За пределами миграции Teradata, внедрение современного хранилища данных в Microsoft Azure
Эта статья представляет собой седьмую из семи статей, посвященных рекомендациям по переходу от Teradata к Azure Synapse Analytics. Основное внимание в этой статье уделено рекомендациям по реализации современных хранилищ данных.
За пределами миграции хранилища данных в Azure
Основная причина миграции существующего хранилища данных в Azure Synapse Analytics заключается в использовании безопасной с глобальной точки зрения, масштабируемой, недорогой, ориентированной на облако аналитической базы данных с оплатой по мере использования. Azure Synapse позволяет полностью интегрировать перенесенное хранилище данных с аналитической экосистемой Microsoft Azure с целью использования других технологий Майкрософт и модернизации перенесенного хранилища данных. К этим технологиям относятся следующие:
Azure Data Lake Storage для экономичного приема, размещения, очистки и преобразования данных. Data Lake Storage может освободить емкость хранилища данных, занятую быстрорастущими промежуточными таблицами.
Фабрика данных Azure для интеграции полученных в результате совместной работы данных ИТ и самообслуживания с соединителями для облачных и локальных источников данных и данных потоковой передачи.
Common Data Model для совместного использования согласованных доверенных данных несколькими технологиями, в том числе:
- Azure Synapse
- Azure Synapse Spark
- Azure HDInsight
- Power BI
- Adobe Customer Experience Platform
- Azure IoT
- Партнеры Майкрософт ISV
Технологии обработки и анализа данных Майкрософт, в том числе:
- Студия машинного обучения Azure.
- Машинное обучение Azure
- Azure Synapse Spark (Spark как служба)
- Jupyter Notebook
- RStudio
- ML.NET
- .NET для Apache Spark, позволяющая специалистам по обработке и анализу данных использовать данные Azure Synapse для обучения моделей машинного обучения в большом масштабе.
Azure HDInsight для обработки больших объемов данных и объединения больших данных с данными Azure Synapse путем создания логического хранилища данных с помощью PolyBase.
Центры событий Azure, Azure Stream Analytics и Apache Kafka для интеграции с данными потоковой трансляции из Azure Synapse.
Рост больших данных привел к острой потребности в машинном обучении для реализации пользовательских обученных моделей машинного обучения для использования в Azure Synapse. Модели машинного обучения позволяют выполнять пакетную аналитику в базе данных в большом масштабе на основе событий и по запросу. Кроме того, возможность использования в Azure Synapse аналитики в базе данных из различных средств и приложений бизнес-аналитики гарантирует получение согласованных прогнозов и рекомендаций.
Существует также возможность интеграции Azure Synapse с инструментами партнеров Майкрософт в Azure, позволяющая сократить сроки окупаемости.
Давайте изучим, как можно модернизировать хранилище данных после миграции в Azure Synapse с помощью технологий в аналитической экосистеме Майкрософт.
Передача операций помещения данных на промежуточное хранение и обработку и ETL-обработки в Data Lake Storage и Фабрику данных Azure
Цифровое преобразование создало большую проблему для предприятий, вызванную потоком новых данных для сбора и анализа. Хороший пример — данные транзакций, созданные путем открытия систем оперативной обработки транзакций (OLTP) для служебного доступа с мобильных устройств. Большая часть этих данных попадает в хранилищах данных, а системы OLTP являются основным источником. Поскольку теперь скорость выполнения транзакций увеличивают клиенты, а не сотрудники, объем данных в промежуточных таблицах хранилища данных быстро растет.
Столкнувшись с быстрым притоком данных на предприятие, а также с новыми источниками данных, такими как Интернет вещей (IoT), компаниям стало необходимо найти способы масштабирования обработки ETL для интеграции данных. Добиться этого можно посредством разгрузки приема, очистки, преобразования и интеграции данных в озеро данных и обработки их там в большом масштабе в рамках программы модернизации хранилища данных.
После переноса хранилища данных в Azure Synapse корпорация Майкрософт может модернизировать ETL-обработки за счет приема и промежуточного хранения данных в Data Lake Storage. После этого можно очищать, преобразовывать и интегрировать данные в большом масштабе с помощью Фабрики данных перед загрузкой их в Azure Synapse одновременно с использованием PolyBase.
Что касается стратегий ELT, рассмотрите возможность разгрузки ELT-обработки в Data Lake Storage, чтобы легко осуществлять масштабирование по мере увеличения объема данных или частоты.
Фабрика данных Microsoft Azure
Фабрика данных Azure — это гибридная служба интеграции данных с оплатой по мере использования для высокомасштабируемой ETL и ELT-обработки. Фабрика данных предоставляет веб-интерфейс для создания конвейеров интеграции данных без написания кода. Фабрика данных позволяет выполнять следующие действия:
Создание масштабируемых конвейеров интеграции данных без написания кода.
Простое получение данных в большом масштабе.
Оплата по мере использования.
Подключение к локальным, облачным и SaaS-источникам данных.
Прием, перемещение, очистка, преобразование, интеграция и анализ облачных и локальных данных в большом масштабе.
Простое создание, отслеживание и администрирование конвейеров, охватывающих хранилища данных как в локальной, так и в облачной среде.
Включение горизонтального увеличения масштаба с оплатой по мере использования по мере роста числа клиентов.
Эти функции можно использовать без написания кода, либо можно добавить пользовательский код в конвейеры Фабрики данных. На следующем снимке экрана представлен пример конвейера Фабрики данных.

