Анализ производительности в поиске ИИ Azure
В этой статье описываются инструменты, поведение и подходы для анализа производительности запросов и индексирования в службе "Поиск ИИ Azure".
Определение базовых показателей
В любой крупной реализации важно выполнить тест производительности для тестирования производительности служба ИИ Azure, прежде чем выполнить его развертывание в рабочей среде. Вы должны протестировать ожидаемую нагрузку поискового запроса, но и ожидаемые рабочие нагрузки приема данных (если это возможно, одновременное выполнение обеих рабочих нагрузок). Эталонные показатели помогают выбрать правильный уровень службы поиска, конфигурацию службы и оценить ожидаемую задержку запросов.
Для определения эталонных показателей мы рекомендуем использовать инструмент azure-search-performance-testing (GitHub).
Чтобы изолировать влияние архитектуры распределенной службы, попробуйте проверить конфигурации с одной репликой и одной секцией.
Примечание.
Для уровней "Оптимизировано для хранилища" (L1 и L2) следует ожидать меньшую пропускную способность обработки запросов и более высокую задержку по сравнению с уровнями "Стандартный".
Использование ведения журнала ресурсов
Самым важным средством диагностики в распоряжении администратора является ведение журнала ресурсов. Ведение журнала ресурсов — это сбор операционных данных и метрик службы поиска. Ведение журнала ресурсов включено с помощью Azure Monitor. За использование Azure Monitor и хранение данных взимается определенная плата, но эта служба может сыграть важную роль при диагностике проблем с производительностью.
На следующем рисунке показана цепочка событий в запросе запроса и ответе. Задержка может возникать в любом из них, будь то во время сетевой передачи, обработки содержимого на уровне служб приложений или службы поиска. Ключевое преимущество ведения журнала ресурсов заключается в том, что действия регистрируются с точки зрения службы поиска, что означает, что журнал может помочь определить, связана ли проблема с производительностью из-за проблем с запросом или индексированием или другой точкой сбоя.
Ведение журнала ресурсов предоставляет варианты хранения записываемой информации. Мы рекомендуем использовать Log Analytics, чтобы выполнять расширенные запросы Kusto к данным для поиска ответов на различные вопросы об использовании и производительности.
На страницах портала службы поиска можно включить ведение журнала с помощью параметров диагностики, а затем настроить запросы Kusto к Log Analytics в разделе Журналы. Дополнительные сведения о настройке этих параметров см. в статье Сбор и анализ данных журналов.
Алгоритмы регулирования
Регулирование возникает, когда служба поиска находится в емкости. Регулирование может происходить во время запросов или индексирования. Со стороны клиента вызов API при регулировании приводит к возникновению HTTP-ответа 503. Во время индексирования также существует возможность получения HTTP-ответа 207, указывающего, что один или несколько элементов не удалось индексировать. Эта ошибка является индикатором того, что служба поиска почти исчерпала свою емкость.
Как правило, попробуйте квалифицировать количество регулирования и любые шаблоны. Например, если один поисковый запрос из 500 000 регулируется, это может быть не стоит исследовать. Однако если в течение некоторого времени регулируется значительная доля запросов, это является более серьезным поводом для беспокойства. Оценка регулирования в течение определенного периода также помогает определить временные рамки, когда этот эффект наиболее вероятен, и решить, как лучше избежать его возникновения.
Простым решением для большинства проблем с регулированием является увеличение ресурсов для службы поиска (обычно это реплики для регулирования запросов или секции для регулировании индексирования). Однако увеличение реплика или секций добавляет затраты, поэтому важно знать причину, почему регулирование происходит на всех. Анализ условий, вызывающих регулирование, рассматривается в следующих нескольких разделах.
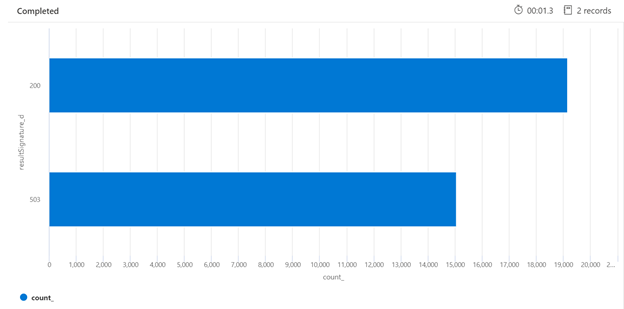
Ниже приведен пример запроса Kusto, который получает разбивку HTTP-ответов от службы поиска, работающей под нагрузкой. В течение 7-дневного периода отрисованная линейчатая диаграмма показывает, что относительно большой процент поисковых запросов был регулироваться по сравнению с числом успешных ответов (200).
