Пошаговое руководство. Умножение матриц
В этом пошаговом руководстве показано, как использовать C++ AMP для ускорения выполнения умножения матрицы. Представлены два алгоритма, один без наливки и один с наливкой.
Необходимые компоненты
Перед началом:
- Ознакомьтесь с обзором C++ AMP.
- Чтение с помощью плиток.
- Убедитесь, что вы работаете по крайней мере под управлением Windows 7 или Windows Server 2008 R2.
Примечание.
Заголовки C++ AMP устарели начиная с Visual Studio 2022 версии 17.0.
Включение всех заголовков AMP приведет к возникновению ошибок сборки. Определите _SILENCE_AMP_DEPRECATION_WARNINGS перед включением всех заголовков AMP, чтобы замолчать предупреждения.
Создание проекта
Инструкции по созданию проекта зависят от установленной версии Visual Studio. Чтобы ознакомиться с документацией по предпочтительной версии Visual Studio, используйте селектор Версия. Он находится в верхней части оглавления на этой странице.
Создание проекта в Visual Studio
В строке меню выберите Файл>Создать>Проект, чтобы открыть диалоговое окно Создание проекта.
В верхней части диалогового окна задайте для параметра Язык значение C++, для параметра Платформа значение Windows, а для Типа проекта — Консоль.
Из отфильтрованного списка типов проектов нажмите кнопку "Пустой проект " и нажмите кнопку "Далее". На следующей странице введите MatrixMultiply в поле "Имя ", чтобы указать имя проекта и указать расположение проекта при необходимости.
Нажмите кнопку Создать, чтобы создать клиентский проект.
В Обозреватель решений откройте контекстное меню для исходных файлов и нажмите кнопку "Добавить>новый элемент".
В диалоговом окне "Добавить новый элемент" выберите файл C++(CPP), введите MatrixMultiply.cpp в поле "Имя", а затем нажмите кнопку "Добавить".
Создание проекта в Visual Studio 2017 или 2015
В строке меню в Visual Studio выберите "Файл>нового>проекта".
В разделе "Установленные " в области шаблонов выберите Visual C++.
Выберите пустой проект, введите MatrixMultiply в поле "Имя " и нажмите кнопку "ОК ".
Нажмите кнопку Далее.
В Обозреватель решений откройте контекстное меню для исходных файлов и нажмите кнопку "Добавить>новый элемент".
В диалоговом окне "Добавить новый элемент" выберите файл C++(CPP), введите MatrixMultiply.cpp в поле "Имя", а затем нажмите кнопку "Добавить".
Умножение без наложения
В этом разделе рассмотрим умножение двух матриц, А и B, которые определены следующим образом:
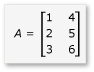

A — это матрица 3-к-2, а B — это матрица 2-к-3. Результат умножения A на B — это следующая матрица 3-на-3. Продукт вычисляется путем умножения строк A на столбцы элемента B по элементу.

Умножение без использования C++ AMP
Откройте MatrixMultiply.cpp и используйте следующий код для замены существующего кода.
#include <iostream> void MultiplyWithOutAMP() { int aMatrix[3][2] = {{1, 4}, {2, 5}, {3, 6}}; int bMatrix[2][3] = {{7, 8, 9}, {10, 11, 12}}; int product[3][3] = {{0, 0, 0}, {0, 0, 0}, {0, 0, 0}}; for (int row = 0; row < 3; row++) { for (int col = 0; col < 3; col++) { // Multiply the row of A by the column of B to get the row, column of product. for (int inner = 0; inner < 2; inner++) { product[row][col] += aMatrix[row][inner] * bMatrix[inner][col]; } std::cout << product[row][col] << " "; } std::cout << "\n"; } } int main() { MultiplyWithOutAMP(); getchar(); }Алгоритм — это простая реализация определения умножения матрицы. Он не использует параллельные или потоковые алгоритмы для уменьшения времени вычисления.
В строке меню выберите Файл>Сохранить все.
Выберите сочетание клавиш F5, чтобы начать отладку и убедиться, что выходные данные верны.
Нажмите клавишу ВВОД , чтобы выйти из приложения.
