Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Диспетчер кластерных ресурсов Service Fabric — это центральная служба, которая работает в кластере. Он управляет требуемым состоянием служб в кластере, особенно в отношении потребления ресурсов и любых правил размещения.
Чтобы управлять ресурсами в кластере, диспетчер кластерных ресурсов Service Fabric должен иметь несколько элементов информации:
- Какие службы в настоящее время существуют
- Текущее использование ресурсов каждой службы (или по умолчанию)
- Оставшаяся емкость кластера
- Емкость узлов в кластере
- Объем ресурсов, потребляемых на каждом узле
Потребление ресурсов данной службы может меняться с течением времени, и службы обычно заботятся о нескольких типах ресурсов. В разных службах могут измеряться как реальные физические, так и физические ресурсы. Службы могут отслеживать физические метрики, такие как потребление памяти и диска. Чаще всего службы могут заботиться о логических метриках, таких как WorkQueueDepth или TotalRequests. Логические и физические метрики можно использовать в одном кластере. Метрики могут быть общими для многих служб или быть характерными для конкретной службы.
Другие вопросы
Владельцы и операторы кластера могут отличаться от авторов служб и приложений, или как минимум одни и те же люди, одетые в разные шляпы. При разработке приложения вы знаете несколько вещей о том, что требуется. У вас есть оценка ресурсов, которые будут использоваться, и способ развертывания различных служб. Например, веб-уровень должен выполняться на узлах, доступных из Интернета, в то время как службы базы данных не должны. В качестве другого примера веб-службы, вероятно, ограничены ЦП и сетью, а службы уровня данных больше заботятся о потреблении памяти и дисков. Однако пользователь, обрабатывающий инцидент с динамическим сайтом для этой службы в рабочей среде, или который управляет обновлением службы, имеет другое задание для выполнения и требует различных средств.
Кластер и службы являются динамическими:
- Количество узлов в кластере может увеличиваться и уменьшаться
- Узлы разных размеров и типов могут прийти и уйти
- Службы можно создавать, удалять и изменять требуемые правила выделения ресурсов и размещения.
- Обновления или другие операции управления могут происходить в кластере на уровне приложений и инфраструктуры.
- Ошибки могут произойти в любое время.
Компоненты диспетчера кластерных ресурсов и поток данных
Диспетчер кластерных ресурсов должен отслеживать требования каждой службы и потребление ресурсов для каждого объекта службы в этих службах. Диспетчер кластерных ресурсов состоит из двух концептуальных частей: агентов, которые работают на каждом узле, и отказоустойчивого сервиса. Агенты на каждом узле отслеживают отчеты о загрузке из служб, агрегируют их и периодически сообщают о них. Служба Cluster Resource Manager объединяет все сведения из локальных агентов и реагирует на ее текущую конфигурацию.
Рассмотрим следующую схему:
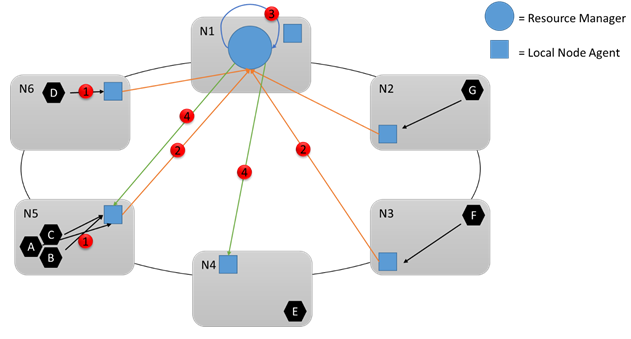
Во время выполнения есть много изменений, которые могут произойти. Например, предположим, что объём потребляемых ресурсов некоторыми службами изменяется, некоторые службы выходят из строя, а некоторые узлы присоединяются к кластеру и покидают его. Все изменения на узле агрегируются и периодически отправляются в службу Cluster Resource Manager (1,2), где они агрегируются повторно, анализируются и хранятся. Каждые несколько секунд служба проверяет изменения и определяет, необходимы ли какие-либо действия (3). Например, система может обнаружить, что в кластер были добавлены некоторые пустые узлы. В результате он решает переместить некоторые службы на эти узлы. Диспетчер кластерных ресурсов также может заметить, что определенный узел перегружен или что определенные службы завершились сбоем или были удалены, освобождая ресурсы в другом месте.
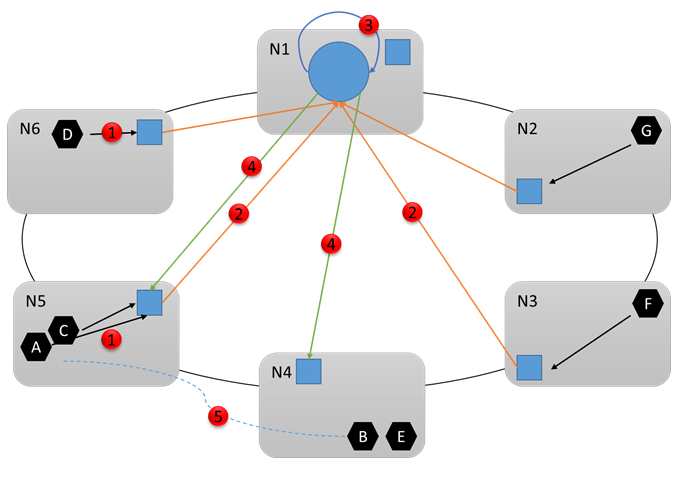
Давайте рассмотрим следующую схему и посмотрим, что произойдет дальше. Предположим, что диспетчер кластерных ресурсов определяет необходимые изменения. Он координирует работу с другими службами системы (в частности с диспетчером переключения при отказе), чтобы внести необходимые изменения. Затем необходимые команды отправляются на соответствующие узлы (4). Например, предположим, что Resource Manager заметил, что Node5 был перегружен, и поэтому решил переместить службу B из Node5 в Node4. В конце перенастройки (5) кластер выглядит следующим образом:
Дальнейшие действия
- Диспетчер кластерных ресурсов имеет множество вариантов описания кластера. Дополнительные сведения о них см. в этой статье по описанию кластера Service Fabric
- Основные обязанности Диспетчера кластерных ресурсов — перебалансировать кластер и применить правила размещения. Дополнительные сведения о настройке этих поведений см. в статье о балансировке кластера Service Fabric