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
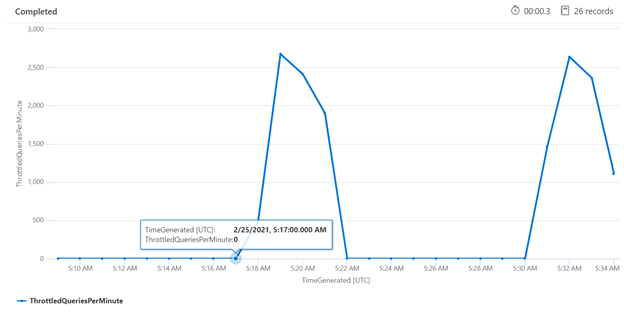
Анализ регулирования за определенный период может помочь определить моменты, когда регулирование происходит чаще всего. В приведенном ниже примере на диаграмме временных рядов отражено число отрегулированных запросов за указанный промежуток времени. В этом случае отрегулированные запросы коррелируют с моментами выполнения эталонных тестов производительности.
let ['_startTime']=datetime('2021-02-25T20:45:07Z');
let ['_endTime']=datetime('2021-03-03T20:45:07Z');
let intervalsize = 1m;
AzureDiagnostics
| where TimeGenerated > ago(7d)
| where resultSignature_d != 403 and resultSignature_d != 404 and OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete")
| summarize
ThrottledQueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete") and resultSignature_d == 503)/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Измерение отдельных запросов
В некоторых случаях это может быть полезно для тестирования отдельных запросов, чтобы узнать, как они выполняются. Для этого важно узнать, сколько времени занимает служба поиска, чтобы завершить работу, а также сколько времени требуется для выполнения запроса на круговую поездку от клиента и обратно к клиенту. Журналы диагностика можно использовать для поиска отдельных операций, но это может быть проще сделать из клиента REST.
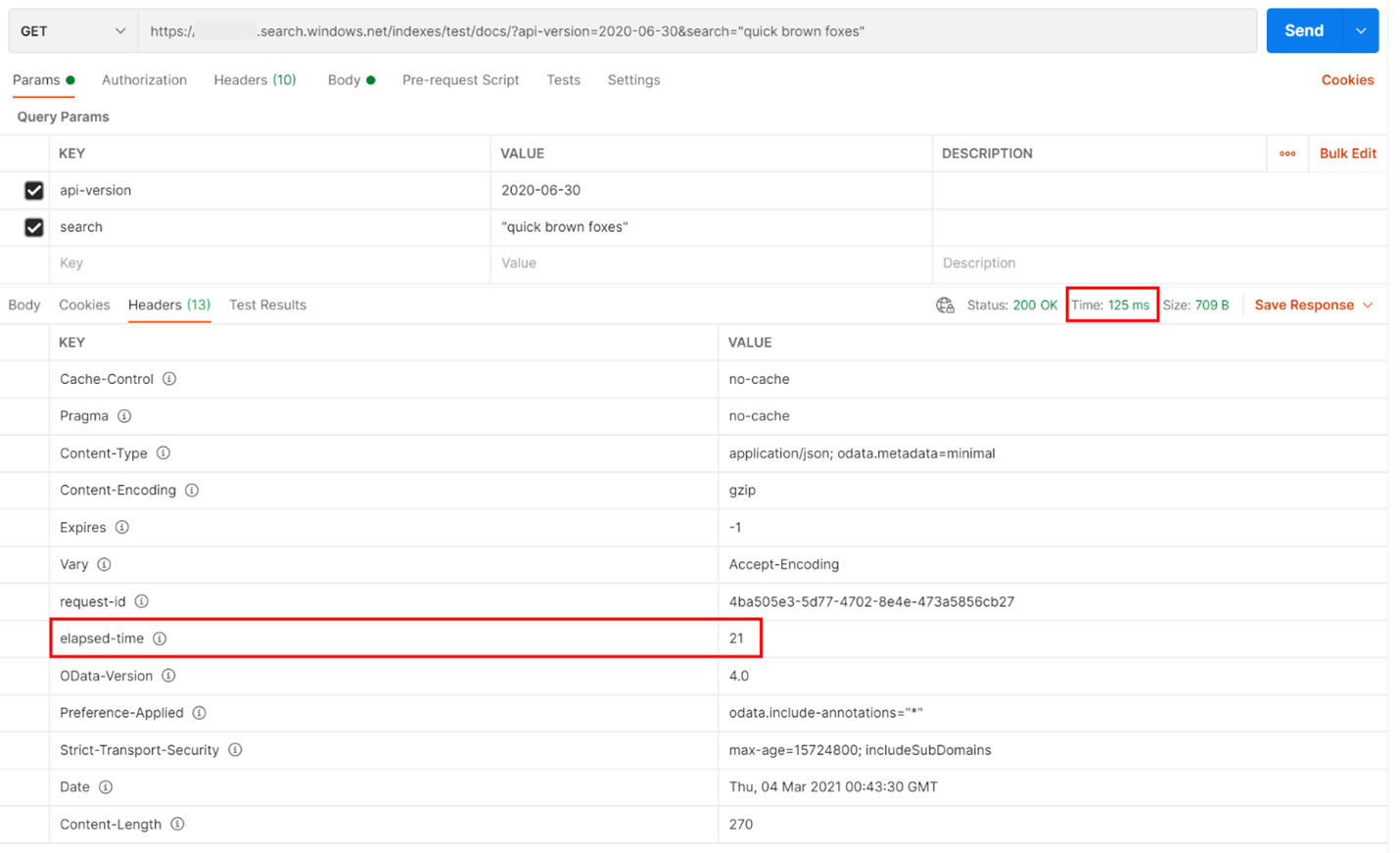
