Использование внешних таблиц в Synapse SQL
Внешняя таблица указывает на данные, расположенные в Hadoop, большом двоичном объекте в службе хранилища Azure или Azure Data Lake Storage. Внешние таблицы можно использовать для чтения данных из файлов или записи данных в файлы в служба хранилища Azure.
В Synapse SQL внешние таблицы можно использовать для чтения внешних данных с помощью выделенного пула SQL или бессерверного пула SQL.
В зависимости от типа внешнего источника данных можно использовать два типа внешних таблиц:
- Внешние таблицы Hadoop, которые можно использовать для чтения и экспорта данных в различных форматах данных, таких как CSV, Parquet и ORC. Внешние таблицы Hadoop доступны в выделенных пулах SQL, но недоступны в бессерверных пулах SQL.
- Собственные внешние таблицы, которые можно использовать для чтения и экспорта данных в различных форматах данных, таких как CSV и Parquet. Собственные внешние таблицы доступны в бессерверных пулах SQL. Они предоставляются в общедоступной предварительной версии в выделенных пулах SQL. Запись и экспорт данных с помощью CETAS и собственных внешних таблиц доступна только в бессерверном пуле SQL, но не в выделенных пулах SQL.
Основные различия между Hadoop и собственными внешними таблицами:
| Тип внешней таблицы | Hadoop | Нативный |
|---|---|---|
| Выделенный пул SQL | Доступен | Таблицы Parquet предоставляются только в общедоступной предварительной версии. |
| Бессерверный пул SQL | Недоступно | На месте |
| Поддерживаемые форматы | С разделителями/CSV, Parquet, ORC, Hive RC и RC | Бессерверный пул SQL: с разделителями/CSV, Parquet и Delta Lake Выделенный пул SQL: Parquet (предварительная версия) |
| Устранение секций папок | Нет | Функция удаления разделов доступна только в секционированных таблицах, созданных в форматах Parquet или CSV, которые синхронизируются из пулов Apache Spark. Вы можете создавать внешние таблицы в секционированных папках Parquet, но столбцы секционирования недоступны и игнорируются, а исключение секционирования не будет применено. Не создавайте внешние таблицы в папках Delta Lake, так как они не поддерживаются. Используйте разностные секционированные представления, если необходимо запросить секционированные данные Delta Lake. |
| Исключение файлов (включение предиката) | Нет | Да в бессерверном пуле SQL. Для включения строк необходимо использовать параметры сортировки Latin1_General_100_BIN2_UTF8для столбцовVARCHAR. Дополнительные сведения о параметрах сортировки см . в типах сортировки, поддерживаемых для Synapse SQL. |
| Пользовательский формат расположения | Нет | Да, можно использовать подстановочные знаки, например /year=*/month=*/day=*, для форматов Parquet или CSV. Пути к пользовательским папкам недоступны в Delta Lake. В бессерверном пуле SQL можно также использовать рекурсивные дикие карта ы /logs/** для ссылки на файлы Parquet или CSV в любой вложенной папке под указанной папкой. |
| Рекурсивное сканирование папок | Да | Да. В бессерверных пулах SQL необходимо указывать /** в конце пути к расположению. В выделенном пуле папки всегда сканируются рекурсивно. |
| Проверка подлинности хранилища | служба хранилища ключ доступа (SAK), сквозное руководство Microsoft Entra, управляемое удостоверение, пользовательское удостоверение Microsoft Entra | Подписанный URL-адрес (SAS), сквозное руководство Microsoft Entra, управляемое удостоверение, пользовательское приложение Microsoft Entra identity. |
| Сопоставление столбцов | По порядку: столбцы в определении внешней таблицы сопоставляются со столбцами в базовых файлах Parquet по позиции. | Бессерверный пул: по имени. Столбцы в определении внешней таблицы сопоставляются со столбцами в базовых файлах Parquet по имени столбца. Выделенный пул: по порядку. Столбцы в определении внешней таблицы сопоставляются со столбцами в базовых файлах Parquet по позиции. |
| CETAS (экспорт и преобразование) | Да | CETAS с собственными таблицами в качестве целевого объекта работает только в бессерверном пуле SQL. Выделенные пулы SQL нельзя использовать для экспорта данных с помощью собственных таблиц. |
Примечание.
