Проектирование и производительность миграции из Teradata
Это первая из семи статей, посвященных рекомендациям по миграции из Teradata в Azure Synapse Analytics. В ней приведены рекомендации по проектированию и повышению производительности.
Обзор
Многих существующих пользователей систем хранилища данных Teradata интересуют преимущества инноваций, предоставляемых современными облачными средами. Облачные среды типа "инфраструктура как услуга" (IaaS) и "платформа как услуга" (PaaS) позволяют делегировать такие задачи, как обслуживание инфраструктуры и разработка платформы, поставщику облачных служб.
Совет
Среда Azure — это нечто большее, чем обычная база данных. Она включает полный набор возможностей и инструментов.
Хотя Teradata и Azure Synapse Analytics являются базами данных SQL, использующими методы массовой параллельной обработки (MPP) для обеспечения высокой производительности запросов к исключительно большим объемам данных, между ними есть некоторые базовые различия в подходах.
Устаревшие системы Teradata часто устанавливаются локально и используют защищаемое оборудование. Azure Synapse работает в облаке и использует службу хранилища, а также вычислительные ресурсы Azure.
Поскольку хранилище и вычислительные ресурсы в среде Azure работают отдельно и поддерживают эластичное масштабирование, их масштаб можно независимо вертикально увеличивать или уменьшать.
Вы можете приостанавливать работу Azure Synapse и изменять размер службы, чтобы сэкономить на используемых ресурсах и затратах.
Обновление конфигурации Teradata — это сложная задача, требующая дополнительного физического оборудования и потенциально длительной перенастройки или перезагрузки базы данных.
Microsoft Azure — это глобально доступная, масштабируемая облачная среда с высоким уровнем безопасности, которая включает в себя Azure Synapse и экосистему вспомогательных средств и возможностей. На следующей схеме представлена экосистема Azure Synapse.
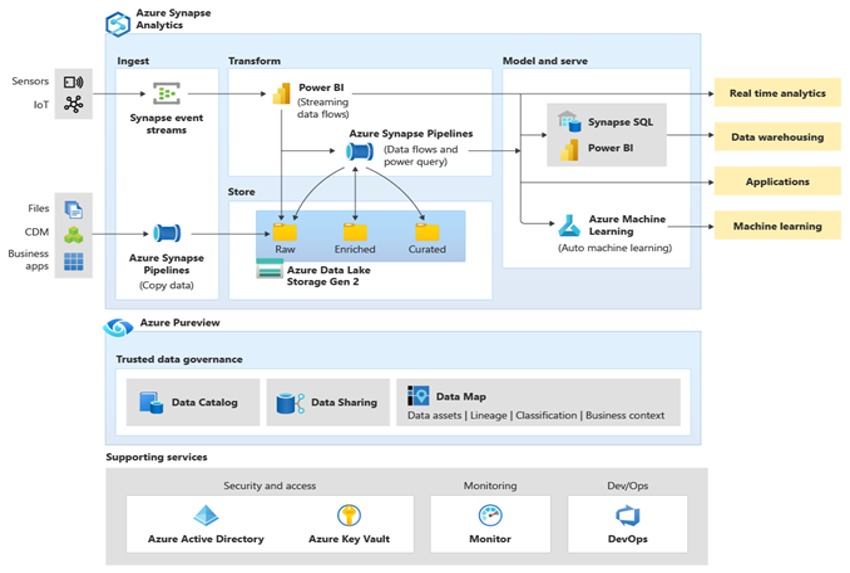
Azure Synapse обеспечивает лучшие в своем классе показатели производительности реляционной базы данных благодаря таким методам, как массовая параллельная обработка (MPP) и несколько уровней автоматического кэширования для часто используемых данных. Результаты применения этих приемов описаны в отчетах о независимых тестах производительности, например от GigaOm, где Azure Synapse сравнивается с другими популярными облачными хранилищами данных. Клиенты, которые переносятся в среду Azure Synapse, получают целый ряд преимуществ, включая следующие:
улучшение показателей производительности, а также соотношения цены и производительности;
Увеличение гибкость и сокращение срока окупаемости.
Увеличение скорости развертывания серверов и разработки приложений.