В примере ниже был выполнен поисковый запрос REST в службе поиска. Поиск по искусственному интеллекту Azure включает в каждый ответ количество миллисекундах, которое требуется для выполнения запроса, видимого на вкладке "Заголовки" в "истекшее время". Рядом с состоянием в верхней части ответа вы найдете длительность круговой поездки( в этом случае 418 миллисекунд (мс). В разделе результатов выбрана вкладка "Заголовки". Используя эти два значения, выделенные красным полем на изображении ниже, мы видим, что служба поиска заняла 21 мс, чтобы завершить поисковый запрос, и весь запрос на круговую поездку клиента занял 125 мс. Вычитая эти два числа, мы можем определить, что потребовалось 104-мс дополнительного времени для передачи поискового запроса в службу поиска и передачи результатов поиска клиенту.
Этот метод помогает изолировать задержку сети от других факторов, влияющих на производительность запросов.
Скорость запросов
Одним из факторов, из-за которых служба поиска начинает регулировать запросы, является большее число запросов, выполняемых при записи тома — этот показатель оценивается по числу запросов в секунду (QPS) или запросов в минуту (QPM). По мере увеличения показателя QPS службе поиска, как правило, требуется больше времени, чтобы отреагировать на эти запросы, она постепенно отстает и начинает отправлять обратно HTTP-ответ 503 (активируется регулирование).
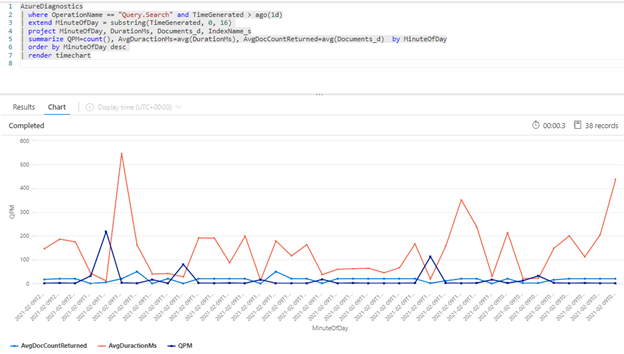
В следующем запросе Kusto показан объем запросов (в QPM), а также средняя длительность запроса в миллисекундах (AvgDurationMS) и среднее количество документов (AvgDocCountReturned), возвращаемых в каждом запросе.