Встроенные внешние таблицы — это рекомендуемое решение в пулах, где они общедоступны. Если необходим доступ к внешним данным, всегда используйте собственные таблицы в бессерверных пулах. В выделенных пулах собственные таблицы следует использовать для чтения файлов Parquet (после их выпуска в общедоступной версии). Используйте таблицы Hadoop, только если вам необходим доступ к некоторым типам, которые не поддерживаются в собственных внешних таблицах (например, ORC, RC) или если собственная версия недоступна.
Внешние таблицы в выделенном пуле SQL и бессерверном пуле SQL
Внешние таблицы можно использовать в следующих целях:
- Запрос по данным в хранилище BLOB-объектов Azure и Azure Data Lake Storage 2-го поколения с использованием инструкций Transact-SQL.
- Сохраните результаты запросов в файлах в Хранилище BLOB-объектов Azure или Azure Data Lake Storage с помощью CETAS.
- Импортируйте данные из хранилища BLOB-объектов Azure и Azure Data Lake Storage и храните их в выделенном пуле SQL (только таблицы Hadoop в выделенном пуле).
Примечание.
При использовании в сочетании с инструкцией CREATE TABLE AS SELECT выбранные из внешней таблицы данные импортируются в таблицу в выделенном пуле SQL.
Если производительность внешних таблиц Hadoop в выделенных пулах не соответствует вашим требованиям, вы можете загружать внешние данные в таблицы хранилища данных с помощью инструкции COPY.
Учебник по загрузке данных см. в статье Загрузка данных из хранилища BLOB-объектов Azure в хранилище данных SQL Azure с помощью PolyBase.
Вы можете создать внешние таблицы в пулах Synapse SQL, выполнив следующие действия:
- СОЗДАТЬ ВНЕШНИЙ ИСТОЧНИК ДАННЫХ для ссылки на внешнее хранилище Azure и указать учетные данные, которые следует использовать для доступа к хранилищу.
- СОЗДАТЬ ВНЕШНИЙ ФОРМАТ ФАЙЛА для описания формата файлов CSV или Parquet.
- СОЗДАТЬ ВНЕШНЮЮ ТАБЛИЦУ поверх файлов, размещенных в источнике данных с таким же форматом файлов.
Устранение секций папок
Собственные внешние таблицы в пулах Synapse могут игнорировать файлы в папках, не относящихся к запросам. Если файлы хранятся в иерархии папок (например, — /year=2020/month=03/day=16) и значения для year, monthа day также предоставляются в виде столбцов, запросы, содержащие фильтры, например year=2020 , считывают файлы только из вложенных папок, размещенных в папке year=2020 . Файлы и папки, помещенные в другие папки (year=2021 или year=2022) будут игнорироваться в этом запросе. Такое исключение называется исключением секций.
Исключение секций папок доступно в собственных внешних таблицах, которые синхронизируются из пулов Synapse Spark. Если у вас есть секционированный набор данных и вы хотите использовать исключение секций с внешними таблицами, которые вы создали, используйте вместо внешних таблиц секционированные представления.
Исключение файлов
Некоторые форматы данных, такие как Parquet и Delta, содержат статистику файлов для каждого столбца (например, значения минимума и максимума для каждого столбца). Запросы, которые фильтруют данные, не считывают файлы, в которых отсутствуют значения обязательных столбцов. Сначала запрос анализирует значения минимума и максимума для столбцов, используемых в предикате запроса, чтобы найти файлы, которые не содержат обязательных данных. Эти файлы будут проигнорированы и исключены из плана запроса.
