Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Из этого краткого руководства вы узнаете, как создать бессерверный пул Apache Spark в Azure Synapse с помощью веб-инструментов. Затем вы узнаете, как подключиться к пулу Apache Spark и запустить запросы SQL Spark к файлам и таблицам. Apache Spark обеспечивает быструю аналитику данных и кластерные вычисления с помощью обработки в памяти. Сведения о Spark в Azure Synapse см. в статье "Обзор: Apache Spark в Azure Synapse".
Это важно
Экземпляры Spark оплачиваются пропорционально за каждую минуту, независимо от того, используете вы их или нет. Не забудьте завершить работу экземпляра Spark после его использования или задайте короткое время ожидания. Дополнительные сведения см. в разделе Очистка ресурсов этой статьи.
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Предпосылки
- Вам понадобится подписка Azure. При необходимости создайте бесплатную учетную запись Azure.
- Рабочая область Synapse Analytics
- бессерверный пул Apache Spark;
Войдите на портал Azure
Войдите на портал Azure.
Если у вас еще нет подписки Azure, создайте бесплатную учетную запись Azure, прежде чем начинать работу.
Создание записной книжки
Записная книжка — это интерактивная среда, поддерживающая различные языки программирования. Записная книжка позволяет взаимодействовать с данными, объединять код с разметкой, текстом и выполнять простые визуализации.
В представлении портала Azure для рабочей области Azure Synapse, которую вы хотите использовать, выберите "Запустить Synapse Studio".
После запуска Synapse Studio нажмите кнопку "Разработка". Затем щелкните значок "+" для добавления нового ресурса.
Оттуда выберите Записная книжка. Создается и открывается новая записная книжка с автоматически созданным именем.
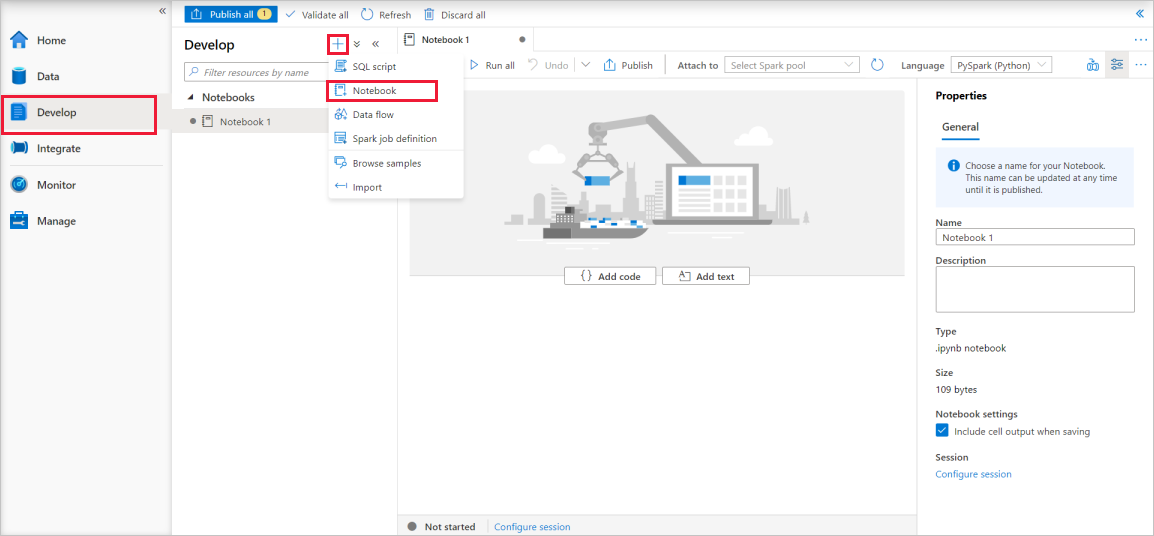
В окне "Свойства" укажите имя записной книжки.
На панели инструментов нажмите кнопку "Опубликовать".
Если в рабочей области есть только один пул Apache Spark, он выбран по умолчанию. Используйте раскрывающийся список, чтобы выбрать правильный пул Apache Spark, если он не выбран.
Нажмите кнопку "Добавить код". По умолчанию используется язык
Pyspark. Вы собираетесь использовать сочетание Pyspark и Spark SQL, поэтому выбор по умолчанию подходит. Другие поддерживаемые языки: Scala и .NET для Spark.Затем вы создадите простой объект DataFrame Spark для управления. В этом случае вы создаете его из кода. Существует три строки и три столбца:
new_rows = [('CA',22, 45000),("WA",35,65000) ,("WA",50,85000)] demo_df = spark.createDataFrame(new_rows, ['state', 'age', 'salary']) demo_df.show()Теперь запустите ячейку с помощью одного из следующих методов:
Нажмите SHIFT + ВВОД.