AzureDiagnostics
| where OperationName == "Query.Search" and TimeGenerated > ago(1d)
| extend MinuteOfDay = substring(TimeGenerated, 0, 16)
| project MinuteOfDay, DurationMs, Documents_d, IndexName_s
| summarize QPM=count(), AvgDuractionMs=avg(DurationMs), AvgDocCountReturned=avg(Documents_d) by MinuteOfDay
| order by MinuteOfDay desc
| render timechart
Совет
Чтобы посмотреть данные, на которых основана эта диаграмма, удалите строку | render timechart, а затем повторно запустите запрос.
Влияние индексирования на запросы
Важным фактором, который следует учитывать при оценке производительности, является то, что индексирование использует те же ресурсы, что и поисковые запросы. Если вы индексируете большое количество содержимого, вы можете ожидать увеличения задержки по мере того, как служба пытается разместить обе рабочие нагрузки.
Если обработка запросов замедляется, проверьте время запуска индексирования, чтобы выяснить, не совпадает ли оно с периодом замедления. Возможно, индексатор выполняет ежедневное или ежечасное задание, которое коррелирует со снижением производительности поисковых запросов.
В этом разделе содержится набор запросов, которые помогают визуализировать скорости поиска и индексирования. В этих примерах диапазон времени задается в запросе. При выполнении запросов на портал Azure не забудьте выбрать вариант В запросе.
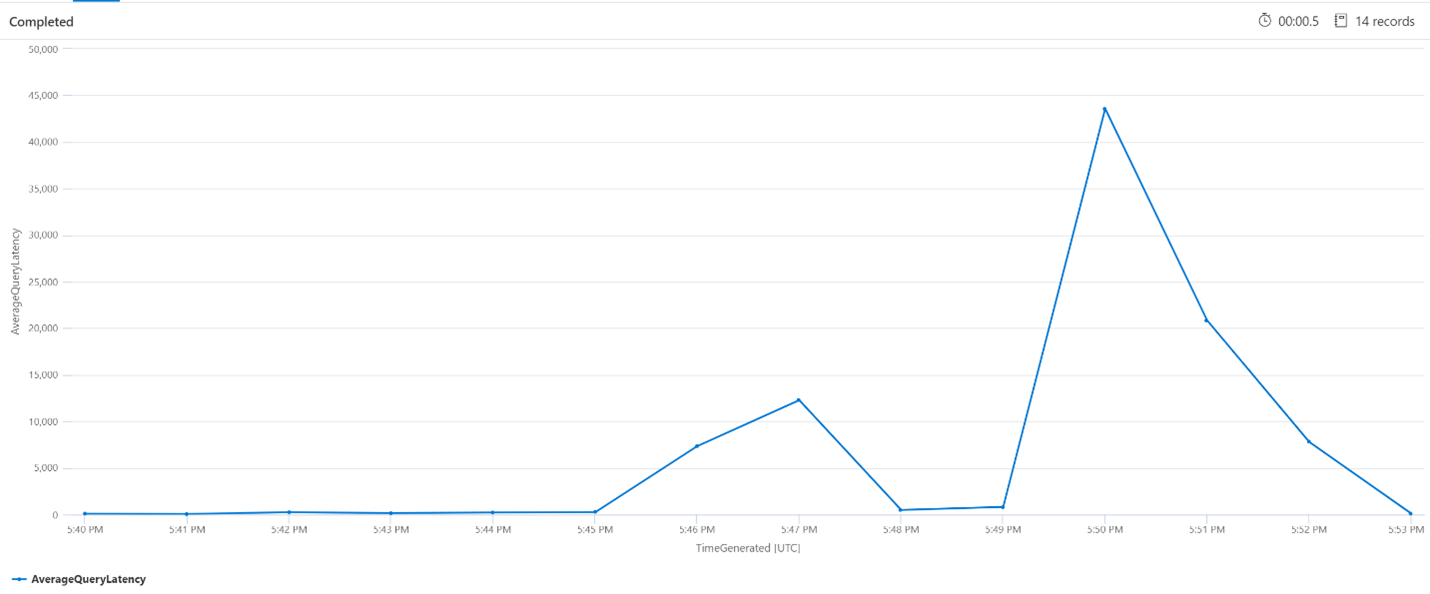
Средняя задержка запросов