Этот метод также называется включением предиката фильтра и позволяет повысить производительность запросов. Включение фильтра доступно на бессерверных пулах SQL в форматах Parquet и Delta. Чтобы задействовать включение фильтра для строковых типов, используйте тип VARCHAR с параметрами сортировки Latin1_General_100_BIN2_UTF8. Дополнительные сведения о параметрах сортировки см . в типах сортировки, поддерживаемых для Synapse SQL.
Безопасность
У пользователя должно быть разрешение SELECT на внешнюю таблицу для чтения данных.
Внешние таблицы получают доступ к базовому хранилищу Azure с использованием учетных данных в области базы данных, определенных в источнике данных, с использованием следующих правил:
- Источник данных без учетных данных позволяет внешним таблицам получать доступ к общедоступным файлам в службе хранилища Azure.
- Источник данных может иметь учетные данные, которые позволяют внешним таблицам получать доступ только к файлам в хранилище Azure с использованием маркера SAS или управляемой идентификации рабочей области. Примеры см. в статье Разработка управления доступом к хранилищу файлов хранилища.
Пример инструкции CREATE EXTERNAL DATA SOURCE
Следующий пример создает внешний источник данных Hadoop в выделенном пуле SQL для Azure Data Lake 2-го поколения, который указывает на набор данных New York:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2018-03-28&ss=bf&srt=sco&sp=rl&st=2019-10-14T12%3A10%3A25Z&se=2061-12-31T12%3A10%3A00Z&sig=KlSU2ullCscyTS0An0nozEpo4tO5JAgGBvw%2FJX2lguw%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
В следующем примере создается внешний источник данных для Azure Data Lake 2-го поколения, который указывает на общедоступный набор данных New York.
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
Пример инструкции CREATE EXTERNAL FILE FORMAT
В следующем примере создается формат внешнего файла для данных о переписи населения:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Пример инструкции CREATE EXTERNAL TABLE
В следующем примере создается внешняя таблица. Далее возвращается ее первая строка.
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
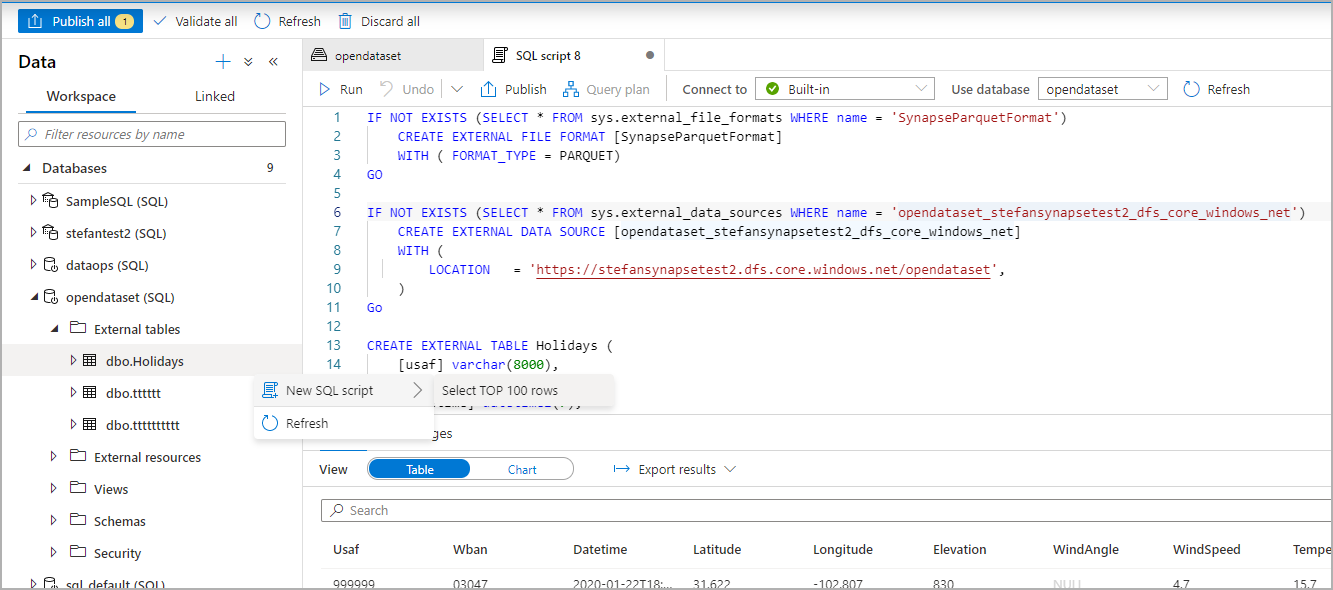
Создание внешних таблиц из файла в Azure Data Lake и запросы по ним
Используя возможности просмотра Data Lake в Synapse Studio, вы можете создавать внешнюю таблицу и выполнять запросы к ней через пул Synapse SQL, просто щелкнув файл правой кнопкой мыши. Создание внешних таблиц одним щелчком в учетной записи хранения ADLS 2-го поколения поддерживается только для файлов Parquet.
