Руководство по REST. Использование наборов навыков для создания содержимого с возможностью поиска в Azure AI
В этом руководстве описано, как вызывать REST API, создающие конвейер обогащения ИИ для извлечения содержимого и преобразований во время индексирования.
Наборы навыков добавляют обработку ИИ в необработанное содержимое, что делает его более универсальным и доступным для поиска. После того как вы узнаете, как работают наборы навыков, вы можете поддерживать широкий спектр преобразований: от анализа изображений до обработки естественного языка до настраиваемой обработки, которую вы предоставляете внешне.
В этом руководстве вы узнаете, как:
- Определите объекты в конвейере обогащения.
- Создание набора навыков. Вызов OCR, распознавание речи, распознавание сущностей и извлечение ключевых фраз.
- Выполните конвейер. Создание и загрузка индекса поиска.
- Проверьте результаты с помощью полнотекстового поиска.
Если у вас еще нет подписки Azure, создайте бесплатную учетную запись Azure, прежде чем начинать работу.
Обзор
В этом руководстве для создания источника данных, индекса, индексатора и набора навыков используется клиент REST rest службы "Поиск ИИ Azure".
Индексатор управляет каждым шагом в конвейере, начиная с извлечения содержимого примеров данных (неструктурированный текст и изображения) в контейнере БОЛЬШИХ двоичных объектов на служба хранилища Azure.
После извлечения содержимого набор навыков выполняет встроенные навыки от Корпорации Майкрософт для поиска и извлечения информации. Эти навыки включают оптическое распознавание символов (OCR) на изображениях, распознавание языка на тексте, извлечении ключевых фраз и распознавании сущностей (организации). Новая информация, созданная набором навыков, отправляется в поля в индексе. После заполнения индекса вы можете использовать поля в запросах, аспектах и фильтрах.
Необходимые компоненты
Примечание.
Вы можете использовать бесплатную службу поиска для этого руководства. Уровень "Бесплатный" ограничивается тремя индексами, тремя индексаторами и тремя источниками данных. В этом руководстве создается по одному объекту из каждой категории. Перед началом работы убедитесь, что у службы есть достаточно места, чтобы принять новые ресурсы.
Загрузка файлов
Скачайте ZIP-файл примера репозитория данных и извлеките его содержимое. Подробнее.
Отправка примеров данных в служба хранилища Azure
В служба хранилища Azure создайте новый контейнер и назовите его cog-search-demo.
Отправьте примеры файлов данных.
Получите строка подключения хранилища, чтобы сформулировать подключение в службе "Поиск ИИ Azure".
В левой части экрана выберите ключи доступа.
Скопируйте строка подключения для одного или двух ключей. Строка подключения аналогичен следующему примеру:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Службы ИИ Azure
Встроенное обогащение ИИ поддерживается службами ИИ Azure, включая языковую службу и Распознавание ИИ Azure для естественного языка и обработки изображений. Для небольших рабочих нагрузок, таких как в этом руководстве, можно использовать бесплатное выделение двадцати транзакций на индексатор. Для более крупных рабочих нагрузок подключите ресурс Служб искусственного интеллекта Azure к набору навыков для оплаты по мере использования.
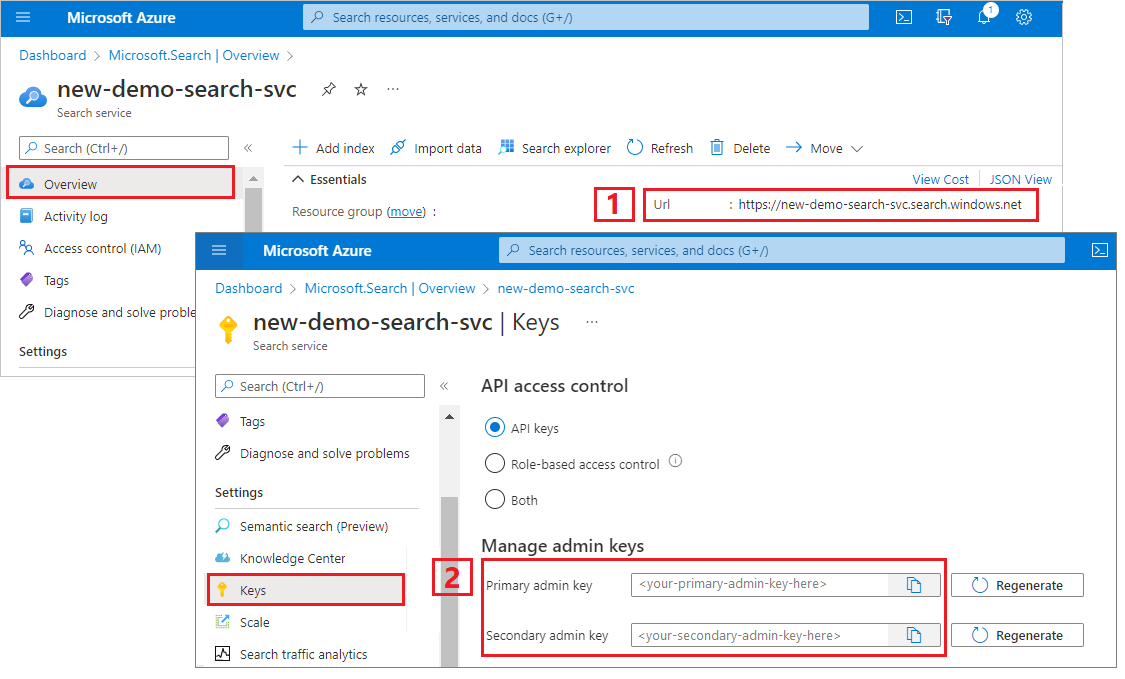
Копирование URL-адреса службы поиска и ключа API
Для работы с этим руководством для подключений к службе "Поиск ИИ Azure" требуется конечная точка и ключ API. Эти значения можно получить из портал Azure.