В запросе ниже для отображения средней задержки поисковых запросов используется интервал в 1 минуту. На диаграмме видно, что средняя задержка была низкой до 5:45 вечера и длилась до 5:53 вечера.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime']..['_endTime']) // Time range filtering
| summarize AverageQueryLatency = avgif(DurationMs, OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))
by bin(TimeGenerated, intervalsize)
| render timechart
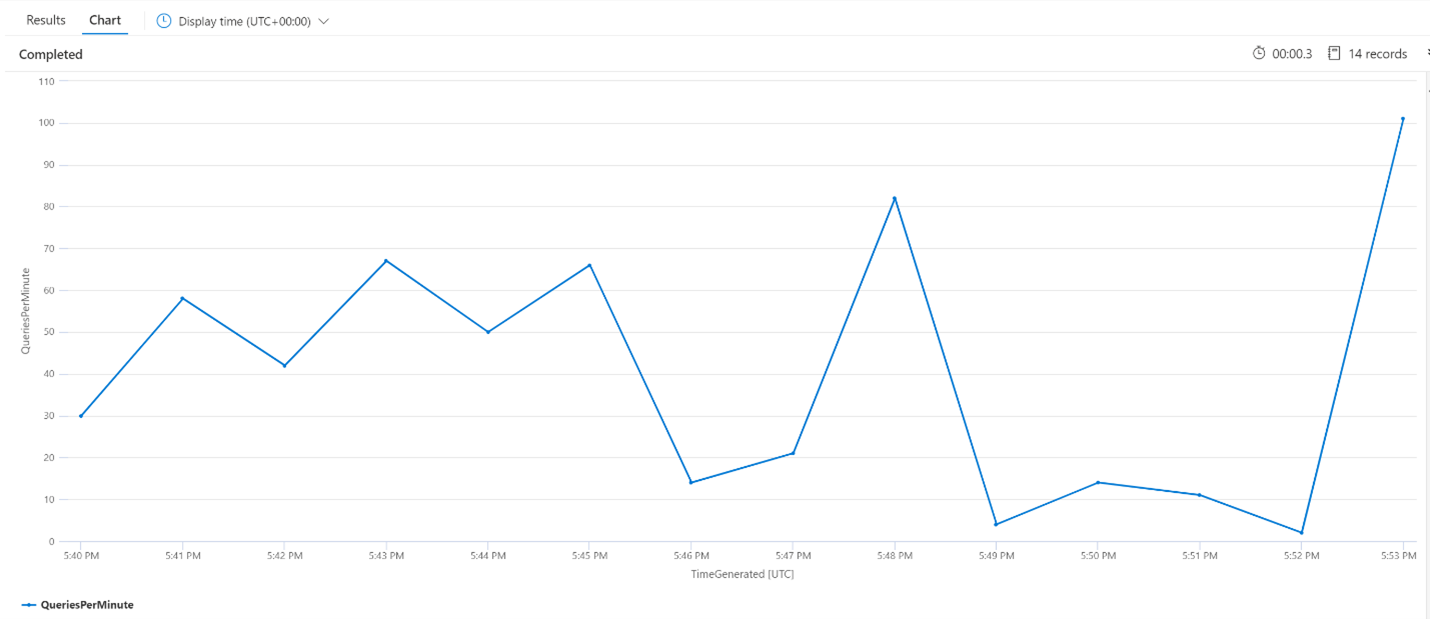
Среднее число запросов в минуту (QPM)
Следующий запрос проверяет среднее количество запросов в минуту, чтобы убедиться, что не было всплеска запросов поиска, которые могли повлиять на задержку. На диаграмме мы видим, что есть некоторые дисперсии, но ничего, чтобы указать всплеск количества запросов.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize QueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
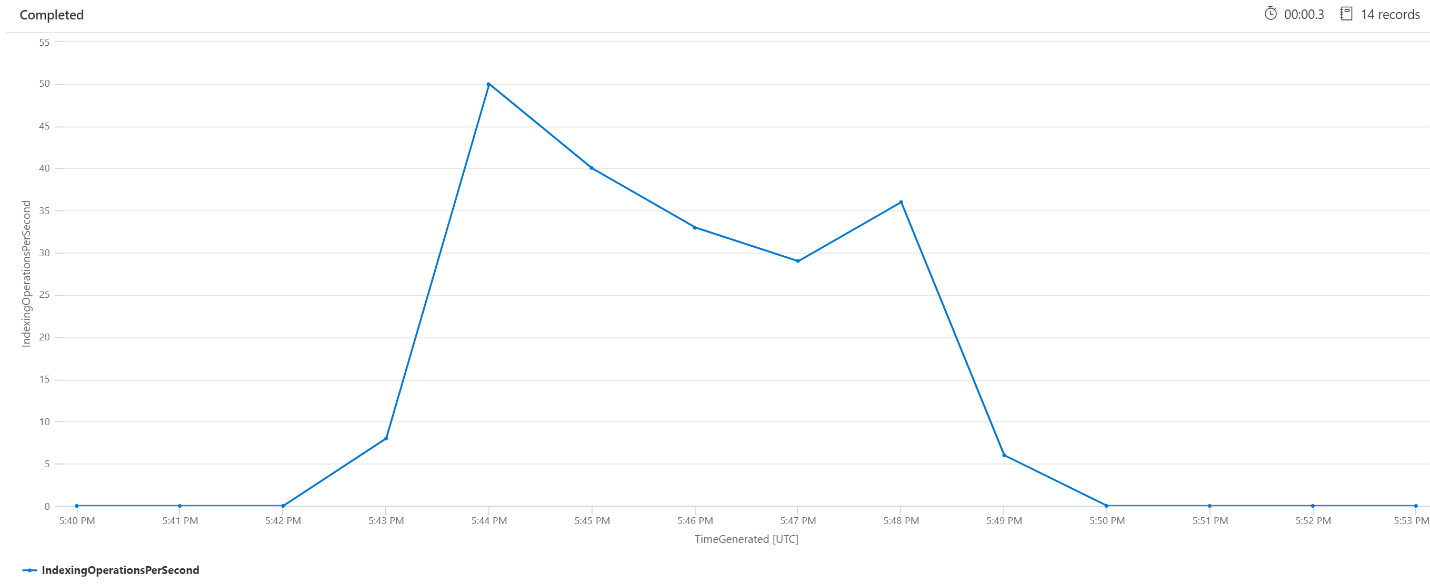
Операции индексирования в минуту (OPM)
Здесь мы рассмотрим количество операций индексирования в минуту. На диаграмме видно, что большой объем данных был индексирован в 5:42 вечера и закончился в 5:50 вечера. Индексирование началось за 3 минуты до увеличения задержки поисковых запросов и завершилось за 3 минуты до того, как задержка исчезла.