эластичная масштабируемость — плата только за фактическое использование;
улучшение показателей безопасности и соответствия требованиям;
Снижение затрат на хранение и аварийное восстановление.
уменьшение общей совокупной стоимости владения, улучшение контроля затрат и оптимизация эксплуатационных расходов (OPEX).
Чтобы в полной мере использовать эти преимущества, перенесите новые или существующие данные и приложения на платформу Azure Synapse. Во многих организациях миграция включает перенос существующего хранилища данных с устаревшей локальной платформы, например Teradata, в Azure Synapse. В целом процесс миграции включает следующие этапы:
Подготовка 🡆
Определите область (что именно нужно перенести).
Составьте список данных и процессов для миграции.
Определите изменения модели данных (при их наличии).
Определите механизм извлечения исходных данных.
Определите оптимальные средства и функции Azure и сторонних производителей.
Сразу же проведите обучение персонала на новой платформе.
Настройте целевую платформу Azure.
Миграция 🡆
Начните с малого.
Автоматизируйте все, что возможно.
Используйте встроенные средства и функции Azure, чтобы уменьшить трудоемкость переноса.
Перенесите метаданные для таблиц и представлений.
Перенесите исторические данные, которые требуется сохранить.
Произведите миграцию или рефакторинг хранимых процедур и бизнес-процессов.
Произведите миграцию или рефакторинг процессов добавочной загрузки в рамках извлечения, преобразования и загрузки или извлечения, загрузки и преобразования.
После миграции
Отслеживайте и документируйте все этапы процесса.
На основе полученного опыта создайте шаблон для будущих миграций.
При необходимости переработайте модель данных с учетом производительности и масштабируемости новой платформы.
Протестируйте приложения и средства запросов.
Протестируйте и оптимизируйте производительность запросов.
В этой статье приведены общие сведения и рекомендации по оптимизации производительности при переносе хранилища данных из существующей среды Netezza в Azure Synapse. Цель оптимизации производительности — достичь той же или более высокой производительности хранилища данных в Azure Synapse после миграции схемы.
Рекомендации по проектированию
Область миграции
При подготовке к миграции из среды Teradata рассмотрите перечисленные ниже варианты миграции.
Выбор рабочей нагрузки для начальной миграции
Среды Teradata обычно со временем развиваются, охватывая новые предметные области и смешанные рабочие нагрузки. Если вы решаете, с чего начать проект начальной миграции, выберите область, которая обладает следующими особенностями:
дает возможность подтвердить жизнеспособность перехода на Azure Synapse, быстро предоставив преимущества новой среды;
позволяет внутреннему техническому персоналу получить опыт работы с новыми процессами и средствами, который затем можно применить при переносе других областей;
позволяет создать шаблон для дальнейшей миграции, относящийся к исходной среде Teradata, а также к текущим средствам и процессам, которые уже существуют.
Хороший кандидат на начальную миграцию из среды Teradata соответствует указанным выше условиям, а также:
реализует рабочую нагрузку бизнес-аналитики, а не рабочую нагрузку обработки транзакций (OLTP);
использует модель данных, например типа "звезда" или "снежинка", которую можно перенести с минимальными изменениями.
Совет
Проведите инвентаризацию объектов для переноса и задокументируйте процесс миграции.
Объем данных миграции для начальной задачи должен быть достаточно большим, чтобы можно было показать возможности и преимущества среды Azure Synapse, но при этом быстро продемонстрировать ценность. Как правило, такой объем составляет от 1 до 10 терабайт.
Чтобы быстро увидеть преимущества облачной среды Azure, свести к минимуму риски, усилия и время, необходимые на перенос, ограничьте область миграции только киосками данных, например частью баз данных OLAP хранилища Teradata. Методы lift-and-shift и поэтапной миграции ограничивают область начальной миграции только киосками данных и не рассматривают более широкие аспекты, такие как миграция ETL и перенос исторических данных. Однако эти аспекты можно реализовать на последующих этапах проекта после того, как перенесенный уровень киоска данных будет заполнен данными и необходимыми процессами сборки.
Перенос по методу lift-and-shift и поэтапный подход
Как правило, независимо от цели и области применения плановой миграции существует два метода: lift-and-shift без изменений и поэтапный подход, включающий изменения.
