Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Функция Диспетчера кластерных ресурсов Azure Service Fabric предоставляет несколько механизмов описания кластера:
- Домены сбоя
- Обновление доменов
- Свойства узла
- Емкости узлов
Во время выполнения Диспетчер кластерных ресурсов использует эти сведения, чтобы обеспечить высокий уровень доступности служб, работающих в кластере. При применении этих важных правил он также пытается оптимизировать потребление ресурсов в кластере.
Домены сбоя
Домен сбоя — это любая область согласованного сбоя. Один компьютер — это домен сбоя. Он может завершиться сбоем самостоятельно по различным причинам, от сбоев питания до сбоев сетевого адаптера.
Компьютеры, подключенные к одному коммутатору Ethernet, находятся в одном домене сбоя. Машины, использующие один источник питания или находящиеся в одном месте.
Так как это естественно для перекрывающихся аппаратных сбоев, домены сбоя по сути являются иерархическими. Они представлены как URI в Service Fabric.
Важно правильно настроить домены сбоя, так как Service Fabric использует эту информацию для безопасного размещения служб. Service Fabric не хочет размещать службы таким образом, что потеря домена сбоя (вызвана сбоем некоторых компонентов) приводит к снижению службы.
В среде Azure Service Fabric использует сведения о домене сбоя, предоставляемые средой, для правильной настройки узлов в кластере от вашего имени. Для автономных экземпляров Service Fabric домены сбоя определяются во время настройки кластера.
Предупреждение
Важно, чтобы сведения о домене сбоя, предоставленные Service Fabric, были точными. Например, предположим, что узлы кластера Service Fabric работают на 10 виртуальных машинах, работающих на 5 физических узлах. В этом случае, даже если существует 10 виртуальных машин, существует только 5 разных доменов сбоя (верхнего уровня). Общий доступ к одному физическому узлу приводит к тому, что виртуальные машины будут совместно использовать один и тот же корневой домен сбоя, так как виртуальные машины испытывают сбой в случае сбоя физического узла.
Service Fabric ожидает, что домен сбоя узла не изменится. Другие механизмы обеспечения высокой доступности виртуальных машин, таких как ha-VM, могут привести к конфликтам с Service Fabric. Эти механизмы используют прозрачную миграцию виртуальных машин с одного узла на другой. Они не перенастраивают и не оповещают запущенный код на виртуальной машине. Таким образом, они не поддерживаются в качестве сред для запуска кластеров Service Fabric.
Service Fabric должна быть единственной технологией, реализующей высокую доступность. Такие механизмы, как миграция динамических виртуальных машин и сети SAN, не необходимы. Если эти механизмы используются в сочетании с Service Fabric, они снижают доступность приложений и надежность. Причина заключается в том, что они вводят дополнительную сложность, добавляют централизованные точки отказа и используют стратегии надежности и доступности, противоречащие стратегиям Service Fabric.
На следующем рисунке мы цветим все сущности, которые способствуют доменам сбоя и перечисляем все различные домены сбоя, которые приводят к этому результату. В этом примере у нас есть центры обработки данных ("DC"), стойки ("R") и блейды ("B"). Если каждый блейд содержит более одной виртуальной машины, возможно, появится еще один слой в иерархии домена отказоустойчивости.
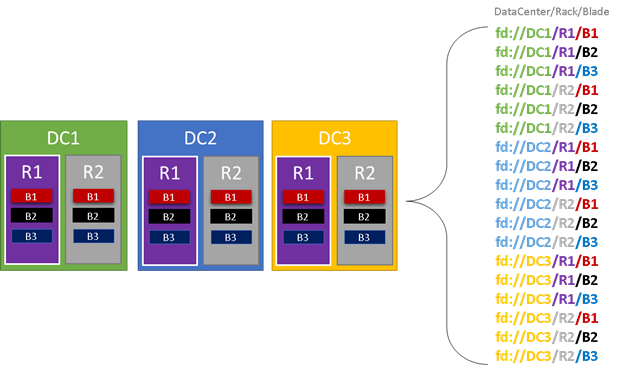
Во время выполнения Диспетчер кластерных ресурсов Service Fabric рассматривает домены сбоя в макетах кластера и планов. Реплики с отслеживанием состояния или экземпляры без отслеживания состояния для службы распределяются, поэтому они находятся в отдельных доменах сбоя. Распределение службы между доменами сбоя гарантирует, что доступность службы не скомпрометирована при сбое домена сбоя на любом уровне иерархии.
Диспетчер кластерных ресурсов не заботится о количестве слоев в иерархии домена сбоя. Он пытается убедиться, что потеря любой части иерархии не влияет на службы, выполняемые в ней.
Лучше всего, если одинаковое количество узлов находится на каждом уровне глубины в иерархии домена сбоя. Если "дерево" доменов сбоя не сбалансировано в кластере, то для диспетчера кластерных ресурсов сложнее определить лучшее распределение служб. Несбалансированные конфигурации области отказа означают, что потеря некоторых доменов влияет на доступность сервисов больше, чем других доменов. В результате диспетчер кластерных ресурсов разрывается между двумя целями:
- Он хочет использовать компьютеры в этом "тяжелом" домене, разместив службы на них.
- Он хочет разместить службы в других доменах, чтобы потеря домена не приводила к проблемам.
Как выглядят несбалансированные домены? На следующей схеме показаны два разных макета кластера. В первом примере узлы распределяются равномерно по доменам сбоя. Во втором примере один домен сбоя имеет гораздо больше узлов, чем другие домены сбоя.
