Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом разделе описывается базовый двоичный интерфейс приложения (ABI) для x64, 64-разрядное расширение архитектуры x86. В ней рассматриваются такие темы, как соглашение о вызовах, макет типов, стек и регистрация использования и многое другое.
Соглашения о вызовах x64
Два важных различия между x86 и x64:
- 64-разрядная возможность адресации
- Шестнадцать 64-разрядных регистров для общего использования.
Учитывая развернутый набор регистров, x64 использует __fastcall соглашение о вызовах и модель обработки исключений на основе RISC.
Соглашение __fastcall использует регистры для первых четырех аргументов и кадр стека для передачи дополнительных аргументов. Подробные сведения о соглашении о вызовах x64, в том числе об использовании регистров, параметрах стека, возвращаемых значениях и раскрутке стека, см. в статье Соглашение о вызовах x64.
Дополнительные сведения о соглашении __vectorcall о вызовах см. в статье __vectorcall.
Включение оптимизации компилятора x64
Следующий параметр компилятора позволяет оптимизировать приложение для архитектуры x64:
Тип x64 и макет хранилища
В этом разделе описывается хранилище типов данных для архитектуры x64.
Скалярные типы
Хотя можно получить доступ к данным с любым выравниванием, рекомендуется выравнивать данные по их естественной границе или по кратному от нее, чтобы избежать потери производительности. Перечисления — это целочисленные константы, которые обрабатываются как 32-разрядные целые числа. Следующая таблица описывает определение типов и рекомендованные места хранения данных в контексте выравнивания, используя следующие значения выравнивания:
- байт — 8 битов;
- слово — 16 битов;
- двойное слово — 32 бита;
- квадслово — 64 бита
- слово из восьми слов — 128 бит.
| Скалярный тип | Тип данных C | Размер хранилища (в байтах) | Рекомендуемое выравнивание |
|---|---|---|---|
INT8 |
char |
1 | Байт |
UINT8 |
unsigned char |
1 | Байт |
INT16 |
short |
2 | Слово |
UINT16 |
unsigned short |
2 | Слово |
INT32 |
int, long |
4 | Двойное слово |
UINT32 |
unsigned int, unsigned long |
4 | Двойное слово |
INT64 |
__int64 |
8 | квадрослово |
UINT64 |
unsigned __int64 |
8 | квадрослово |
FP32 (одиночная точность) |
float |
4 | Двойное слово |
FP64 (двойная точность) |
double |
8 | квадрослово |
POINTER |
* | 8 | квадрослово |
__m64 |
struct __m64 |
8 | квадрослово |
__m128 |
struct __m128 |
16 | Октаворд |
Макет агрегатов и объединений x64
Другие типы, такие как массивы, структуры и союзы, предъявляют более строгие требования к выравниванию, что обеспечивает согласованное хранение и извлечение агрегатов и союзов. Ниже приведены определения для массивов, структур и объединений.
Массив
Содержит упорядоченную группу смежных объектов данных. Каждый объект называется элементом. Все элементы массива имеют одинаковый размер и тип данных.
Структура
Содержит упорядоченную группу объектов данных. В отличие от элементов массива, элементы структуры могут иметь различные типы и размеры данных.
Объединение
Объект, содержащий любой из наборов именованных элементов. Элементы именованного набора могут быть любого типа. Размер памяти, выделяемой для объединения, равен размеру памяти, необходимому для хранения его крупнейшего элемента, плюс добавочные байты, требуемые для выравнивания.
В следующей таблице показано строго рекомендуемое выравнивание скалярных членов объединений и структур.
| Скалярный тип | Тип данных в C | Требуемое выравнивание |
|---|---|---|
INT8 |
char |
Байт |
UINT8 |
unsigned char |
Байт |
INT16 |
short |
Слово |
UINT16 |
unsigned short |
Слово |
INT32 |
int, long |
Двойное слово |
UINT32 |
unsigned int, unsigned long |
Двойное слово |
INT64 |
__int64 |
квадрослово |
UINT64 |
unsigned __int64 |
квадрослово |
FP32 (одиночная точность) |
float |
Двойное слово |
FP64 (двойная точность) |
double |
квадрослово |
POINTER |
* | квадрослово |
__m64 |
struct __m64 |
квадрослово |
__m128 |
struct __m128 |
Октаворд |
Для агрегированного выравнивания действуют следующие правила:
Выравнивание массива совпадает с выравниванием одного из его элементов.
