Советы по повышению производительности в поиске ИИ Azure
Эта статья представляет собой коллекцию советов и рекомендаций по повышению производительности запросов и индексирования для поиска ключевых слов. Знание факторов, которые могут повлиять на производительность поиска, поможет избежать неэффективности и использовать службу поиска с максимальной отдачей. Вот некоторые основные факторы:
- Построение индекса (схема и размер)
- Структура запросов
- Емкость службы (ее уровень и количество реплик и секций)
Примечание.
Ищете стратегии по индексации большого объема? См. статью "Индексирование больших наборов данных" в службе "Поиск ИИ Azure".
Размер и схема индекса
Запросы выполняются быстрее в индексах небольшого размера. Одна из причин в том, что приходится проверять меньше полей, а вторая связана с тем, как система кэширует содержимое для будущих запросов. После первого запроса определенное содержимое остается в памяти, где его проще найти. Поскольку размер индекса, как правило, увеличивается со временем, рекомендуем периодически пересматривать построение индекса (как схему, так и документы), чтобы найти возможности для уменьшения объема содержимого. Однако если индекс имеет правильный размер, остается только увеличить емкость: добавить реплики либо повысить уровень службы. В разделе "Совет. Обновление до уровня "Стандартный" рассматривается увеличение масштаба и решение о горизонтальном масштабировании.
Сложность схемы также может негативно повлиять на производительность индексирования и запросов. При присвоении полям избыточных атрибутов возникают ограничения и требования к обработке. Если используются сложные типы, на индексирование и на выполнение запросов уходит больше времени. Все эти условия рассматриваются в разделах ниже.
Совет: присваивайте атрибуты полям выборочно
Распространенная ошибка, которую администраторы и разработчики делают при создании индекса поиска, выбирает все доступные свойства для полей, а не только выбор необходимых свойств. Например, если для поля не требуется поддержка полнотекстового поиска, не присваивайте этому полю атрибут доступности для поиска.
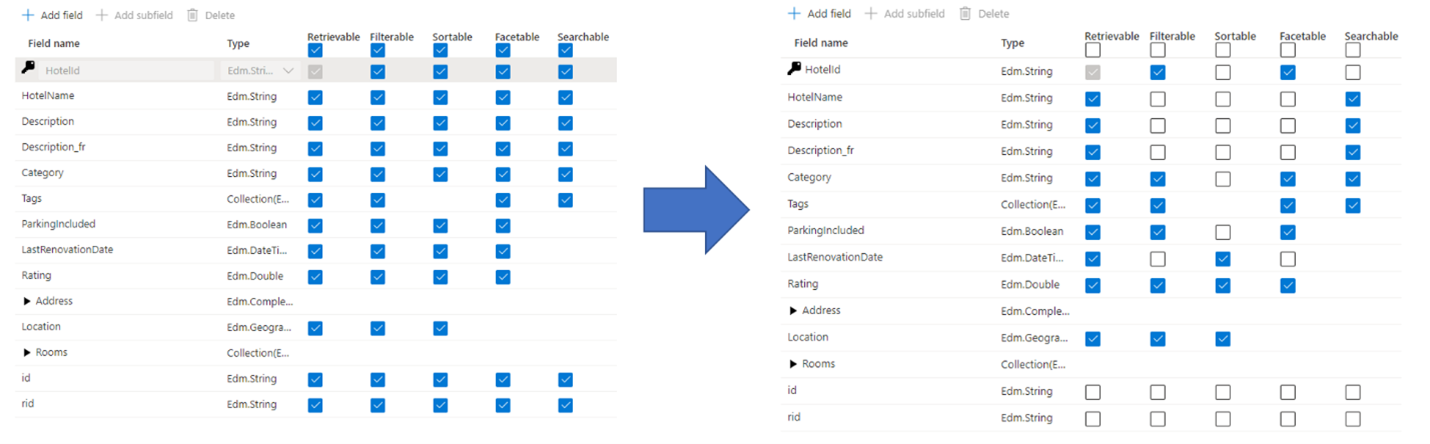
Поддержка фильтров, аспектов и сортировки может вчетверо увеличить требуемый объем хранилища. Если добавить средства подбора, потребуется еще больше места в хранилище. Сведения о том, как атрибуты влияют на требования к хранилищу, см. в разделе Атрибуты и размер индекса.
Коротко говоря, присвоение излишних атрибутов может привести к таким последствиям:
Производительность индексирования снижается из-за дополнительной работы, необходимой для обработки содержимого в поле и его последующего сохранения в инвертированном индексе поиска (устанавливайте атрибут доступности для поиска только для полей с содержимым, которое должно быть доступно для поиска).
При выполнении каждого запроса приходится обрабатывать больше данных. При полнотекстовом поиске проверяются все поля, помеченные как доступные для поиска.
