Создание индексатора в поиске ИИ Azure
Используйте индексатор для автоматизации импорта и индексирования данных в службе "Поиск ИИ Azure". Индексатор — это именованный объект службы поиска, который подключается к внешнему источнику данных Azure, считывает данные и передает его в поисковую систему для индексирования. Использование индексаторов значительно сокращает количество и сложность кода, который необходимо написать, если вы используете поддерживаемый источник данных.
Индексаторы поддерживают два рабочих процесса:
Индексирование на основе текста, извлечение строк и метаданных из текстового содержимого для сценариев полнотекстового поиска.
Индексирование на основе навыков с помощью встроенных или пользовательских навыков, которые добавляют интегрированное машинное обучение для анализа изображений и большого неифференцированного содержимого, извлечения или вывода текста и структуры. Индексирование на основе навыков позволяет выполнять поиск по содержимому, которое в противном случае легко выполнять полнотекстовый поиск. Дополнительные сведения см. в статье "Обогащение ИИ" в службе "Поиск ИИ Azure".
В этой статье рассматриваются основные шаги по созданию индексатора. В зависимости от источника данных и рабочего процесса может потребоваться дополнительная конфигурация.
Необходимые компоненты
Поддерживаемый источник данных, содержащий содержимое, которое требуется принять.
Источник данных индексатора, который настраивает подключение к внешним данным.
Индекс поиска, который может принимать входящие данные.
Под максимальными ограничениями уровня служб. Уровень "Бесплатный" позволяет три объекта каждого типа и 1–3 минуты обработки индексатора или 3-10, если есть набор навыков.
Шаблоны индексатора
При создании индексатора определение является одним из двух шаблонов: индексирование на основе текста или обогащение ИИ с помощью навыков. Шаблоны одинаковы, за исключением того, что индексирование на основе навыков имеет больше определений.
Пример индексатора для индексирования на основе текста
Индексирование на основе текста для полнотекстового поиска является основным вариантом использования индексаторов, а для этого рабочего процесса индексатор выглядит следующим образом.
{
"name": (required) String that uniquely identifies the indexer,
"description": (optional),
"dataSourceName": (required) String indicating which existing data source to use,
"targetIndexName": (required) String indicating which existing index to use,
"parameters": {
"batchSize": null,
"maxFailedItems": 0,
"maxFailedItemsPerBatch": 0,
"base64EncodeKeys": false,
"configuration": {}
},
"fieldMappings": (optional) unless field discrepancies need resolution,
"disabled": null,
"schedule": null,
"encryptionKey": null
}
Индексаторы имеют следующие требования:
- Свойство
"name", однозначно определяющее индексатор в коллекции индексатора. - Свойство
"dataSourceName", указывающее на объект источника данных. Он указывает подключение к внешним данным. - Свойство
"targetIndexName", указывающее на индекс целевого поиска.
Другие параметры являются необязательными и изменяют поведение времени выполнения, например количество ошибок, которые необходимо принять перед сбоем всего задания. Обязательные параметры указываются во всех индексаторов и документируются в справочнике по REST API.
Индексаторы для отдельных источников данных для больших двоичных объектов, SQL и Azure Cosmos DB предоставляют дополнительные "configuration" параметры для поведения, зависяющего от источника. Например, если источником является хранилище BLOB-объектов, можно задать параметр, который фильтрует расширения файлов: "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf,.docx" } } Если источником является Azure SQL, можно задать параметр времени ожидания запроса.
Сопоставления полей используются для явного сопоставления полей источника с назначением, если между полем в источнике данных и полем в индексе поиска существуют несоответствия по имени или типу.
По умолчанию индексатор запускается сразу же при его создании в службе поиска. Если вы не хотите выполнять индексатор, задайте "disabled" значение true при создании индексатора.
Можно также указать расписание или задать ключ шифрования для дополнительного шифрования определения индексатора.
Пример индексатора для индексирования на основе навыков
Индексаторы также управляют обогащением ИИ. Все перечисленные выше свойства и параметры для применения, но следующие дополнительные свойства относятся к обогащению ИИ: "skillSetName", , "cache""outputFieldMappings".
{
"name": (required) String that uniquely identifies the indexer,
"dataSourceName": (required) String, provides raw content that will be enriched,
"targetIndexName": (required) String, name of an existing index,
"skillsetName" : (required for AI enrichment) String, name of an existing skillset,
"cache": {
"storageConnectionString" : (required if you enable the cache) Connection string to a blob container,
"enableReprocessing": true
},
"parameters": { },
"fieldMappings": (optional) Maps fields in the underlying data source to fields in an index,
"outputFieldMappings" : (required) Maps skill outputs to fields in an index,
}
Обогащение ИИ является собственной предметной областью и выходит за рамки этой статьи. Дополнительные сведения см. в разделе "Обогащение ИИ", "Наборы навыков" в службе "Поиск ИИ Azure", "Создание набора навыков", "Сопоставление выходных полей обогащения" и "Включение кэширования для обогащения ИИ".