Выравнивание начала структуры или объединения соответствует максимальному выравниванию любого отдельного элемента. Каждый элемент структуры или объединения должен быть правильно выровнен в соответствии с приведенной выше таблицей, для чего может потребоваться неявное внутреннее заполнение в зависимости от предыдущего элемента.
Размер структуры должен быть целое число раз кратен параметру ее выравнивания, для чего может потребоваться заполнение после последнего элемента. Так как структуры и объединения могут объединяться в массивы, каждый элемент массива, представляющий собой структуру или объединение, должен начинаться и заканчиваться в ранее определенной позиции выравнивания.
Вы можете выровнять данные так, чтобы они превышали требования к выравниванию, при условии соблюдения предыдущих правил.
Отдельный компилятор может настроить упаковку структуры с целью ограничения ее размера. Например, /Zp (выравнивание элементов структуры) позволяет настраивать упаковку структур.
Примеры выравнивания структуры x64
В четырех примерах ниже объявляется выровненная структура или объединение, и на соответствующих рисунках показано их размещение в памяти. Каждый столбец на рисунке представляет байт памяти, а число в столбце соответствует смещению этого байта. Имя во второй строке на каждом рисунке соответствует имени переменной в объявлении. Затененные столбцы обозначают заполнение, необходимое для обеспечения указанного выравнивания.
Пример 1
// Total size = 2 bytes, alignment = 2 bytes (word).
_declspec(align(2)) struct {
short a; // +0; size = 2 bytes
}

Пример 2
// Total size = 24 bytes, alignment = 8 bytes (quadword).
_declspec(align(8)) struct {
int a; // +0; size = 4 bytes
double b; // +8; size = 8 bytes
short c; // +16; size = 2 bytes
}

На схеме показаны 24 байта памяти. Член a, int, занимает байты от 0 до 3. На схеме показана заполнение байтов 4–7. Член b, двойной, занимает байты 8–15. Член c, короткий, занимает байты 16–17. Байты 18–23 не используются.
Пример 3
// Total size = 12 bytes, alignment = 4 bytes (doubleword).
_declspec(align(4)) struct {
char a; // +0; size = 1 byte
short b; // +2; size = 2 bytes
char c; // +4; size = 1 byte
int d; // +8; size = 4 bytes
}
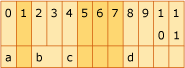
На схеме показаны 12 байт памяти. Член a, char, занимает байт 0. Байт 1 является заполнением. Член b, короткий, занимает байты 2–4. Член c, char, занимает байт 4. Байты 5–7 являются заполняющими. Член d, int, занимает байты 8–11.
Пример 4
// Total size = 8 bytes, alignment = 8 bytes (quadword).
_declspec(align(8)) union {
char *p; // +0; size = 8 bytes
short s; // +0; size = 2 bytes
long l; // +0; size = 4 bytes
}

На схеме показаны 8 байт памяти. Член p, char, занимает байт 0. Свойство s, типа short, занимает байты с 0 по 1. Элемент l, длинное, занимает байты с 0 по 3. Байты 4–7 заполнены.
Битовые поля
Битовые поля структуры ограничены 64 битами и могут иметь тип signed int, unsigned int, int64 или unsigned int64. Битовые поля, пересекающие границу типа, будут пропускать биты для выравнивания поля по следующему выравниванию типа. Например, целые битовые поля могут не пересекать 32-разрядную границу.
Конфликты с компилятором x86
Типы данных, размер которых превышает 4 байта, не выравниваются автоматически в стеке при использовании компилятора x86 для компиляции приложения. Так как архитектура компилятора x86 — это 4 байтовой стек, все, что больше 4 байта, например 64-разрядное целое число, не может быть автоматически выровнено с 8-байтовым адресом.
Работа с невыровненными данными имеет два последствия.
Доступ к невыровненным позициям может занимать больше времени, чем к выровненным позициям.
Невыравненные расположения нельзя использовать во взаимоблокируемых операциях.
Если требуется более строгое выравнивание, используйте __declspec(align(N)) в объявлениях переменных. В результате компилятор будет динамически выравнивать стек в соответствии с вашими спецификациями. Однако динамическая настройка стека во время выполнения может привести к более медленному выполнению приложения.
Использование регистров x64
Архитектура x64 предоставляет 16 регистров общего назначения (далее называемые целыми регистрами), а также 16 XMM/YMM регистров, доступных для использования с плавающей запятой. Разрушаемые регистры — это временные регистры, которые вызывающая сторона предполагает будут уничтожены во время вызова. Неизменяемые регистры должны сохранять свое значение во время вызова функции и при использовании должны сохраняться вызываемым объектом.
Изменчивость и сохранение регистров
Следующая таблица описывает использование каждого из регистров в вызовах функций.
| Регистрация | Состояние | Использование |
|---|---|---|
RAX |
Переменный | Регистр возвращаемого значения |
RCX |
Переменный | Первый целочисленный аргумент |
RDX |
Переменный | Второй целочисленный аргумент |
R8 |
Переменный | Третий целочисленный аргумент |
R9 |
Переменный | Четвертый целочисленный аргумент |
R10:R11 |
Переменный | Должен сохраняться вызывающим объектом; используется в инструкциях syscall/sysret. |
R12:R15 |
Энергонезависимый | Должен сохраняться вызываемой стороной. |
R16:R29 |
Переменный | Должен сохраняться при необходимости вызывающей стороной (APX Register) |
R30:R31 |
Энергонезависимый | Должен сохраняться вызываемой функцией (регистр APX) |
RDI |
Энергонезависимый | Должен сохраняться вызываемой стороной. |
RSI |
Энергонезависимый | Должен сохраняться вызываемой стороной. |
RBX |
Энергонезависимый | Должен сохраняться вызываемой стороной. |
RBP |
Энергонезависимый | Может использоваться в качестве указателя фрейма; должен сохраняться вызываемым объектом. |
RSP |
Энергонезависимый | Указатель стека |
XMM0, YMM0 |
Переменный | Первый аргумент FP; первый аргумент векторного типа при использовании __vectorcall |
XMM1, YMM1 |
Переменный | Второй аргумент FP; второй аргумент векторного типа при использовании __vectorcall |
XMM2, YMM2 |
Переменный | Третий аргумент FP; третий аргумент векторного типа при использовании __vectorcall |
XMM3, YMM3 |
Переменный | Четвертый аргумент FP; четвертый аргумент векторного типа при использовании __vectorcall |
XMM4, YMM4 |
Переменный | Должен сохраняться вызывающим объектом; пятый аргумент векторного типа при использовании __vectorcall |
XMM5, YMM5 |
Переменный | Должен сохраняться вызывающим объектом; шестой аргумент векторного типа при использовании __vectorcall |
XMM6:XMM15, YMM6:YMM15 |
Энергонезависимая (XMM), Энергозависимая (верхняя половина YMM) |
Должен сохраняться вызываемым объектом.
YMM Регистры должны сохраняться по мере необходимости вызывающим абонентом. |
При выходе из функции и при входе в функцию для вызовов библиотеки времени выполнения C и системных вызовов Windows флаг направления в регистре флагов ЦП должен сбрасываться.
Использование стека
Дополнительные сведения о выделении стека, выравнивании, типах функций и кадрах стека в x64 см. в разделе об использовании стека x64.
Пролог и эпилог
Каждая функция, которая выделяет пространство стека, вызывает другие функции, сохраняет невлетающие регистры или использует обработку исключений, должна содержать пролог с ограничениями адресов, описанными в данных распаковки стека, связанных с соответствующей записью таблицы функций, и эпилоги на каждом выходе из функции. Подробные сведения о необходимом коде пролога и эпилога в архитектуре x64 см. в статье Пролог и эпилог для 64-разрядных систем.
Обработка исключений в 64-разрядных системах
Сведения о соглашениях и структурах данных для реализации структурированной обработки исключений и обработки исключений C++ в архитектуре x64 см. в статье Обработка исключений в 64-разрядных системах.
Встроенные функции и встраиваемый ассемблерный код
Одно из ограничений компилятора x64 заключается в том, что он не поддерживает встроенный ассемблер. Это означает, что функции, которые не могут быть записаны в C или C++, должны быть записаны как вложенные или как встроенные функции, поддерживаемые компилятором. Некоторые функции чувствительны к производительности, а другие — нет. Функции, для которых производительность важна, должны реализовываться как встроенные.
Встроенные компоненты, поддерживаемые компилятором, описаны в встроенных функциях компилятора.
Формат изображения x64
Формат исполняемого образа x64 — PE32+. Размер исполняемых образов (как DLL, так и EXE) ограничен 2 гигабайтами, поэтому для адресации статических данных образов можно использовать относительную адресацию с 32-битным смещением. Эти данные включают в себя таблицу адресов импорта, строковые константы, статические глобальные данные и т. д.