Из-за потребности в дополнительной емкости хранилища возрастают эксплуатационные расходы. При фильтрации и сортировке требуется дополнительное пространство для хранения исходных (не проанализированных) строк. Не разрешайте фильтрацию и сортировку для тех полей, для которых в этом нет необходимости.
Во многих случаях присвоение ненужных атрибутов ограничивает возможности поля. Например, если поле допускает применение аспектов, а также доступно для фильтрации и поиска, в нем можно хранить не более 16 КБ текста, в то время как поле, доступное только для поиска, может содержать до 16 МБ текста.
Примечание.
Отказывайтесь только от тех атрибутов, которые действительно не нужны. Фильтры и аспекты часто очень важны для поиска, а при использовании фильтров часто требуется сортировка, чтобы можно было упорядочить результаты (сами фильтры возвращают неупорядоченные наборы).
Совет: рассмотрите альтернативы вместо сложных типов
Сложные типы данных полезны, если данные имеют сложную структуру с уровнями вложенности (например, элементы типа "родители-потомки", встречающиеся в документах JSON). Недостаток сложных типов — потребность в дополнительной емкости хранилища и в дополнительных ресурсах для индексирования содержимого в сравнении с несложными типами данных.
В некоторых случаях этого можно избежать, сопоставив сложную структуру данных с более простым типом поля, таким как "Коллекция". Кроме того, можно преобразовать иерархическую структуру в плоскую, содержащую поля корневого уровня.

Структура запросов
Состав и сложность запросов являются одним из наиболее важных факторов для производительности, а оптимизация запросов может значительно повысить производительность. При проектировании запросов уделяйте внимание следующим моментам:
Число полей, доступных для поиска. Каждое дополнительное поле поиска приводит к большей работе для службы поиска. Вы можете ограничить число полей, по которым выполняется поиск, во время выполнения запроса с помощью параметра searchFields. Чтобы повысить производительность, следует указывать только те поля, которые действительно важны.
Объем возвращаемых данных. Получение большого объема содержимого может замедлить запросы. Запрос следует структурировать таким образом, чтобы возвращать только те поля, которые необходимы для отображения страницы результатов, а затем получать оставшиеся поля с помощью API поиска, когда пользователь выбирает один из результатов.
Использование частичного поиска терминов. Частичные поисковые запросы терминов, такие как поиск префикса, нечеткий поиск и поиск регулярных выражений, являются более дорогостоящими, чем типичные поисковые слова, так как для получения результатов требуются полные проверки индекса.
Число аспектов. Добавление аспектов к запросам требует применения агрегата для каждого запроса. Чтобы запросить более высокое значение count для аспекта, также необходима дополнительная работа службы. В общем случае добавляйте только те аспекты, которые планируется отображать в приложении, и не запрашивайте большое количество аспектов без необходимости.
Высокие значения Skip. Если задать для параметра
$skipвысокое значение (например, несколько тысяч), повышается задержка поиска, так как обработчик получает и ранжирует большой объем документов для каждого запроса. Из соображений производительности рекомендуем избегать высоких значений$skipи использовать другие способы, например фильтрацию, для получения большого количества документов.Ограничение числа полей с высокой кратностью. К полям с высокой кратностью относятся поля, допускающие применение аспектов или фильтров, с большим числом уникальных значений, что приводит к значительному потреблению ресурсов для расчета результатов. Например, если указать поле "Код продукта" или "Описание" как поддерживающее аспекты или фильтры, оно станет полем с высокой кратностью, так как большинство значений в разных документах уникальны.
Совет: используйте функции поиска вместо сложных условий фильтра
Чем сложнее условия фильтра в поисковом запросе, тем медленнее он будет выполняться. Рассмотрим следующий пример, в котором фильтр используется для отбора результатов на основе удостоверения пользователя:
$filter= userid eq 123 or userid eq 234 or userid eq 345 or userid eq 456 or userid eq 567
В этом случае с помощью выражений фильтра проверяется, равно ли одно поле в каждом документе одному из множества возможных значений удостоверения пользователя. Скорее всего, вы найдете этот шаблон в приложениях, реализующих обрезку безопасности (проверка поля, содержащего один или несколько идентификаторов субъектов в списке основных идентификаторов, представляющих пользователя, выдавающего запрос).
Более эффективный способ применения фильтров, содержащих большое количество значений, — использовать функцию search.in, как показано в этом примере:
search.in(userid, '123,234,345,456,567', ',')
Совет: добавляйте секции для отдельных медленно выполняющихся запросов
Если производительность снижается для всех запросов, проблему часто можно устранить, добавив реплики. Но что делать, если проблема затрагивает только один запрос, который выполняется слишком долго? В этом сценарии добавление реплик не поможет, но другие секции могут быть. С помощью секций данные разделяются между дополнительными вычислительными ресурсами. Две секции разбивают данные пополам, третья секция разделяет их на три части и т. д.