Необходимые компоненты
У вас должен быть доступ к рабочей области с по крайней мере
Storage Blob Data Contributorролью доступа к учетной записи ADLS 2-го поколения или спискам контроль доступа,которые позволяют запрашивать файлы.Для создания внешней таблицы и запроса внешних таблиц в пуле Synapse SQL (выделенных или бессерверных) необходимо иметь по крайней мере разрешения.
На панели "Данные" выберите файл, из которого нужно создать внешнюю таблицу.
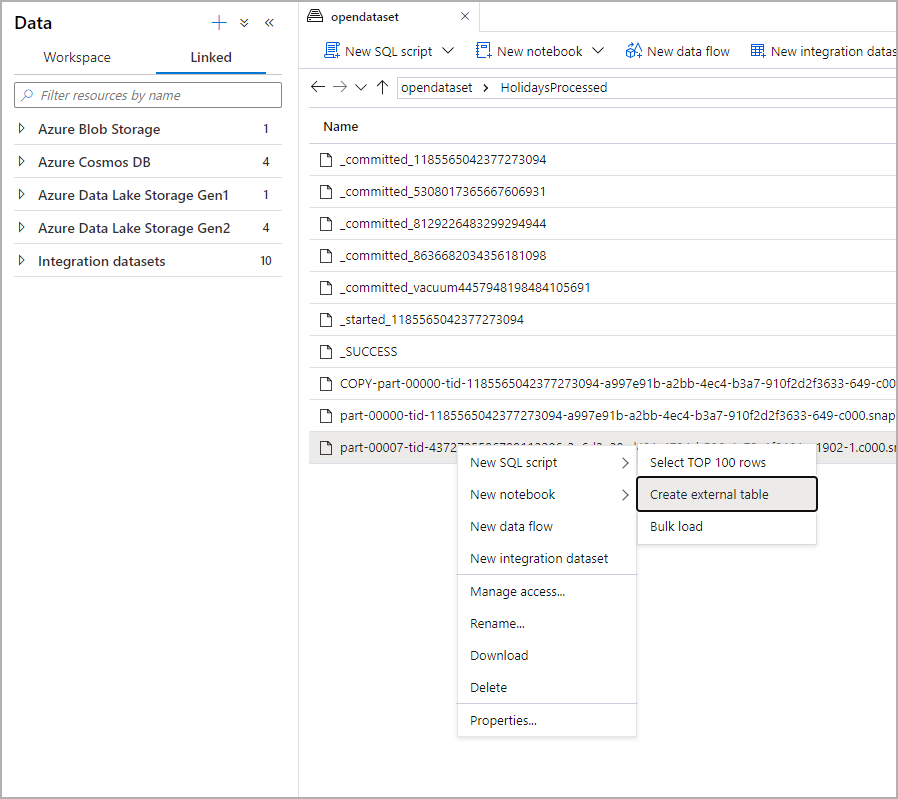
Откроется диалоговое окно. Выберите выделенный или бессерверный пул SQL, присвойте таблице имя и щелкните "Открыть скрипт"
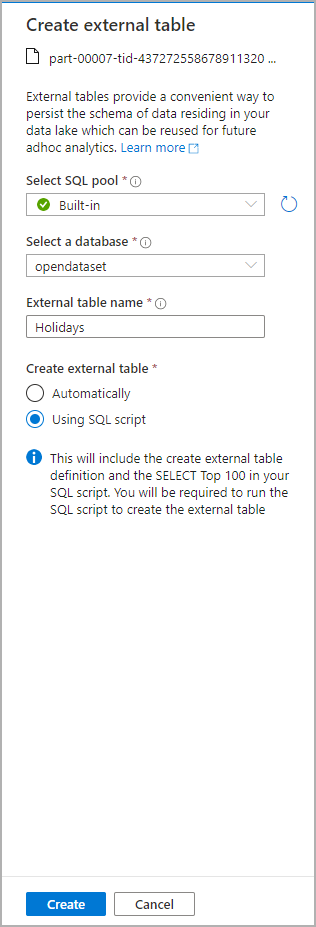
Автоматически создается скрипт SQL на основании схемы, определенной по файлу.