Методика lift-and-shift
В рамках подхода lift-and-shift существующая модель данных, например схема "звезда", переносится на новую платформу Azure Synapse без изменений. Упор делается на минимизацию рисков и времени миграции путем уменьшения объема работ, необходимого для реализации преимуществ перехода на облачную среду Azure. Миграция lift-and-shift подходит для следующих сценариев:
- у вас есть среда Teradata с одним киоском данных для миграции;
- у вас есть среда Teradata с данными, которые уже вписаны в правильно спроектированную схему "звезда" или "снежинка";
- у вас ограничены время и бюджет на миграцию в современную облачную среду.
Совет
Lift-and-shift является хорошей отправной точкой, даже если на последующих этапах в модель данных будут вноситься изменения.
Поэтапный подход, включающий изменения
Если устаревшее хранилище развивалось в течение длительного времени, возможно, его потребуется модернизировать для обеспечения необходимых уровней производительности. или поддержки новых данных, например потоков Интернета вещей. В рамках процесса модернизации вы можете перейти на Azure Synapse, чтобы получить преимущества масштабируемой облачной среды. Миграция также может включать изменение базовой модели данных, например переход с модели Inmon на хранилище данных.
Корпорация Майкрософт рекомендует переместить существующую модель данных в Azure без изменений (при необходимости применив экземпляр Teradata на виртуальной машине в Azure) и использовать производительность и гибкость среды Azure для, чтобы применить изменения модернизации. Так вы сможете задействовать возможности Azure для внесения изменений, не затрагивая существующую исходную систему.
Использование экземпляра Teradata на виртуальной машине Azure в процессе миграции
При миграции из локальной среды Teradata можно использовать облачное хранилище и преимущества эластичной масштабируемости в Azure для создания экземпляра Teradata на виртуальной машине. Этот подход сопоставляет экземпляр Teradata с целевой средой Azure Synapse. При этом стандартные служебные программы Teradata, такие как Teradata Parallel Data Transporter, могут эффективно переместить подмножество таблиц Teradata, которые переносятся в экземпляр виртуальной машины. Затем все последующие задачи миграции могут выполняться в среде Azure. Такой подход имеет несколько преимуществ.
После начальной репликации данных на исходную систему не влияют задачи миграции.
В среде Azure доступны привычные интерфейсы, средства и служебные программы Teradata.
В среде Azure не возникает потенциальных проблем с доступной пропускной способностью сети между исходной локальной и целевой облачными системами.
Такие средства, как Фабрика данных Azure, могут вызывать служебные программы, например Teradata Parallel Transporter, для простого и быстрого переноса данных.
Процесс миграции полностью оркестрируется и контролируется в среде Azure.
Совет
Используйте виртуальные машины Azure для создания временного экземпляра Teradata, чтобы ускорить миграцию и свести к минимуму влияние на исходную систему.
Использование Фабрики данных Azure для реализации миграции на основе метаданных
Можно использовать возможности среды Azure, чтобы автоматизировать и отладить процесс миграции. Такой подход позволяет снизить влияние на существующую среду Netezza, нагрузка на которую уже может быть максимальной.
Фабрика данных Azure — это облачная служба интеграции данных, которая позволяет создавать управляемые данными рабочие процессы в облаке для оркестрации и автоматизации перемещения и преобразования данных. С помощью Фабрики данных можно создавать и включать в расписание управляемые данными рабочие процессы (конвейеры), которые принимают данные из разнородных хранилищ. Фабрика данных может обрабатывать и преобразовывать эти данные с помощью таких служб вычислений, как Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics и машинное обучение Azure.
Планируя использование средств Фабрики данных для управления процессом миграции, создайте метаданные со списком всех таблиц данных, которые необходимо перенести, и их расположений.
Структурные различия между Teradata и Azure Synapse
Как упоминалось ранее, существуют некоторые основные различия в подходе между базами данных Teradata и Azure Synapse Analytics, и эти различия рассматриваются далее.
Несколько или одна база данных, схемы
Среда Teradata часто содержит несколько отдельных баз данных. Например, могут существовать отдельные базы для приема данных и промежуточных таблиц, основных таблиц хранилища и киосков данных (иногда это называется семантическим слоем). Процессы конвейеров "извлечение, преобразование и загрузка" и "извлечение, загрузка и преобразование" могут реализовывать соединения между отдельными базами и перемещать данные между ними.
