Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Поиск ИИ Azure может извлекать и индексировать текст и изображения из документов PDF, хранящихся в хранилище BLOB-объектов Azure. В этом руководстве показано, как создать конвейер многомодального индексирования, описывая визуальное содержимое на естественном языке и внедряя его вместе с текстом документа.
В исходном документе каждый образ передается навыку запроса GenAI (предварительная версия) для создания краткого текстового описания. Эти описания вместе с исходным текстом документа затем внедряются в векторные представления с помощью модели Azure OpenAI text-embedding-3-large. Результатом является один индекс, содержащий семантический искомый контент из обоих модальности: текст и словесные изображения.
В этом руководстве вы используете следующее:
36-страничный PDF-документ, который объединяет форматированное визуальное содержимое, например диаграммы, инфографики и сканированные страницы с традиционным текстом.
Функция извлечения документов для извлечения нормализованных изображений и текста.
Навык запроса GenAI (предварительная версия) для создания подписей изображений, которые представляют собой текстовые описания визуального содержимого для поиска и заземления.
Индекс поиска, настроенный для хранения внедренных текста и изображений и поддержки поиска сходства на основе векторов.
В этом руководстве демонстрируется менее затратный подход к индексации многомодального контента с помощью модуля извлечения данных из документов и генерации подписей изображений. Он позволяет извлекать и выполнять поиск по тексту и изображениям из документов в хранилище BLOB-объектов Azure. Однако в нём отсутствуют метаданные о расположении текста, такие как номера страниц или ограничивающие области.
Более комплексное решение, включающее структурированный текстовый макет и пространственные метаданные, см. в разделе Индексирование больших двоичных объектов с текстом и изображениями для сценариев многомодальной RAG с помощью навыка словизации изображений и макета документов.
Замечание
Для этого руководства требуется установить imageAction на generateNormalizedImages и взимается дополнительная плата за извлечение изображений согласно ценам на поиск с использованием искусственного интеллекта Azure.
Используя клиент REST и REST API поиска, вы будете:
- Настройте образцы данных и сконфигурируйте источник данных
azureblob - Создание индекса с поддержкой внедрения текста и изображения
- Определите набор навыков с этапами по извлечению, созданию подписей и внедрению
- Создание и запуск индексатора для обработки и индексирования содержимого
- Поиск по индексу, который вы только что создали.
Предпосылки
Учетная запись Azure с активной подпиской. Создайте учетную запись бесплатно .
Поиск ИИ Azure, ценовая категория "Базовый" или выше, с управляемым удостоверением. Создайте службу или найдите существующую службу в текущей подписке.
Visual Studio Code с клиентом REST.
Загрузка файлов
Скачайте следующий пример PDF- файла:
Загрузка образцов данных в службу хранилища Azure
В Azure Storage создайте новый контейнер с именем doc-extraction-image-verbalization-container.
Для подключений, выполненных с помощью управляемого удостоверения, назначаемого системой. Укажите строку подключения, содержащую ResourceId, без ключа учетной записи или пароля. ResourceId должен содержать идентификатор подписки учетной записи хранения, группу ресурсов учетной записи хранения и имя учетной записи хранения. Строка подключения аналогична следующему примеру:
