Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Azure Synapse Analytics — это служба аналитики, которая объединяет хранилище корпоративных данных и аналитику больших данных. Эта служба позволяет вам запрашивать данные в соответствии с вашими требованиями.
Примечание.
Дополнительные сведения об Azure Synapse Analytics см. в этом видео, в котором объясняются улучшения перемещения данных.
Компоненты архитектуры Synapse SQL
Специализированный пул SQL (ранее — Хранилище данных SQL) использует архитектуру с горизонтальным масштабированием для распределения вычислительной обработки данных на нескольких узлах. Единица масштабирования представляет собой абстракцию вычислительной мощности, известную как единица использования хранилища данных. Вычислительные ресурсы отделены от ресурсов хранилища. Это позволяет масштабировать вычислительные ресурсы независимо от данных в системе.
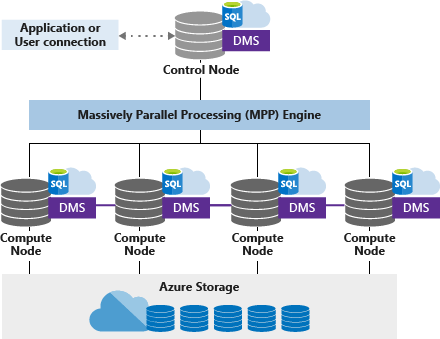
Выделенный пул SQL (ранее — Хранилище данных SQL) использует архитектуру на базе узлов. Приложения подключаются к управляющему узлу и выполняют команды T-SQL. На управляющем узле размещена подсистема обработки распределенных запросов, которая оптимизирует запросы для параллельной обработки, а затем перенаправляет операции на вычислительные узлы, чтобы обеспечить параллельную работу.
Вычислительные узлы хранят все данные пользователей в службе хранилища Azure и выполняют параллельные запросы. Служба перемещения данных (DMS) представляет собой внутреннюю службу на уровне системы, которая перемещает данные между узлами, что необходимо для выполнения параллельных запросов и возвращения точных результатов.
Благодаря отделению ресурсов хранилища от вычислительных ресурсов использование выделенного пула SQL (ранее — Хранилище данных SQL) обеспечивает следующие возможности:
- Определите объем вычислительных ресурсов независимо от потребностей в хранилище.
- увеличение или уменьшение вычислительной мощности в выделенном пуле SQL (ранее — Хранилище данных SQL) без перемещения данных;
- приостановка вычислений без изменения данных (вы платите только за хранилище);
- Возобновление вычислительных мощностей в рабочие часы.
Хранилище Azure
В выделенном пуле SQL (ранее — Хранилище данных SQL) используется служба хранилища Azure для безопасного хранения данных пользователя. Так как ваши данные хранятся в службе хранилища Azure и управляются ею, предусмотрена отдельная плата за использование хранилища. Для оптимизации производительности системы данные сегментированы по областям распределения. При определении таблицы вы можете выбрать шаблон сегментирования, который будет использоваться для распределения данных. Поддерживаются следующие шаблоны сегментирования:
- хеш
- Циклический раунд
- Копировать
Управляющий узел
Управляющий узел является ключевым элементом архитектуры. Это внешний интерфейс, который взаимодействует со всеми приложениями и подключениями. Подсистема обработки распределенных запросов запускается на управляющем узле, чтобы оптимизировать и координировать параллельные запросы. При отправке запроса T-SQL управляющий узел преобразует его в запросы, которые будут выполняться на каждом вычислительном узле в параллельном режиме.
Вычислительные узлы
Вычислительные узлы обеспечивают вычислительную мощность. Дистрибутивы сопоставляются с вычислительными узлами для обработки. Когда вы оплачиваете увеличение вычислительных ресурсов, распределения повторно сопоставляются с доступными вычислительными узлами. Число вычислительных узлов колеблется от 1 до 60 и определяется уровнем обслуживания Synapse SQL.