Совет
Фабрика данных позволяет создавать масштабируемые конвейеры интеграции данных без написания кода.
Реализовать разработку конвейера Фабрики данных можно из нескольких мест, в том числе:
портал Microsoft Azure;
Microsoft Azure PowerShell;
программным образом из .NET и Python с помощью пакета SDK с поддержкой нескольких языков;
шаблоны Azure Resource Manager (ARM);
REST API.
Совет
Фабрика данных может подключаться к локальным и облачным данным, а также к данным SaaS.
Разработчики и специалисты по обработке и анализу данных, предпочитающие писать код, могут без проблем создавать конвейеры фабрики данных на Java, Python и .NET с помощью пакетов SDK, доступных для этих языков программирования. Конвейеры Фабрики данных бывают гибридными, так как могут подключаться, принимать, очищать, преобразовывать и анализировать данные в локальных центрах обработки данных, Microsoft Azure, других облаках и предложениях SaaS.
После завершения разработки конвейеров Фабрики данных для интеграции и анализа данных, можно развернуть эти конвейеры глобально и запланировать их выполнение в пакетном режиме, вызывать их по требованию как службу или запускать в реальном времени на основе событий. Конвейер Фабрики данных также может выполняться на одном или нескольких модулях выполнения и отслеживать выполнение с целью обеспечения производительности и отслеживания ошибок.
Совет
В Фабрике данных Azure конвейеры управляют интеграцией и анализом данных. Фабрика данных — это программное обеспечение корпоративного класса для интеграции данных, предназначенное для ИТ-специалистов и способное на первичную обработку данных для бизнес-пользователей.
Варианты использования
Фабрика данных поддерживает множество вариантов использования, включая следующие:
Подготовка, интеграция и обогащение данных из облачных и локальных источников для заполнения перенесенного хранилища данных и киосков данных в Microsoft Azure Synapse.
Подготовка, интеграция и обогащение данных из облачных и локальных источников с целью создания обучающих данных для использования при разработке моделей машинного обучения и повторном обучении аналитических моделей.
Оркестрация подготовки и аналитики данных с целью создания прогнозных и предписывающих аналитических конвейеров для пакетной обработки и анализа данных, таких как аналитика тональности. Выполнение действий на основе результатов анализа или заполнение хранилища данных результатами.
Подготовка, интеграция и обогащение данных для бизнес-приложений на основе данных, работающих в облаке Azure на базе таких операционных хранилищ данных, как Azure Cosmos DB.
Совет
Создавайте при обработке и анализе данных наборы данных для обучения с целью разработки моделей машинного обучения.
Источники данных
Фабрика данных позволяет использовать соединители из облачных и локальных источников данных. Агентское программное обеспечение, известное как локальная среда выполнения интеграции, безопасно обращается к локальным источникам данных и поддерживает безопасную масштабируемую передачу данных.
Преобразование данных с помощью фабрики данных Azure
В конвейере Фабрики данных можно принимать, очищать, преобразовывать, интегрировать и анализировать любые типы данных из этих источников. Данные могут быть структурированы, частично структурированы, например JSON или Avro, или неструктурированными.
Без написания и строчки кода профессиональные ETL-разработчики могут использовать потоки данных для сопоставления Фабрики данных для фильтрации, разделения, соединения (различные типы), поиска, свертывания, отмены свертывания, сортировки, объединения и агрегирования данных. Кроме того, Фабрика данных поддерживает суррогатные ключи, различные варианты обработки записи, такие как вставка, upsert, обновление, воссоздание таблиц и усечение таблиц, а также несколько типов целевых хранилищ данных, также известных как приемники. ETL-разработчики также могут создавать агрегаты, в том числе агрегаты временных рядов, требующие размещения окна в столбцах данных.
Совет
Профессиональные ETL-разработчики могут использовать потоки данных для сопоставления Фабрики данных для очистки, преобразования и интеграции данных без написания кода.
Потоки данных сопоставления, преобразующие данные, можно запускать в качестве действий в конвейере Фабрики данных, и при необходимости можно включить несколько потоков данных сопоставления в один конвейер. Таким образом можно управлять сложностью, разбивая сложные задачи преобразования данных и интеграции на более мелкие потоки данных сопоставления, которые можно комбинировать. А при необходимости можно добавить пользовательский код. Помимо этих функций, потоки данных для сопоставления Фабрики данных включают следующие возможности:
Определите выражения для очистки и преобразования данных, вычислений агрегатов и обогащения данных. Например, эти выражения могут выполнять проектирование признаков в поле даты, чтобы разбить его на несколько полей, чтобы создать обучающие данные во время разработки модели машинного обучения. Можно создавать выражения из богатого набора функций, в том числе математических, временных, разделения, слияния, объединения строк, условий, сопоставления с образцом, замены и многих других.
Выполняйте автоматическую обработку смещения схемы, чтобы конвейеры преобразования данных могли избежать влияния на изменения схемы в источниках данных. Это возможность особенно важна для потоковой передачи данных Интернета вещей, где изменения схемы могут происходить без уведомления при обновлении устройств или при пропуске операций чтения устройствами шлюза, собирающими данные Интернета вещей.
Секционирование данных для параллельного выполнения преобразований в большом масштабе.
Анализ потоковых данных для просмотра метаданных преобразуемого потока.
Совет
Фабрика данных поддерживает возможность автоматического обнаружения изменений схемы и управления ими во входящих данных, таких как данные потоковой передачи.
На следующем снимке экрана показан пример потока сопоставления данных в фабрике данных.