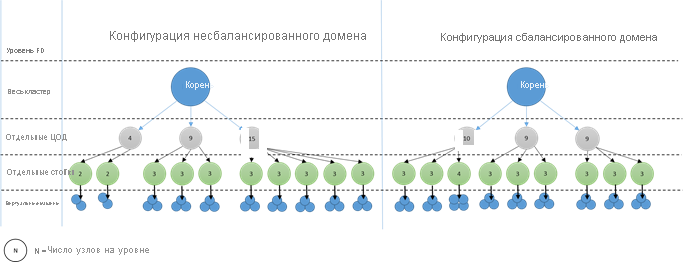
В Azure выбор домена сбоя, содержащего узел, управляется для вас. Но в зависимости от количества подготовленных узлов вы по-прежнему можете в конечном итоге в конечном итоге с доменами сбоя, имеющими больше узлов в них, чем в других.
Например, у вас есть пять доменов сбоя в кластере, но подготовьте семь узлов для типа узла (NodeType). В этом случае первые два домена сбоя в конечном итоге будут больше узлов. Если вы продолжите развертывать больше экземпляров NodeType всего с парой экземпляров, проблема ухудшится. По этой причине рекомендуется, чтобы количество узлов в каждом типе узлов было кратным числом доменов сбоя.
Обновление доменов
Домены обновления — это еще одна функция, которая помогает Диспетчеру кластеров Service Fabric понять макет кластера. Домены обновления определяют наборы узлов, обновляемых одновременно. Домены обновления помогают Менеджеру ресурсов кластера в понимании и организации операций управления, таких как обновления.
Домены обновления очень похожи на домены сбоя, но с несколькими ключевыми различиями. Во-первых, области скоординированных сбоев оборудования определяют домены сбоя. Домены обновления, с другой стороны, определяются политикой. Вы можете решить, сколько вы хотите, вместо того, чтобы разрешить среде диктовать число. У вас может быть столько доменов для обновлений, сколько и узлов. Еще одно различие между доменами сбоя и доменами обновления заключается в том, что домены обновления не являются иерархическими. Вместо этого они больше похожи на простой тег.
На следующей схеме показаны три домена обновления, распределённые по трем доменам сбоя. Он также показывает одно из возможных размещений для трех разных реплик состояния службы, где каждая из них оказывается в разных зонах отказа и обновления. Это размещение позволяет потерять домен сбоя в процессе обновления службы и при этом сохранить одну копию кода и данных.
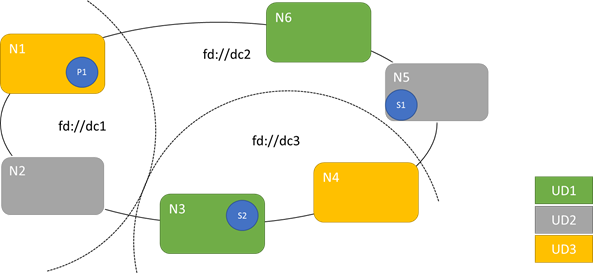
Есть плюсы и минусы в большом количестве обновляемых доменов. Дополнительные домены обновления означают, что каждый шаг обновления более детализирован и влияет на меньшее количество узлов или служб. Меньше служб должно перемещаться за раз, вводя меньше оттока в систему. Это, как правило, повышает надежность, поскольку меньшая часть службы подвергается какой-либо проблеме, возникающей во время обновления. Дополнительные домены обновления также означают, что вам нужен менее доступный буфер на других узлах для обработки влияния обновления.
Например, если у вас есть пять доменов для обновления, узлы в каждом из них обрабатывают примерно 20 процентов трафика. Если вам нужно отключить этот домен обновления для проведения модернизации, нагрузка обычно должна быть перенаправлена. Так как у вас есть четыре оставшихся доменов обновления, каждый из них должен помещать около 25 процентов всего трафика. Большее количество доменов обновления означает, что в узлах кластера требуется меньше буфера.
Рассмотрите, если вместо этого у вас есть 10 доменов обновления. В этом случае каждая область обновления будет обрабатывать только около 10 процентов общего трафика. При выполнении действий по обновлению кластера каждому домену потребуется место только для 11 процентов общего трафика. Больше доменов обновлений обычно позволяют запускать узлы с более высокой загрузкой, поскольку требуется меньше зарезервированной мощности. То же самое относится к областям отказов.
Недостатком множества доменов обновления является то, что процесс обновления занимает больше времени. Service Fabric ждет короткое время после завершения обновления домена и выполняет проверки, прежде чем начать обновление следующего. Эти задержки позволяют обнаруживать проблемы, введенные обновлением до продолжения обновления. Компромисс является приемлемым, так как он предотвращает негативное влияние изменений на слишком большую часть службы за один раз.
Недостаточное количество доменов обновления вызывает множество негативных побочных эффектов. Пока каждый домен обновления отключен и обновляется, большая часть общей мощности вашей системы недоступна. Например, если у вас есть только три домена обновления, вы временно отключаете около одной трети общей емкости службы или кластера за раз. Иметь одновременно выключенными так много ваших служб нежелательно, потому что для обработки рабочей нагрузки требуется достаточно ресурсов в оставшейся части кластера. Сохранение этого буфера означает, что во время нормальной работы эти узлы менее загружены, чем они будут в противном случае. Это увеличивает затраты на работу вашего сервиса.
Нет реального ограничения на общее количество доменов сбоя или обновления в среде или ограничений на их перекрытие. Но существуют распространенные шаблоны:
- Домены сбоя и домены обновления в соотношении 1:1
- Один домен обновления на узел (физический или виртуальный экземпляр ОС)
- Модель "полосатая" или "матрица", в которой домены сбоя и домены обновления образуют матрицу с компьютерами, обычно расположенными по диагоналям.