Войдите в портал Azure, перейдите на страницу обзора службы поиска и скопируйте URL-адрес. Пример конечной точки может выглядеть так:
https://mydemo.search.windows.net.В разделе "Ключи>параметров" скопируйте ключ администратора. Ключи администратора используются для добавления, изменения и удаления объектов. Существует два взаимозаменяемых ключа администратора. Скопируйте любой из них.
Настройка REST-файла
Запустите Visual Studio Code и откройте файл skillset-tutorial.rest . См . краткое руководство. Поиск текста с помощью REST , если вам нужна помощь с клиентом REST.
Укажите значения переменных: конечная точка службы поиска, ключ API администратора службы поиска, имя индекса, строка подключения учетной записи служба хранилища Azure и имя контейнера BLOB-объектов.
Создание конвейера
Обогащение ИИ зависит от индексатора. В этой части пошагового руководства описано, как создать четыре объекта: источник данных, определение индекса, набор навыков и индексатор.
Шаг 1. Создание источника данных
Вызовите источник данных, чтобы задать строка подключения контейнер BLOB-объектов, содержащий примеры файлов данных.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Шаг 2. Создание набора навыков
Вызовите набор навыков, чтобы указать, какие шаги обогащения применяются к содержимому. Навыки выполняются параллельно, если не существует зависимости.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
Основные моменты:
Текст запроса задает следующие встроенные навыки:
Навык Description Оптическое распознавание символов Распознает текст и числа в файлах изображений. Слияние текста Создает объединенное содержимое, которое повторно объединяет ранее разделенное содержимое, полезное для документов с внедренными изображениями (PDF, DOCX и т. д.). Изображения и текст отделяются во время этапа взлома документа. Навык слияния перекомбинирует их путем вставки любого распознанного текста, подписей изображений или тегов, созданных во время обогащения в том же расположении, где изображение было извлечено из документа. При работе с объединенным содержимым в наборе навыков этот узел включает весь текст в документе, включая текстовые документы, которые никогда не проходят анализ OCR или изображений. Распознавание языка. Обнаруживает язык и выводит имя языка или код. В многоязычных наборах данных поле языка может быть полезно для фильтров. Распознавание сущностей Извлекает имена людей, организаций и расположений из объединенного содержимого. Разделение текста Разбивает большое объединенне содержимое на небольшие блоки перед вызовом навыка извлечения ключевых фраз. Этот метод принимает входные данные объемом 50 000 символов или меньше. Некоторые примеры файлов следует разделить, чтобы удовлетворить это ограничение. Извлечение ключевых фраз. Извлекает ключевые фразы, которые встречаются чаще всего. Каждый навык выполняется в содержимом документа. Во время обработки поиск Azure AI взломает каждый документ для чтения содержимого из разных форматов файлов. Найденный текст в исходном файле помещается в созданное поле
content, по одному для каждого документа. Входные данные принимают следующий вид:"/document/content".Мы используем навык разделения текста для разбиения больших файлов на страницы, поэтому контекстом для навыка извлечения ключевых фраз будет
"document/pages/*"(для каждой страницы в документе), а не"/document/content".
Примечание.
Выходные данные могут быть сопоставлены с индексом, используемым в качестве входных данных для нисходящего навыка, или к обоим, как в случае с кодом языка. В индексе код языка полезен для фильтрации. Общие сведения о наборах навыков см. в статье How to create a skillset in an enrichment pipeline (Способ создания набора навыков в конвейере обогащения).
Шаг 3. Создание индекса
Вызовите индекс для предоставления схемы, используемой для создания инвертированных индексов и других конструкций в службе "Поиск ИИ Azure".
Самым большим компонентом индекса является коллекция полей, где тип данных и атрибуты определяют содержимое и поведение в поиске ИИ Azure. Убедитесь, что у вас есть поля для недавно созданных выходных данных.
### Create an index
POST {{baseUrl}}/indexes?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
Шаг 4. Создание и запуск индексатора
Вызовите индексатор для управления конвейером. Три компонента, которые вы создали ранее (источник данных, набор навыков и индекс) предоставляют входные данные для индексатора. Создание индексатора в службе "Поиск ИИ Azure" — это событие, которое помещает весь конвейер в движение.