Умножение с помощью C++ AMP
В MatrixMultiply.cpp добавьте следующий код перед методом
main.void MultiplyWithAMP() { int aMatrix[] = { 1, 4, 2, 5, 3, 6 }; int bMatrix[] = { 7, 8, 9, 10, 11, 12 }; int productMatrix[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0 }; array_view<int, 2> a(3, 2, aMatrix); array_view<int, 2> b(2, 3, bMatrix); array_view<int, 2> product(3, 3, productMatrix); parallel_for_each(product.extent, [=] (index<2> idx) restrict(amp) { int row = idx[0]; int col = idx[1]; for (int inner = 0; inner <2; inner++) { product[idx] += a(row, inner)* b(inner, col); } }); product.synchronize(); for (int row = 0; row <3; row++) { for (int col = 0; col <3; col++) { //std::cout << productMatrix[row*3 + col] << " "; std::cout << product(row, col) << " "; } std::cout << "\n"; } }Код AMP похож на код, отличный от AMP. Вызов запуска
parallel_for_eachодного потока для каждого элемента иproduct.extentзаменяетforциклы для строк и столбцов. Значение ячейки в строке и столбце доступно вidx. Вы можете получить доступ к элементам объекта с помощью[]оператора и переменнойarray_viewиндекса, а также()оператора и переменных строк и столбцов. В примере показаны оба метода. Методarray_view::synchronizeкопирует значения переменнойproductобратно вproductMatrixпеременную.Добавьте следующие
includeиusingинструкции в верхней части MatrixMultiply.cpp.#include <amp.h> using namespace concurrency;Измените
mainметод для вызоваMultiplyWithAMPметода.int main() { MultiplyWithOutAMP(); MultiplyWithAMP(); getchar(); }Нажмите сочетание клавиш CTRL+F5, чтобы начать отладку и убедиться, что выходные данные верны.
Нажмите клавишу ПРОБЕЛ, чтобы выйти из приложения.
Умножение с помощью наливки
Тилинг — это метод, в котором данные секционируются в подмножества равных размеров, которые называются плитками. При использовании наливки изменяются три вещи.
Можно создать
tile_staticпеременные. Доступ к данным вtile_staticпространстве может быть гораздо быстрее, чем доступ к данным в глобальном пространстве. Экземпляр переменной создается для каждойtile_staticплитки, а все потоки в плитке имеют доступ к переменной. Основное преимущество настойки — это повышение производительности из-заtile_staticдоступа.Метод tile_barrier:wait можно вызвать, чтобы остановить все потоки в одной плитке в указанной строке кода. Вы не можете гарантировать порядок, в который будут выполняться потоки, только если все потоки в одной плитке остановятся на вызове
tile_barrier::waitперед продолжением выполнения.У вас есть доступ к индексу потока относительно всего
array_viewобъекта и индекса относительно плитки. Используя локальный индекс, вы можете упростить чтение и отладку кода.
Чтобы воспользоваться преимуществами умножения матрицы, алгоритм должен разделить матрицу на плитки, а затем скопировать данные плитки в tile_static переменные для быстрого доступа. В этом примере матрица секционируется на подматрисы равного размера. Продукт найден путем умножения подматриков. Два матрицы и их продукт в этом примере:
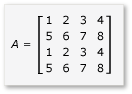
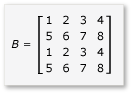
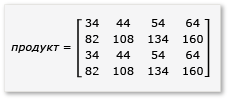
Матрицы секционируются на четыре матрицы 2x2, которые определяются следующим образом:


Теперь продукт A и B можно записать и вычислить следующим образом:
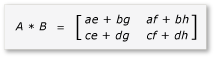
Поскольку матрицы ah через 2x2 матрицы, все продукты и суммы из них также 2x2 матрицы. Он также следует, что продукт A и B является матрицей 4x4, как ожидалось. Чтобы быстро проверка алгоритм, вычислите значение элемента в первой строке, первый столбец в продукте. В примере это будет значение элемента в первой строке и первом столбце ae + bg. Необходимо вычислить только первый столбец, первую строку ae и bg для каждого термина. Это значение ae для (1 * 1) + (2 * 5) = 11. Значением для bg этого является (3 * 1) + (4 * 5) = 23. Конечное значение равно 11 + 23 = 34правильному.
Для реализации этого алгоритма код:
tiled_extentИспользует объект вместоextentобъекта в вызовеparallel_for_each.tiled_indexИспользует объект вместоindexобъекта в вызовеparallel_for_each.Создает
tile_staticпеременные для хранения вложенных матриц.tile_barrier::waitИспользует метод для остановки потоков для вычисления продуктов субмарис.
