Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Эта статья является частью двух из семи частей серии, которая содержит рекомендации по миграции из Netezza в Azure Synapse Analytics. Эта статья посвящена лучшим практикам для ETL-процессов и миграции нагрузки.
Рекомендации по переносу данных
Первоначальные решения по миграции данных из Netezza
При переносе хранилища данных Netezza необходимо задать некоторые основные вопросы, связанные с данными. Рассмотрим пример.
Следует ли переносить неиспользуемые структуры таблиц?
Какой оптимальный подход к миграции позволяет свести к минимуму риск и влияние пользователя?
При переносе хранилищ данных: оставаться физическими или стать виртуальными?
В следующих разделах рассматриваются эти моменты в контексте миграции из Netezza.
Переносить неиспользуемые таблицы?
Подсказка
В устаревших системах таблицы нередко становятся избыточными с течением времени. В большинстве случаев их не нужно переносить.
Имеет смысл перенести только таблицы, которые используются в существующей системе. Таблицы, которые не являются активными, можно архивировать, а не перенести, чтобы данные были доступны при необходимости в будущем. Для определения того, какие таблицы используются, лучше всего использовать системные метаданные и файлы журналов, а не документацию, так как документация может быть устаревшей.
Если этот параметр включен, таблицы журнала запросов Netezza содержат сведения, которые могут определить, когда эта таблица была последней, доступ к которой, в свою очередь, может использоваться для определения того, является ли таблица кандидатом на миграцию.
Ниже приведен пример запроса, который ищет использование определенной таблицы в течение заданного периода времени:
SELECT FORMAT_TABLE_ACCESS (usage),
hq.submittime
FROM "$v_hist_queries" hq
INNER JOIN "$hist_table_access_3" hta USING
(NPSID, NPSINSTANCEID, OPID, SESSIONID)
WHERE hq.dbname = 'PROD'
AND hta.schemaname = 'ADMIN'
AND hta.tablename = 'TEST_1'
AND hq.SUBMITTIME > '01-01-2015'
AND hq.SUBMITTIME <= '08-06-2015'
AND
(
instr(FORMAT_TABLE_ACCESS(usage),'ins') > 0
OR instr(FORMAT_TABLE_ACCESS(usage),'upd') > 0
OR instr(FORMAT_TABLE_ACCESS(usage),'del') > 0
)
AND status=0;
| FORMAT_TABLE_ACCESS | SUBMITTIME
----------------------+---------------------------
ins | 2015-06-16 18:32:25.728042
ins | 2015-06-16 17:46:14.337105
ins | 2015-06-16 17:47:14.430995
(3 rows)
Этот запрос использует вспомогательные функции FORMAT_TABLE_ACCESS и цифру в конце представления $v_hist_table_access_3 для сопоставления установленной версии журнала запросов.
Какой подход к миграции лучше всего подходит для минимизации рисков и влияния на пользователей?
Этот вопрос возникает часто, так как компании хотят снизить влияние изменений на модель данных хранилища данных для повышения гибкости. Компании часто видят возможность дальнейшей модернизации или преобразования данных во время миграции ETL. Такой подход сопряжен с более высоким риском, поскольку он изменяет несколько факторов одновременно, что затрудняет сравнение результатов старой и новой систем. Внесение изменений в модель данных также может повлиять на задания ETL для других, вышестоящих или нижестоящих, систем. Because of that risk, it's better to redesign on this scale after the data warehouse migration.
Даже если модель данных планово изменяется в рамках общей миграции, рекомендуется перенести существующую модель в Azure Synapse "как есть", а не выполнять какие-либо изменения на новой платформе. Такой подход позволяет свести к минимуму влияние на существующие рабочие системы, а также использовать производительность и эластичное масштабирование платформы Azure для одноразовых задач повторной разработки.
When migrating from Netezza, often the existing data model is already suitable for as-is migration to Azure Synapse.
Подсказка
Переносите существующую модель "как есть", даже если в будущем планируется изменение модели данных.
Migrate data marts: stay physical or go virtual?