Один из положительных побочных эффектов добавления секций проявляется в том, что медленные запросы иногда выполняются быстрее из-за параллельной обработки. Мы отметили параллелизацию при низкой селекторности запросов, таких как запросы, соответствующие многим документам, или аспекты, предоставляющие счетчики по большому количеству документов. Поскольку для оценки релевантности документов или подсчета количества документов требуются значительные объемы вычислений, добавление дополнительных секций позволяет ускорить выполнение запросов.
Чтобы добавить секции, используйте портал Azure, PowerShell, Azure CLI или пакет SDK для управления.
Емкость службы
Служба испытывает перегрузку, когда обработка запросов занимает слишком много времени или когда служба начинает отбрасывать запросы. В этом случае проблему можно решить, обновив службу или добавив емкость.
Уровень службы поиска и количество реплик или секций также оказывают большое влияние на производительность. Каждый постепенно более высокий уровень обеспечивает более быстрые ЦП и больше памяти, оба из которых оказывают положительное влияние на производительность.
Совет. Создание новой службы поиска высокой емкости
Базовые и стандартные службы, созданные [в поддерживаемых регионах](поддерживаемые регионы после 3 апреля 2024 г. имеют больше хранилища на секцию, чем старые службы. Перед обновлением до более высокого уровня и более высокой тарифной оплаты вернитесь к ограничениям службы уровня, чтобы узнать, предоставляет ли тот же уровень в новой службе необходимое хранилище.
Совет: выполните обновление до уровня "Стандартный" S2
Когда клиент только начинает работу, часто используется уровень службы поиска "Стандартный" S1. Для служб уровня S1 характерно то, что объем индексов растет со временем, так что требуется все больше секций. Чем больше секций, тем больше время отклика, поэтому для своевременной обработки всех запросов приходится добавлять реплики. Как можно понять, затраты на работу службы S1 повышаются до сумм, не предусмотренных изначально.
При таком положении дел важно задать себе вопрос о том, что эффективнее: переход на более высокий уровень или постепенное увеличение числа секций или реплик для имеющейся службы.
Рассмотрим следующую топологию в качестве примера службы, для которой требуется увеличение емкости:
- уровень "Стандартный" S1;
- размер индекса: 190 ГБ;
- число секций: 8 (на уровне S1 размер одной секции составляет 25 ГБ);
- число реплик: 2;
- всего единиц поиска: 16 (8 секций x 2 реплики);
- Гипотетическая розничная цена: ~$4000 USD /месяц (предполагается, что 250 ДОЛЛАРОВ США x 16 единиц поиска)
Предположим, что администратор службы постоянно сталкивается с увеличением задержек и планирует добавить еще одну реплику. В результате число реплик изменится с 2 на 3, а число единиц поиска увеличится до 24, так что цена составит 6000 долларов США в месяц.
Однако если администратор предпочтет перейти на уровень "Стандартный" S2, топология будет выглядеть следующим образом:
- уровень "Стандартный" S2;
- размер индекса: 190 ГБ;
- число секций: 2 (на уровне S2 размер одной секции составляет 100 ГБ);
- число реплик: 2;
- всего единиц поиска: 4 (2 секции x 2 реплики);
- Гипотетическая розничная цена: ~$4000 USD / месяц (1000 ДОЛЛАРОВ США x 4 единиц поиска)
Как показано в этом гипотетическом сценарии, во многих случаях при переходе на более высокий уровень затраты не возрастают. Кроме того, при выборе более высокого уровня предоставляется хранилище класса Premium, так что индексирование выполняется быстрее. Службам более высоких уровней также предоставляется больше памяти и вычислительной мощности. При одинаковых затратах можно получить более производительную инфраструктуру для поддержки того же индекса.
Дополнительная память дает важное преимущество: можно кэшировать больше содержимого индекса, а это позволит сократить задержку при поиске и увеличить число запросов в секунду. В итоге администратору, возможно, не придется даже задумываться о добавлении реплик, а расходы могут быть даже меньше, чем если бы было принято решение остаться на уровне S1.
Совет. Рассмотрим альтернативные варианты запросов регулярных выражений
Запросы регулярных выражений или регулярные выражения могут быть особенно дорогостоящими. Хотя они могут быть очень полезными для расширенных поисковых запросов, выполнение может требовать много мощности обработки, особенно если регулярное выражение сложно или если выполняется поиск по большому количеству данных. Все эти факторы способствуют высокой задержке поиска. В качестве устранения неполадок попробуйте упростить регулярное выражение или разорвать сложный запрос на меньшие, более управляемые запросы.
Следующие шаги
Ознакомьтесь с другими статьями, связанными с производительностью службы: