Запуск или сброс индексаторов, навыков или документов
В службе поиска искусственного интеллекта Azure существует несколько способов запуска индексатора:
- Запустите сразу после создания индексатора, если он не создан в режиме "отключен".
- Выполнение по расписанию для вызова выполнения через регулярные интервалы.
- Запустите по запросу с "сбросом" или без него.
В этой статье объясняется, как запускать индексаторы по запросу и без сброса. Он также описывает выполнение индексатора, длительность и параллелизм.
Как индексаторы подключаются к ресурсам Azure
Индексаторы — это одна из немногих подсистем, которые делают исходящие вызовы исходящих вызовов к другим ресурсам Azure. С точки зрения ролей Azure индексаторы не имеют отдельных удостоверений: подключение от поисковой системы к другому ресурсу Azure осуществляется с помощью управляемого удостоверения , назначаемого системой или пользователем службы поиска. Если индексатор подключается к ресурсу Azure в виртуальной сети, необходимо создать общую приватную ссылку для этого подключения. Дополнительные сведения о безопасных подключениях см. в статье "Безопасность" в службе "Поиск ИИ Azure".
Выполнение индексатора
Служба поиска выполняет одно задание индексатора на единицу поиска. Каждая служба поиска начинается с одной единицы поиска, но каждая новая секция или реплика увеличивает единицы поиска вашей службы. Вы можете проверить количество единиц поиска в разделе "Основные сведения" портала на странице "Обзор ". Если требуется параллельная обработка, убедитесь, что единицы поиска включают достаточные реплики. Индексаторы не выполняются в фоновом режиме, поэтому можно обнаружить больше регулирования запросов, чем обычно, если служба находится под давлением.
На следующем снимках экрана показано количество единиц поиска, которое определяет, сколько индексаторов может выполняться одновременно.

После запуска выполнения индексатора невозможно приостановить или остановить его. Выполнение индексатора останавливается, если нет больше документов для загрузки или обновления, или когда достигнуто максимальное ограничение времени выполнения.
Можно одновременно запускать несколько индексаторов, предполагая достаточную емкость, но каждый индексатор сам является одним экземпляром. Запуск нового экземпляра, когда индексатор уже находится в выполнении, выдает следующую ошибку: "Failed to run indexer "<indexer name>" error: "Another indexer invocation is currently in progress; concurrent invocations are not allowed."
Задание индексатора выполняется в управляемой среде выполнения. В настоящее время существует две среды:
Частная среда выполнения выполняется в кластерах поиска, относящихся к службе поиска. Если служба поиска имеет значение Standard2 или nigher, можно задать
executionEnvironmentпараметр в определении индексатора, чтобы всегда запускать индексатор в частной среде выполнения.Мультитенантная среда содержит процессоры содержимого, управляемые и защищенные корпорацией Майкрософт без дополнительных затрат. Эта среда используется для разгрузки вычислительно-ресурсоемких операций, в результате чего ресурсы, зависящие от службы, доступны для выполнения подпрограмм. По возможности большинство наборов навыков выполняются в мультитенантной среде. Это значение по умолчанию.
Вычислительные интенсивные обработки включают наборы навыков, выполняемые на процессорах содержимого, и задания индексатора большого объема или задания индексатора с большими документами. Обработка набора навыков на мультитенантных обработчиках содержимого определяется hueristics и системной информацией и не находится под контролем клиента. Службы S2 и более высокая поддержка привязки индексатора и набора навыков исключительно к кластерам поиска через
executionEnvironmentпараметр.Примечание.
Брандмауэры IP-адресов блокируют мультитенантную среду, поэтому если у вас есть брандмауэр, создайте правило, которое позволяет мультитенантной обработке.
Ограничения индексатора зависят от каждой среды:
| Рабочая нагрузка | Максимальная длительность | Максимальное количество заданий | Среда выполнения |
|---|---|---|---|
| Частное выполнение | 24 ч | Одно задание индексатора на единицу поиска 1. | Индексирование не выполняется в фоновом режиме. Вместо этого служба поиска будет балансировать все задания индексирования по текущим запросам и действиям управления объектами (например, созданию или обновлению индексов). При выполнении индексаторов следует ожидать, что некоторые задержки запросов будут отображаться, если объемы индексирования большие. |
| Мультитенантные | 2 часа 2 | Неопределенное 3 | Так как кластер обработки содержимого является мультитенантным, процессоры содержимого добавляются для удовлетворения спроса. Если вы испытываете задержку по запросу или запланированному выполнению, вероятно, это связано с тем, что система добавляет процессоры или ожидает того, что он станет доступным. |
1 Единицы поиска могут быть гибкими сочетаниями секций и реплик, но задания индексатора не привязаны к одному или другому. Другими словами, если у вас 12 единиц, можно одновременно выполнять 12 заданий индексатора, независимо от того, как развертываются единицы поиска.
