Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Стратегия диспетчера ресурсов кластера Service Fabric по умолчанию для управления метриками нагрузки в кластере заключается в распределении нагрузки. Обеспечение равномерного использования узлов позволяет избежать горячих и холодных точек, которые приводят как к спору, так и к тратам ресурсов. Распределение рабочих нагрузок в кластере также является самым безопасным способом в плане устойчивости к сбоям, так как это гарантирует, что сбой не выводит из строя значительную часть заданной рабочей нагрузки.
Диспетчер кластерных ресурсов Service Fabric поддерживает другую стратегию управления нагрузкой, которая является дефрагментацией. Дефрагментация означает, что вместо того, чтобы попытаться распределить использование метрик в кластере, он консолидируется. Консолидация — это просто инверсия стратегии балансировки по умолчанию — вместо минимизации среднего стандартного отклонения нагрузки метрик, диспетчер кластерных ресурсов пытается его увеличить.
Когда следует использовать дефрагментацию
Распределение нагрузки в кластере использует некоторые ресурсы на каждом узле. Некоторые рабочие нагрузки создают службы, которые являются чрезвычайно большими и используют большую часть или весь узел. В таких случаях возможно, что при создании больших рабочих нагрузок может оказаться недостаточно места для их выполнения на любом из узлов. Большие рабочие нагрузки не являются проблемой в Service Fabric; В этих случаях Диспетчер кластерных ресурсов определяет, что он должен реорганизовать кластер, чтобы освободить место для этой большой рабочей нагрузки. В то же время данная рабочая нагрузка должна ждать планирования в кластере.
Если существует много служб и состояний для перемещения, может потребоваться много времени для размещения большой рабочей нагрузки в кластере. Это, скорее всего, если другие рабочие нагрузки в кластере также являются большими, поэтому требуется больше времени для реорганизации. Команда Service Fabric измеряла время создания в имитациях этого сценария. Мы обнаружили, что создание больших служб занимает гораздо больше времени, как только использование кластера превышает диапазон от 30% до 50%. Для обработки этого сценария мы ввели дефрагментацию в качестве стратегии балансировки. Мы обнаружили, что для больших рабочих нагрузок, в частности там, где время генерации было важным, дефрагментация в значительной степени помогла новым рабочим нагрузкам быть запланированными в кластере.
Вы можете настроить метрики дефрагментации, чтобы диспетчер кластерных ресурсов заранее пыталась сократить нагрузку служб на меньшее количество узлов. Это помогает обеспечить почти всегда место для крупных служб без реорганизации кластера. Не нужно переорганизовать кластер, что позволяет быстро создавать большие рабочие нагрузки.
Большинству людей не требуется дефрагментация. Службы обычно небольшие, поэтому не трудно найти место для них в кластере. Когда реорганизация возможна, она идет быстро, опять же, потому что большинство служб малы и могут быть быстро перемещены и параллельно. Однако, если у вас есть большие сервисы и их нужно быстро создать, то стратегия дефрагментации — это для вас. Далее мы обсудим компромиссы использования дефрагментации.
Компромиссы дефрагментации
Дефрагментация может увеличить значимость сбоев, так как на узлах, которые выходят из строя, запускается больше служб. Дефрагментация также может увеличить затраты, так как ресурсы в кластере должны храниться в резерве, ожидая создания больших рабочих нагрузок.
На следующей схеме представлено визуальное представление двух кластеров, одно из них дефрагментировано, а другое — нет.