"credentials" : { "connectionString" : "ResourceId=/subscriptions/00000000-0000-0000-0000-00000000/resourceGroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.Storage/storageAccounts/MY-DEMO-STORAGE-ACCOUNT/;" }Для подключений, сделанных с помощью управляемого удостоверения, назначаемого пользователем. Укажите строку подключения, содержащую ResourceId, без ключа учетной записи или пароля. ResourceId должен содержать идентификатор подписки учетной записи хранения, группу ресурсов учетной записи хранения и имя учетной записи хранения. Предоставьте идентификатор с помощью синтаксиса, показанного в следующем примере. Установите userAssignedIdentity для управляемого удостоверения, назначенного пользователем, как в следующем примере настройки строки подключения:
"credentials" : { "connectionString" : "ResourceId=/subscriptions/00000000-0000-0000-0000-00000000/resourceGroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.Storage/storageAccounts/MY-DEMO-STORAGE-ACCOUNT/;" }, "identity" : { "@odata.type": "#Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity" : "/subscriptions/00000000-0000-0000-0000-00000000/resourcegroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.ManagedIdentity/userAssignedIdentities/MY-DEMO-USER-MANAGED-IDENTITY" }
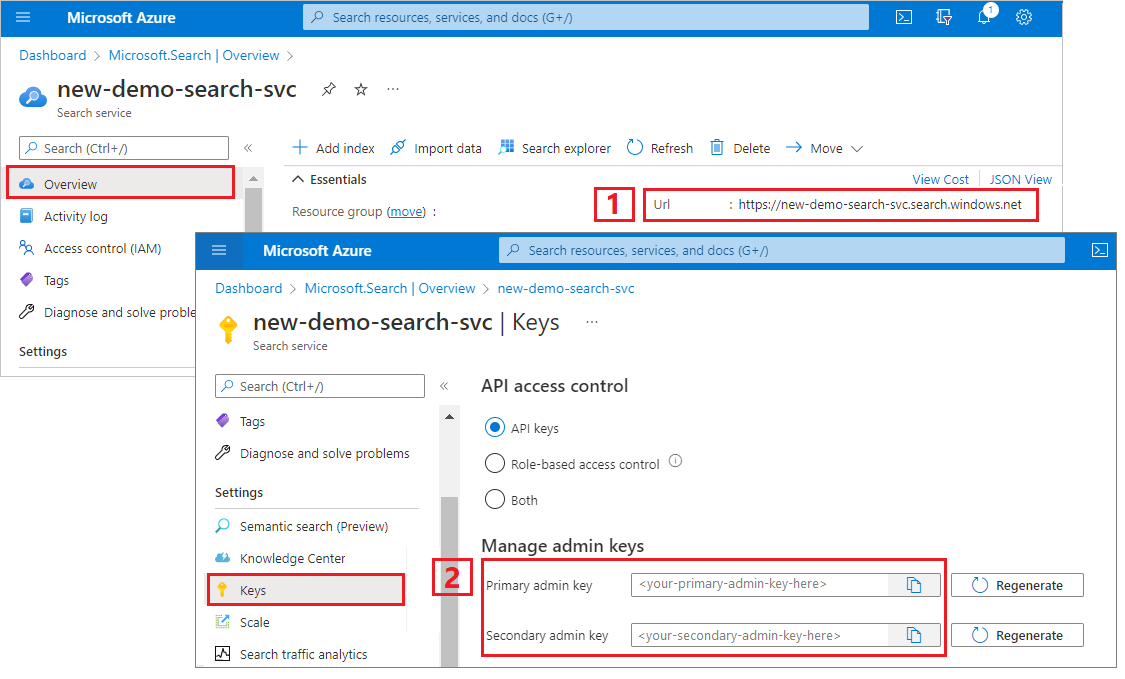
Копирование URL-адреса службы поиска и ключа API
Для выполнения этого руководства потребуется конечная точка и ключ API для подключений к службе "Поиск ИИ Azure". Эти значения можно получить из портал Azure. Способы альтернативного подключения смотрите в разделе «Управляемые удостоверения».
Войдите в портал Azure, перейдите на страницу обзора службы поиска и скопируйте URL-адрес. Пример конечной точки может выглядеть так:
https://mydemo.search.windows.net.В разделе «Параметры»>«Ключи» скопируйте ключ администратора. Ключи администратора используются для добавления, изменения и удаления объектов. Существует два взаимозаменяемых ключа администратора. Скопируйте любой из них.
Настройка REST-файла
Запустите Visual Studio Code и создайте новый файл.
Укажите значения переменных, используемых в запросе.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @openAIResourceUri = PUT-YOUR-OPENAI-URI-HERE @openAIKey = PUT-YOUR-OPENAI-KEY-HERE @chatCompletionResourceUri = PUT-YOUR-CHAT-COMPLETION-URI-HERE @chatCompletionKey = PUT-YOUR-CHAT-COMPLETION-KEY-HERE @imageProjectionContainer=PUT-YOUR-IMAGE-PROJECTION-CONTAINER-HEREСохраните файл с помощью
.restрасширения или.httpрасширения.
Дополнительные сведения о клиенте REST см. в кратком руководстве. Полнотекстовый поиск с помощью REST.
Создание источника данных
Создание источника данных (REST) создает подключение к источнику данных, указывающее, какие данные следует индексировать.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "doc-extraction-image-verbalization-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnection}}"
},
"container": {
"name": "doc-extraction-image-verbalization-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Отправьте запрос. Результат должен выглядеть следующим образом:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows-int.net:443/datasources('doc-extraction-image-verbalization-ds')?api-version=2025-05-01-preview -Preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 4eb8bcc3-27b5-44af-834e-295ed078e8ed
elapsed-time: 346
Date: Sat, 26 Apr 2025 21:25:24 GMT
Connection: close
{
"name": "doc-extraction-image-verbalization-ds",
"description": "A test datasource",
"type": "azureblob",
"subtype": null,
"indexerPermissionOptions": [],
"credentials": {
"connectionString": null
},
"container": {
"name": "doc-extraction-multimodality-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Создание индекса
Создание индекса (REST) создает индекс поиска в службе поиска. Индекс указывает все параметры и их атрибуты.