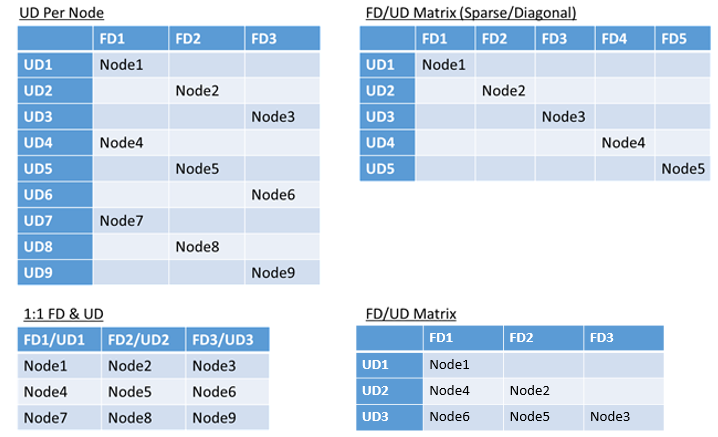
Нет лучшего ответа на выбор макета. У каждого есть плюсы и минусы. Например, модель 1FD:1UD проста для настройки. Модель одного домена обновления для каждой модели узла больше всего похожа на то, к чему привыкли люди. При обновлении каждый узел обновляется независимо. Это похоже на то, как небольшие наборы компьютеров были обновлены вручную в прошлом.
Наиболее распространённая модель — матрица FD/UD, где домены отказов и домены обновления образуют таблицу, и узлы размещаются, начиная с диагонали. Это модель, используемая по умолчанию в кластерах Service Fabric в Azure. Для кластеров с большим количеством узлов все выглядит как плотная матрица.
Замечание
Кластеры Service Fabric, размещенные в Azure, не поддерживают изменение стратегии по умолчанию. Только автономные кластеры предлагают настройку.
Ограничения домена сбоя и обновления и результирующее поведение
Подход по умолчанию
По умолчанию Диспетчер кластерных ресурсов сохраняет баланс служб между доменами сбоя и обновления. Это моделировается как ограничение. Ограничение для доменов отказа и обновления гласит: "Для заданного раздела службы никогда не должно быть разницы больше одного в количестве объектов службы (экземпляров беспредметных служб или реплик служб с состоянием) между любыми двумя доменами на одном уровне иерархии".
Предположим, что это ограничение обеспечивает "максимальную разницу". Ограничение для доменов отказа и обновления предотвращает определенные перемещения или конфигурации, которые нарушают правило.
Например, предположим, что у нас есть кластер с шестью узлами, настроенными с пятью доменами сбоя и пятью доменами обновления.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N3 | ||||
| UD3 | N4 | ||||
| UD4 | N5 |
Теперь предположим, что мы создадим службу с значением TargetReplicaSetSize (или для службы без отслеживания состояния , InstanceCount) из пяти. Реплики приземлились на N1-N5. На самом деле N6 никогда не используется, вне зависимости от того, сколько подобных служб вы создаете. Но почему? Давайте рассмотрим разницу между текущим макетом и тем, что произойдет, если выбран N6.
Вот макет, который мы получили, и общее количество реплик для каждого домена сбоя и обновления:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | 1 | ||||
| UD3 | Р4 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Этот макет сбалансирован с точки зрения узлов на домен сбоя и домен обновления. Она также сбалансирована с точки зрения количества реплик в каждом домене сбоя и в каждом домене обновления. Каждый домен имеет одинаковое количество узлов и одинаковое количество реплик.
Теперь давайте рассмотрим, что произойдет, если бы мы использовали N6 вместо N2. Как будут распространяться реплики?
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R5 | 1 | ||||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | Р4 | 1 | ||||
| FDTotal | 2 | 0 | 1 | 1 | 1 | - |
Этот макет нарушает наше определение "максимальной разницы" для ограничения домена сбоя. FD0 имеет две реплики, в то время как FD1 имеет ноль. Разница между FD0 и FD1 составляет в общей сложности два, что больше максимальной разницы в одном. Поскольку ограничение нарушено, Диспетчер кластерных ресурсов не разрешает это соглашение.
Аналогичным образом, если мы выбрали N2 и N6 (вместо N1 и N2), мы получим:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | 0 | |||||
| UD1 | R5 | R1 | 2 | |||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | Р4 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Этот распределение сбалансировано с точки зрения отказоустойчивости. Но теперь это нарушает ограничение домена обновления, так как UD0 имеет ноль реплик и UD1 имеет два. Этот макет также недопустим и не будет выбран диспетчером кластерных ресурсов.
Такой подход к распределению реплик с отслеживанием состояния или экземпляров без отслеживания состояния обеспечивает максимально возможную отказоустойчивость. Если один домен выходит из строя, минимальное количество реплик или экземпляров будет потеряно.
С другой стороны, этот подход может быть слишком строгим и не позволяет кластеру использовать все ресурсы. Для определенных конфигураций кластера некоторые узлы нельзя использовать. Это может привести к тому, что Service Fabric не помещать службы, что приводит к предупреждению сообщений. В предыдущем примере некоторые узлы кластера не могут использоваться (N6 в примере). Даже если вы добавили узлы в этот кластер (N7-N10), реплики и экземпляры будут помещены только в N1–N5 из-за ограничений на домены сбоя и обновления.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | Н10 | |||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N9 | N5 |
Альтернативный подход
Cluster Resource Manager поддерживает другой вариант ограничения для зон отказа и обновления. Он позволяет размещать, гарантируя минимальный уровень безопасности. Альтернативное ограничение можно указать следующим образом: "Для заданной секции службы распределение реплик между доменами должно гарантировать, что секция не страдает потерей кворума". Предположим, что это ограничение обеспечивает гарантию безопасности кворума.
