Заметка
Доступ к этой странице требует авторизации. Вы можете попробовать войти в систему или изменить каталог.
Доступ к этой странице требует авторизации. Вы можете попробовать сменить директорию.
Ускорение запросов позволяет приложениям и платформам аналитики значительно оптимизировать обработку данных, извлекая только данные, необходимые для выполнения данной операции. Это сокращает время и мощность обработки, необходимые для получения критически важных сведений о хранимых данных.
Обзор
Ускорение запросов принимает предикаты фильтрации и проекции столбцов, которые позволяют приложениям фильтровать строки и столбцы при чтении данных с диска. В приложение передаются только данные, соответствующие условиям предиката. Это снижает задержку сети и затраты на вычисления.
С помощью SQL можно указать предикаты фильтра строк и проекции столбцов в запросе ускорения запросов. Запрос обрабатывает только один файл. Поэтому расширенные реляционные функции SQL, такие как соединения и группы по агрегатам, не поддерживаются. Ускорение запросов поддерживает форматированные данные CSV и JSON в качестве входных данных для каждого запроса.
Функция ускорения запросов не ограничивается хранилищем данных типа Data Lake (учетными записями хранения, у которых включено иерархическое пространство имен). Ускорение запросов совместимо с большими двоичными объектами в учетных записях хранения, на которых не включено иерархическое пространство имен. Это означает, что при обработке данных, уже хранящихся в блоках в учетных записях хранения, вы сможете добиться такого же уменьшения сетевой задержки и затрат на вычислительные ресурсы.
Пример использования ускорения запросов в клиентском приложении см. в статье "Фильтрация данных с помощью ускорения запросов Azure Data Lake Storage".
Поток данных
На следующей схеме показано, как обычное приложение использует ускорение запросов для обработки данных.
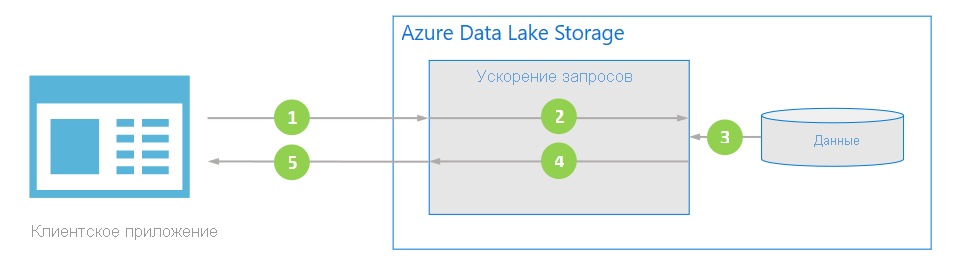
Клиентское приложение запрашивает данные файлов, указывая предикаты и проекции столбцов.
Ускорение запросов анализирует указанный SQL-запрос и распределяет работу для анализа и фильтрации данных.
Процессоры считывают данные с диска, анализирует данные с помощью соответствующего формата, а затем фильтрует данные, применяя указанные предикаты и проекции столбцов.
Ускорение запросов объединяет фрагменты ответа для передачи обратно в клиентское приложение.
Клиентское приложение получает и анализирует потокованный ответ. Приложению не нужно фильтровать другие данные и напрямую применять требуемые вычисления или преобразование.
Повышение производительности при более низкой стоимости
Ускорение запросов оптимизирует производительность, уменьшая объем передаваемых и обработанных приложением данных.
Чтобы вычислить агрегированное значение, приложения обычно извлекают все данные из файла, а затем обрабатывают и фильтруют данные локально. Анализ шаблонов входных и выходных данных для рабочих нагрузок аналитики показывает, что приложения обычно требуют только 20% данных, которые они считывают для выполнения любого заданного вычисления. Эта статистика является верной даже после применения таких методов, как обрезка разделов. Это означает, что 80% этих данных бесполезно передаются по сети, анализируются и фильтруются приложениями. Этот шаблон, предназначенный для удаления ненужных данных, вызывает значительные затраты на вычислительные ресурсы.
Несмотря на то что сеть Azure является ведущей в отрасли по пропускной способности и задержке, излишняя передача данных через эту сеть по-прежнему обходится дорого для производительности приложений. Отфильтровав нежелательные данные во время запроса на хранение, ускорение запросов устраняет эту стоимость.
Кроме того, загрузка ЦП, необходимая для синтаксического анализа и фильтрации ненужных данных, требует от приложения подготовки большего числа и больших виртуальных машин для выполнения своей работы. Перенос этой вычислительной нагрузки на ускорение запросов позволяет приложениям значительно сократить затраты.
Приложения, которые могут воспользоваться ускорением запросов
Ускорение запросов предназначено для распределенных платформ аналитики и приложений обработки данных.
Платформы распределенной аналитики, такие как Apache Spark и Apache Hive, включают уровень абстракции хранилища в платформе. Эти подсистемы также включают оптимизаторы запросов, которые могут включать знания о возможностях базовой службы ввода-вывода при определении оптимального плана запросов пользователей. Эти платформы начинают интегрировать ускорение запросов. В результате пользователи этих платформ видят улучшенную задержку запросов и более низкую общую стоимость владения, не изменяя запросы.
Ускорение запросов также предназначено для приложений обработки данных. Эти типы приложений обычно выполняют крупномасштабные преобразования данных, которые могут не привести непосредственно к аналитическим выводам, поэтому они не всегда используют установленные фреймворки распределенной аналитики. Эти приложения часто имеют более прямую связь с базовой службой хранилища, чтобы они могли воспользоваться непосредственно функциями, такими как ускорение запросов.
Пример того, как приложение может интегрировать ускорение запросов, см. в статье "Фильтрация данных с помощью ускорения запросов Azure Data Lake Storage".
Ценообразование
Из-за повышенной вычислительной нагрузки в службе Azure Data Lake Storage модель ценообразования для использования ускорения запросов отличается от обычной модели транзакций Azure Data Lake Storage. Ускорение запросов взимает плату за объем отсканированных данных, а также плату за объем данных, возвращенных вызывающему клиенту. Дополнительные сведения см. в разделе о ценах на Azure Data Lake Storage.
Несмотря на изменение модели выставления счетов, модель ценообразования ускорения запросов предназначена для снижения общей стоимости владения для рабочей нагрузки, учитывая снижение затрат на более дорогие виртуальные машины.