Для вложенных json поля индекса должны совпадать с исходными полями. В настоящее время поиск ИИ Azure не поддерживает сопоставления полей с вложенным JSON, поэтому имена полей и типы данных должны полностью соответствовать. Следующий индекс соответствует элементам JSON в необработанном содержимом.
### Create an index
POST {{baseUrl}}/indexes?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "doc-extraction-image-verbalization-index",
"fields": [
{
"name": "content_id",
"type": "Edm.String",
"retrievable": true,
"key": true,
"analyzer": "keyword"
},
{
"name": "text_document_id",
"type": "Edm.String",
"searchable": false,
"filterable": true,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false
},
{
"name": "document_title",
"type": "Edm.String",
"searchable": true
},
{
"name": "image_document_id",
"type": "Edm.String",
"filterable": true,
"retrievable": true
},
{
"name": "content_text",
"type": "Edm.String",
"searchable": true,
"retrievable": true
},
{
"name": "content_embedding",
"type": "Collection(Edm.Single)",
"dimensions": 3072,
"searchable": true,
"retrievable": true,
"vectorSearchProfile": "hnsw"
},
{
"name": "content_path",
"type": "Edm.String",
"searchable": false,
"retrievable": true
},
{
"name": "offset",
"type": "Edm.String",
"searchable": false,
"retrievable": true
},
{
"name": "location_metadata",
"type": "Edm.ComplexType",
"fields": [
{
"name": "page_number",
"type": "Edm.Int32",
"searchable": false,
"retrievable": true
},
{
"name": "bounding_polygons",
"type": "Edm.String",
"searchable": false,
"retrievable": true,
"filterable": false,
"sortable": false,
"facetable": false
}
]
}
],
"vectorSearch": {
"profiles": [
{
"name": "hnsw",
"algorithm": "defaulthnsw",
"vectorizer": "{{vectorizer}}"
}
],
"algorithms": [
{
"name": "defaulthnsw",
"kind": "hnsw",
"hnswParameters": {
"m": 4,
"efConstruction": 400,
"metric": "cosine"
}
}
],
"vectorizers": [
{
"name": "{{vectorizer}}",
"kind": "azureOpenAI",
"azureOpenAIParameters": {
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"modelName": "text-embedding-3-large"
}
}
]
},
"semantic": {
"defaultConfiguration": "semanticconfig",
"configurations": [
{
"name": "semanticconfig",
"prioritizedFields": {
"titleField": {
"fieldName": "document_title"
},
"prioritizedContentFields": [
],
"prioritizedKeywordsFields": []
}
}
]
}
}
Основные моменты:
Вставки текста и изображения хранятся в
content_embeddingполе и должны быть настроены с соответствующими измерениями (например, 3072) и профилем векторного поиска.location_metadataфиксирует ограничивающий полигон и метаданные, связанные с номером страницы, для каждого нормализованного изображения, что позволяет выполнять точный пространственный поиск или накладывать элементы пользовательского интерфейса.location_metadataсуществует только для изображений в этом сценарии. Если вы хотите записать метаданные географического расположения для текста, рассмотрите возможность использования навыка макета документов. Внизу страницы представлено подробное руководство.Дополнительные сведения о поиске векторов см. в статье "Векторы" в службе "Поиск ИИ Azure".
Дополнительные сведения о семантическом ранжировании см. в статье "Семантическое ранжирование в Azure AI Search".