Замечание
Для службы с отслеживанием состояния мы определяем потерю кворума в ситуации, когда большинство реплик партиций одновременно вышли из строя. Например, если TargetReplicaSetSize равно пяти, набор из трех реплик представляет кворум. Аналогичным образом, если TargetReplicaSetSize составляет шесть, для кворума необходимы четыре реплики. В обоих случаях не более двух реплик могут выйти из строя одновременно, если раздел может продолжать функционировать нормально.
Для службы без состояния не существует такого понятия, как потеря кворума. Службы без отслеживания состояния продолжают работать обычно, даже если большинство экземпляров одновременно идут вниз. Поэтому мы сосредоточимся на состояние-ориентированных службах в дальнейшем изложении статьи.
Давайте вернемся к предыдущему примеру. При использовании "кворум-безопасной" версии ограничения все три макета были бы допустимы. Даже если FD0 выйдет из строя во втором макете или UD1 выйдет из строя в третьем макете, раздел всё равно будет иметь кворум. (Большинство копий остаются в рабочем состоянии.) При использовании этой версии ограничения N6 можно использовать почти всегда.
Подход "безопасного для кворума" обеспечивает большую гибкость, чем подход "максимальной разницы". Причина заключается в том, что проще найти дистрибутивы реплик, допустимые практически в любой топологии кластера. Однако этот подход не может гарантировать лучшие характеристики отказоустойчивости, так как некоторые ошибки хуже других.
В худшем случае большинство реплик может быть потеряно сбоем одного домена и одной дополнительной реплики. Например, вместо трех сбоев, необходимых для потери кворума с пятью репликами или экземплярами, теперь можно потерять большинство кворума с двумя сбоями.
Адаптивный подход
Поскольку оба подхода имеют сильные и слабые стороны, мы представили адаптивный подход, который объединяет эти две стратегии.
Замечание
Это поведение по умолчанию, начиная с Service Fabric версии 6.2.
Адаптивный подход использует логику "максимальной разницы" по умолчанию и переключается на "безопасную" логику кворума только при необходимости. Диспетчер кластерных ресурсов автоматически определяет, какая стратегия необходима, глядя на настройку кластера и служб.
Диспетчер кластерных ресурсов должен использовать логику, основанную на кворуме для службы, если оба эти условия выполняются.
- TargetReplicaSetSize для службы равномерно делится по количеству доменов сбоя и количеству доменов обновления.
- Число узлов меньше или равно количеству доменов сбоя, умноженных на число доменов обновления.
Имейте в виду, что Диспетчер кластерных ресурсов будет использовать этот подход как для служб без отслеживания состояния, так и для служб без отслеживания состояния, несмотря на то, что потеря кворума не относится к службам без отслеживания состояния.
Давайте вернемся к предыдущему примеру и предположим, что кластер теперь имеет восемь узлов. Кластер по-прежнему настроен с пятью доменами сбоя и пятью доменами обновления, а значение TargetReplicaSetSize службы, размещенной в этом кластере, остается пять.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N5 |
Так как все необходимые условия выполнены, Диспетчер кластерных ресурсов будет использовать логику на основе кворума при распределении службы. Это позволяет использовать N6-N8. Возможное распределение служб в этом случае может выглядеть следующим образом:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | Р4 | 2 | |||
| UD3 | 0 | |||||
| UD4 | R5 | 1 | ||||
| FDTotal | 2 | 1 | 1 | 0 | 1 | - |
Если значение TargetReplicaSetSize службы уменьшается до четырех (например), диспетчер кластерных ресурсов заметит это изменение. Он возобновляет использование логики "максимальной разницы", так как TargetReplicaSetSize больше не делится по количеству доменов сбоя и доменов обновления. В результате некоторые движения реплик будут выполняться для распределения оставшихся четырех реплик на узлах N1-N5. Таким образом не нарушается версия с «максимальной разницей» в логике домена сбоев и обновления.
В предыдущем макете, если значение TargetReplicaSetSize равно 5, а N1 удаляется из кластера, число доменов обновления становится равным четырем. Опять же, Диспетчер кластерных ресурсов начинает использовать логику "максимальной разницы", поскольку количество доменов обновления больше не делится на равные части в значение TargetReplicaSetSize службы. В результате реплика R1 при повторном построении должна разместиться на N4, чтобы ограничение на домен отказов и обновлений не нарушалось.
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | Не применимо | Не применимо | Не применимо | Не применимо | Не применимо | Не применимо |
| UD1 | R2 | 1 | ||||
| UD2 | R3 | Р4 | 2 | |||
| UD3 | R1 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Настройка доменов сбоя и обновления
В развертываниях Service Fabric, размещенных в Azure, домены сбоя и домены обновления определяются автоматически. Service Fabric выбирает и использует сведения о среде из Azure.
Если вы создаете собственный кластер (или хотите запустить определенную топологию в разработке), вы можете предоставить домен сбоя и сведения о домене обновления самостоятельно. В этом примере мы определим локальный кластер разработки с девятью узлами, охватывающим три центра обработки данных (каждый из которых содержит три стойки). Этот кластер также имеет три домена обновления, распределенные между этими тремя центрами обработки данных. Ниже приведен пример конфигурации в ClusterManifest.xml:
<Infrastructure>
<!-- IsScaleMin indicates that this cluster runs on one box/one single server -->
<WindowsServer IsScaleMin="true">
<NodeList>
<Node NodeName="Node01" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType01" FaultDomain="fd:/DC01/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node02" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType02" FaultDomain="fd:/DC01/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node03" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType03" FaultDomain="fd:/DC01/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node04" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType04" FaultDomain="fd:/DC02/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node05" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType05" FaultDomain="fd:/DC02/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node06" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType06" FaultDomain="fd:/DC02/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node07" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType07" FaultDomain="fd:/DC03/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node08" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType08" FaultDomain="fd:/DC03/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node09" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType09" FaultDomain="fd:/DC03/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
</NodeList>
</WindowsServer>
</Infrastructure>
В этом примере для автономных развертываний используется ClusterConfig.json:
"nodes": [
{
"nodeName": "vm1",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm2",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm3",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm4",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm5",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm6",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm7",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm8",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm9",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD3"
}
],
Замечание
При определении кластеров с помощью Azure Resource Manager Azure назначает домены сбоя и домены обновления. Поэтому определение типов узлов и масштабируемых наборов виртуальных машин в шаблоне Azure Resource Manager не содержит сведения о домене сбоя или домене обновления.