Из этого аналитических сведений видно, что для службы поиска потребовалось около 3 минут, чтобы они были достаточно заняты для индексирования, чтобы повлиять на задержку запроса. Мы также видим, что после завершения индексирования служба поиска заняла еще 3 минуты, чтобы завершить всю работу из недавно индексированного содержимого, а также задержку запроса для разрешения.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize IndexingOperationsPerSecond=bin(countif(OperationName == "Indexing.Index")/ (intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Фоновая обработка службы
Это не необычно, чтобы увидеть периодические пики в запросе или индексировании задержки. Пики могут возникать в результате индексирования или повышения скорости запросов, однако это может происходить и во время операций слияния. Поисковые индексы хранятся во фрагментах, или сегментах. Периодически система объединяет меньшие сегменты в более крупные, чтобы оптимизировать производительность службы. Этот процесс слияния также удаляет документы, которые ранее были помечены для удаления из индекса, что приводит к освобождению дискового пространства.
Объединение сегментов выполняется быстро, но этот процесс требует больших ресурсов и, таким образом, может снизить производительность службы. Если вы заметите короткие всплески задержки запроса, и эти всплески совпадают с недавними изменениями индексированного содержимого, вы можете предположить, что задержка связана с операциями слияния сегментов.
Следующие шаги
Ознакомьтесь с этими статьями, связанными с анализом производительности службы.