Выполнение этого действия может занять несколько минут. Несмотря на то что набор данных невелик, аналитические навыки выполняют интенсивные вычисления.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
Основные моменты:
Текст запроса содержит ссылки на предыдущие объекты, свойства конфигурации, необходимые для обработки изображений, и два типа сопоставлений полей.
"fieldMappings"обрабатываются перед набором навыков, отправляя содержимое из источника данных в целевые поля в индексе. Сопоставления полей используются для отправки существующего немодифицированного содержимого в индекс. Если имена и типы полей одинаковы в исходном и целевом расположениях, сопоставление не требуется."outputFieldMappings"предназначены для полей, созданных с помощью навыков, после выполнения набора навыков. Ссылки наsourceFieldNameвoutputFieldMappingsне существуют до того момента, пока не будут созданы в процессе распознавания или обогащения документа.targetFieldNameобозначает поле в индексе, определенное в схеме индекса.Параметр
"maxFailedItems"имеет значение -1, что указывает подсистеме индексирования игнорировать ошибки во время импорта данных. Это допустимо, так как в демонстрационном источнике данных мало документов. Для большего источника данных необходимо установить значение больше 0.Инструкция
"dataToExtract":"contentAndMetadata"сообщает индексатору автоматически извлекать значения из свойства содержимого большого двоичного объекта и метаданных каждого объекта.Параметр
imageActionсообщает индексатору извлекать текст из изображений, найденных в источнике данных. Конфигурация"imageAction":"generateNormalizedImages"вместе с навыком распознавания текста и навыком объединения текста инструктирует индексатор извлекать текст из изображений (например слово "стоп" из знака остановки движения) и вставлять его как часть поля содержимого. Это поведение применяется как к внедренным изображениям (подумайте о изображении внутри PDF-файла), так и к автономным файлам изображений, например к ФАЙЛу JPG.
Примечание.
Создание индексатора вызывает конвейер. Если есть проблемы с получением данных, сопоставлением входных и выходных данных или порядком операций, они появятся на этом этапе. Чтобы повторно запустить конвейер с изменениями кода или скрипта, вам может потребоваться сначала удалить объекты. Дополнительные сведения см. в статье Руководство по вызову API-интерфейсов когнитивного поиска (предварительная версия).
Мониторинга индексирования
Индексирование и обогащение начинаются сразу же после отправки запроса на создание индексатора. В зависимости от сложности набора навыков и операций индексирование может занять некоторое время.
Чтобы узнать, работает ли индексатор, вызовите состояние индексатора, чтобы проверить состояние индексатора.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Основные моменты:
Предупреждения распространены в некоторых сценариях и не всегда указывают на проблему. Например, если контейнер BLOB-объектов содержит файлы изображений, а конвейер не обрабатывает изображения, вы получите предупреждение о том, что изображения не обработаны.
В этом примере есть PNG-файл, содержащий текст. Все пять навыков на основе текста (распознавание речи, распознавание сущностей расположений, организаций, людей и извлечение ключевых фраз) не выполняются в этом файле. Полученное уведомление отображается в журнале выполнения.
Проверка результатов
Теперь, когда вы создали индекс, содержащий содержимое, созданное СИ, вызовите поиск документов для выполнения некоторых запросов, чтобы просмотреть результаты.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
Фильтры помогают сузить результаты до интересующих элементов:
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
Эти запросы иллюстрируют несколько способов работы с синтаксисом запросов и фильтрами в новых полях, созданных поиском ИИ Azure. Дополнительные примеры запросов см. в разделах с примерами для REST API поиска документов, запросов с простым синтаксисом и запросов full Lucene.
Сброс и повторный запуск
На ранних этапах разработки итерация по проектированию распространена. Сброс и повторное выполнение помогает выполнить итерацию.
Общие выводы
В этом руководстве показано, как использовать REST API для создания конвейера обогащения ИИ: источника данных, набора навыков, индекса и индексатора.
Были представлены встроенные навыки, а также определение набора навыков, которое показывает механику цепочки навыков совместно с помощью входных и выходных данных. Вы также узнали, что outputFieldMappings в определении индексатора требуется маршрутизация обогащенных значений из конвейера в индекс, доступный для поиска в служба ИИ Azure.
Наконец, вы узнали, как тестировать результаты и выполнять сброс системы для дальнейших итераций. Вы узнали, что отправка запросов к индексу возвращает результат, созданный обогащенным конвейером индексирования.
Очистка ресурсов
Если вы работаете в своей подписке, после завершения проекта целесообразно удалить созданные ресурсы, которые вам больше не потребуются. Ресурсы, которые продолжат работать, могут быть платными. Вы можете удалить ресурсы по отдельности либо удалить всю группу ресурсов.
Просматривать ресурсы и управлять ими можно на портале с помощью ссылок "Все ресурсы" или "Группы ресурсов" в области навигации слева.
Следующие шаги
Теперь, когда вы знакомы со всеми объектами в конвейере обогащения ИИ, ознакомьтесь с определениями набора навыков и отдельными навыками.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по