Создание набора навыков
Создание набора навыков (REST) создает индекс поиска в службе поиска. Индекс указывает все параметры и их атрибуты.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "doc-extraction-image-verbalization-skillset",
"description": "A test skillset",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Util.DocumentExtractionSkill",
"name": "document-extraction-skill",
"description": "Document extraction skill to exract text and images from documents",
"parsingMode": "default",
"dataToExtract": "contentAndMetadata",
"configuration": {
"imageAction": "generateNormalizedImages",
"normalizedImageMaxWidth": 2000,
"normalizedImageMaxHeight": 2000
},
"context": "/document",
"inputs": [
{
"name": "file_data",
"source": "/document/file_data"
}
],
"outputs": [
{
"name": "content",
"targetName": "extracted_content"
},
{
"name": "normalized_images",
"targetName": "normalized_images"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "split-skill",
"description": "Split skill to chunk documents",
"context": "/document",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 200,
"unit": "characters",
"inputs": [
{
"name": "text",
"source": "/document/extracted_content",
"inputs": []
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "text-embedding-skill",
"description": "Embedding skill for text",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "embedding",
"targetName": "text_vector"
}
],
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"dimensions": 3072,
"modelName": "text-embedding-3-large"
},
{
"@odata.type": "#Microsoft.Skills.Custom.ChatCompletionSkill",
"name": "genAI-prompt-skill",
"description": "GenAI Prompt skill for image verbalization",
"uri": "{{chatCompletionResourceUri}}",
"timeout": "PT1M",
"apiKey": "{{chatCompletionKey}}",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "systemMessage",
"source": "='You are tasked with generating concise, accurate descriptions of images, figures, diagrams, or charts in documents. The goal is to capture the key information and meaning conveyed by the image without including extraneous details like style, colors, visual aesthetics, or size.\n\nInstructions:\nContent Focus: Describe the core content and relationships depicted in the image.\n\nFor diagrams, specify the main elements and how they are connected or interact.\nFor charts, highlight key data points, trends, comparisons, or conclusions.\nFor figures or technical illustrations, identify the components and their significance.\nClarity & Precision: Use concise language to ensure clarity and technical accuracy. Avoid subjective or interpretive statements.\n\nAvoid Visual Descriptors: Exclude details about:\n\nColors, shading, and visual styles.\nImage size, layout, or decorative elements.\nFonts, borders, and stylistic embellishments.\nContext: If relevant, relate the image to the broader content of the technical document or the topic it supports.\n\nExample Descriptions:\nDiagram: \"A flowchart showing the four stages of a machine learning pipeline: data collection, preprocessing, model training, and evaluation, with arrows indicating the sequential flow of tasks.\"\n\nChart: \"A bar chart comparing the performance of four algorithms on three datasets, showing that Algorithm A consistently outperforms the others on Dataset 1.\"\n\nFigure: \"A labeled diagram illustrating the components of a transformer model, including the encoder, decoder, self-attention mechanism, and feedforward layers.\"'"
},
{
"name": "userMessage",
"source": "='Please describe this image.'"
},
{
"name": "image",
"source": "/document/normalized_images/*/data"
}
],
"outputs": [
{
"name": "response",
"targetName": "verbalizedImage"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "verblized-image-embedding-skill",
"description": "Embedding skill for verbalized images",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "text",
"source": "/document/normalized_images/*/verbalizedImage",
"inputs": []
}
],
"outputs": [
{
"name": "embedding",
"targetName": "verbalizedImage_vector"
}
],
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"dimensions": 3072,
"modelName": "text-embedding-3-large"
},
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "shaper-skill",
"description": "Shaper skill to reshape the data to fit the index schema"
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "normalized_images",
"source": "/document/normalized_images/*",
"inputs": []
},
{
"name": "imagePath",
"source": "='{{imageProjectionContainer}}/'+$(/document/normalized_images/*/imagePath)",
"inputs": []
},
{
"name": "location_metadata",
"sourceContext": "/document/normalized_images/*",
"inputs": [
{
"name": "page_number",
"source": "/document/normalized_images/*/pageNumber"
},
{
"name": "bounding_polygons",
"source": "/document/normalized_images/*/boundingPolygon"
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "new_normalized_images"
}
]
}
],
"indexProjections": {
"selectors": [
{
"targetIndexName": "{{index}}",
"parentKeyFieldName": "text_document_id",
"sourceContext": "/document/pages/*",
"mappings": [
{
"name": "content_embedding",
"source": "/document/pages/*/text_vector"
},
{
"name": "content_text",
"source": "/document/pages/*"
},
{
"name": "document_title",
"source": "/document/document_title"
}
]
},
{
"targetIndexName": "{{index}}",
"parentKeyFieldName": "image_document_id",
"sourceContext": "/document/normalized_images/*",
"mappings": [
{
"name": "content_text",
"source": "/document/normalized_images/*/verbalizedImage"
},
{
"name": "content_embedding",
"source": "/document/normalized_images/*/verbalizedImage_vector"
},
{
"name": "content_path",
"source": "/document/normalized_images/*/new_normalized_images/imagePath"
},
{
"name": "document_title",
"source": "/document/document_title"
},
{
"name": "locationMetadata",
"source": "/document/normalized_images/*/new_normalized_images/location_metadata"
}
]
}
],
"parameters": {
"projectionMode": "skipIndexingParentDocuments"
}
},
"knowledgeStore": {
"storageConnectionString": "{{storageConnection}}",
"projections": [
{
"files": [
{
"storageContainer": "{{imageProjectionContainer}}",
"source": "/document/normalized_images/*"
}
]
}
]
}
}
Этот набор навыков извлекает текст и изображения, векторизирует и формирует метаданные изображения для проекции в индекс.