В то же время среда Azure Synapse содержит единственную базу данных и использует схемы для разделения таблиц на логически изолированные группы. Мы рекомендуем использовать несколько схем в целевой базе данных Azure Synapse, чтобы смоделировать все отдельные базы данных, перенесенные из среды Teradata. Если в среде Teradata уже используются схемы, для перемещения существующих таблиц и представлений Teradata в новую среду может потребоваться новое соглашение об именовании. Например, можно сцепить имена существующих схемы и таблицы Teradata с именем новой таблицы Azure Synapse, а затем использовать имена схем в новой среде для сохранения имен исходных отдельных баз данных. Если имена консолидации схемы содержат точки, в Azure Synapse Spark могут возникнуть проблемы. Для сохранения логических структур можно использовать представления SQL поверх базовых таблиц, однако у такого подхода есть ряд потенциальных недостатков.
Представления в Azure Synapse доступны только для чтения, поэтому любые изменения данных должны вноситься в базовые таблицы.
У вас уже может быть реализован один или несколько уровней представлений, и добавление еще одного уровня может повлиять на производительность и возможности поддержки, так как неполадки с вложенными представлениями плохо поддаются устранению.
Совет
Объедините несколько баз данных в отдельную базу данных в Azure Synapse и используйте имена схем для логического разделения таблиц.
Рекомендации по таблице
При переносе таблиц между разными средами обычно перемещаются только необработанные данные и метаданные, описывающие их физическую миграцию. Другие элементы базы данных из исходной системы, такие как индексы, обычно не переносятся, так как они могут оказаться не нужны или реализованы по-другому в новой среде. Механизмы оптимизации производительности в исходной среде, например индексы, помогают понять, как именно можно оптимизировать производительность в новой среде. Например, если у таблицы в исходной среде Teradata есть неуникальный вторичный индекс (NUSI), то, вероятно, в Azure Synapse следует создать создан некластеризованный индекс. Вместо прямого воссоздания индексов бывает целесообразно воспользоваться другими нативными методами оптимизации производительности, например репликацией таблиц.
Совет
Существующие индексы помогают найти кандидатов на индексирование в перенесенном хранилище.
Высокий уровень доступности базы данных
Teradata поддерживает репликацию данных между узлами с помощью параметра FALLBACK. При этом строки таблицы, которые физически находятся в определенном узле, реплицируются в другой узел в системе. Такой подход гарантирует, что данные не будут потеряны в случае сбоя узла, и обеспечивает основу для сценариев отработки отказа.
Цель архитектуры с высоким уровнем доступности в Azure Synapse Analytics — гарантировать работоспособность базы данных в течение 99,9 % времени, не беспокоясь о влиянии операций обслуживания и перебоев в работе. Дополнительные сведения см. в Соглашении об уровне обслуживания для Azure Synapse Analytics. Платформа Azure автоматически обрабатывает критически важные задачи обслуживания, такие как обновление путем частичной замены, резервное копирование, обновление Windows и SQL, а также незапланированные события, например сбои основного оборудования, программного обеспечения или сети.
Для хранилища данных в Azure Synapse автоматически выполняется резервное копирование с созданием моментальных снимков. Такие моментальные снимки — это встроенная функция службы, которая создает точки восстановления. Ее не нужно включать специально. В настоящее время пользователи не могут удалять автоматически созданные точки восстановления, которые служба применяет для соблюдения соглашений об уровне обслуживания, касающихся восстановления.
Выделенный пул SQL Azure Synapse делает моментальные снимки вашего хранилища данных в течение дня, создавая точки восстановления, доступные в течение семи дней. Этот период хранения невозможно изменить. Azure Synapse поддерживает восьмичасовую целевую точку восстановления (RPO). Вы можете восстановить хранилище данных в основном регионе до любого из моментальных снимков, доступных за последние семь дней. Если требуется более детализированное резервное копирование, можно воспользоваться другими определенными пользователем параметрами.
Неподдерживаемые типы таблиц Teradata
Teradata поддерживает специальные типы таблиц для временных рядов и темпоральных данных. Синтаксис и некоторые функции для таблиц этих типов не поддерживаются непосредственно в Azure Synapse. Однако данные можно перенести в стандартную таблицу Azure Synapse, сопоставив их с соответствующими типами данных и проиндексировав или секционировав столбец даты и времени.
