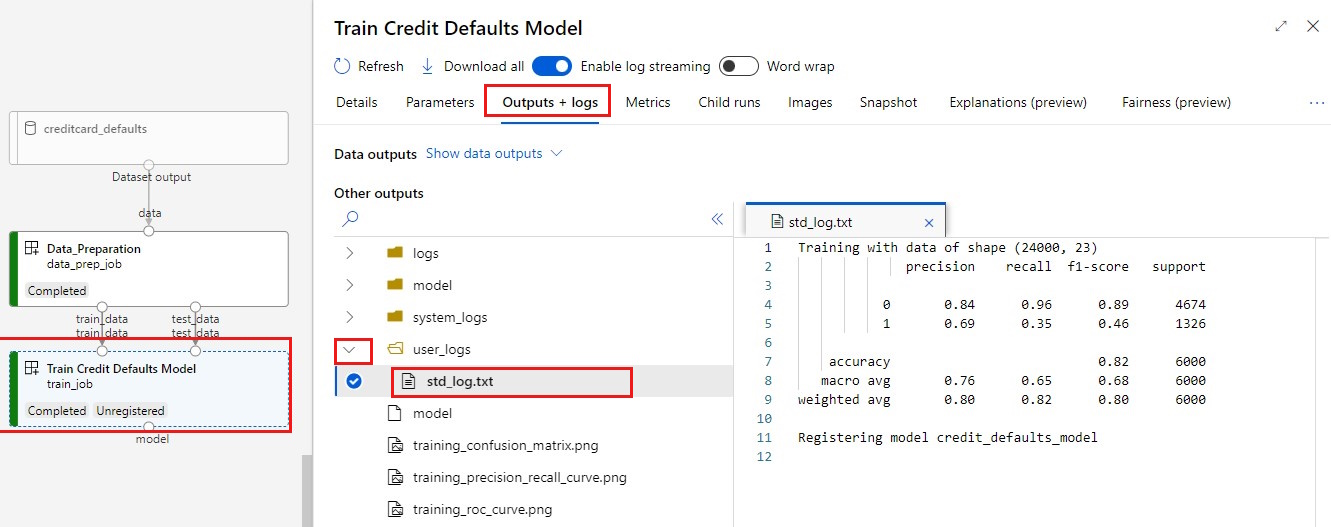
Просмотр метрик. Выберите вкладку "Метрики ". В этом разделе показаны различные метрики, зарегистрированные в журнале. В этом примере mlflow
autologgingавтоматически регистрирует метрики обучения.


Развертывание модели в качестве подключенной конечной точки
Дополнительные сведения о развертывании модели в сетевой конечной точке см. в руководстве по развертыванию модели в качестве онлайн-конечной точки.
Очистка ресурсов
Если вы планируете продолжить работу с другими руководствами, перейдите к следующему шагу.
Остановка вычислительного экземпляра
Если вы не собираетесь использовать вычислительный экземпляр в данный момент, остановите его:
- В студии в левой области выберите "Вычисления".
- На верхних вкладках выберите экземпляры вычислений.
- Выберите вычислительный экземпляр из списка.
- В верхней панели инструментов выберите Остановить.
Удаление всех ресурсов
Внимание
Созданные вами ресурсы могут использоваться в качестве необходимых компонентов при работе с другими руководствами по Машинному обучению Azure.
Если вы не планируете использовать созданные вами ресурсы, удалите их, чтобы с вас не взималась плата:
В портал Azure в поле поиска введите группы ресурсов и выберите его из результатов.
Выберите созданную группу ресурсов из списка.
На странице "Обзор" выберите "Удалить группу ресурсов".
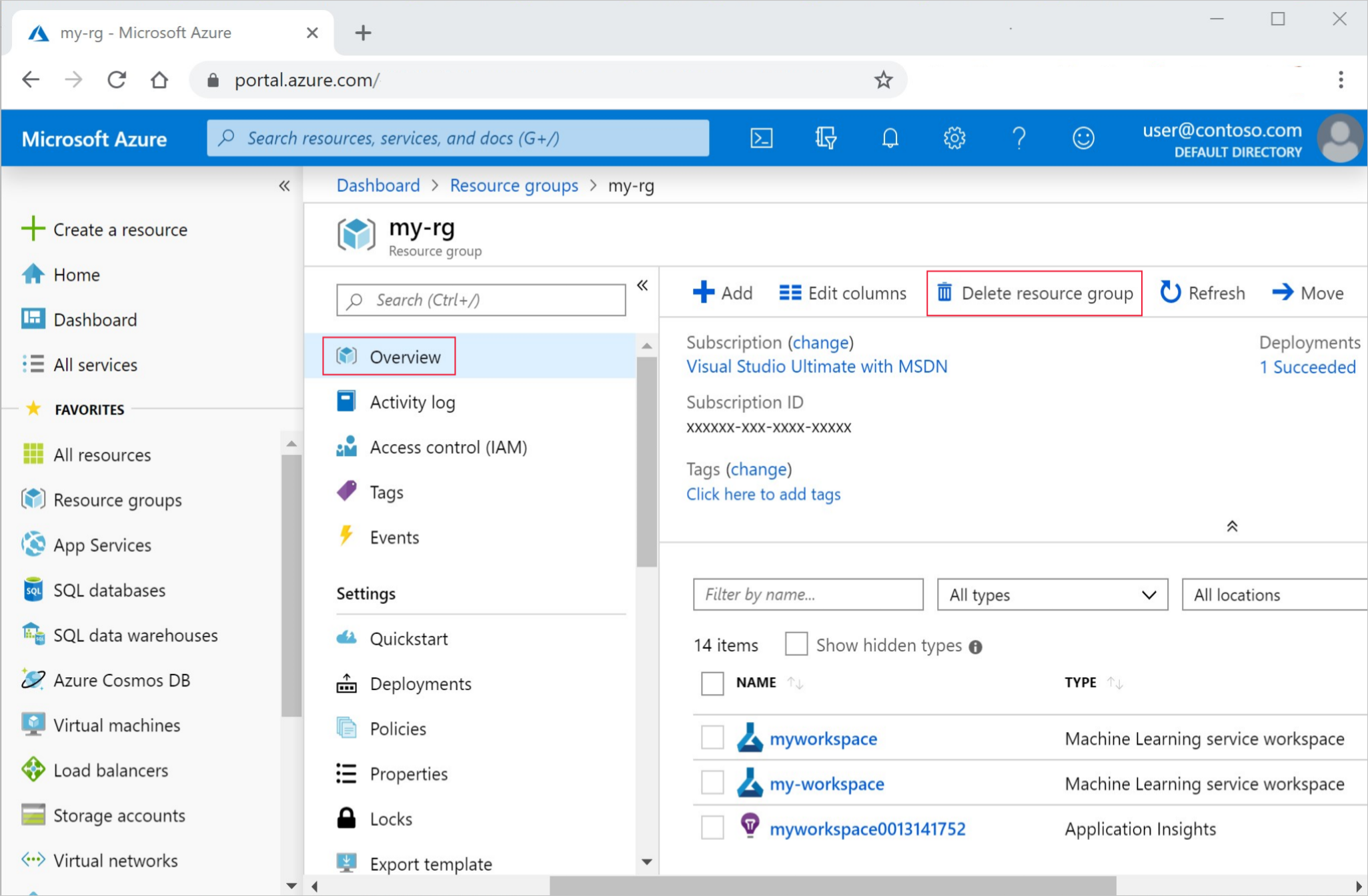
Введите имя группы ресурсов. Затем выберите Удалить.