Умножение с помощью AMP и наливки
В MatrixMultiply.cpp добавьте следующий код перед методом
main.void MultiplyWithTiling() { // The tile size is 2. static const int TS = 2; // The raw data. int aMatrix[] = { 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8 }; int bMatrix[] = { 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8 }; int productMatrix[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 }; // Create the array_view objects. array_view<int, 2> a(4, 4, aMatrix); array_view<int, 2> b(4, 4, bMatrix); array_view<int, 2> product(4, 4, productMatrix); // Call parallel_for_each by using 2x2 tiles. parallel_for_each(product.extent.tile<TS, TS>(), [=] (tiled_index<TS, TS> t_idx) restrict(amp) { // Get the location of the thread relative to the tile (row, col) // and the entire array_view (rowGlobal, colGlobal). int row = t_idx.local[0]; int col = t_idx.local[1]; int rowGlobal = t_idx.global[0]; int colGlobal = t_idx.global[1]; int sum = 0; // Given a 4x4 matrix and a 2x2 tile size, this loop executes twice for each thread. // For the first tile and the first loop, it copies a into locA and e into locB. // For the first tile and the second loop, it copies b into locA and g into locB. for (int i = 0; i < 4; i += TS) { tile_static int locA[TS][TS]; tile_static int locB[TS][TS]; locA[row][col] = a(rowGlobal, col + i); locB[row][col] = b(row + i, colGlobal); // The threads in the tile all wait here until locA and locB are filled. t_idx.barrier.wait(); // Return the product for the thread. The sum is retained across // both iterations of the loop, in effect adding the two products // together, for example, a*e. for (int k = 0; k < TS; k++) { sum += locA[row][k] * locB[k][col]; } // All threads must wait until the sums are calculated. If any threads // moved ahead, the values in locA and locB would change. t_idx.barrier.wait(); // Now go on to the next iteration of the loop. } // After both iterations of the loop, copy the sum to the product variable by using the global location. product[t_idx.global] = sum; }); // Copy the contents of product back to the productMatrix variable. product.synchronize(); for (int row = 0; row <4; row++) { for (int col = 0; col <4; col++) { // The results are available from both the product and productMatrix variables. //std::cout << productMatrix[row*3 + col] << " "; std::cout << product(row, col) << " "; } std::cout << "\n"; } }Этот пример значительно отличается от примера без наливки. В коде используются следующие концептуальные шаги:
Скопируйте элементы плитки[0,0]
aвlocA. Скопируйте элементы плитки[0,0]bвlocB. Обратите внимание, чтоproductплитка не иba. Поэтому для доступаa, bproductиспользуйте глобальные индексы. Призывtile_barrier::waitявляется важным. Он останавливает все потоки на плитке до тех пор, пока ониlocBнеlocAбудут заполнены.Умножайте
locAиlocBпомещайте результатыproduct.Скопируйте элементы плитки[0,1]
aвlocA. Скопируйте элементы плитки [1,0]bвlocB.Умножьте
locAиlocBдобавьте их в результаты, которые уже находятсяproduct.Умножение плитки[0,0] завершено.
Повторите для остальных четырех плиток. Индексирование не выполняется специально для плиток, и потоки могут выполняться в любом порядке. По мере выполнения
tile_staticкаждого потока переменные создаются для каждой плитки соответствующим образом и вызов управленияtile_barrier::waitпотоком программы.При внимательном изучении алгоритма обратите внимание, что каждая подматрикса загружается в
tile_staticпамять дважды. Передача данных занимает время. Однако после того, как данные будут вtile_staticпамяти, доступ к данным гораздо быстрее. Так как для вычисления продуктов требуется повторный доступ к значениям в подматрисах, существует общий рост производительности. Для каждого алгоритма требуется экспериментирование для поиска оптимального алгоритма и размера плитки.
В примерах, отличных от AMP и не плитки, каждый элемент A и B обращается четыре раза из глобальной памяти для вычисления продукта. В примере плитки каждый элемент обращается дважды из глобальной памяти и четыре раза из
tile_staticпамяти. Это не является значительным повышением производительности. Тем не менее, если матрицы A и B были 1024x1024 и размер плитки были бы 16, было бы значительное увеличение производительности. В этом случае каждый элемент копируется вtile_staticпамять только 16 раз и обращается изtile_staticпамяти 1024 раза.Измените основной метод для вызова
MultiplyWithTilingметода, как показано ниже.int main() { MultiplyWithOutAMP(); MultiplyWithAMP(); MultiplyWithTiling(); getchar(); }Нажмите сочетание клавиш CTRL+F5, чтобы начать отладку и убедиться, что выходные данные верны.
Нажмите клавишу ПРОБЕЛ, чтобы выйти из приложения.
См. также
C++ AMP (C++ Accelerated Massive Parallelism)
Пошаговое руководство. Отладка приложения C++ AMP
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по