Нажмите на синий значок воспроизведения, расположенный слева от ячейки.
Нажмите кнопку "Запустить все " на панели инструментов.
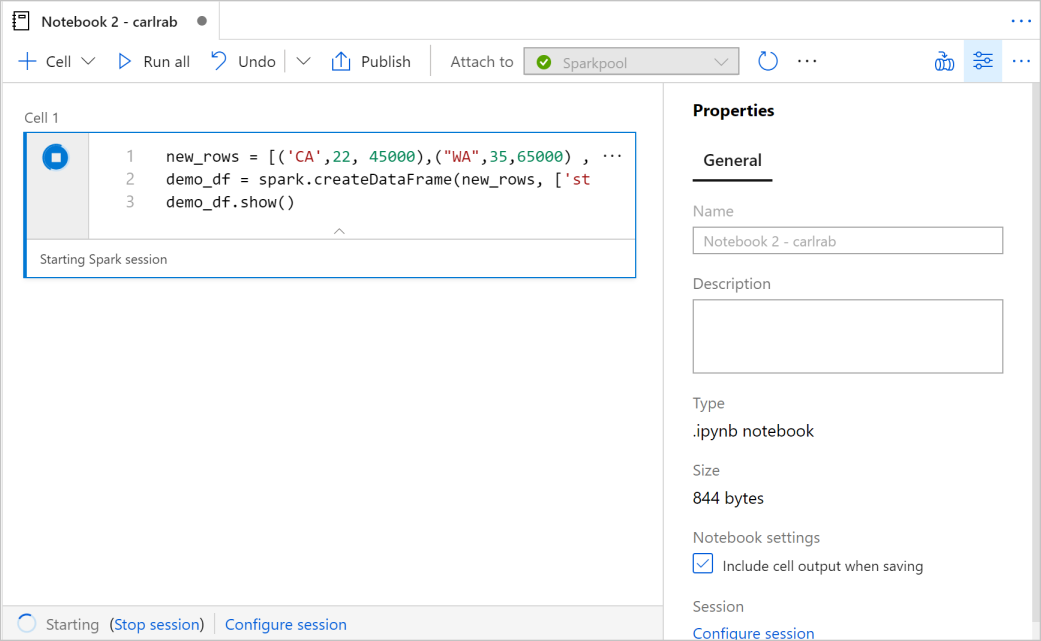
Если экземпляр пула Apache Spark еще не запущен, он автоматически запускается. Вы можете увидеть состояние экземпляра пула Apache Spark под выполняемой ячейкой, а также на панели статуса внизу записной книжки. В зависимости от размера пула, начало должно занять 2–5 минут. После завершения выполнения кода под ячейкой отображается информация о времени выполнения и ходе исполнения. В выходной ячейке отображаются выходные данные.
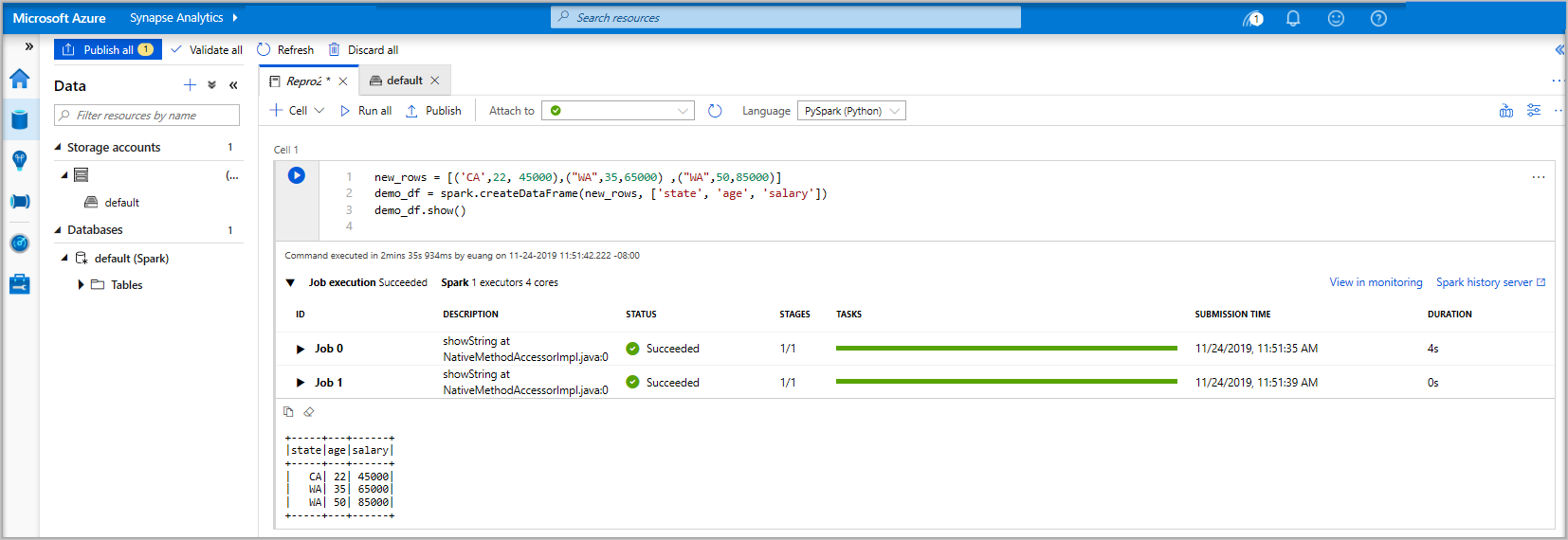
Теперь данные существуют в DataFrame, и их можно использовать различными способами. Вам потребуется использовать его в различных форматах для остальной части этого краткого руководства.