Свойства узла и ограничения размещения
Иногда (на самом деле большую часть времени) необходимо убедиться, что определенные рабочие нагрузки выполняются только на определенных типах узлов в кластере. Например, для некоторых рабочих нагрузок может потребоваться gpu или SSD, а другие — нет.
Отличный пример нацеливания оборудования на конкретные рабочие нагрузки — это n-уровневая архитектура. Некоторые компьютеры служат интерфейсной или обслуживающей стороной API приложения и предоставляются клиентам или Интернету. Разные компьютеры, часто с различными аппаратными ресурсами, обрабатывают работу уровней вычислений или хранилища. Обычно они не предоставляются клиентам или Интернету напрямую.
Service Fabric ожидает, что в некоторых случаях для определенных конфигураций оборудования может потребоваться выполнение определенных рабочих нагрузок. Рассмотрим пример.
- Существующее n-уровневое приложение было "снято и перемещено" в среду Service Fabric.
- Рабочая нагрузка должна выполняться на определенном оборудовании для обеспечения производительности, масштабирования или изоляции безопасности.
- Рабочая нагрузка должна быть изолирована от других рабочих нагрузок по соображениям политики или потребления ресурсов.
Для поддержки этих типов конфигураций Service Fabric включает теги, которые можно применить к узлам. Эти теги называются свойствами узла. Ограничения размещения — это условия, связанные с отдельными службами, которые выбираются для одного или нескольких свойств узла. Ограничения размещения определяют, где должны запускаться службы. Набор ограничений расширяемый. Любая пара "ключ-значение" может работать.
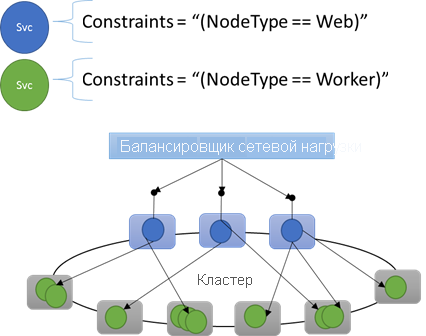
Встроенные свойства узла
Service Fabric определяет некоторые свойства узла по умолчанию, которые можно использовать автоматически, чтобы их не нужно определять. Свойства по умолчанию, определенные на каждом узле, — NodeType и NodeName.
Например, можно написать ограничение размещения как "(NodeType == NodeType03)".
NodeType — это часто используемое свойство. Полезно, так как он полностью соответствует типу машины. Каждый тип компьютера соответствует типу рабочей нагрузки в традиционном n-уровневом приложении.
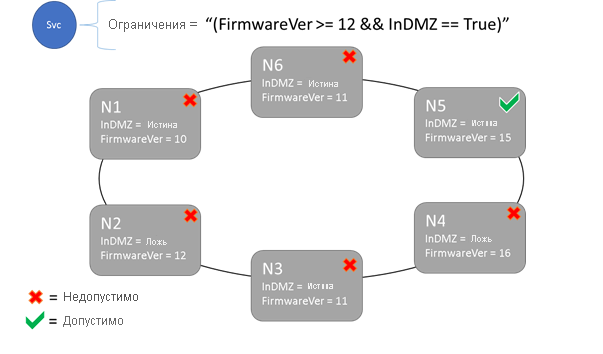
Ограничения размещения и синтаксис свойств узла
Значение, указанное в свойстве узла, может быть строкой, bool или целым со знаком. Заявление в службе называется ограничением размещения, потому что оно ограничивает, где служба может работать в кластере. Ограничение может быть любым логическим выражением, которое применяется к свойствам узла в кластере. Допустимые селекторы в этих булевых выражениях:
Проверка условий для написания определённых утверждений:
Заявление Синтаксис "равно" "==" "не равно" "!=" больше чем > "больше или равно" >= "меньше" < "меньше или равно" "<=" Булевы выражения для группировки и логических операций:
Заявление Синтаксис "и" "&&" "или" "||" "не" "!" Сгруппировать в единое выражение ()
Ниже приведены некоторые примеры базовых ограничений:
"Value >= 5""NodeColor != green""((OneProperty < 100) || ((AnotherProperty == false) && (OneProperty >= 100)))"
Только узлы, в которых общая инструкция ограничения размещения оценивается как True, может содержать службу, размещенную на ней. Узлы, у которых нет свойства, не соответствуют никаким ограничениям размещения, содержащим это свойство.
Предположим, что для типа узла в ClusterManifest.xmlопределены следующие свойства узла:
<NodeType Name="NodeType01">
<PlacementProperties>
<Property Name="HasSSD" Value="true"/>
<Property Name="NodeColor" Value="green"/>
<Property Name="SomeProperty" Value="5"/>
</PlacementProperties>
</NodeType>
В следующем примере показаны свойства узлов, определенные с помощью ClusterConfig.json для автономных развертываний или Template.json для кластеров, размещенных в Azure.
Замечание
В шаблоне Azure Resource Manager тип узла обычно параметризуется. Он будет выглядеть как "[parameters('vmNodeType1Name')]", вместо NodeType01.