Подготовка внешних данных
Индексаторы работают с наборами данных. При запуске индексатора он подключается к источнику данных, извлекает данные из контейнера или папки, при необходимости сериализует его в JSON перед передачей в поисковую систему для индексирования. В этом разделе описываются требования входящих данных для индексирования на основе текста.
| Исходные данные | Задачи |
|---|---|
| Документы JSON | Убедитесь, что структура или форма входящих данных соответствуют схеме индекса поиска. Большинство индексов поиска довольно плоские, где коллекция полей состоит из полей на одном уровне. Однако иерархические или вложенные структуры можно использовать с помощью сложных полей и коллекций. |
| Реляционная | Укажите его как плоский набор строк, где каждая строка становится полной или частичной документом поиска в индексе. Чтобы свести реляционные данные в набор строк, следует создать представление SQL или сформировать запрос, возвращающий родительские и дочерние записи в одной строке. Например, встроенный набор данных для отелей — это база данных SQL с 50 записями (по одному для каждого отеля), связанная с записями комнат в связанной таблице. Запрос, который выполняет сведение общих данных в набор строк, внедряет все сведения о номерах в документы JSON для каждой записи гостиницы. Внедренные сведения о номерах создаются запросом, использующим предложение FOR JSON AUTO. Дополнительные сведения об этом методе см. в статье Определение запроса, возвращающего внедренный код JSON. Это всего лишь один пример. Вы можете найти другие подходы, которые создают тот же результат. |
| Файлы | Индексатор обычно создает один документ поиска для каждого файла, где документ поиска состоит из полей для содержимого и метаданных. В зависимости от типа файла индексатор иногда может анализировать один файл в несколько документов поиска. Например, в CSV-файле каждая строка может стать автономным документом поиска. |
Помните, что необходимо извлекать только данные, доступные для поиска и фильтрации:
- Данные, доступные для поиска, — это текст.
- Фильтруемые данные являются буквенно-цифровыми.
Поиск azure AI не может выполнять поиск по двоичным данным в любом формате, хотя он может извлекать и выводить текстовые описания файлов изображений (см . обогащение ИИ) для создания содержимого, доступного для поиска. Аналогичным образом большой текст можно разбить и проанализировать с помощью моделей естественного языка, чтобы найти структуру или соответствующую информацию, создав новое содержимое, которое можно добавить в документ поиска.
Учитывая, что индексаторы не устраняют проблемы с данными, могут потребоваться другие виды очистки или обработки данных. Дополнительные сведения см. в документации по вашему продукту Базы данных Azure.
Подготовка источника данных
Индексаторы требуют источника данных, указывающего тип, контейнер и подключение.
Убедитесь, что используется поддерживаемый тип источника данных.
Создайте определение источника данных. Ниже перечислены некоторые из наиболее часто используемых источников данных:
Если источник данных является базой данных, например Azure SQL или Cosmos DB, включите отслеживание изменений. служба хранилища Azure имеет встроенное отслеживание изменений через
LastModifiedсвойство для каждого большого двоичного объекта, файла и таблицы. Приведенные выше ссылки для различных источников данных объясняют, какие методы отслеживания изменений поддерживаются индексаторами.
Подготовка индекса
Индексаторы также требуют индекса поиска. Помните, что индексаторы передают данные в поисковую систему для индексирования. У индексаторов имеются свойства, определяющие поведение выполнения. Точно так же у схемы индекса есть свойства, которые определяют, как индексируются строки (только строки анализируются и дополняются маркерами).
Начните с создания индекса поиска.
Настройте коллекцию полей и атрибуты полей.
Поля являются единственными рецепторами внешнего содержимого. В зависимости от того, как поля относятся к схеме, значения для каждого поля анализируются, токенизированы или хранятся в виде подробных строк для фильтров, нечетких запросов поиска и типа.
Индексаторы могут автоматически сопоставлять исходные поля с целевыми полями индекса, если имена и типы эквивалентны. Если поле не может быть неявно сопоставлено, помните, что можно определить явное сопоставление полей, указывающее индексатору, как маршрутизировать содержимое.
Просмотрите назначения анализатора в каждом поле. Анализаторы могут преобразовывать строки. Таким образом индексированные строки могут отличаться от переданных вами строк. Вы можете оценить влияние анализаторов с помощью функции анализа текста (REST). Дополнительные сведения об анализаторах см. в разделе Анализаторы для обработки текста в Когнитивном поиске Azure.
Во время индексирования индексатор проверяет только имена полей и типы. Нет шага проверки, гарантирующего правильность входящего содержимого для соответствующего поля поиска в индексе.
Создать индексатор
Когда вы будете готовы создать индексатор в службе удаленного поиска, вам потребуется клиент поиска. Клиент поиска может быть портал Azure, клиент REST или код, который создает экземпляр клиента индексатора. Для ранней разработки и проверки концепции рекомендуется использовать портал Azure или интерфейсы REST API.