Подсказка
Виртуализация киосков данных позволяет сэкономить на ресурсах для хранения и обработки.
В устаревших средах хранилища данных Netezza обычно рекомендуется создавать несколько киосков данных, структурированных для обеспечения хорошей производительности для нерегламентированных запросов самообслуживания и отчетов для определенного отдела или бизнес-функции в организации. Таким образом, витрина данных обычно состоит из подмножества хранилища данных и содержит агрегированные данные в формате, который позволяет пользователям эффективно выполнять запросы к этим данным с быстрыми временем отклика с помощью удобных инструментов для выполнения запросов, таких как Microsoft Power BI, Tableau или MicroStrategy. Эта форма обычно является измерительной моделью данных. One use of data marts is to expose the data in a usable form, even if the underlying warehouse data model is something different, such as a data vault.
Вы можете использовать отдельные киоски данных для отдельных бизнес-подразделений в организации для реализации надежных режимов безопасности данных, позволяя только пользователям получать доступ к определенным киоскам данных, которые относятся к ним, и устранять, маскировать или анонимизировать конфиденциальные данные.
If these data marts are implemented as physical tables, they'll require additional storage resources to store them, and additional processing to build and refresh them regularly. Кроме того, данные в киоске будут актуальны только на момент последней операции обновления и поэтому могут быть непригодными для панелей мониторинга данных с высокой степенью изменчивости.
Подсказка
Производительность и масштабируемость Azure Synapse обеспечивает виртуализацию без ущерба для производительности.
С появлением относительно недорогих масштабируемых архитектур MPP, таких как Azure Synapse, и их встроенных характеристик производительности, возможно, вы можете предоставлять функциональность хранилища данных без необходимости создавать хранилище как набор физических таблиц. This is achieved by effectively virtualizing the data marts via SQL views onto the main data warehouse, or via a virtualization layer using features such as views in Azure or the visualization products of Microsoft partners. Этот подход упрощает или устраняет необходимость в дополнительной обработке хранилища и агрегирования и уменьшает общее количество объектов базы данных, которые необходимо перенести.
Существует еще одна потенциальная выгода для этого подхода. Реализуя логику агрегирования и соединения в уровне виртуализации, а также предоставляя внешние средства отчетности через виртуализированное представление, обработка, необходимая для создания этих представлений, "отправляется вниз" в хранилище данных, что, как правило, лучше всего подходит для запуска соединений, агрегатов и других связанных операций с большими объемами данных.
Основными факторами при выборе реализации виртуального хранилища данных по сравнению с физическим хранилищем данных являются:
Больше гибкости: виртуальную витрину данных изменить легче, чем физические таблицы и связанные с ними процессы извлечения, преобразования и загрузки (ETL).
Более низкая совокупная стоимость владения: меньшее количество хранилищ данных и копий данных в виртуализированной реализации.
Elimination of ETL jobs to migrate and simplify data warehouse architecture in a virtualized environment.
Performance: although physical data marts have historically been more performant, virtualization products now implement intelligent caching techniques to mitigate.
Миграция данных из Netezza
Поймите свои данные
Часть планирования миграции подробно понимает объем данных, которые необходимо перенести, так как это может повлиять на решение о подходе к миграции. Используйте системные метаданные для определения физического пространства, занятого "необработанными данными" в таблицах для переноса. В этом контексте "необработанные данные" означает объем пространства, используемого строками данных в таблице, за исключением накладных расходов, таких как индексы и сжатие. This is especially true for the largest fact tables since these will typically comprise more than 95% of the data.
Вы можете получить точное число для переноса объема данных для данной таблицы, извлекив представительный образец данных ( например, один миллион строк) в несжатый неструктурированный файл данных ASCII. Затем используйте размер этого файла, чтобы получить средний размер необработанных данных для каждой строки этой таблицы. Наконец, умножьте этот средний объем на общее количество строк в полной таблице, чтобы получить объем необработанных данных в таблице. Используйте этот объем необработанных данных при планировании.
Сопоставление типов данных Netezza
Подсказка
Оцените влияние неподдерживаемых типов данных в рамках этапа подготовки.