"nodeTypes": [
{
"name": "NodeType01",
"placementProperties": {
"HasSSD": "true",
"NodeColor": "green",
"SomeProperty": "5"
},
}
],
Вы можете создать ограничения размещения службы следующим образом:
FabricClient fabricClient = new FabricClient();
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
serviceDescription.PlacementConstraints = "(HasSSD == true && SomeProperty >= 4)";
// Add other required ServiceDescription fields
//...
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceType -Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementConstraint "HasSSD == true && SomeProperty >= 4"
Если все узлы NodeType01 допустимы, можно также выбрать этот тип узла с ограничением "(NodeType == NodeType01)".
Ограничения размещения службы можно обновлять динамически во время выполнения. Если вам нужно, вы можете перемещать службу в кластере, добавлять и удалять требования и т. д. Service Fabric гарантирует, что служба остается доступной даже при внесении этих изменений.
StatefulServiceUpdateDescription updateDescription = new StatefulServiceUpdateDescription();
updateDescription.PlacementConstraints = "NodeType == NodeType01";
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
Update-ServiceFabricService -Stateful -ServiceName $serviceName -PlacementConstraints "NodeType == NodeType01"
Ограничения размещения задаются для каждого именованного экземпляра служебного процесса. Обновления всегда заменяют собой то, что было указано ранее.
Определение кластера определяет свойства узла. Для изменения свойств узла требуется обновление конфигурации кластера. Для обновления свойств узла требуется, чтобы каждый затронутый узел перезагрузится, чтобы сообщить о новых свойствах. Service Fabric управляет этими последовательными обновлениями.
Описание ресурсов кластера и управление ими
Одним из наиболее важных заданий любого оркестратора является управление потреблением ресурсов в кластере. Управление ресурсами кластера может означать несколько разных вещей.
Во-первых, это гарантирует, что компьютеры не перегружены. Это означает, что компьютеры не выполняют больше служб, чем они могут обрабатывать.
Во-вторых, существует балансировка и оптимизация, которые критически важны для эффективного выполнения служб. Экономически эффективные или высокопроизводительные предложения служб не могут позволить некоторым узлам быть горячими, а другие — холодными. Горячие узлы приводят к спорам за ресурсы и плохой производительности. Холодные узлы представляют нерасточимые ресурсы и увеличение затрат.
Service Fabric представляет ресурсы в виде метрик. Метрики — это любой логический или физический ресурс, который вы хотите описать в Service Fabric. Примерами метрик являются WorkQueueDepth или MemoryInMb. Сведения о физических ресурсах, которые Service Fabric может управлять на узлах, см. в разделе "Управление ресурсами". Сведения о метриках по умолчанию, используемых диспетчером кластерных ресурсов и настройке пользовательских метрик, см. в этой статье.
Метрики отличаются от ограничений размещения и свойств узлов. Свойства узла — это статические дескрипторы самих узлов. Метрики описывают ресурсы, которыми обладают узлы и которые потребляются службами, когда они работают на узле. Свойство узла может быть HasSSD и может иметь значение true или false. Объем свободного места на этом SSD и сколько используется службами, будет метрикой, такой как DriveSpaceInMb.
Как и для ограничений размещения и свойств узлов, Диспетчер кластерных ресурсов Service Fabric не понимает, какие имена метрик означают. Имена метрик — это просто строки. Рекомендуется объявлять единицы как часть имен метрик, создаваемых при их неоднозначности.
Вместимость
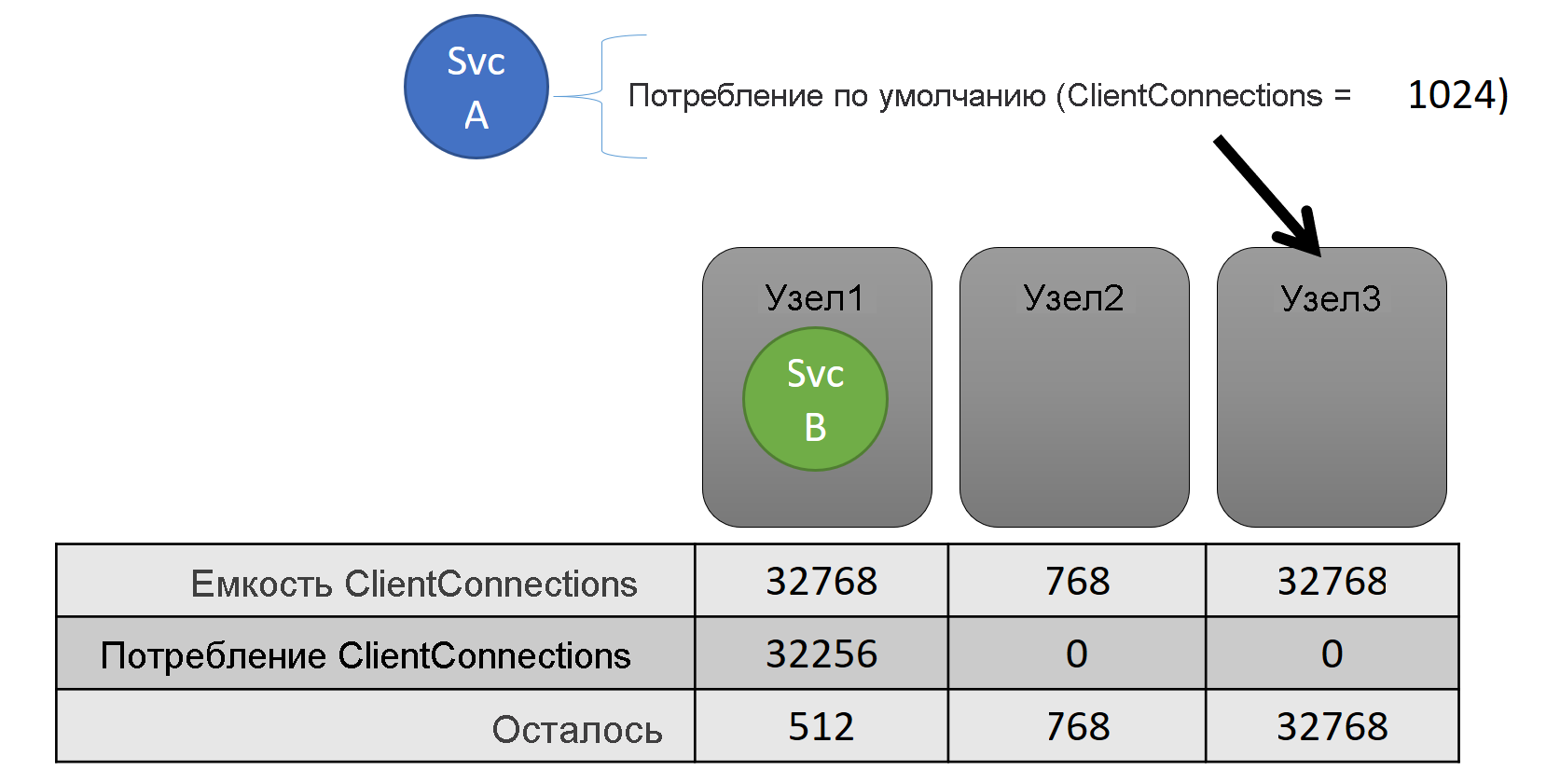