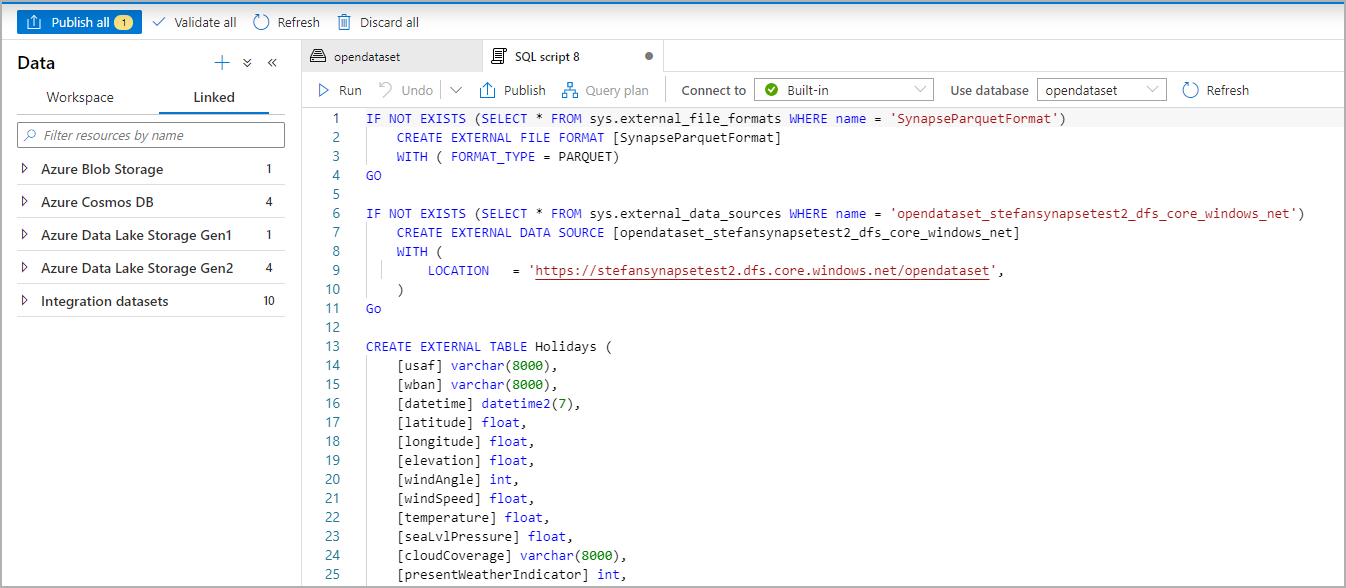
Выполните скрипт. Этот скрипт автоматически выполняет инструкцию SELECT Top 100 *.