Совет
Стандартные таблицы в Azure Synapse могут поддерживать перенесенные временные ряды и темпоральные данные Teradata.
В Teradata функциональность темпоральных запросов реализуется путем перезаписи запроса и добавления дополнительных фильтров, ограничивающих диапазон дат. Если вы планируете перенести эту функцию из исходной среды Teradata, добавьте в соответствующие темпоральные запросы дополнительную фильтрацию.
Среда Azure поддерживает аналитику временных рядов для реализации сложной аналитики данных временных рядов в большом масштабе. Эти функции предназначены для приложений для анализа данных Интернета вещей.
Различия в синтаксисе SQL DML
Существуют определенные различия в синтаксисе языка обработки данных DML SQL между Teradata SQL и Azure Synapse.
QUALIFY: Teradata поддерживает операторQUALIFY. Например:SELECT col1 FROM tab1 WHERE col1='XYZ' QUALIFY ROW_NUMBER () OVER (PARTITION by col1 ORDER BY col1) = 1;Эквивалентный синтаксис Azure Synapse:
SELECT * FROM ( SELECT col1, ROW_NUMBER () OVER (PARTITION by col1 ORDER BY col1) rn FROM tab1 WHERE col1='XYZ' ) WHERE rn = 1;Арифметические операции с датами: в Azure Synapse есть такие операторы, как
DATEADDиDATEDIFF, которые можно использовать в поляхDATEилиDATETIME. Teradata поддерживает прямое вычитание таких дат, какSELECT DATE1 - DATE2 FROM...GROUP BY: в поле порядкового номераGROUP BYявно укажите имя столбца T-SQL.LIKE ANY: Teradata поддерживает синтаксисLIKE ANY, например:SELECT * FROM CUSTOMER WHERE POSTCODE LIKE ANY ('CV1%', 'CV2%', 'CV3%');Эквивалентный синтаксис в Azure Synapse:
SELECT * FROM CUSTOMER WHERE (POSTCODE LIKE 'CV1%') OR (POSTCODE LIKE 'CV2%') OR (POSTCODE LIKE 'CV3%');В зависимости от параметров системы сравнение символов в Teradata может по умолчанию производиться без учета регистра. В Azure Synapse при сравнении символов всегда учитывается регистр.
Функции, хранимые процедуры, триггеры и последовательности
При переносе хранилища данных из развитой среды, например Teradata, часто приходится переносить не только простые таблицы и представления, но и другие элементы. Примерами являются функции, хранимые процедуры, триггеры и последовательности. Проверьте, могут ли средства среды Azure заменить функциональные возможности функций, хранимых процедур и последовательностей, так как обычно бывает эффективнее использовать встроенные средства Azure, чем переписывать эти элементы для Azure Synapse.
На этапе подготовки составьте каталог объектов, которые необходимо перенести, определите метод их обработки и выделите соответствующие ресурсы в плане миграции.
Партнеры по интеграции данных предлагают средства и службы, которые позволяют автоматизировать перенос функций, хранимых процедур и последовательностей.
В следующих разделах подробно рассматривается перенос функций, хранимых процедур и последовательностей.
Функции
Как и большинство СУБД, Teradata поддерживает системные и определяемые пользователем функции в реализации SQL. При миграции с устаревшей платформы базы данных на Azure Synapse стандартные системные функции обычно переносятся без изменений. У некоторых системных функций может быть немного другой синтаксис, однако необходимые изменения можно автоматизировать.
Системные функций Teradata и произвольные пользовательские функции, у которых нет эквивалента в Azure Synapse, можно переписать на языке целевой среды. В Azure Synapse для реализации пользовательских функций применяется язык Transact-SQL.
Хранимые процедуры
Большинство современных СУБД поддерживают хранимые процедуры в базе данных. Teradata предоставляет для этой цели язык SPL. Как правило, хранимая процедура содержит инструкции SQL и процедурную логику, а также может возвращать данные или состояние.
Azure Synapse реализует хранимые процедуры с помощью T-SQL, поэтому потребуется переписать все перенесенные хранимые процедуры на этом языке.