Если вы отключили всю балансировку ресурсов, Диспетчер кластерных ресурсов Service Fabric по-прежнему обеспечит, чтобы ни один узел не превышал свою емкость. Управление переполнением емкости возможно, если кластер не слишком заполнен и рабочая нагрузка не превышает возможности любого узла. Емкость — это другое ограничение , которое диспетчер кластерных ресурсов использует для понимания того, сколько ресурсов имеет узел. Оставшаяся емкость также отслеживается для кластера в целом.
Емкость и потребление на уровне обслуживания выражаются с точки зрения метрик. Например, метрика может быть "ClientConnections", а узел может иметь вместимость для "ClientConnections", составляющую 32 768. Другие узлы могут иметь другие ограничения. Служба, запущенная на этом узле, может сообщить, что в настоящее время используется 32 256 единиц метрики "ClientConnections".
Во время выполнения Диспетчер кластерных ресурсов отслеживает оставшуюся емкость в кластере и на узлах. Чтобы отслеживать емкость, Диспетчер кластерных ресурсов вычитает использование каждой службы из емкости узла, в которой выполняется служба. С помощью этой информации Диспетчер кластерных ресурсов может определить, где размещать или перемещать реплики, чтобы узлы не перебирали емкость.
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
ServiceLoadMetricDescription metric = new ServiceLoadMetricDescription();
metric.Name = "ClientConnections";
metric.PrimaryDefaultLoad = 1024;
metric.SecondaryDefaultLoad = 0;
metric.Weight = ServiceLoadMetricWeight.High;
serviceDescription.Metrics.Add(metric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ClientConnections,High,1024,0)
В манифесте кластера отображаются емкости. Ниже приведен пример для ClusterManifest.xml:
<NodeType Name="NodeType03">
<Capacities>
<Capacity Name="ClientConnections" Value="65536"/>
</Capacities>
</NodeType>
Ниже приведен пример емкостей, определенных с помощью ClusterConfig.json для автономных развертываний или Template.json для кластеров, размещенных в Azure:
"nodeTypes": [
{
"name": "NodeType03",
"capacities": {
"ClientConnections": "65536",
}
}
],
Загрузка службы часто меняется динамически. Предположим, что загрузка реплики ClientConnections изменилась с 1024 на 2048. Узел, на котором выполнялась программа, имел ограниченную емкость только 512 единиц для этой метрики. Теперь размещение реплики или экземпляра недопустимо, поскольку на этом узле недостаточно места. Диспетчер кластерных ресурсов должен снизить загрузку узла до его емкости. Это снижает нагрузку на узел, который превышает емкость, путем перемещения одной или нескольких реплик или экземпляров с этого узла на другие узлы.
Диспетчер кластерных ресурсов пытается свести к минимуму затраты на перемещение реплик. Дополнительные сведения о затратах на перемещение и о стратегиях и правилах перебалансирования.
Емкость кластера
Как диспетчер кластерных ресурсов Service Fabric предотвращает переполнение общего кластера? При динамической нагрузке не так много, что можно сделать. Службы могут иметь пик нагрузки независимо от действий, выполняемых диспетчером кластерных ресурсов. В результате ваш кластер с запасом мощности сегодня может оказаться недостаточно мощным, если завтра произойдет всплеск спроса.
Элементы управления в Диспетчере кластерных ресурсов помогают предотвратить проблемы. Первое, что можно сделать, заключается в предотвращении создания новых рабочих нагрузок, что приведет к тому, что кластер станет полным.
Предположим, что вы создаете службу без состояния, и с ней связана некоторая нагрузка. Служба следит за метрикой "DiskSpaceInMb". Служба будет использовать пять единиц "DiskSpaceInMb" для каждого экземпляра службы. Вы хотите создать три экземпляра службы. Это означает, что вам потребуется наличие 15 единиц "DiskSpaceInMb" в кластере, прежде чем вы сможете создать данные экземпляры служб.
Диспетчер кластерных ресурсов постоянно вычисляет емкость и потребление каждой метрики, чтобы определить оставшуюся емкость в кластере. Если недостаточно места, Диспетчер кластерных ресурсов отклоняет вызов для создания службы.