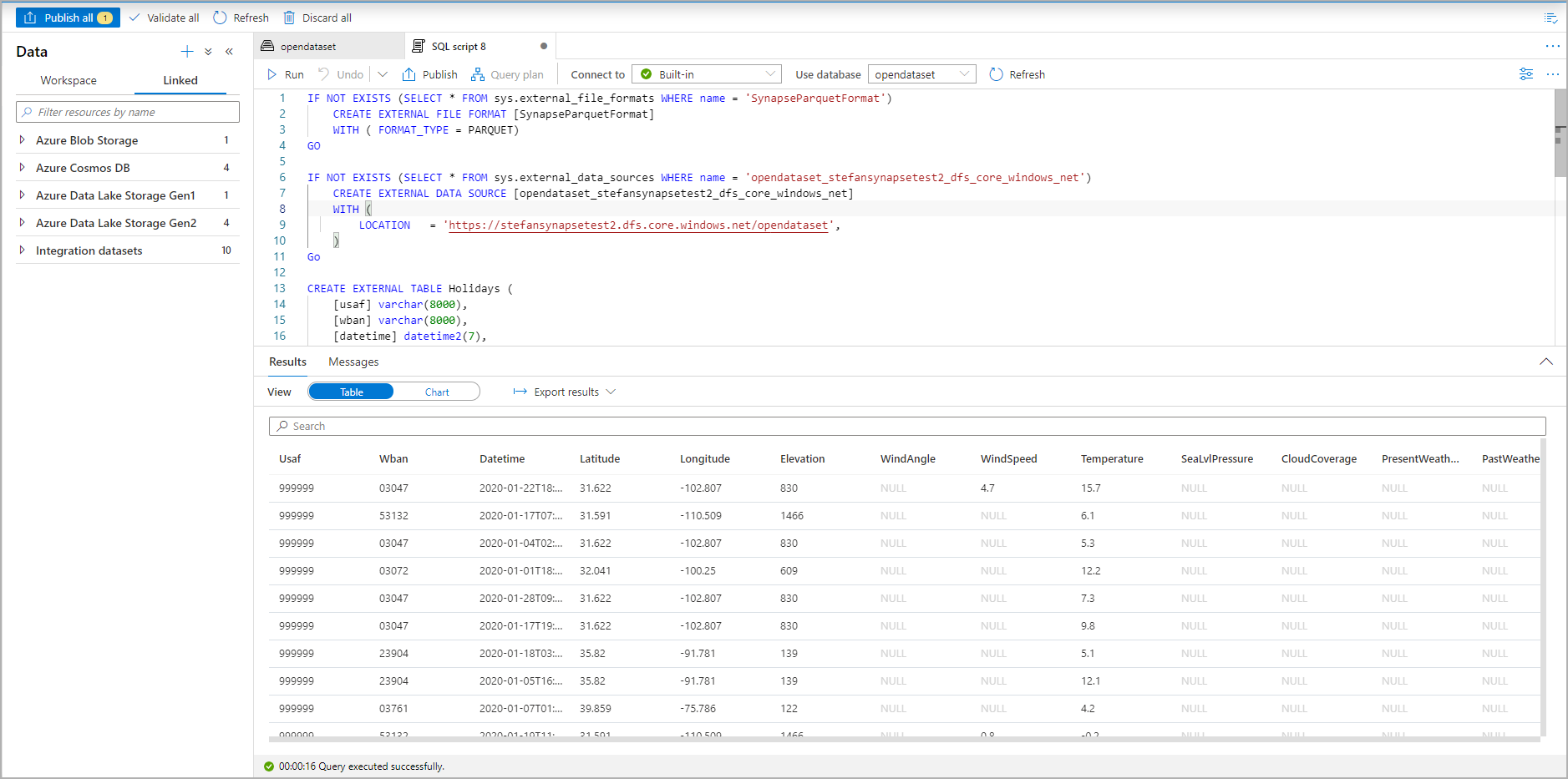
Теперь создается внешняя таблица для последующего изучения ее содержимого, для которого пользователь может выполнять запросы непосредственно на панели данных.
Следующие шаги
См. статью CETAS , чтобы узнать, как сохранить результаты запроса во внешней таблице в хранилище Azure. Вы также можете начать работать с запросами ко внешним таблицам Apache Spark для Azure Synapse.