Большинство типов данных Netezza имеют прямой эквивалент в Azure Synapse. В следующей таблице показаны эти типы данных, а также рекомендуемый подход для их сопоставления.
| Тип данных Netezza | Тип данных Azure Synapse |
|---|---|
| BIGINT | BIGINT |
| BINARY VARYING(n) | VARBINARY(n) |
| BOOLEAN | BIT |
| BYTEINT | TINYINT |
| CHARACTER VARYING(n) | VARCHAR(n) |
| CHARACTER(n) | CHAR(n) |
| Дата | DATE(date) |
| DECIMAL(p,s) | DECIMAL(p,s) |
| двойная точность | FLOAT |
| FLOAT(n) | FLOAT(n) |
| INTEGER | INT |
| ИНТЕРВАЛ | Типы данных INTERVAL в настоящее время не поддерживаются непосредственно в Azure Synapse Analytics, но можно вычислять с помощью темпоральных функций, таких как DATEDIFF. |
| ДЕНЬГИ | ДЕНЬГИ |
| NATIONAL CHARACTER VARYING(n) | NVARCHAR(n) |
| NATIONAL CHARACTER(n) | NCHAR(n) |
| NUMERIC(p,s) | NUMERIC(p,s) |
| REAL | REAL |
| SMALLINT | SMALLINT |
| ST_GEOMETRY(n) | Пространственные типы данных, такие как ST_GEOMETRY, в настоящее время не поддерживаются в Azure Synapse Analytics, но данные могут храниться как VARCHAR или VARBINARY. |
| ВРЕМЯ | ВРЕМЯ |
| TIME WITH TIME ZONE | DATETIMEOFFSET |
| TIMESTAMP | Дата и время |
Используйте метаданные из таблиц каталога Netezza, чтобы определить, необходимо ли перенести любой из этих типов данных и разрешить это в плане миграции. Важные представления метаданных в Netezza для этого типа запроса:
_V_USER: представление пользователя предоставляет сведения о пользователях в системе Netezza._V_TABLE: представление таблицы содержит список таблиц, созданных в системе производительности Netezza._V_RELATION_COLUMN: представление системного каталога реляционных столбцов содержит столбцы, доступные в таблице._V_OBJECTS: представление объектов содержит различные объекты, такие как таблицы, представления, функции и т. д., доступные в Netezza.
Например, в этом sql-запросе Netezza отображаются столбцы и типы столбцов:
SELECT
tablename,
attname AS COL_NAME,
b.FORMAT_TYPE AS COL_TYPE,
attnum AS COL_NUM
FROM _v_table a
JOIN _v_relation_column b
ON a.objid = b.objid
WHERE a.tablename = 'ATT_TEST'
AND a.schema = 'ADMIN'
ORDER BY attnum;
TABLENAME | COL_NAME | COL_TYPE | COL_NUM
----------+-------------+----------------------+--------
ATT_TEST | COL_INT | INTEGER | 1
ATT_TEST | COL_NUMERIC | NUMERIC(10,2) | 2
ATT_TEST | COL_VARCHAR | CHARACTER VARYING(5) | 3
ATT_TEST | COL_DATE | DATE | 4
(4 rows)
The query can be modified to search all tables for any occurrences of unsupported data types.
Фабрика данных Azure может использоваться для перемещения данных из устаревшей среды Netezza. For more information, see IBM Netezza connector.
сторонние поставщики предлагают средства и службы для автоматизации миграции, включая сопоставление типов данных, как описано ранее. Кроме того, сторонние средства ETL, такие как Informatica или Talend, уже используемые в среде Netezza, могут реализовать все необходимые преобразования данных. В следующем разделе рассматривается миграция существующих сторонних процессов ETL.
Рекомендации по миграции ETL
Первоначальные решения о миграции Netezza ETL
Подсказка
Планируйте подход к миграции ETL заранее и используйте средства Azure, где это необходимо.