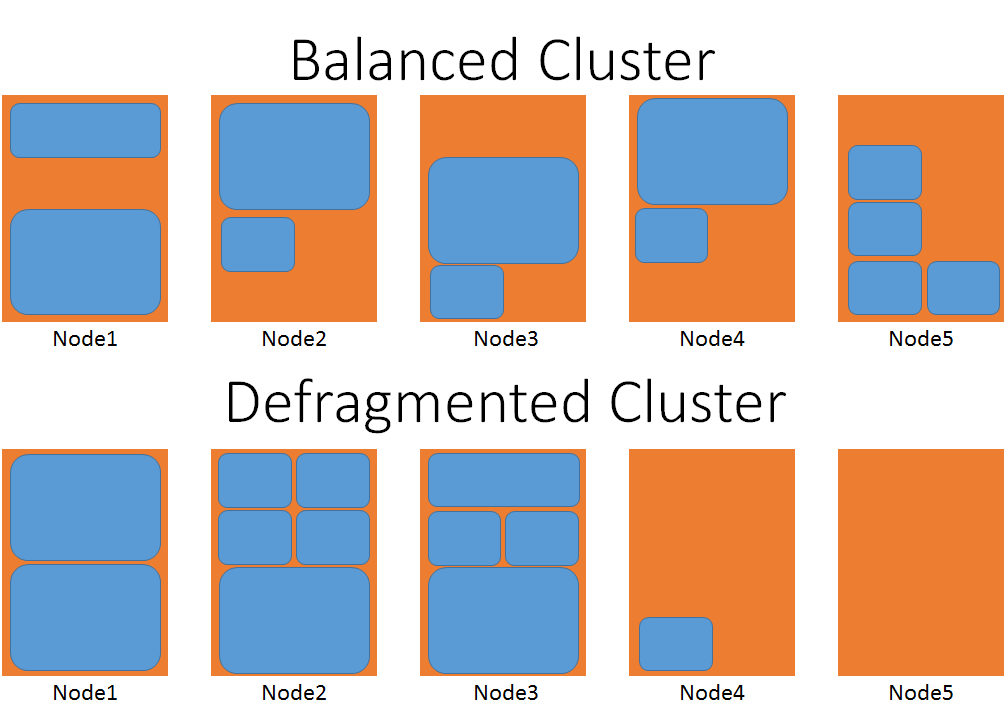
В сбалансированном случае рассмотрим количество перемещений, необходимых для размещения одного из крупнейших объектов службы. В дефрагментированном кластере большая рабочая нагрузка может быть размещена на узлы четыре и пять, не ожидая перемещения других служб.
Дефрагментация плюсов и минусов
Так что же такое другие концептуальные компромиссы? Вот краткая таблица вещей, о которых следует думать:
| Преимущества дефрагментации | Недостатки дефрагментации |
|---|---|
| Позволяет ускорить создание больших служб | Концентрирует нагрузку на меньшее количество узлов, увеличивая конкуренцию. |
| Обеспечивает уменьшение перемещения данных во время создания | Сбои могут повлиять на больше служб и привести к большему объему обработки |
| Позволяет подробные описания требований и восстановление пространства | Более сложная общая конфигурация управления ресурсами |
Вы можете смешивать дефрагментированные и обычные метрики в одном кластере. Диспетчер кластерных ресурсов пытается в максимальной степени консолидировать метрики дефрагментации, одновременно распределяя остальные. Результаты сочетания стратегий дефрагментации и балансировки зависят от нескольких факторов, в том числе:
- количество метрик балансировки и число метрик дефрагментации
- Применяет ли какая-либо служба оба типа метрик
- Метрические веса
- текущая загруженность системы
Для определения требуемой конфигурации требуется экспериментирование. Перед включением метрик дефрагментации в рабочей среде рекомендуется тщательно измерять рабочие нагрузки. Это особенно верно при сочетании дефрагментации и сбалансированных метрик в одной службе.
Настройка метрик дефрагментации
Настройка метрик дефрагментации — это глобальное решение в кластере, а для дефрагментации можно выбрать отдельные метрики. В следующих фрагментах конфигурации показано, как настроить метрики для дефрагментации. В этом случае "Метрика1" настроена как метрика дефрагментации, а "Метрика2" будет продолжать балансироваться нормально.
ClusterManifest.xml:
<Section Name="DefragmentationMetrics">
<Parameter Name="Metric1" Value="true" />
<Parameter Name="Metric2" Value="false" />
</Section>
Для автономных развертываний используется ClusterConfig.json, а для размещенных в Azure кластеров — Template.json.
"fabricSettings": [
{
"name": "DefragmentationMetrics",
"parameters": [
{
"name": "Metric1",
"value": "true"
},
{
"name": "Metric2",
"value": "false"
}
]
}
]
Дальнейшие действия
- Диспетчер кластерных ресурсов имеет множество вариантов описания кластера. Дополнительные сведения о них см. в этой статье по описанию кластера Service Fabric
- Метрики показывают, как диспетчер кластерных ресурсов Service Fabric управляет потреблением и емкостью в кластере. Дополнительные сведения о метриках и их настройке см. в этой статье