Триггеры
Azure Synapse не поддерживает создание триггеров, но его можно реализовать с помощью Фабрики данных Azure.
Последовательности
Azure Synapse обрабатывает последовательности аналогично Teradata, и вы можете реализовать последовательности с помощью столбцов IDENTITY или кода SQL, генерирующего следующий порядковый номер. Последовательность предоставляет уникальные числовые значения, которые можно использовать в качестве суррогатных первичных ключей.
Извлечение метаданных и данных из среды Teradata
Создание языка описания данных (DDL)
Стандарт ANSI SQL определяет базовый синтаксис для команд языка описания данных (DDL). Некоторые команды DDL, такие как CREATE TABLE и CREATE VIEW, являются общими для Teradata и Azure Synapse, но также обладают характерными для своей реализации возможностями, такими как индексирование, распределение таблиц и параметры секционирования.
Существующие скрипты Teradata CREATE TABLE и CREATE VIEW можно изменить для создания эквивалентных определений в Azure Synapse. Для этого может потребоваться задействовать модифицированные типы данных и удалить или изменить характерные для Teradata предложения, например FALLBACK.
Однако все сведения, указывающие текущие определения таблиц и представлений в существующей среде Teradata, сохраняются в таблицах системного каталога. Эти таблицы — лучший источник этой информации, так как она гарантированно будет обновлена и завершена. Поддерживаемая пользователем документация может быть не синхронизирована с текущими определениями таблиц.
В среде Teradata определение текущей таблицы и представления задают таблицы системного каталога. В отличие от пользовательской документации сведения из системного каталога всегда являются полными и в точности соответствуют текущим определениям таблиц. Представления из каталога, такие какDBC.ColumnsV, обеспечивают доступ к сведениям о системном каталоге для создания инструкций DDL CREATE TABLE, создающих эквивалентные таблицы в Azure Synapse.
Совет
Используйте существующие метаданные Teradata для автоматизации создания DDL-инструкций CREATE TABLE и CREATE VIEW для Azure Synapse.
Вы также можете использовать сторонние средства миграции и извлечения, преобразования и загрузки, обрабатывающие сведения о системном каталоге для получения аналогичных результатов.
Извлечение данных из Teradata
Необработанные данные таблицы можно извлекать из таблиц Teradata в неструктурированные файлы с разделителями, например CSV, с помощью стандартных служебных программ Teradata, таких как Basic Teradata Query (BTEQ), Teradata FastExport и Teradata Parallel Transporter (TPT). Для максимально эффективного извлечения табличных данных используйте TPT. TPT задействует несколько параллельных потоков FastExport для достижения максимальной пропускной способности.
Совет
Для максимально эффективного извлечения данных используйте Teradata Parallel Transporter.
Вызывайте TPT непосредственно из Фабрики данных Azure. Это рекомендуемый подход для переноса данных локальных экземпляров Teradata и экземпляров Teradata, которые выполняются в виртуальной машине в среде Azure.
Извлеченные файлы данных должны содержать текст с разделителями в формате CSV, ORC или Parquet.
Подробные сведения см. в статье Перенос данных, операции извлечения, преобразования и загрузки, а также особенности загрузки данных для миграции из Teradata.
Рекомендации по оптимизации производительности для миграции из Teradata
Цель оптимизации производительности — достичь той же или более высокой производительности хранилища данных в Azure Synapse после миграции.
Совет
Ознакомьтесь с параметрами настройки в Azure Synapse перед началом миграции.
Различия в подходе к настройке производительности
В этом разделе описаны различия более низкого уровня между Teradata и Azure Synapse, касающиеся настройки производительности.
Возможности распространения данных
Для повышения производительности в архитектуре Azure Synapse применяются несколько узлов и параллельная обработка. Чтобы оптимизировать производительность отдельных таблиц в Azure Synapse, можно задать параметр распределения данных в инструкциях CREATE TABLE с помощью инструкции DISTRIBUTION. Например, можно указать распределенную таблицу с хэш-распределением, которая распределяет строки таблицы между вычислительными узлами с помощью детерминированной хэш-функции. Цель заключается в том, чтобы уменьшить объем данных, перемещаемых между узлами обработки при выполнении запроса.