Для обработки ETL/ELT устаревшие хранилища данных Netezza могут использовать пользовательские скрипты с помощью служебных программ Netezza, таких как nzsql и nzload, или сторонние средства ETL, такие как Informatica или Ab Initio. Иногда хранилища данных Netezza используют сочетание подходов ETL и ELT, которые развивались с течением времени. При планировании миграции в Azure Synapse необходимо определить оптимальный способ реализации требуемой обработки ETL/ELT в новой среде, минимизируя затраты и риски. To learn more about ETL and ELT processing, see ELT vs ETL design approach.
В следующих разделах рассматриваются варианты миграции и рекомендации по различным вариантам использования. В этой блок-схеме приводится один подход:
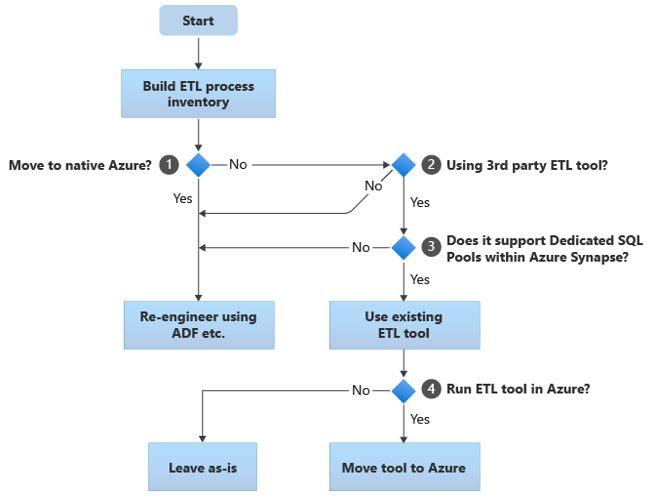
Первым шагом является создание инвентаризации процессов ETL/ELT, которые необходимо перенести. Как и в других шагах, возможно, стандартные встроенные функции Azure могут сделать ненужной миграцию некоторых существующих процессов. В целях планирования важно понимать масштаб выполняемой миграции.
В приведенной выше блок-схеме решение 1 относится к высокому решению о том, следует ли переходить в полностью собственную среду Azure. If you're moving to a totally Azure-native environment, we recommend that you re-engineer the ETL processing using Pipelines and activities in Azure Data Factory or Azure Synapse Pipelines. Если вы не переходите в полностью собственную среду Azure, то решение 2 заключается в том, уже используется ли существующее стороннее средство ETL.
Подсказка
Используйте существующие сторонние средства, чтобы снизить затраты и риски.
Если сторонний инструмент ETL уже используется, и особенно если есть большие инвестиции в навыки или несколько существующих рабочих процессов и расписаний использования этого инструмента, то решение 3 заключается в том, может ли средство эффективно поддерживать Azure Synapse в качестве целевой среды. В идеале средство будет включать "собственные" соединители, которые могут использовать такие средства Azure, как PolyBase или COPY INTO, для наиболее эффективной загрузки данных. Существует способ вызова внешнего процесса, например PolyBase или COPY INTO, и передать соответствующие параметры. В этом случае используйте существующие навыки и рабочие процессы с Azure Synapse в качестве новой целевой среды.
Если вы решите сохранить существующее стороннее ETL-средство, может быть выгодно запускать его в среде Azure (вместо на существующем локальном сервере ETL), при этом Azure Data Factory будет управлять общей оркестрацией существующих рабочих процессов. Одним из преимуществ является то, что меньше данных необходимо скачать из Azure, обработать, а затем отправить обратно в Azure. Таким образом, решение 4 заключается в том, следует ли оставить существующий инструмент as-is работающим или переместить его в среду Azure, чтобы получить выгоды в виде снижения затрат, повышения производительности и улучшения масштабируемости.
Перепроектировать существующие скрипты, специфичные для Netezza
Если некоторые или все существующие операции обработки ETL/ELT хранилища Netezza обрабатываются пользовательскими скриптами, используюющими служебные программы netezza, такие как nzsql или nzload, эти скрипты необходимо перекодировать для новой среды Azure Synapse. Аналогичным образом, если процессы ETL были реализованы с помощью хранимых процедур в Netezza, они также должны быть перекодированы.