Инженеры данных могут профилировать качество данных и просматривать результаты отдельных преобразований данных путем включения возможности отладки во время разработки.
Совет
Фабрика данных также может секционировать данные, чтобы включить обработку ETL для выполнения в большом масштабе.
При необходимости можно расширить возможности преобразования Фабрики данных и аналитических функций, добавив в конвейер связанную службу, содержащую пользовательский код. Например, записная книжка пула Spark Azure Synapse может содержать код Python, который использует обученную модель для оценки данных, интегрированных потоком данных сопоставления.
Можно хранить интегрированные данные и любые результаты аналитики внутри конвейера Фабрики данных, в одном или нескольких хранилищах данных, таких как Data Lake Storage, Azure Synapse или таблицы Hive в HDInsight. Можно также инициировать другие действия для работы с аналитическими сведениями, созданными аналитическим конвейером Фабрики данных.
Совет
Конвейеры Фабрики данных являются расширяемыми, так как Фабрика данных позволяет писать собственный код и запускать его как часть конвейера.
Используйте Spark для масштабирования интеграции данных
Вовремя выполнения Фабрика данных на внутреннем уровне использует пулы Spark Azure Synapse — предложение Microsoft Spark как службы для очистки и интеграции данных в облаке Azure. Вы можете очищать, интегрировать и анализировать большие объемы данных и высокоскоростные данные, такие как данные потоковой передачи по щелчку, в большом масштабе. Корпорация Майкрософт намерена также запускать конвейеры Фабрики данных в других дистрибутивах Spark. Помимо выполнения заданий извлечения, преобразования и загрузки в Spark, Фабрика данных может вызывать скрипты Pig и запросы Hive для доступа к данным, хранящимся в HDInsight, и преобразовывать их.
Свяжите самостоятельную подготовку данных и обработку ETL фабрики данных с помощью обработки потоков данных
Первичная обработка данных позволяет бизнес-пользователям, также известным как интеграторы и инженеры данных гражданина, использовать платформу для визуального обнаружения, изучения и подготовки данных в большом масштабе без написания кода. Эта простая в использовании возможность Фабрики данных аналогична потокам данных Microsoft Excel Power Query или Microsoft Power BI, где бизнес-пользователи самостоятельно используют пользовательский интерфейс в стиле электронной таблицы с раскрывающимся списком преобразований для подготовки и интеграции данных. На следующем снимке экрана показан пример потока данных фабрики данных.

В отличие от Excel и Power BI потоки данных для первичной обработки Фабрики данных используют Power Query для создания кода M и последующего преобразования его в параллельное задание Spark в памяти для выполнения в облаке. Сочетание потоков данных для сопоставления и обработки потоков данных в Фабрике данных позволяет специалистам по извлечению, преобразованию и загрузке данных совместно с бизнес-пользователями подготавливать, интегрировать и анализировать данные для общей бизнес-цели. На предыдущей схеме потока данных для сопоставления Фабрики данных показано, как объединить Фабрику данных и записные книжки пула Spark Azure Synapse в одном конвейере Фабрики данных. Комбинация потоков сопоставления и обработки данных в Фабрике данных помогает ИТ-специалистам и бизнес-пользователям оставаться в курсе того, какие потоки данных были созданы, и поддерживает повторное использование потока данных, чтобы свести к минимуму повторную разработку и повысить производительность и согласованность.
Совет
Фабрика данных поддерживает как потоки данных, так и потоки данных сопоставления, поэтому бизнес-пользователи и ИТ-пользователи могут совместно интегрировать данные в общую платформу.
Связывание данных и аналитики в аналитических конвейерах
Помимо очистки и преобразования данных, Фабрика данных может объединять интеграцию данных и аналитику в одном конвейере. Фабрику данных можно использовать для создания как интеграции данных, так и аналитических конвейеров — последнее является расширением первого. Можно отправить аналитическую модель в конвейер, чтобы создать аналитический конвейер, который генерирует чистые интегрированные данные для прогнозов и рекомендаций. Затем можно на основе прогнозов и рекомендаций можно выполнить немедленное действие или сохранить их в хранилище данных, чтобы предоставить новые аналитические сведения и рекомендации, которые можно просмотреть в средствах бизнес-аналитики.
Для пакетной оценки данных можно разработать аналитическую модель, которая вызывается как услуга в конвейере Фабрики данных. Можно разрабатывать аналитические модели без написания кода с помощью Студии машинного обучения Azure или с помощью пакета SDK Машинного обучения Azure с использованием записных книжек Spark Azure Synapse или языка R в RStudio. При запуске конвейеров машинного обучения Spark в записных книжках пула Spark Azure Synapse анализ выполняется в большом масштабе.
Можно хранить интегрированные данные и любые результаты аналитики внутри конвейера Фабрики данных, в одном или нескольких хранилищах данных, таких как Data Lake Storage, Azure Synapse или таблицы Hive в HDInsight. Можно также инициировать другие действия для работы с аналитическими сведениями, созданными аналитическим конвейером Фабрики данных.
Использование базы данных озера для совместного использования согласованных доверенных данных
Ключевой целью любой настройки интеграции данных является возможность интегрировать данные один раз и повторно использовать их везде, а не только в хранилище данных. Например, может потребоваться использовать интегрированные данные в области обработки и анализа данных. Повторное использование позволяет избежать повторного обновления и обеспечивает согласованные, общепонятные данные, которым все могут доверять.
Common Data Model описывает основные сущности данных, которые можно использовать совместно и повторно на предприятии. Для повторного использования модель Common Data Model устанавливает набор общих имен и определений данных, описывающих сущности логических данных. Примерами общих имен данных являются Customer (Клиент), Account (Учетная запись), Product (Продукт), Supplier (Поставщик), Orders (Заказы), Payments (Платежи) и Returns (Возвраты). ИТ-специалисты и бизнес-пользователи могут использовать программное обеспечение для интеграции данных для создания и хранения общих ресурсов данных в целях максимально эффективного повторного использования и обеспечения согласованности повсюду.
Azure Synapse предоставляет отраслевые шаблоны баз данных, помогающие стандартизировать данные в озере. Шаблоны базы данных озера предоставляют схемы для предварительно определенных сфер деятельности, что позволяет загружать данные в базу данных озера структурированным образом. Мощные возможности появляются при использовании программного обеспечения интеграции данных для создания общих ресурсов данных озера, что приводит к самостоятельному описанию надежных данных, которые могут использоваться приложениями и аналитическими системами. Общие ресурсы данных можно создавать в Data Lake Storage с помощью Фабрики данных.
Совет
Data Lake Storage — это общее хранилище, которое лежит в основе Microsoft Azure Synapse, Машинного обучения Azure, Azure Synapse Spark и HDInsight.
Power BI, Azure Synapse Spark, Azure Synapse и Машинное обучение Azure могут использовать общие ресурсы данных. На следующей схеме показано, как базу данных озера можно использовать в Azure Synapse.
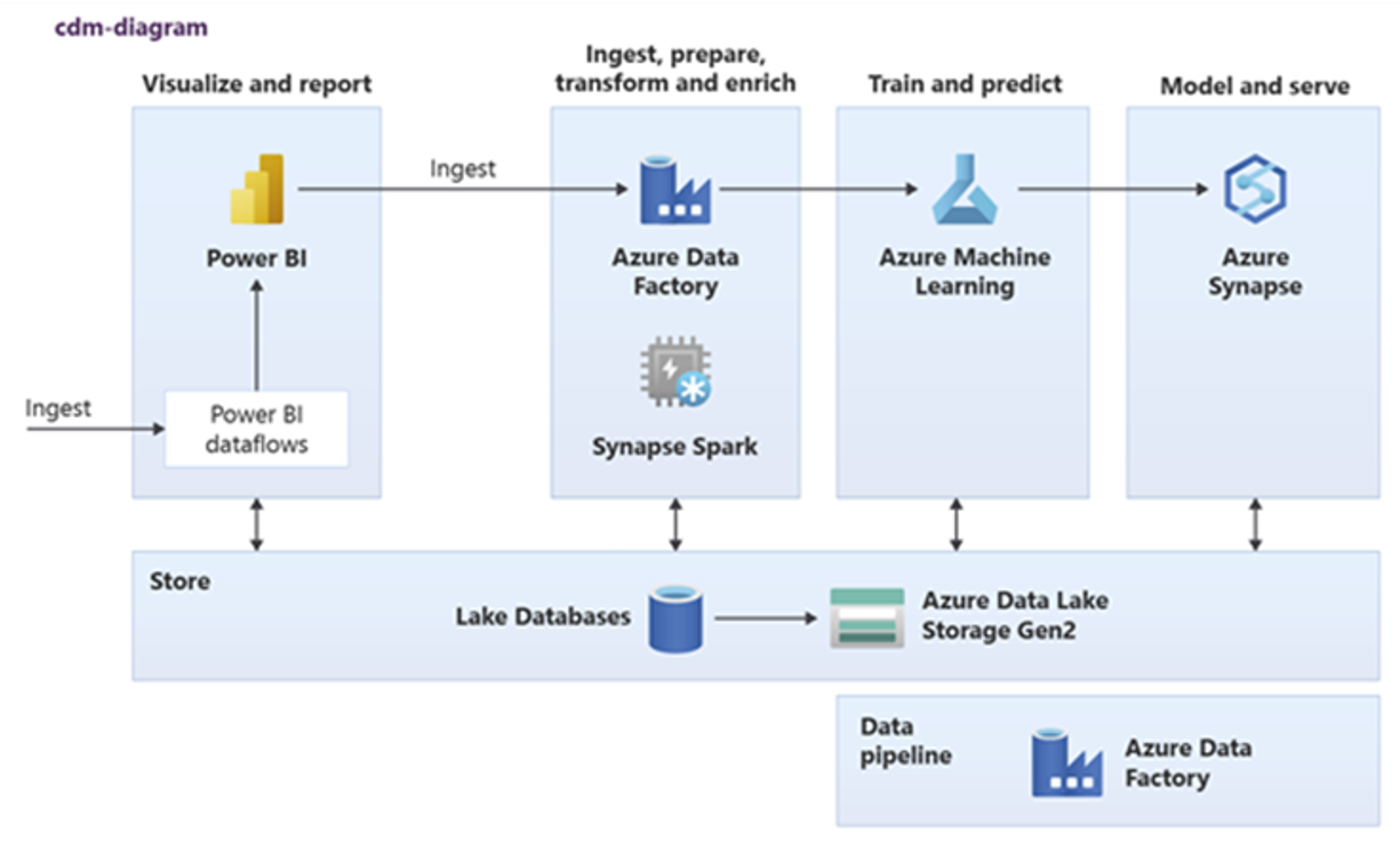
Совет
Интегрируйте данные для создания логических сущностей базы данных озера в общее хранилище, чтобы обеспечить максимально эффективное повторное использование общих ресурсов данных.
Интеграция с технологиями обработки данных Microsoft в Azure.
Еще одной важной целью модернизации хранилища данных является создание аналитических сведений для конкурентного преимущества. Можно получить аналитику, интегрировав в Azure перенесенное хранилище данных с технологиями обработки и анализа данных корпорации Майкрософт и сторонних поставщиков. В следующих разделах описывается машинное обучение и технологии обработки и анализа данных, предлагаемые корпорацией Майкрософт, чтобы вы могли узнать, как их использовать с Azure Synapse в современной среде хранилища данных.
Технологии Майкрософт для обработки и анализа данных в Azure
Корпорация Майкрософт предлагает ряд технологий, поддерживающих расширенный анализ. Эти технологии позволяют создавать прогнозные аналитические модели с помощью машинного обучения и анализировать неструктурированные данные с помощью глубокого обучения. К этим технологиям относятся следующие:
Студия машинного обучения Azure.
Машинное обучение Azure
Записные книжки пула Spark Azure Synapse
ML.NET (API, CLI или ML.NET Model Builder для Visual Studio)
.NET для Apache Spark
Специалисты по обработке и анализу данных могут использовать RStudio (R) и Jupyter Notebook (Python) для разработки аналитических моделей или использовать платформы, такие как Keras или TensorFlow.
Совет
Разрабатывайте модели машинного обучения, используя подход без написания кода или с малым объемом кода или применяя языки программирования, такие как Python, R и .NET.
Студия машинного обучения Azure.
Студия машинного обучения Azure — это полностью управляемая облачная служба, которая позволяет создавать, развертывать и совместно использовать прогнозную аналитику с помощью пользовательского интерфейса на основе перетаскивания. На следующем снимке экрана показан пользовательский интерфейс Студии машинного обучения Azure.

Машинное обучение Azure
Машинное обучение Azure предоставляет пакет SDK и службы для языка Python, которые помогают быстро подготавливать данные, а также обучать и развертывать модели машинного обучения. Машинное обучение Azure можно использовать в записных книжках Azure с помощью Jupyter Notebook, с платформами с открытым кодом, такими как PyTorch, TensorFlow, scikit-learn или со Spark MLlib — библиотекой машинного обучения для Spark. Машинное обучение Azure предоставляет возможность AutoML, которая автоматически тестирует различные алгоритмы, чтобы определить наиболее точные из них для ускорения разработки моделей.
Совет
Машинное обучение Azure предоставляет пакет средств разработки программного обеспечения для разработки моделей машинного обучения с помощью нескольких платформ с открытым кодом.
Машинное обучение Azure также можно использовать для создания конвейеров машинного обучения, управляющих комплексным рабочим процессом, осуществляющих масштабирование в облаке программными средствами и развертывающих модели как в облаке, так и на периферии. Машинное обучение Azure содержит рабочие области — логические пространства, которые можно программно или вручную создавать на портале Azure. В этих рабочих областях централизованно хранятся целевые объекты вычислений, эксперименты, хранилища данных, обученные модели машинного обучения, образы Docker и развернутые службы, благодаря чему команды могут вести совместную работу. Машинное обучение Azure можно использовать в Visual Studio с расширением Visual Studio для ИИ.
Совет
Упорядочивайте связанные хранилища данных, эксперименты, обученные модели, образы Docker и развернутые службы в рабочих областях и управляйте ими.
Записные книжки пула Spark Azure Synapse
Записная книжка пула Spark Azure Synapse — это оптимизированная для Azure служба Apache Spark. Записные книжки пула Spark Azure Synapse обладают следующими возможностями:
Инженеры данных могут создавать и выполнять масштабируемые задания подготовки данных с помощью Фабрики данных.
Специалисты по обработке и анализу данных могут создавать и выполнять модели машинного обучения в большом масштабе с помощью записных книжек, написанных на таких языках, как Scala, R, Python, Java и SQL, для визуализации результатов.
Совет
Azure Synapse Spark — это динамически масштабируемая служба Spark как услуга корпорации Майкрософт, предлагающая масштабируемую подготовку данных, разработку моделей и выполнение развернутых моделей.
Задания, выполняемые в записной книжке пула Spark Azure Synapse, могут получать, обрабатывать и анализировать данные в большом масштабе из Хранилища BLOB-объектов Azure, Data Lake Storage, Azure Synapse, HDInsight и таких служб потоковой передачи данных, как Apache Kafka.
Совет
Azure Synapse Spark может получать доступ к данным в различных хранилищах данных аналитической экосистемы Майкрософт в Azure.
Записные книжки пула Spark Azure Synapse поддерживают автоматическое масштабирование и автоматическое завершение, что позволяет снизить совокупную стоимость владения. Специалисты по обработке и анализу данных могут использовать для управления жизненным циклом машинного обучения платформу с открытым кодом MLflow.
ML.NET
ML.NET — это платформа машинного обучения с открытым кодом для Windows, Linux и macOS. Корпорация Майкрософт разработала ML.NET, чтобы разработчики .NET могли использовать существующие средства, такие как ML.NET Model Builder для Visual Studio, для разработки пользовательских моделей машинного обучения и их интеграции в свои приложения .NET.
Совет
Корпорация Майкрософт расширила возможности машинного обучения для .NET-разработчиков.
.NET для Apache Spark
.NET для Apache Spark расширяет поддержку Spark за пределы R, Scala, Python и Java до .NET и предназначен для обеспечения доступности Spark для разработчиков .NET во всех API-интерфейсах Spark. Хотя .NET для Apache Spark в настоящее время доступен только в Apache Spark в HDInsight, корпорация Майкрософт намерена сделать .NET для Apache Spark доступным в записных книжках пула Spark в Azure Synapse.
Использование Azure Synapse Analytics с хранилищем данных
Объединить модели машинного обучения с Azure Synapse можно следующими способами:
Используйте модели машинного обучения в пакетном режиме или в реальном времени на потоковых данных для создания новых аналитических сведений и добавления их к уже известным данным в Azure Synapse.
Используйте данные в Azure Synapse для разработки и обучения новых прогнозных моделей для развертывания в другом месте, например, в других приложениях.
Развертывайте в Azure Synapse модели машинного обучения, в том числе обученные в других местах, для анализа данных в хранилище данных и формирования ценности для бизнеса.
Совет
Обучайте, тестируйте, оценивайте и выполняйте модели машинного обучения в большом масштабе в записной книжке пула Spark Azure Synapse с использованием данных в Azure Synapse.
Специалисты по обработке и анализу данных могут использовать RStudio, записные книжки Jupyter и записные книжки пула Spark Azure Synapse совместно с Машинным обучением Azure для разработки моделей машинного обучения, которые выполняются в большом масштабе в записных книжках пула Spark Azure Synapse с использованием данных в Azure Synapse. Например, специалисты по обработке и анализу данных могут создать неконтролируемую модель для сегментирования клиентов для использования в различных маркетинговых кампаниях. Используйте контролируемое машинное обучение для обучения модели, которая должна прогнозировать конкретный результат, например, прогнозировать склонность клиента к оттоку или рекомендовать клиенту следующее наилучшее предложение, чтобы попытаться увеличить свою ценность. На следующей схеме показано использование Azure Synapse для Машинного обучения Azure.
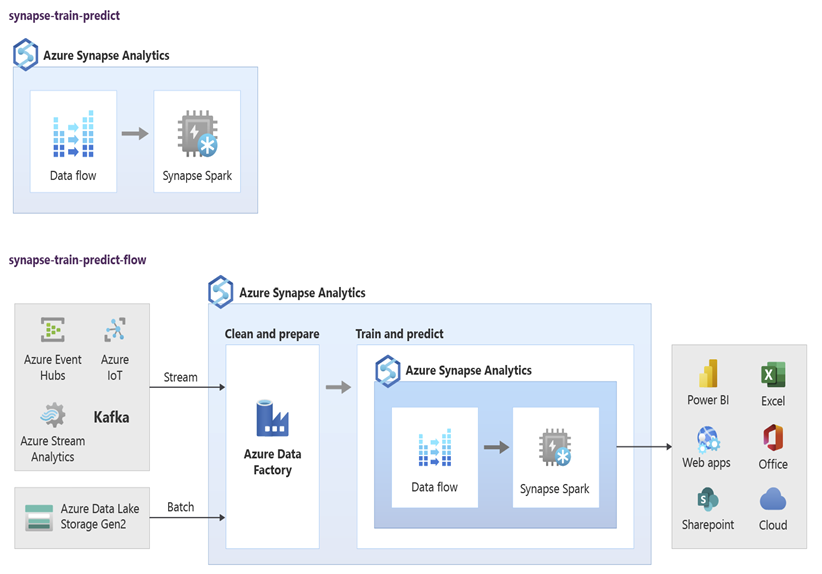
В другом сценарии можно принимать данные социальных сетей или данные о просмотрах веб-сайта в Data Lake Storage, а затем подготавливать и анализировать их в большом масштабе в записной книжке пула Spark Azure Synapse, используя обработку естественного языка для оценки тональности отзывов клиентов о продуктах или торговой марке. Затем эти оценки можно добавить в хранилище данных. Используя аналитику больших данных для понимания влияния негативных настроений на продажи продуктов, вы добавляете дополнительные сведения к известным данным в хранилище данных.
Совет
Создавайте новые аналитические сведения с помощью машинного обучения в Azure в пакетном режиме или в реальном времени и добавляйте их к уже известным данным в хранилище данных.
Интеграция данных потоковой передачи в Azure Synapse Analytics
При анализе данных в современном хранилище данных необходимо иметь возможность анализировать данные потоковой передачи в реальном времени и объединять их с историческими данными в хранилище данных. Примером является объединение данных Интернета вещей с данными о продуктах или ресурсах.
Совет
Интегрируйте хранилище данных с данными потоковой передачи с устройств Интернета вещей или сведениями о посещениях.
После успешного переноса хранилища данных в Azure Synapse можно внедрить интеграцию потоковых данных в реальном времени в рамках модернизации хранилища данных, воспользовавшись дополнительными функциями Azure Synapse. Для этого принимайте потоковые данные через Центры событий, другие технологии, такие как Apache Kafka, или, возможно, ваш существующий инструмент ETL, если он поддерживает источники потоковых данных. Сохраните данные в Data Lake Storage. Затем создайте внешнюю таблицу в Azure Synapse с помощью PolyBase и соедините ее с данными, которые передаются в Data Lake Storage, чтобы ваше хранилище данных теперь содержало новые таблицы, предоставляющие доступ к потоковым данным в реальном времени. Запрашивайте данные в этой внешней таблице так, как если бы данные находились в хранилище данных, с помощью стандартных инструкций T-SQL из любого средства бизнес-аналитики, имеющего доступ к Azure Synapse. Вы также можете присоединять потоковые данные к другим таблицам с историческими данными, чтобы создавать представления, которые присоединяют данные потоковой передачи к историческим данным, чтобы упростить доступ к ним для бизнес-пользователей.
Совет
Принимайте данные потоковой передачи в Data Lake Storage из Центров событий или Apache Kafka и обращайтесь к ним из Azure Synapse с помощью внешних таблиц PolyBase.
На следующей схеме хранилище данных в реальном времени в Azure Synapse интегрировано с данными потоковой передачи в Data Lake Storage.
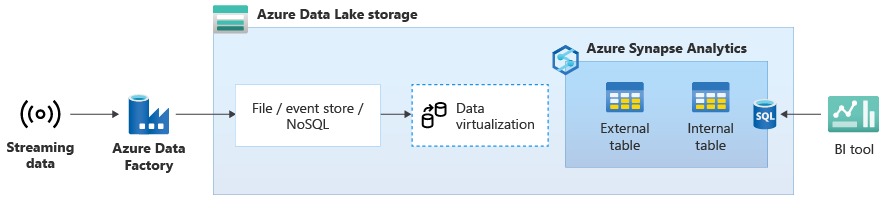
Создание логического хранилища данных с помощью PolyBase
С помощью PolyBase можно создать логическое хранилище данных для упрощения доступа пользователей к нескольким хранилищам аналитических данных. За последние несколько лет многие компании реализовали хранилища аналитических данных, оптимизированные для рабочей нагрузки, в дополнение к имеющимся хранилищам данных. Аналитические платформы в Azure включают следующие:
Data Lake Storage с записной книжкой Azure Synapse пула Spark (Spark как служба) для аналитики больших данных.
HDInsight (Hadoop как служба), также для аналитики больших данных.
Базы данных NoSQL Graph для анализа графов, которые можно выполнить в Azure Cosmos DB.
Центры событий и Stream Analytics для анализа передаваемых данных в режиме реального времени.
Кроме того, у вас могут быть аналоги этих платформ не от Майкрософт или система управления основными данными (MDM), к которой требуется доступ для получения согласованных доверенных данных о клиентах, поставщиках, продуктах, ресурсах и т. д.
Совет
PolyBase упрощает доступ к нескольким базовым хранилищам аналитических данных в Azure, чтобы упростить доступ для бизнес-пользователей.
Эти аналитические платформы появились из-за взрывного роста новых источников данных внутри и за пределами предприятия и спроса бизнес-пользователей на сбор и анализ новых данных. К новым источникам данных относятся следующие:
созданные компьютером данные, такие как данные датчиков Интернета вещей и сведения о посещениях;
созданные человеком данные, такие как данные социальных сетей, данные о просмотрах веб-сайта, сообщения электронной почты от клиентов, изображения и видео;
Другие внешние данные, такие как открытые данные государственных организаций и данные о погоде.
Эти новые данные выходят за рамки структурированных данных транзакций и основных источников данных, которые обычно питают хранилища данных и часто включают:
- частично структурированные данные, такие как JSON, XML или Avro;
- неструктурированные данные, такие как текст, голос, изображение или видео, которые сложнее обрабатывать и анализировать.
- Данные большого объема, данные с высокой скорость или и то и другое сразу.
В результате появились новые более сложные виды анализа, такие как обработка естественного языка, анализ графов, глубокое обучение, аналитика данных потоковой передачи или сложный анализ больших объемов структурированных данных. Как правило, эти виды аналитики выполняются не в хранилище данных, поэтому в появлении различных аналитических платформ для разных типов аналитических рабочих нагрузок, как показано на следующей схеме, нет ничего удивительного.
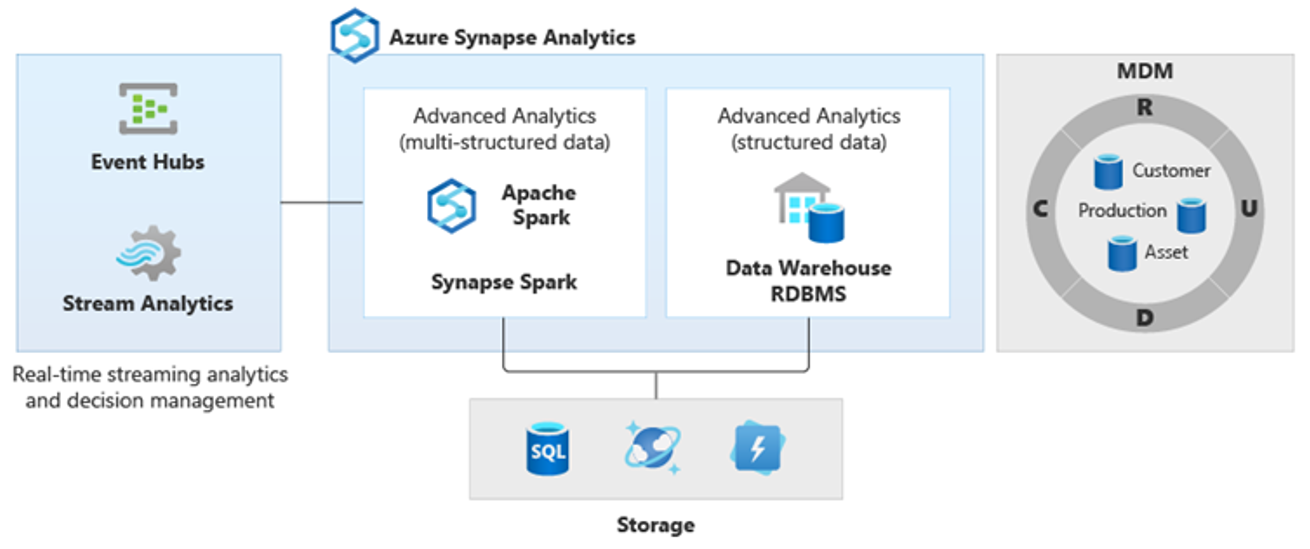
Совет
Возможность придать данным в нескольких хранилищах аналитических данных такой вид, как будто это единая система, и присоединить их к Azure Synapse называется архитектурой логического хранилища данных.
Так как эти платформы создают новые аналитические данные, возникает естественная потребность объединить новую аналитику с уже известными сведениями в Azure Synapse, что технология PolyBase делает возможным.
С помощью виртуализации данных PolyBase в Azure Synapse можно реализовать логическое хранилище данных, в котором данные Azure Synapse присоединяются к данным в других хранилищах Azure и локальных хранилищах, таких как HDInsight, Azure Cosmos DB или потоковые данные, поступающие в Data Lake Storage из Stream Analytics или Центров событий. Этот подход снижает сложность для пользователей, которые обращаются к внешним таблицам в Azure Synapse и не должны знать, что данные, к которым они обращаются, хранятся в нескольких базовых аналитических системах. На следующей схеме показана сложная структура хранилища данных, доступ к которому осуществляется с помощью сравнительно более простых, но эффективных методов пользовательского интерфейса.
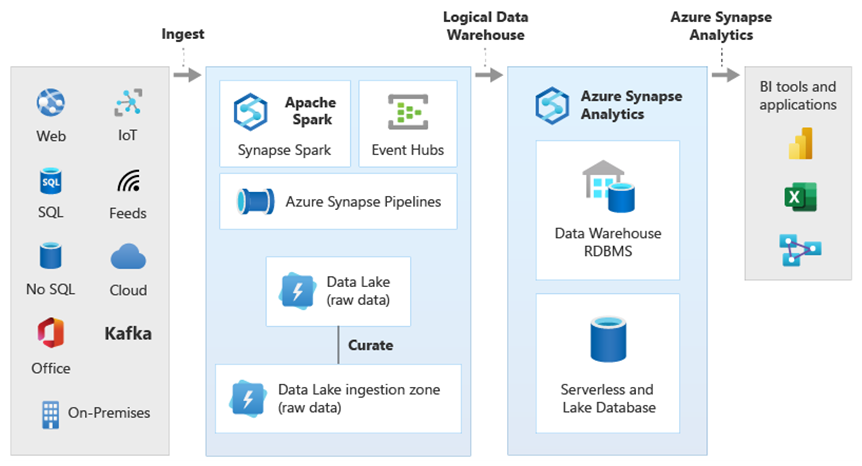
На схеме показано, как сочетать другие технологии аналитической экосистемы Майкрософт с возможностями архитектуры логического хранилища данных Azure Synapse. Например, данные можно принимать в Data Lake Storage и курировать их с помощью Фабрики данных для создания доверенных продуктов данных, представляющих логические сущности данных базы данных озера Майкрософт. Эти доверенные общепринятые данные в дальнейшем можно применять и повторно использовать в разных аналитических средах, таких как Azure Synapse, записные книжки пула Spark Azure Synapse или Azure Cosmos DB. Все аналитические сведения, созданные в этих средах, доступны на уровне виртуализации данных логического хранилища данных. Предоставляет такую возможность PolyBase.
Совет
Архитектура логического хранилища данных упрощает доступ к данным для бизнес-пользователей и повышает ценность уже известных данных в хранилище данных.
Выводы
После переноса хранилища данных в Azure Synapse можно использовать преимущества других технологий в аналитической экосистеме Майкрософт. Таким образом, вы не только модернизируете хранилище данных, но и объединяете аналитические сведения, созданные в других хранилищах аналитических данных Azure, в интегрированную аналитическую архитектуру.
Можно расширить ETL-обработку для приема в Data Lake Storage данных любого типа, а затем подготовить и интегрировать данные в большом масштабе с помощью Фабрики данных для создания доверенных, понятных для всех ресурсов данных. Эти ресурсы могут быть использованы вашим хранилищем данных и доступны специалистам по обработке и анализу данных и другим приложениям. Можно создавать аналитические конвейеры в реальном времени и аналитические конвейеры для работы в пакетном режиме, а также модели машинного обучения для выполнения в пакетном режиме, в реальном времени для обработки данных потоковой передачи и обработки данных по запросу по модели "как услуга".
Можно использовать PolyBase или COPY INTO, чтобы выйти за рамки хранилища данных и упростить доступ к аналитическим сведениям из нескольких базовых аналитических платформ в Azure. Для это создайте комплексные интегрированные представления в логическом хранилище данных, которые поддерживают доступ к потоковым данным, большим данным и традиционным аналитическим сведениям хранилища данных из инструментов и приложений бизнес-аналитики.
Перенос хранилища данных в Azure Synapse позволяет воспользоваться преимуществами богатой аналитической экосистемы Майкрософт, работающей в Azure, для повышения ценности вашей компании.
Дальнейшие действия
Сведения о переносе в выделенный пул SQL см. в статье Перенос хранилища данных в выделенный пул SQL в Azure Synapse Analytics.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по