При соединении больших таблиц хэш распределяет одну или (в идеале) обе таблицы по одному из столбцов соединения с достаточно широким диапазоном значений, чтобы обеспечить равномерное распределение. Выполняйте обработку соединения локально, так как соединяемые строки данных уже будут выровнены на одном узле обработки.
Azure Synapse также поддерживает локальные соединения между небольшой и большой таблицами путем репликации небольшой таблицы. Например, рассмотрим небольшую таблицу измерения и большую таблицу фактов в схеме типа "звезда". Azure Synapse может реплицировать таблицу измерения меньшего размера по всем узлам, чтобы гарантировать, что у значения любого ключа соединения для большой таблицы есть соответствующая локальная строка измерения. Для небольшой таблицы измерения затраты на репликацию относительно низки. Для больших таблиц измерения целесообразнее применять хэш-распределение. Дополнительные сведения о параметрах распределения данных см. в руководстве по проектированию для реплицируемых таблиц и распределенных таблиц.
Индексирование данных
Azure Synapse поддерживает несколько пользовательских вариантов индексирования, отличных от возможностей индексирования, которые реализованы в Teradata. Дополнительные сведения о различных вариантах индексирования в Azure Synapse см. в статье Индексы в таблицах выделенного пула SQL.
Существующие индексы в исходной среде Teradata служат полезным индикатором того, как используются данные и какие столбцы подходят для индексирования в среде Azure Synapse.
Секционирование данных
В хранилище данных предприятия таблицы фактов могут содержать миллиарды строк. Секционирование позволяет оптимизировать обслуживание этих таблиц и производительность запросов к ним путем разделения их на отдельные части, чтобы уменьшить объем обрабатываемых данных. В Azure Synapse спецификацию секционирования для таблицы определяет инструкция CREATE TABLE. Секционировать следует только очень большие таблицы, при этом каждая секция должна содержать не менее 60 миллионов строк.
Для секционирования можно использовать только одно поле на таблицу. Часто это поле даты, поскольку многие запросы фильтруются по датам или диапазонам дат. Вы можете изменить секционирование таблицы после начальной загрузки с помощью инструкции CREATE TABLE AS (CTAS), повторно создав таблицу с новым распределением. Подробное описание секционирования в Azure Synapse см. в статье Секционирование таблиц в выделенном пуле SQL.
Статистика по таблицам данных
Чтобы обеспечить актуальность статистики по таблицам данных, добавьте этап Статистика в задания "извлечение, преобразование и загрузка" и "извлечение, загрузка и преобразование".
Использование PolyBase или COPY INTO для загрузки данных
PolyBase поддерживает эффективную загрузку больших объемов данных в хранилище с помощью параллельных потоков загрузки. Дополнительные сведения см. в статье Стратегия загрузки данных PolyBase.
COPY INTO также поддерживает прием данных с высокой пропускной способностью, а также перечисленные ниже возможности.
Получение данных из всех файлов в папке и вложенных папках.
Получение данных из нескольких расположений в одной учетной записи хранения. Вы можете указать пути к нескольким расположениям через запятую.
Azure Data Lake Storage (ADLS) и Хранилище BLOB-объектов Azure.
Форматы файлов CSV, PARQUET и ORC.
Управление рабочей нагрузкой
Выполнение смешанных рабочих нагрузок может усложнять процесс распределения ресурсов на загруженных системах. Успешная схема управления рабочей нагрузкой позволяет эффективно управлять ресурсами, обеспечивает их высокоэффективное использование и максимально увеличивает рентабельность инвестиций. Классификация рабочей нагрузки, важность рабочей нагрузки и изоляция рабочей нагрузки позволяют лучше контролировать использование системных ресурсов рабочей нагрузкой.
В руководстве по управлению рабочими нагрузками описываются методы анализа рабочей нагрузки, управления и мониторинга важности рабочей нагрузки, а также шаги по преобразованию класса ресурсов в группу рабочей нагрузки. Используйте портал Azure и запросы T-SQL к DMV, чтобы отслеживать рабочую нагрузку и обеспечивать эффективное использование применимых ресурсов.
Следующие шаги
Дополнительные сведения см. в следующей статье из этой серии: Перенос данных, операции извлечения, преобразования и загрузки, а также особенности загрузки данных для миграции из Teradata.