2 Если для обработки всех данных требуется более двух часов, включите обнаружение изменений и запланируйте выполнение индексатора в течение 5 минут, чтобы возобновить индексирование быстро, если он останавливается из-за времени ожидания. Дополнительные стратегии см. в статье Индексирование большого набора данных.
3 "Неопределенное" означает, что ограничение не определяется числом заданий. Некоторые рабочие нагрузки, такие как обработка набора навыков, могут выполняться параллельно, что может привести к множеству заданий, даже если используется только один индексатор. Хотя среда не накладывает ограничения, ограничения индексатора для службы поиска по-прежнему применяются.
Запуск без сброса
Операция run Indexer обнаруживает и обрабатывает только то, что необходимо для синхронизации индекса поиска с изменениями в базовом источнике данных. Добавочное индексирование начинается путем поиска внутренней водяной отметки, чтобы найти последний обновленный документ поиска, который становится отправной точкой для выполнения индексатора над новыми и обновленными документами в источнике данных.
Обнаружение изменений важно для определения новых или обновленных в источнике данных. Индексаторы используют возможности обнаружения изменений базового источника данных, чтобы определить новые или обновленные возможности источника данных.
служба хранилища Azure имеет встроенное обнаружение изменений с помощью свойства LastModified.
Другие источники данных, такие как SQL Azure или Azure Cosmos DB, должны быть настроены для обнаружения изменений, прежде чем индексатор сможет считывать новые и обновленные строки.
Если базовое содержимое не изменяется, операция выполнения не влияет. В этом случае журнал выполнения индексатора будет указывать 0\0 на обработанные документы.
Чтобы выполнить повторную обработку, необходимо сбросить индексатор, как описано в следующем разделе.
Сброс индексаторов
После первоначального запуска индексатор отслеживает, какие документы поиска индексируются с помощью внутренней водяной отметки. Маркер никогда не предоставляется, но внутренне индексатор знает, где он последний остановлен.
Если необходимо перестроить все или часть индекса, можно очистить высокую воду индексатора с помощью сброса. API-интерфейсы сброса доступны на более низких уровнях в иерархии объектов:
- Сброс индексаторов очищает метку высокой воды и выполняет полный переиндекс всех документов
- Сброс документов (предварительная версия) переиндексирует определенный документ или список документов
- Сброс навыков (предварительная версия) вызывает обработку навыков для определенного навыка
После сброса выполните команду Run для повторной обработки новых и существующих документов. Потерянные документы поиска, не имеющие аналогов в источнике данных, не могут быть удалены с помощью сброса или запуска. Если вам нужно удалить документы, см . статью "Документы — индекс ".
Сброс и запуск индексаторов
Сброс очищает высокий водяной знак. Все документы в индексе поиска будут помечены для полной перезаписи без встроенных обновлений или объединения с существующим содержимым. Для индексаторов с набором навыков и кэшированием обогащения сброс индекса также будет неявно сбрасывать набор навыков.
Фактические действия возникают при выполнении сброса с помощью команды Run:
- Все новые документы, найденные базовым источником, добавляются в индекс поиска.
- Все документы, существующие как в источнике данных, так и в индексе поиска, будут перезаписаны в индексе поиска.
- Все обогащенное содержимое, созданное из наборов навыков, будет перестроено. Кэш обогащения, если он включен, обновляется.
Как отмечалось ранее, сброс является пассивной операцией: необходимо выполнить запрос запуска для перестроения индекса.
Операции сброса и запуска применяются к индексу поиска или хранилищу знаний, к определенным документам или проекциям, а также к кэшируемым обогащениям, если сброс явно или неявно включает навыки.
Сброс также применяется к операциям создания и обновления. Он не активирует удаление или очистку потерянных документов в индексе поиска. Дополнительные сведения об удалении документов см. в разделе "Документы — индекс".
После сброса индексатора невозможно отменить действие.
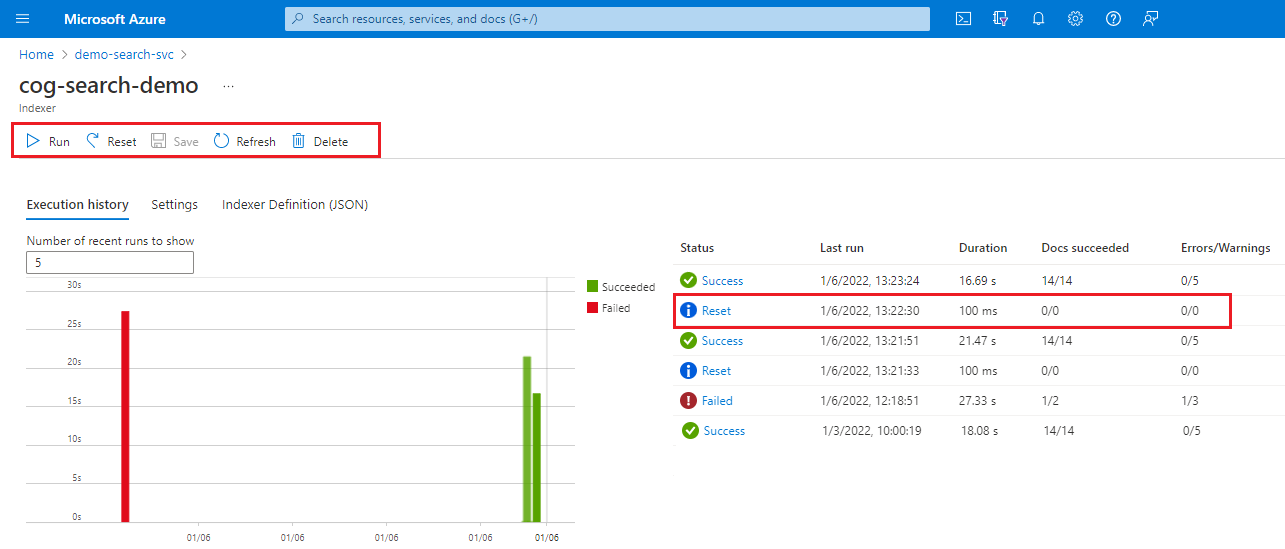
Войдите в портал Azure и откройте страницу службы поиска.
На странице "Обзор" выберите вкладку "Индексаторы".
Выберите индексатор.
Выберите команду "Сброс", а затем нажмите кнопку "Да", чтобы подтвердить действие.
Обновите страницу, чтобы отобразить состояние. Вы можете выбрать элемент, чтобы просмотреть его сведения.
Выберите "Запустить" , чтобы начать обработку индексатора или дождитесь следующего запланированного выполнения.
Сброс навыков (предварительная версия)
Для индексаторов, имеющих наборы навыков, можно сбросить отдельные навыки, чтобы принудительно обрабатывать только этот навык и любые подчиненные навыки, которые зависят от его выходных данных. Кэш обогащения, если он включен, также обновляется.
Сброс навыков в настоящее время доступен только для REST до 2020-06-30-preview или более поздней версии. Рекомендуется использовать последнюю предварительную версию API.
POST /skillsets/[skillset name]/resetskills?api-version=2024-05-01-preview
{
"skillNames" : [
"#1",
"#5",
"#6"
]
}
Вы можете указать отдельные навыки, как продемонстрировано в приведенном выше примере, но если для какого-либо из этих навыков потребуется результат отсутствующих в списке навыков (с #2 до #4), то будут выполняться отсутствующие в списке навыки, если только кэш не предоставит необходимые сведения. Чтобы это осуществилось, кэшированные обогащения для навыков с #2 по #4 не должны зависеть от #1 (указан для сброса).
Если никаких навыков не указано, выполняется весь набор навыков и, если кэширование включено, кэш также обновляется.
Не забудьте выполнить выполнение индексатора, чтобы вызвать фактическую обработку.
Как сбросить документы (предварительная версия)
Индексаторы — сброс документов принимает список ключей документов, чтобы можно было обновить определенные документы. При указании параметров сброса они становятся единственным определителем обрабатываемого объекта, независимо от других изменений в базовых данных. Например, если с момента последнего запуска индексатора были добавлены или обновлены 20 больших двоичных объектов, но сбросить только один документ, обрабатывается только этот документ.