У каждого вычислительного узла есть идентификатор узла, который видно в представлениях системы. Идентификатор вычислительного узла можно увидеть в столбце node_id в системных представлениях, имена которых начинаются с sys.pdw_nodes. Список системных представлений см. в системном представлении Synapse SQL.
Служба перемещения данных
Служба перемещения данных (DMS) — это технология перемещения данных, которая координирует перемещение данных между вычислительными узлами. Некоторым запросам требуется перемещение данных, чтобы параллельные запросы вернули точные результаты. При необходимости перемещения данных DMS гарантирует, что нужные данные окажутся в нужном расположении.
Распределения
Распределение представляет собой базовую единицу хранения и обработки параллельных запросов, выполняемых для распределенных данных. При выполнении запроса в Synapse SQL формируются 60 небольших запросов, которые выполняются параллельно.
Каждый из этих 60 небольших запросов выполняется в одном из распределений данных. Каждый вычислительный узел управляет одним или несколькими из 60 распределений. Выделенный пул SQL (ранее — Хранилище данных SQL) с максимальным количеством вычислительных ресурсов содержит одно распределение на каждом вычислительном узле. Выделенный пул SQL (ранее — Хранилище данных SQL) с минимальным количеством вычислительных ресурсов содержит все распределения на каждом вычислительном узле.
Примечание.
Рекомендации по оптимальной стратегии распределения таблиц для использования на основе рабочих нагрузок см. в разделе Помощник по распределению Azure Synapse SQL.
Таблицы с хэш-распределением
С помощью распределенной хэш-таблицы можно обеспечить наибольшую производительность запроса для операций объединения и агрегирования для больших таблиц.
Чтобы сегментировать данные в распределенную хэш-таблицу, используется хэш-функция для детерминированного назначения каждой строки отдельному распределению. В определении таблицы один из столбцов определяется как столбец распределения. Хэш-функция использует значения в столбце распределения для присвоения каждой строки распределению.
На следующей схеме показано, как полная (недистрибуционная таблица) сохраняется в виде хэш-распределенной таблицы.

- Каждая строка относится к одному распределению.
- Детерминированный хэш-алгоритм присваивает каждую строку одному распределению.
- Количество строк таблицы в распределении зависит от размеров таблиц (как показано на схеме).
Существуют влияющие на производительность факторы, которые учитываются при выборе столбца распределения. Например, определенность, неравномерное смещение данных и типы запросов, выполняемых в системе.
Таблицы с циклическим распределением
Циклическая таблица — это самая простая таблица для создания и обеспечения быстрой работы, если её использовать как промежуточную таблицу для загрузок.
В таблице с распределением методом циклического распределения данные распределяются равномерно, но без дальнейшей оптимизации. Распределение сначала выбирается случайным образом, а затем буферы строк назначаются распределениям последовательно. Вы можете быстро загрузить данные в таблицу с распределением методом циклического перебора, но производительность запроса будет лучше, если использовать распределенные хэш-таблицы. Для объединения таблиц с распределением методом циклического перебора требуется перегруппировка данных, что требует дополнительного времени.
Реплицированные таблицы
Реплицированная таблица обеспечивает наилучшую производительность запросов для небольших таблиц.
Полная копия реплицированной таблицы помещается в кэш на каждом вычислительном узле. В результате репликация таблицы устраняет необходимость передавать данные между вычислительными узлами перед операциями соединения или агрегирования. Наилучшее применение реплицированных таблиц – это использование их для небольших таблиц. При записи данных требуются дополнительное хранилище и дополнительные расходы, что делает использование больших таблиц нецелесообразным.
На следующей схеме представлена реплицированная таблица, которая кэшируется при первом распределении на каждом вычислительном узле.

Связанный контент
Теперь, когда вы немного ознакомились с Azure Synapse, узнайте о том, как быстро создать выделенный пул SQL (ранее — Хранилище данных SQL) и загрузить примеры данных. Если вы не знакомы с Azure, вам могут быть полезны основные понятия Azure, когда вы столкнетесь с новой терминологией. Или ознакомьтесь со следующими ресурсами, посвященными Azure Synapse.