Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Tip
Microsoft Fabric Data Warehouse — это реляционное хранилище корпоративного масштаба на основе озера данных, с архитектурой, готовой к будущему, встроенной ИИ и новыми функциями. Если вы не знакомы с хранилищем данных, начните с Fabric Data Warehouse. Существующие рабочие нагрузки выделенного пула SQL могут обновляться до Fabric для доступа к новым возможностям в области науки о данных, аналитики в реальном времени и отчетности.
В этом разделе описано, как создавать и использовать представления для упаковки бессерверных запросов пула SQL. Представления позволяют повторно использовать эти запросы. Представления также необходимы, если вы хотите использовать такие средства, как Power BI, в сочетании с бессерверным пулом SQL.
Prerequisites
Первым шагом является создание базы данных, в которой будет создано представление и инициализировать объекты, необходимые для проверки подлинности в хранилище Azure путем выполнения скрипта setup в этой базе данных. Все запросы в этой статье будут выполняться в вашей образце базы данных.
Обзор внешних данных
Вы можете создавать представления так же, как и обычные SQL Server представления. Следующий запрос создает представление, которое считывает population.csv файл.
Примечание
Измените первую строку в запросе, т. е. [mydbname], поэтому вы используете созданную базу данных.
USE [mydbname];
GO
DROP VIEW IF EXISTS populationView;
GO
CREATE VIEW populationView AS
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r];
В представлении используется EXTERNAL DATA SOURCE с корневым URL-адресом вашего хранилища как DATA_SOURCE, и к файлам добавляется относительный путь.
Представления Delta Lake
Если вы создаете представления в верхней части папки Delta Lake, необходимо указать расположение корневой папки после BULK параметра вместо указания пути к файлу.
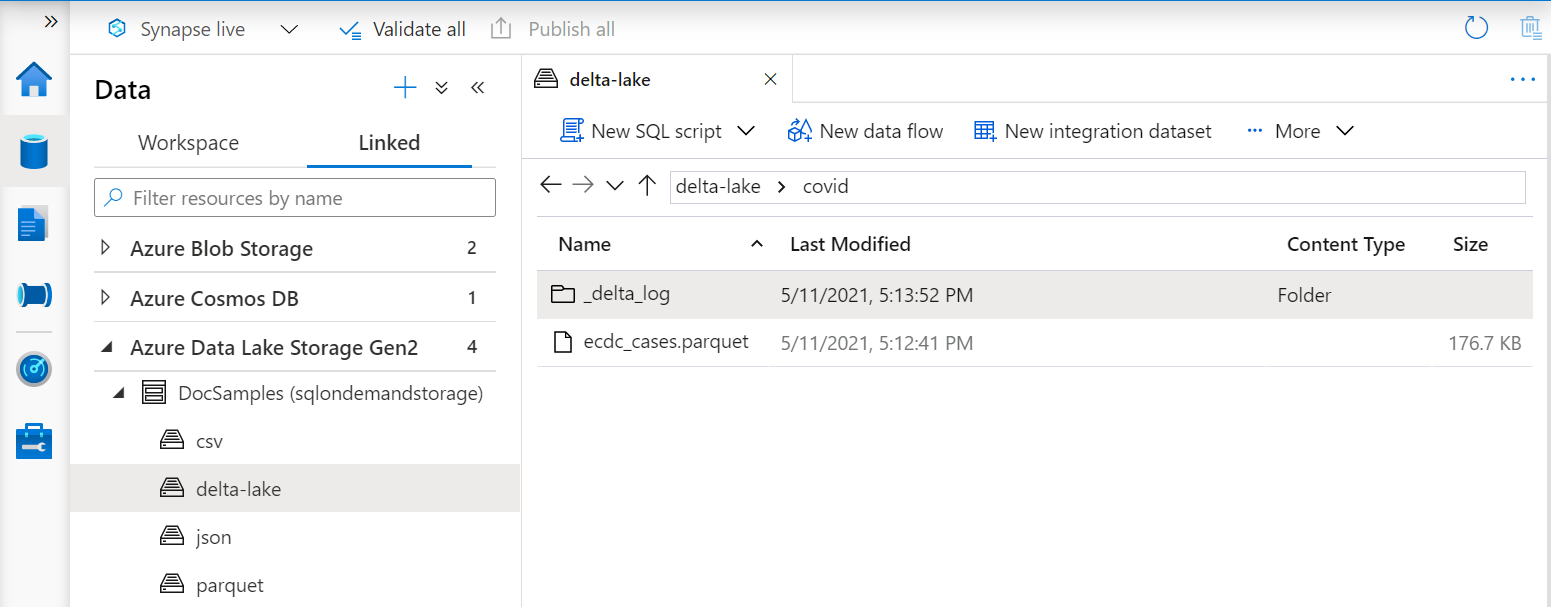
Функция OPENROWSET , считывающая данные из папки Delta Lake, проверяет структуру папок и автоматически определяет расположения файлов.
create or alter view CovidDeltaLake
as
select *
from openrowset(
bulk 'covid',
data_source = 'DeltaLakeStorage',
format = 'delta'
) with (
date_rep date,
cases int,
geo_id varchar(6)
) as rows
Дополнительные сведения см. на странице самообслуживания бессерверного пула Synapse SQL и на странице известных проблем Azure Synapse Analytics.
Секционированные представления
Если у вас есть набор файлов, секционированных в иерархической структуре папок, можно описать шаблон секции с помощью подстановочных знаков в пути к файлу. Используйте функцию FILEPATH для предоставления частей пути к папке в качестве столбцов секционирования.
CREATE VIEW TaxiView
AS SELECT *, nyc.filepath(1) AS [year], nyc.filepath(2) AS [month]
FROM
OPENROWSET(
BULK 'parquet/taxi/year=*/month=*/*.parquet',
DATA_SOURCE = 'sqlondemanddemo',
FORMAT='PARQUET'
) AS nyc
Секционированные представления могут повысить производительность запросов, выполняя исключение секций при запросе с фильтрами в столбцах секционирования. Однако не все запросы поддерживают ликвидацию секций, поэтому важно следовать некоторым рекомендациям.
Чтобы обеспечить ликвидацию секций, избегайте использования вложенных запросов в фильтрах, так как они могут препятствовать устранению секций. Вместо этого передайте результат вложенного запроса в качестве переменной в фильтр.
При использовании JOIN в запросах SQL объявите предикат фильтра как NVARCHAR, чтобы уменьшить сложность плана запроса и увеличить вероятность правильного устранения раздела. Столбцы секционирования обычно выводятся как NVARCHAR(1024), поэтому использование того же типа для предиката позволяет избежать необходимости неявного приведения, что может повысить сложность плана запросов.
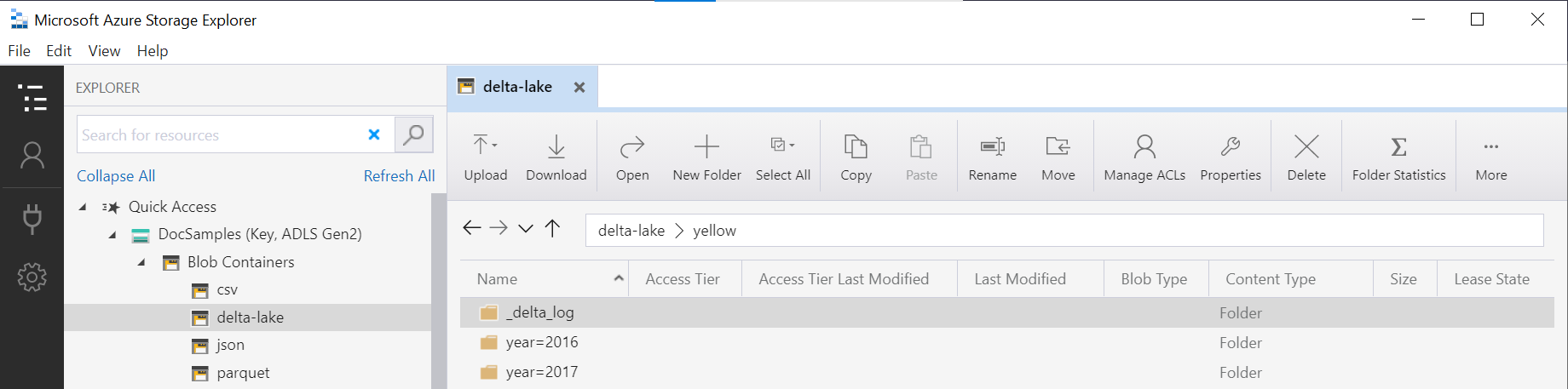
Секционированные представления Delta Lake
Если вы создаете секционированные представления поверх delta Lake storage, можно указать только корневую папку Delta Lake и явно не предоставлять столбцы секционирования с помощью FILEPATH функции:
CREATE OR ALTER VIEW YellowTaxiView
AS SELECT *
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
Функция OPENROWSET проверяет структуру базовой папки Delta Lake и автоматически определяет и предоставляет столбцы секционирования. Исключение секций будет выполнено автоматически, если столбец секционирования помещается в WHERE клаузулу запроса.
Имя папки в функции OPENROWSET, сцепленное с yellow в этом примере, URI, определенным в источнике данных LOCATIONDeltaLakeStorage, должно ссылаться на корневую папку Delta Lake, содержащую подпапку, называемую _delta_log.
Для получения дополнительной информации см. страницу самопомощи безсерверного пула SQL Synapse и раздел известных проблем Azure Synapse Analytics.
Представления JSON
Представления являются хорошим выбором, если необходимо выполнить дополнительную обработку над результирующим набором, который извлекается из файлов. Одним из примеров может быть синтаксический анализ JSON-файлов, в которых необходимо применить функции JSON для извлечения значений из документов JSON:
CREATE OR ALTER VIEW CovidCases
AS
select
*
from openrowset(
bulk 'latest/ecdc_cases.jsonl',
data_source = 'covid',
format = 'csv',
fieldterminator ='0x0b',
fieldquote = '0x0b'
) with (doc nvarchar(max)) as rows
cross apply openjson (doc)
with ( date_rep datetime2,
cases int,
fatal int '$.deaths',
country varchar(100) '$.countries_and_territories')
Функция OPENJSON анализирует каждую строку из JSONL-файла, содержащего один документ JSON на строку в текстовом формате.
представления Azure Cosmos DB на контейнерах
Представления можно создать поверх контейнеров Azure Cosmos DB, если Azure Cosmos DB аналитическое хранилище включено в контейнере. Имя учетной записи, имя базы данных и имя контейнера Azure Cosmos DB должно быть добавлено как часть представления, а ключ доступа только для чтения должен быть помещен в учетные данные базы данных, на которые ссылается представление.
В этом примере скрипта используется база данных и контейнер, которые можно настроить, выполнив следующие инструкции.
Важно
В скрипте замените эти значения собственными значениями:
- your-cosmosdb — имя учетной записи Cosmos DB
- ключ доступа — ключ учетной записи Cosmos DB
CREATE DATABASE SCOPED CREDENTIAL MyCosmosDbAccountCredential
WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = 'access-key';
GO
CREATE OR ALTER VIEW Ecdc
AS SELECT *
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=your-cosmosdb;Database=covid',
OBJECT = 'Ecdc',
CREDENTIAL = 'MyCosmosDbAccountCredential'
) with ( date_rep varchar(20), cases bigint, geo_id varchar(6) ) as rows
Для получения дополнительной информации см. раздел Запрос данных из Azure Cosmos DB с использованием бессерверного пула SQL в Azure Synapse Link.
Используйте представление
Вы можете использовать представления в своих запросах так же, как вы используете представления в запросах SQL Server.
Следующий запрос демонстрирует использование представления population_csv, которое мы создали в разделе Создание представления. Он возвращает имена стран и регионов с их населением в 2019 году в порядке убывания.
Примечание
Измените первую строку в запросе, т. е. [mydbname], поэтому вы используете созданную базу данных.
USE [mydbname];
GO
SELECT
country_name, population
FROM populationView
WHERE
[year] = 2019
ORDER BY
[population] DESC;
При запросе представления могут возникнуть ошибки или непредвиденные результаты. Это, вероятно, означает, что представление ссылается на столбцы или объекты, которые были изменены или больше не существуют. Необходимо вручную настроить определение представления, чтобы выровнять изменения базовой схемы.
Связанный контент
Дополнительные сведения о том, как запрашивать различные типы файлов, см. в статьях о запросах к одному CSV-файлу, файлам Parquet и файлам JSON запроса .