При реализации принципа работы, основанного на документах, все поля в этом поисковом документе обновляются значениями из источника данных. Вы не можете выбрать и выбрать поля для обновления.
Если документ обогащен с помощью набора навыков и содержит кэшированные данные, набор навыков вызывается только для указанных документов, а кэш обновляется для повторно обработанных документов.
При первом тестировании этого API следующие API помогут вам проверить и проверить поведение. Вы можете использовать предварительный просмотр API версии 2020-06-30-preview и более поздних версий. Рекомендуется использовать последнюю предварительную версию API.
Индексаторы вызовов — получение состояния с предварительной версией API для проверки состояния сброса и состояния выполнения. Сведения о запросе на сброс можно найти в конце ответа о состоянии.
Индексаторы вызовов — сброс документов с предварительной версией API, чтобы указать, какие документы следует обрабатывать.
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2024-05-01-preview { "documentKeys" : [ "1001", "4452" ] }Ключи документов, указанные в запросе, — это значения из поискового индекса, которые могут отличаться от соответствующих полей в источнике данных. Если вы не уверены в значении ключа, отправьте запрос , чтобы вернуть значение. Можно использовать
selectдля возврата только поля ключа документа.Для больших двоичных объектов, которые анализируются в несколько документов поиска (где для синтаксического анализа задано значение jsonLines или jsonArrays или jsonArrays, или разделителя), ключ документа создается индексатором и может быть неизвестным для вас. В этом сценарии запрос ключа документа возвращает правильное значение.
Вызовите индексатор запуска (любая версия API), чтобы обработать указанные документы. Индексируются только те определенные документы.
Вызовите индексатор запуска во второй раз, чтобы обработать с последней высокой водяной отметки.
Вызовите документы поиска, чтобы проверить наличие обновленных значений, а также вернуть ключи документов, если вы не уверены в значении. Используйте
"select": "<field names>", если нужно ограничить поля, отображаемые в ответе.
Перезапись списка ключей документа
Вызов API сброса документов несколько раз с различными ключами добавляет новые ключи в список сброса ключей документов. Вызов API с параметром overwrite true перезаписывает текущий список новым:
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2020-06-30-Preview
{
"documentKeys" : [
"200",
"630"
],
"overwrite": true
}
Проверьте состояние сброса currentState
Чтобы проверить состояние сброса и узнать, какие ключи документов помещаются в очередь для обработки, выполните следующие действия.
Вызовите состояние индексатора с помощью API предварительной версии.
API предварительной версии вернет
currentStateраздел, найденный в конце ответа."currentState": { "mode": "indexingResetDocs", "allDocsInitialTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "allDocsFinalTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "resetDocsInitialTrackingState": null, "resetDocsFinalTrackingState": null, "resetDocumentKeys": [ "200", "630" ] }Проверьте режим:
Для параметра "Сброс навыков" необходимо задать
indexingAllDocsзначение "режим" (так как потенциально затрагиваются все документы с точки зрения полей, заполненных с помощью обогащения ИИ).Для параметра "Сброс документов" должно быть задано значение
indexingResetDocsmode. Индексатор сохраняет это состояние до тех пор, пока не будут обработаны все ключи документов, предоставленные в вызове сброса документов, в течение которого другие задания индексатора не будут выполняться во время выполнения операции. При поиске всех документов в списке ключей документов требуется анализ каждого документа для выполнения поиска и сопоставления по ключу. На это может понадобиться некоторое время, если у набора данных большой объем. Если в контейнере BLOB-объектов содержится несколько сотен больших двоичных объектов, а документы, которые нужно сбросить, находятся в конце, индексатор не будет искать совпадающие BLOB-объекты до тех пор, пока сначала не будет проверено все остальное.После повторной обработки документов снова запустите состояние индексатора. Индексатор возвращается в
indexingAllDocsрежим и обрабатывает все новые или обновленные документы при следующем запуске.
Следующие шаги
API-интерфейсы сброса используются для предоставления информации об области следующего выполнения индексатора. Для фактической обработки необходимо инициировать выполнение индексатора по запросу или разрешить запланированному заданию завершить работу. После завершения выполнения индексатор возвращается к нормальной обработке, независимо от того, осуществляется ли она по расписанию или по требованию.
После сброса и повторного запуска заданий индексатора можно отслеживать состояние из службы поиска или получать подробные сведения с помощью ведения журнала ресурсов.