Поскольку требование заключается только в том, что 15 единиц будут доступны, вы можете выделить это пространство различными способами. Например, на 15 разных узлах может быть одна оставшаяся единица емкости или три оставшихся единицы емкости на пяти разных узлах. Если диспетчер кластерных ресурсов может перестроить ресурсы так, чтобы на трех узлах было доступно пять единиц, он размещает службу. Изменение порядка кластера обычно возможно, если кластер почти полный или существующие службы не могут быть консолидированы по какой-то причине.
Буфер узла и емкость переполнения
Если указана емкость узла для метрики, диспетчер кластерных ресурсов никогда не помещает или перемещает реплики на узел, если общая загрузка будет превышена указанной емкости узла. Иногда это может препятствовать размещению новых реплик или замене неудачных реплик, если кластер находится почти в полной емкости, а реплика с большой нагрузкой должна быть помещена, заменена или перемещена.
Чтобы обеспечить большую гибкость, можно указать либо буфер узла, либо емкость овербукинга. При указании буфера узла или возможности переполнения для метрики диспетчер кластерных ресурсов попытается разместить или переместить реплики таким образом, чтобы буфер или возможность переполнения сохранялся неиспользуемым, но позволяет использовать буфер или возможность переполнения при необходимости для действий, повышающих доступность сервисов, таких как:
- Новое размещение реплики или замена неудачных реплик
- Размещение во время обновления
- Устранение нарушений мягких и жестких ограничений
- Дефрагментация
Емкость буфера узла представляет зарезервированную часть ниже указанной емкости узла, а дополнительная вместимость представляет собой часть емкости, добавленную сверх указанной емкости узла. В обоих случаях Диспетчер кластерных ресурсов попытается освободить эту емкость.
Например, если узел имеет указанную емкость для метрики CpuUtilization 100 и процент буфера узла для этой метрики имеет значение 20%, общее и неуправляемое емкость будет 100 и 80 соответственно, а диспетчер кластерных ресурсов не будет размещать более 80 единиц нагрузки на узел во время обычных обстоятельств.
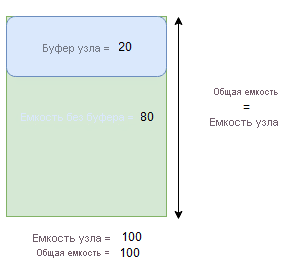
Буфер узла следует использовать, если требуется зарезервировать часть емкости узла, которая будет использоваться только для действий, повышающих доступность служб, упомянутых выше.
С другой стороны, если используется процент перебукинга узлов и задано значение 20%, то общая и нераспределенная емкости будут равны 120 и 100 соответственно.
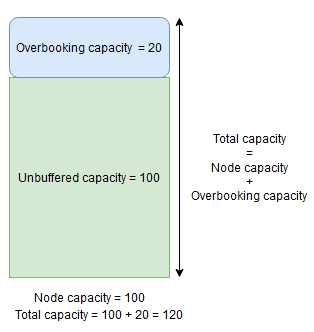
Избыточность ресурсов следует использовать, если требуется разрешить Диспетчеру кластерных ресурсов размещать реплики на узле, даже если общее использование ресурсов превысит емкость. Это можно использовать для предоставления дополнительной доступности для служб за счет производительности. Если используется перепродажа мест, логика пользовательского приложения должна иметь возможность работать с меньшим количеством физических ресурсов, чем обычно требуется.
Если заданы емкости буфера узла или перебронирования, диспетчер кластерных ресурсов не переместит или не разместит реплики, если общая нагрузка на целевой узел превысит общую емкость (емкость узла в случае буфера узла и емкость узла + емкость перебронирования в случае перебронирования).
Можно задать емкость перебукинга как бесконечную. В этом случае Диспетчер кластерных ресурсов попытается сохранить общую нагрузку на узел ниже указанной емкости узла, но допускается возможность существенно увеличить нагрузку на узел, что может привести к серьезному снижению производительности.
Метрика не может одновременно иметь буфер узла и емкость перебукинга, указанную для нее одновременно.
Ниже приведен пример указания буфера узла или переполнения емкостей в ClusterManifest.xml:
<Section Name="NodeBufferPercentage">
<Parameter Name="SomeMetric" Value="0.15" />
</Section>
<Section Name="NodeOverbookingPercentage">
<Parameter Name="SomeOtherMetric" Value="0.2" />
<Parameter Name=”MetricWithInfiniteOverbooking” Value=”-1.0” />
</Section>
Ниже приведен пример указания буфера узла или переполнения емкостей с помощью ClusterConfig.json для автономных развертываний или Template.json для кластеров, размещенных в Azure:
"fabricSettings": [
{
"name": "NodeBufferPercentage",
"parameters": [
{
"name": "SomeMetric",
"value": "0.15"
}
]
},
{
"name": "NodeOverbookingPercentage",
"parameters": [
{
"name": "SomeOtherMetric",
"value": "0.20"
},
{
"name": "MetricWithInfiniteOverbooking",
"value": "-1.0"
}
]
}
]
Дальнейшие шаги
- Сведения об архитектуре и потоке сведений в Диспетчере кластерных ресурсов см. в обзоре архитектуры Cluster Resource Manager.
- Определение метрик дефрагментации — один из способов консолидации нагрузки на узлы вместо ее распределения. Чтобы узнать, как настроить дефрагментацию, см. раздел "Дефрагментация метрик и нагрузки в Service Fabric".
- Начните с начала и получите общие сведения о Диспетчере кластерных ресурсов Service Fabric.
- Сведения о том, как диспетчер кластерных ресурсов управляет нагрузкой и балансирует нагрузку в кластере, см. в статье "Балансировка кластера Service Fabric".