Основные моменты:
Поле
content_textзаполняется двумя способами:Из текста документа, извлеченного с помощью навыка извлечения документов и фрагментированного с помощью навыка разделения текста
На основе содержимого изображения с помощью навыка GenAI Prompt, который генерирует описательные подписи для каждого нормализованного изображения.
Поле
content_embeddingсодержит встраивания размерностью 3072 для текста страницы и словесных описаний изображений. Они создаются с помощью модели text-embedding-3-large из Azure OpenAI.content_pathсодержит относительный путь к файлу изображения в контейнере проекции образа. Это поле создается только для изображений, извлеченных из PDF-файлов, еслиimageActionзадано значениеgenerateNormalizedImages, и может быть сопоставлено из обогащенного документа из исходного поля/document/normalized_images/*/imagePath.
Создание и запуск индексатора
Создать индексатор позволяет создать индексатор в вашей службе поиска. Индексатор подключается к источнику данных, загружает данные, запускает набор умений и индексирует обогащенные данные.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"dataSourceName": "doc-extraction-image-verbalization-ds",
"targetIndexName": "doc-extraction-image-verbalization-index",
"skillsetName": "doc-extraction-image-verbalization-skillset",
"parameters": {
"maxFailedItems": -1,
"maxFailedItemsPerBatch": 0,
"batchSize": 1,
"configuration": {
"allowSkillsetToReadFileData": true
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "document_title"
}
],
"outputFieldMappings": []
}
Выполнение запросов
Вы можете начать поиск сразу после загрузки первого документа.
### Query the index
POST {{baseUrl}}/indexes/doc-extraction-image-verbalization-index/docs/search?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Отправьте запрос. Это неопределенный полнотекстовый поисковый запрос, который возвращает все поля, помеченные как извлекаемые в индексе, а также число документов. Результат должен выглядеть следующим образом:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 712ca003-9493-40f8-a15e-cf719734a805
elapsed-time: 198
Date: Wed, 30 Apr 2025 23:20:53 GMT
Connection: close
{
"@odata.count": 100,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes/doc-extraction-image-verbalization-index/docs/search?api-version=2025-05-01-preview "
}
В ответе возвращаются 100 документов.
Для фильтров можно также использовать логические операторы (и, не) и операторы сравнения (eq, ne, lt, ge, le). Сравнение строк чувствительно к регистру. Дополнительные сведения и примеры см. в примерах простых поисковых запросов.
Замечание
Параметр $filter работает только в полях, которые были помечены фильтруемыми во время создания индекса.
Ниже приведены некоторые примеры других запросов:
### Query for only images
POST {{baseUrl}}/indexes/doc-extraction-image-verbalization-index/docs/search?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true,
"filter": "image_document_id ne null"
}
### Query for text or images with content related to energy, returning the id, parent document, and text (extracted text for text chunks and verbalized image text for images), and the content path where the image is saved in the knowledge store (only populated for images)
POST {{baseUrl}}/indexes/doc-extraction-image-verbalization-index/docs/search?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "energy",
"count": true,
"select": "content_id, document_title, content_text, content_path"
}
Сброс и повторный запуск
Индексаторы можно сбросить, чтобы очистить индикатор выполнения, что позволяет выполнить полный повторный запуск. Следующие запросы POST предназначены для сброса, за которым следует повторно запустить.
### Reset the indexer
POST {{baseUrl}}/indexers/doc-extraction-image-verbalization-indexer/reset?api-version=2025-05-01-preview HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/doc-extraction-image-verbalization-indexer/run?api-version=2025-05-01-preview HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/doc-extraction-image-verbalization-indexer/status?api-version=2025-05-01-preview HTTP/1.1
api-key: {{apiKey}}
Очистите ресурсы
Если вы работаете в рамках своей подписки, после завершения проекта целесообразно удалить ресурсы, которые вам больше не нужны. Оставленные без присмотра ресурсы могут стоить вам денег. Вы можете удалить ресурсы по отдельности или удалить группу ресурсов, чтобы удалить весь набор ресурсов.
Вы можете использовать портал Azure для удаления индексов, индексаторов и источников данных.
См. также
Теперь, когда вы знакомы с примером реализации сценария многомодального индексирования, ознакомьтесь со следующими сведениями: