Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Apache Spark — это платформа параллельной обработки, которая поддерживает обработку в памяти, чтобы повысить производительность приложений для анализа больших данных. Apache Spark в Azure Synapse Analytics — это одна из реализаций Apache Spark в облаке, предоставляемая корпорацией Майкрософт. Azure Synapse упрощает создание и настройку бессерверного пула Apache Spark в Azure. Пулы Spark в Azure Synapse совместимы со службой хранилища Azure и Azure Data Lake Storage 2-го поколения. Следовательно, пулы Spark можно использовать для обработки данных, хранящихся в Azure.
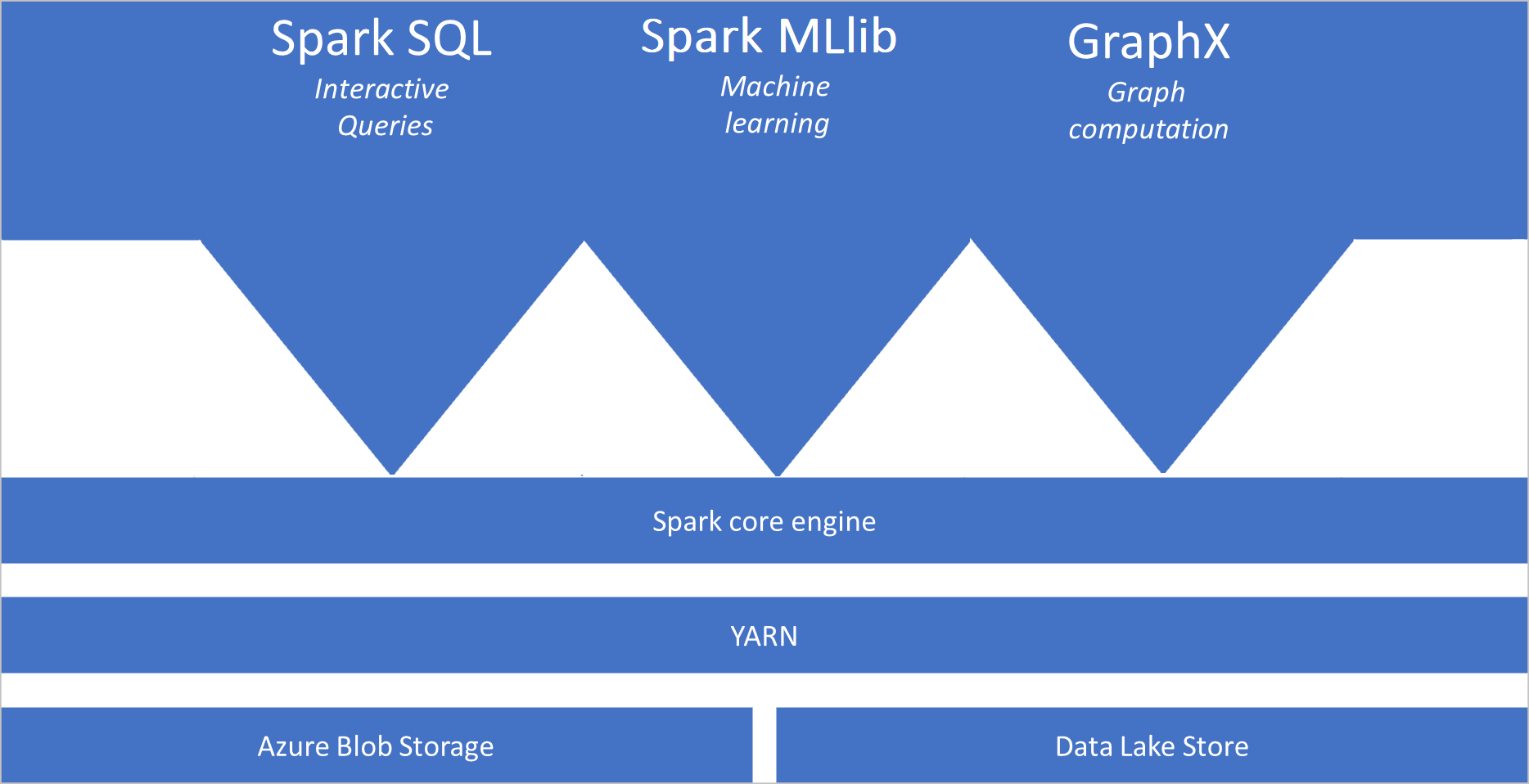
Основные сведения об Apache Spark
Apache Spark предоставляет примитивы для кластерных вычислений в памяти. Задание Spark может загрузить данные, поместить их в кэш в памяти и запрашивать их неоднократно. Вычисления в памяти быстрее, чем приложения на основе дисков. Spark также интегрируется с несколькими языками программирования, что дает возможность управлять распределенными наборами данных, такими как локальные коллекции. Нет необходимости структурировать обмен данными как операции сопоставления и редукции. Дополнительные сведения см. в видео Apache Spark для Synapse.
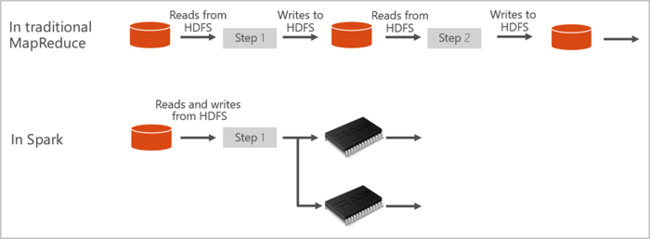
Пулы Spark в Azure Synapse предлагают полностью управляемую службу Spark. Ниже приведены преимущества создания пула Spark в Azure Synapse Analytics.
| Возможность | Description |
|---|---|
| Скорость и эффективность | Запуск экземпляров Spark для менее чем 60 узлов занимает примерно две минуты, а для более 60 узлов — около пяти минут. По умолчанию экземпляр завершает работу через 5 минут после последнего выполненного задания, если работа экземпляра не поддерживается через подключение к записной книжке. |
| Простота создания | Создание пула Spark в Azure Synapse с помощью портала Azure, Azure PowerShell или пакета SDK для .NET в Synapse Analytics занимает всего несколько минут. См. статью Начало работы с пулами Spark в Azure Synapse Analytics. |
| Простота использования | Synapse Analytics включает в себя настраиваемую записную книжку, производную от nteract. Их можно использовать для интерактивной обработки и визуализации данных. |
| Интерфейсы REST API | Spark в Azure Synapse Analytics включает в себя Apache Livy, сервер заданий Spark на основе REST API, который позволяет удаленно отправлять и отслеживать задания. |
| Поддержка Azure Data Lake Storage 2-го поколения | Пулы Spark в Azure Synapse могут использовать Azure Data Lake Storage 2-го поколения и хранилище BLOB-объектов. Дополнительные сведения о Data Lake Storage см. в разделе "Обзор Azure Data Lake Storage" |
| Интеграция со сторонними IDE | Azure Synapse предоставляет подключаемый модуль интегрированной среды разработки для IntelliJ IDEA JetBrains, который можно использовать для создания и отправки приложений в пул Spark. |
| Предварительно загруженные библиотеки Anaconda | Пулы Spark в Azure Synapse поставляются с предустановленными библиотеками Anaconda. Anaconda содержит порядка 200 библиотек для машинного обучения, анализа данных, визуализации и другие технологии. |
| Масштабируемость | В Apache Spark в пулах Azure Synapse может быть включено автомасштабирование, чтобы при необходимости масштаб пулов можно было изменить путем добавления или удаления кластера. Кроме того, завершить работу пулов Spark можно без потери данных, так как все данные хранятся в службе хранилища Azure или Data Lake Storage. |
Пулы Spark в Azure Synapse включают в себя указанные ниже компоненты, доступные в пулах по умолчанию:
- Ядро Spark. Включает в себя ядро Spark, Spark SQL, GraphX и MLlib.
- Anaconda
- Apache Livy
- Записная книжка nteract
Архитектура пула Spark
Приложения Spark выполняются как независимые наборы процессов в пуле, координируемые объектом SparkContext в основной программе, называемой программой драйвера.
SparkContext может подключаться к диспетчеру кластеров, который распределяет ресурсы между приложениями. Диспетчером кластеров является Apache Hadoop YARN. После подключения Spark получает исполнители на узлах пула. Исполнители представляют собой процессы, которые выполняют вычисления и хранят данные для приложения. Затем Spark отправляет исполнителям код приложения, определенный в JAR- или Python-файлах, переданных в SparkContext. Наконец, SparkContext отправляет исполнителям задачи для выполнения.
SparkContext выполняет основную функцию пользователя и осуществляет различные параллельные операции на узлах. Затем SparkContext собирает результаты операций. Узлы считывают данные из файловой системы и записывают их в нее. Кроме того, узлы помещают преобразованные данные в кэш в памяти как устойчивые распределенные наборы данных (RDD).
SparkContext подключается к пулу Spark и отвечает за преобразование приложения в направленный ациклический граф (DAG). Граф состоит из отдельных задач, которые выполняются в рамках процесса исполнителя в узлах. Каждое приложение получает отдельные процессы исполнителя, которые остаются активными во время выполнения приложения и обрабатывают задачи в нескольких потоках.
Варианты использования Apache Spark в Azure Synapse Analytics
Ниже представлены сценарии для использования пулов Spark в Azure Synapse Analytics.
- Инжиниринг и подготовка данных
Apache Spark предусматривает множество языковых функций для поддержки подготовки и обработки больших объемов данных, чтобы их можно было сделать более полезными, а затем использовать их в других службах Azure Synapse Analytics. Это обеспечивается с помощью нескольких языков (C#, Scala, PySpark, Spark SQL) и предоставляемых библиотек для обработки и подключения.
- Машинное обучение
В состав Apache Spark входит MLlib, библиотека машинного обучения, созданная на основе Spark, которую вы можете использовать из пула Spark в Azure Synapse Analytics. Пулы Spark в Azure Synapse Analytics также включают в себя библиотеку Anaconda, распределение Python, содержащее различные пакеты для обработки и анализа данных, в том числе для машинного обучения. В сочетании со встроенной поддержкой записных книжек вы получаете в свое распоряжение среду для создания приложений машинного обучения.
- Интеграция
Synapse Spark поддерживает структурированную потоковую передачу Spark, если вы используете поддерживаемую версию выпуска среды выполнения Azure Synapse Spark. Все задания поддерживаются в течение семи дней. Это относится как к заданиям пакетной, так и потоковой передачи, и, как правило, клиенты автоматизируют процесс перезапуска с помощью Функции Azure.
Связанный контент
Дополнительные сведения об Apache Spark в Azure Synapse Analytics см. в следующих документах:
- Краткое руководство. Создание пула Spark в Azure Synapse
- Краткое руководство. Создание записной книжки Apache Spark
- Руководство по машинному обучению с помощью Apache Spark
Примечание.
Некоторые из официальных документов по Apache Spark предполагают использование консоли Spark, которая недоступна в Spark для Azure Synapse. Вместо этого используйте интерфейсы записной книжки или IntelliJ.