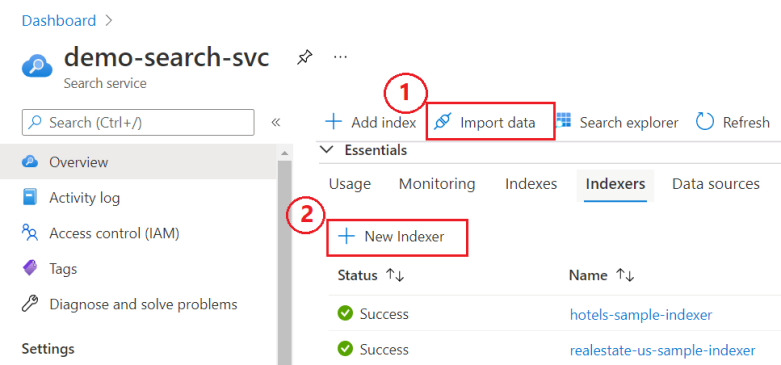
Войдите на портал Azure.
На странице обзора службы поиска выберите один из двух вариантов:
Мастер импорта данных. Мастер уникален тем, что он создает все необходимые элементы. Для других подходов требуется предопределенный источник данных и индекс.
Новый индексатор— визуальный редактор для указания определения индексатора.
На следующем снимке экрана показано, где можно найти эти функции на портале.
Запуск индексатора
По умолчанию индексатор запускается сразу же при его создании в службе поиска. Это поведение можно переопределить, установив "disabled" значение true в определении индексатора. Выполнение индексатора — это момент истины, когда вы узнаете, возникают ли проблемы с подключениями, сопоставлениями полей или построением набора навыков.
Запустить индексатор можно несколькими способами:
Запуск при создании или обновлении индексатора (по умолчанию).
Запустите по запросу, если нет изменений в определении или предшествует сбросу для полного индексирования. Дополнительные сведения см. в разделе "Запуск или сброс индексаторов".
Запланируйте обработку индексатора для вызова выполнения через регулярные интервалы.
Запланированное выполнение обычно реализуется, если требуется добавочное индексирование, чтобы можно было получить последние изменения. Таким образом, планирование зависит от обнаружения изменений.
Индексаторы — это одна из немногих подсистем, которые делают исходящие вызовы исходящих вызовов к другим ресурсам Azure. С точки зрения ролей Azure индексаторы не имеют отдельных удостоверений: подключение от поисковой системы к другому ресурсу Azure осуществляется с помощью управляемого удостоверения , назначаемого системой или пользователем службы поиска. Если индексатор подключается к ресурсу Azure в виртуальной сети, необходимо создать общую приватную ссылку для этого подключения. Дополнительные сведения о безопасных подключениях см. в статье "Безопасность" в службе "Поиск ИИ Azure".
Проверка результатов
Отслеживайте состояние индексатора, чтобы проверить состояние. Успешное выполнение по-прежнему может включать предупреждения и уведомления. Обязательно проверьте уведомления о состоянии успешного и неудачного состояния для получения сведений о задании.
Для проверки содержимого выполните запросы на заполненный индекс, возвращающий все документы или выбранные поля.
Обнаружение изменений и внутреннее состояние
Если источник данных поддерживает обнаружение изменений, индексатор может обнаруживать базовые изменения данных и обрабатывать только новые или обновленные документы для каждого запуска индексатора, оставляя без изменений содержимое как есть. Если журнал выполнения индексатора говорит, что выполнение было успешно обработано с 0/0 документами, это означает, что индексатор не обнаружил новые или измененные строки или большие двоичные объекты в базовом источнике данных.
Логика обнаружения изменений встроена в платформы данных. То, как индексатор поддерживает обнаружение изменений, зависит от источника данных.
служба хранилища Azure имеет встроенное обнаружение изменений, что означает, что индексатор может автоматически распознавать новые и обновленные документы. Хранилище BLOB-объектов, хранилище таблиц Azure и Azure Data Lake Storage 2-го поколения метки каждого обновления больших двоичных объектов или строк с датой и временем. Индексатор автоматически использует эти сведения для определения документов, которые нужно обновить в индексе. Дополнительные сведения об обнаружении удаления см. в статье "Удаление обнаружения с помощью индексаторов для служба хранилища Azure в поиске ИИ Azure".
Облачные технологии базы данных предоставляют необязательные функции обнаружения изменений на своих платформах. Для этих источников данных обнаружение изменений не является автоматическим. Необходимо указать в определении источника данных, какая политика используется:
Индексаторы отслеживают последний документ, обрабатываемый из источника данных, с помощью внутренней высокой водяной отметки. Эта метка никогда не отображается в API, но внутренний индексатор отслеживает ее положение. Когда индексирование возобновляется с помощью вызова по расписанию по запросу, индексатор ссылается на метку максимального уровня, чтобы продолжить обработку с места остановки.
Если необходимо очистить высокий водяной знак для повторной индексации в полном объеме, можно использовать индексатор сброса. Для более выборочного переиндексирования используйте параметры сброса или сброса документов. С помощью API сброса можно очистить внутреннее состояние, а также записать на диск кэш, если вы включили добавочное обогащение. Дополнительные общие сведения и сравнение всех вариантов сброса приведены в разделе о запуске индексаторов, а также сбросе индексаторов, навыков и документов.