Подсказка
Список задач ETL для переноса должен включать скрипты и хранимые процедуры.
Некоторые элементы процесса ETL легко перенести, например путем простой загрузки массовых данных в промежуточную таблицу из внешнего файла. Можно даже автоматизировать эти части процесса, например с помощью PolyBase вместо nzload. Другие части процесса, которые содержат произвольные сложные SQL и (или) хранимые процедуры, потребуют больше времени для повторной перепроектировки.
Одним из способов тестирования Netezza SQL на совместимость с Azure Synapse является сохранение некоторых репрезентативных SQL-операторов из журнала запросов Netezza, добавлением префикса EXPLAINк этим запросам, а затем, если в Azure Synapse предполагается аналогичная мигрированная модель данных, запустите эти операторы EXPLAIN в Azure Synapse. Любой несовместимый SQL создаст ошибку, а сведения об ошибке могут определить масштаб задачи перекодирования.
Партнеры Майкрософт предлагают инструменты и службы для переноса Netezza SQL и хранимых процедур в Azure Synapse.
Использование сторонних средств ETL
Как описано в предыдущем разделе, во многих случаях существующая устаревшая система хранилища данных уже заполняется и поддерживается сторонними продуктами ETL. Список партнеров по интеграции данных Microsoft для Azure Synapse см. в разделе Партнеры по интеграции данных.
Загрузка данных из Netezza
Доступные варианты при загрузке данных из Netezza
Подсказка
Сторонние средства могут упростить и автоматизировать процесс миграции и, следовательно, снизить риск.
Когда речь идет о переносе данных из хранилища данных Netezza, существуют некоторые основные вопросы, связанные с загрузкой данных, которые необходимо устранить. Вам потребуется решить, как данные будут физически перемещаться из существующей локальной среды Netezza в Azure Synapse в облаке и какие средства будут использоваться для выполнения передачи и загрузки. Рассмотрим следующие вопросы, которые рассматриваются в следующих разделах.
Вы будете извлекать данные в файлы или перемещать их непосредственно через сетевое подключение?
Оркестрация процесса будет выполняться из исходной системы или из целевой среды Azure?
Какие средства будут использоваться для автоматизации процесса и управления ими?
Передача данных должна осуществляться через файлы или сетевое подключение?
Подсказка
Поймите объемы данных, которые необходимо перенести, и доступную пропускную способность сети, поскольку эти факторы влияют на выбор подхода к миграции.
После переноса таблиц базы данных в Azure Synapse можно переместить данные для заполнения этих таблиц из устаревшей системы Netezza и в новую среду. Существует два основных подхода:
File extract: extract the data from the Netezza tables to flat files, normally in CSV format, via nzsql with the -o option or via the
CREATE EXTERNAL TABLEstatement. Используйте внешнюю таблицу, если это возможно, так как она наиболее эффективна с точки зрения пропускной способности данных. В следующем примере SQL создается CSV-файл с помощью внешней таблицы:CREATE EXTERNAL TABLE '/data/export.csv' USING (delimiter ',') AS SELECT col1, col2, expr1, expr2, col3, col1 || col2 FROM your table;Используйте внешнюю таблицу, если вы экспортируете данные в подключенную файловую систему на локальном узле Netezza. If you're exporting data to a remote machine that has JDBC, ODBC, or OLEDB installed, then your "remotesource odbc" option is the
USINGclause.Для этого подхода требуется место для размещения извлеченных файлов данных. Пространство может быть локальным для базы данных-источника Netezza (если доступно достаточное хранилище) или удаленным в Azure Blob Storage. Оптимальная производительность достигается при локальной записи файла, так как это позволяет избежать затрат на сеть.
Чтобы свести к минимуму требования к хранилищу и передаче сети, рекомендуется сжать извлеченные файлы данных с помощью программы gzip.