Введите приведенный ниже код в другой ячейке и запустите его, создайте таблицу Spark, CSV-файл и файл Parquet со всеми копиями данных:
demo_df.createOrReplaceTempView('demo_df') demo_df.write.csv('demo_df', mode='overwrite') demo_df.write.parquet('abfss://<<TheNameOfAStorageAccountFileSystem>>@<<TheNameOfAStorageAccount>>.dfs.core.windows.net/demodata/demo_df', mode='overwrite')Если вы используете обозреватель службы хранилища, можно увидеть влияние двух разных способов записи файла, используемого выше. Если файловая система не указана, используется значение по умолчанию.
default>user>trusted-service-user>demo_dfДанные сохраняются в расположении указанной файловой системы.Обратите внимание, что при операциях записи в форматах "csv" и "parquet" создается директория с большим количеством секционированных файлов.


Выполнение инструкций Spark SQL
Язык структурированных запросов (SQL) является наиболее распространенным и широко используемым языком для запроса и определения данных. Spark SQL работает как расширение Apache Spark для обработки структурированных данных с использованием знакомого синтаксиса SQL.
Вставьте следующий код в пустую ячейку и запустите код. Команда перечисляет таблицы в пуле данных.
%%sql SHOW TABLESПри использовании записной книжки с пулом Azure Synapse Apache Spark вы получите предустановку
sqlContext, которую можно использовать для выполнения запросов с помощью Spark SQL.%%sqlсообщает записной книжке использовать предустановкуsqlContextдля выполнения запроса. Запрос извлекает первые 10 строк из системной таблицы, которая поставляется со всеми пулами Apache Spark Azure Synapse по умолчанию.Выполните другой запрос, чтобы вывести данные из таблицы
demo_df.%%sql SELECT * FROM demo_dfКод создает две выходные ячейки, одна из которых содержит результаты данных, а другая показывает информацию о задании.
По умолчанию в представлении результатов отображается сетка. Но под сеткой есть переключатель представления, который позволяет представлению переключаться между представлениями сетки и графа.

В переключателе представления выберите диаграмму.
Выберите значок опций просмотра на самой правой стороне.
В поле "Тип диаграммы" выберите "линейчатая диаграмма".
В поле столбца оси X выберите "состояние".
В поле столбца оси Y выберите "Зарплата".
В поле агрегирования выберите "AVG".
Выберите Применить.

Вы можете получить тот же интерфейс выполнения SQL, но не переключаться на языки. Это можно сделать, заменив ячейку SQL выше этой ячейкой PySpark, выходной интерфейс совпадает с тем, что используется команда отображения :
display(spark.sql('SELECT * FROM demo_df'))Каждая из ячеек, которые ранее выполняли, имела возможность перейти к серверу журнала и мониторингу. Щелкнув ссылки, вы перейдете к различным частям пользовательского интерфейса.
Примечание.
В официальной документации Apache Spark используется консоль Spark, которая недоступна в Synapse Spark. Вместо этого используйте блокнот или IntelliJ.
Очистка ресурсов
Azure Synapse сохраняет данные в Azure Data Lake Storage. Вы можете безопасно разрешить экземпляру Spark завершить работу, если он не используется. Плата взимается за бессерверный пул Apache Spark до тех пор, пока он запущен, даже если он не используется.
Поскольку расходы на пул значительно больше, чем расходы на хранение, экономически оправдано автоматически завершать работу экземпляров Spark, когда они не используются.
Чтобы правильно завершить работу экземпляра Spark, завершите все подключенные сессии и записные книжки. Пул Apache Spark завершит работу автоматически, когда истечет указанное для него время простоя. Вы также можете выбрать конечный сеанс в строке состояния в нижней части записной книжки.
Дальнейшие действия
Из этого краткого руководства вы узнали, как создать бессерверный пул Apache Spark и запустить базовый SQL-запрос Spark.