После извлечения плоские файлы можно переместить в хранилище BLOB-объектов Azure (расположенное рядом с целевым экземпляром Azure Synapse) или загрузить непосредственно в Azure Synapse с помощью PolyBase или команды COPY INTO. Метод физического перемещения данных из локального локального хранилища в облачную среду Azure зависит от объема данных и доступной пропускной способности сети.
Корпорация Майкрософт предоставляет различные возможности для перемещения больших объемов данных, включая AzCopy для перемещения файлов в сеть в службу хранилища Azure, Azure ExpressRoute для перемещения массовых данных через подключение к частной сети и Azure Data Box для файлов, перемещаемых на физическое устройство хранилища, которое затем отправляется в центр обработки данных Azure для загрузки. For more information, see data transfer.
прямую извлечение и загрузку по сети: целевая среда Azure отправляет запрос на извлечение данных, обычно с помощью команды SQL, в устаревшую систему Netezza для извлечения данных. Результаты отправляются по сети и загружаются непосредственно в Azure Synapse без необходимости помещать данные в промежуточные файлы. Ограничение в этом сценарии обычно является пропускной способностью сетевого подключения между базой данных Netezza и средой Azure. Для очень больших объемов данных такой подход может оказаться нецелесообразным.
Существует также гибридный подход, при котором используются оба метода. Например, для небольших таблиц измерений и образцов больших таблиц фактов можно использовать метод непосредственного извлечения по сети, чтобы быстро предоставить тестовую среду в Azure Synapse. Для таблиц фактов большого объема можно использовать подход извлечения и передачи файлов с помощью Azure Data Box.
Организация процессов из Netezza или Azure?
Рекомендуемый подход при переходе в Azure Synapse заключается в оркестрации извлечения и загрузки данных из среды Azure с помощью Azure Synapse Pipelines или Azure Data Factory, а также связанных служебных программ, таких как PolyBase или COPY INTOдля наиболее эффективной загрузки данных. Этот подход использует возможности Azure и предоставляет простой метод для создания конвейеров загрузки повторно используемых данных.
Другие преимущества этого подхода включают снижение влияния на систему Netezza во время процесса загрузки данных, так как процесс управления и загрузки выполняется в Azure, а также возможность автоматизировать процесс с помощью конвейеров загрузки данных на основе метаданных.
Какие средства можно использовать?
Задача преобразования данных и перемещения — это основная функция всех продуктов ETL. Если один из этих продуктов уже используется в существующей среде Netezza, то использование существующего средства ETL может упростить миграцию данных из Netezza в Azure Synapse. Этот подход предполагает, что средство ETL поддерживает Azure Synapse в качестве целевой среды. For more information on tools that support Azure Synapse, see Data integration partners.
Если вы используете средство ETL, попробуйте запустить это средство в среде Azure, чтобы воспользоваться преимуществами облачной производительности, масштабируемости и затрат, а также освободить ресурсы в центре обработки данных Netezza. Еще одним преимуществом является снижение перемещения данных между облаком и локальными средами.
Сводка
Ниже приведены рекомендации по переносу данных и связанных процессов ETL из Netezza в Azure Synapse:
Планируйте заранее, чтобы обеспечить успешную миграцию.
Как можно скорее создайте подробный список данных и процессов, которые необходимо перенести.
Используйте системные метаданные и файлы журналов, чтобы получить точное представление об использовании данных и процессов. Не полагайтесь на документацию, так как она может быть устаревшей.
Определите объем данных, которые необходимо перенести, и пропускную способность сети между локальным центром обработки данных и облачными средами Azure.
Использование стандартных встроенных функций Azure для минимизации рабочей нагрузки миграции.
Определите и изучите наиболее эффективные средства извлечения и загрузки данных в средах Netezza и Azure. Используйте соответствующие средства на каждом этапе процесса.
Используйте такие средства Azure, как Azure Synapse Pipelines или Azure Data Factory, для оркестрации и автоматизации процесса миграции, минимизируя влияние на систему Netezza.
Дальнейшие действия
Для получения дополнительной информации об операциях управления доступом см. следующую статью этой серии: Безопасность, доступ и операции для миграций Netezza.