Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом руководстве показано, как создать рекомендуемый фильм с помощью ML.NET в консольном приложении .NET. Этапы выполняются с использованием C# и Visual Studio 2019.
В этом руководстве вы узнаете, как:
- Выбор алгоритма машинного обучения
- Подготовка и загрузка данных
- Создание и обучение модели
- Оценка модели
- Развертывание и использование модели
Исходный код для этого руководства можно найти в репозитории dotnet/samples .
Рабочий процесс машинного обучения
Для выполнения задачи вы будете использовать следующие действия, а также любую другую ML.NET задачу:
Предпосылки
Выберите соответствующую задачу машинного обучения
Существует несколько способов подхода к решению задач рекомендаций, таких как рекомендации списка фильмов или рекомендация списка связанных продуктов, но в этом случае вы будете прогнозировать, какой рейтинг (1-5) пользователь даст определенному фильму и будете рекомендовать этот фильм, если рейтинг выше заданного порогового значения (чем выше рейтинг, тем выше вероятность того, что пользователю понравится определенный фильм).
Создайте консольное приложение
Создание проекта
Создайте консольное приложение C# с именем MovieRecommender. Нажмите кнопку Далее.
Выберите .NET 8 в качестве платформы для использования. Нажмите кнопку Создать.
Создайте каталог с именем Data в проекте для хранения набора данных:
В обозревателе решений щелкните проект правой кнопкой мыши и выберите команду "Добавить>новую папку". Введите "Данные" и нажмите ВВОД.
Установите пакеты NuGet Microsoft.ML и Microsoft.ML.Recommender :
Замечание
В этом примере используется последняя стабильная версия упомянутых пакетов NuGet, если не указано иное.
В обозревателе решений щелкните проект правой кнопкой мыши и выберите Управление пакетами NuGet. Выберите "nuget.org" в качестве источника пакета, перейдите на вкладку "Обзор ", найдите Microsoft.ML, выберите пакет в списке и нажмите кнопку "Установить". Нажмите кнопку "ОК " в диалоговом окне "Предварительные изменения" , а затем нажмите кнопку "Принять" в диалоговом окне принятия лицензий, если вы согласны с условиями лицензии для перечисленных пакетов. Повторите эти действия для Microsoft.ML.Recommender.
Добавьте следующие
usingдирективы в верхней части файла Program.cs :using Microsoft.ML; using Microsoft.ML.Trainers; using MovieRecommendation;
Скачайте свои данные
Скачайте два набора данных и сохраните их в ранее созданной папке данных :
Щелкните правой кнопкой мыши recommendation-ratings-train.csv и выберите "Сохранить ссылку (или цель) как..."
Щелкните правой кнопкой мыши recommendation-ratings-test.csv и выберите "Сохранить ссылку (или цель) как..."
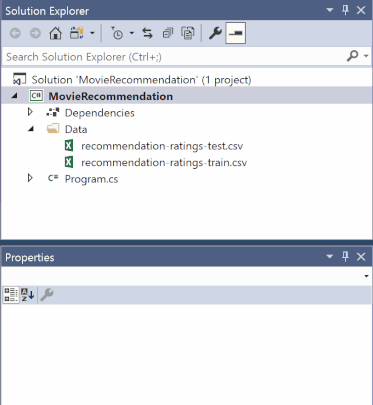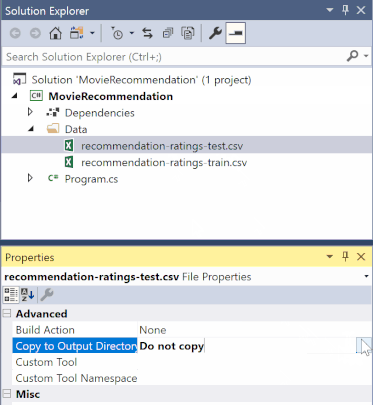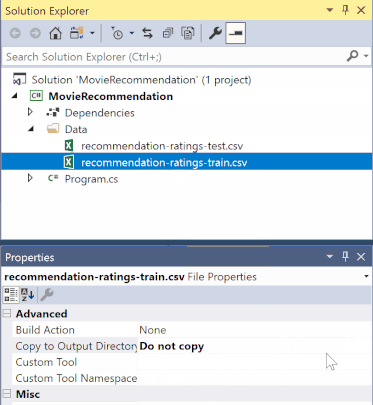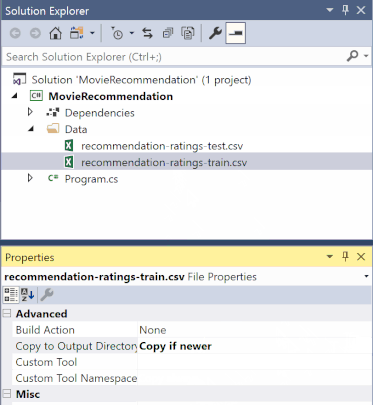
Убедитесь, что файлы *.csv сохранены в папке данных или после сохранения в другом месте, переместите файлы *.csv в папку данных .
В обозревателе решений щелкните правой кнопкой мыши каждый из файлов *.csv и выберите "Свойства". В разделе "Дополнительно" измените значение Копировать в выходной каталог на Копировать, если новее.
Загрузка данных
Первым шагом процесса ML.NET является подготовка и загрузка данных обучения и тестирования модели.
Данные оценки рекомендаций разделены на наборы данных Train и Test. Данные Train используются для соответствия модели. Данные Test используются для прогнозирования с помощью обученной модели и оценки производительности модели. Обычно имеется разделение 80/20 с Train данными и Test данными.
Ниже приведена предварительная версия данных из файлов *.csv:
В файлах *.csv есть четыре столбца:
userIdmovieIdratingtimestamp
В машинном обучении столбцы, используемые для прогнозирования, называются "Функции", а столбец с возвращаемым прогнозом называется Меткой.
Вы хотите прогнозировать рейтинги фильмов, поэтому столбец рейтинга — это Label. Остальные три столбца, userIdmovieIdи timestamp все Features используются для прогнозированияLabel.
| Функции | Этикетка |
|---|---|
userId |
rating |
movieId |
|
timestamp |
Это до вас, чтобы решить, какие Features используются для прогнозирования Label. Вы также можете использовать такие методы, как важность функции перемутации , чтобы помочь в выборе лучшего Features.
В этом случае следует исключить timestamp столбец как метку времени, так как Feature метка времени на самом деле не влияет на то, как пользователь оценивает данный фильм и таким образом не будет способствовать созданию более точного прогноза:
| Функции | Этикетка |
|---|---|
userId |
rating |
movieId |
Затем необходимо определить структуру данных для входного класса.
Добавьте новый класс в проект:
В обозревателе решений щелкните проект правой кнопкой мыши и выберите пункт "Добавить > новый элемент".
В диалоговом окне "Добавление нового элемента" выберите класс и измените поле "Имя " на MovieRatingData.cs. Затем нажмите кнопку "Добавить".
Файл MovieRatingData.cs откроется в редакторе кода. Добавьте следующую using директиву в начало MovieRatingData.cs:
using Microsoft.ML.Data;
Создайте класс, вызываемый MovieRating путем удаления существующего определения класса и добавления следующего кода в MovieRatingData.cs:
public class MovieRating
{
[LoadColumn(0)]
public float userId;
[LoadColumn(1)]
public float movieId;
[LoadColumn(2)]
public float Label;
}
MovieRating указывает входной класс данных. Атрибут LoadColumn указывает, какие столбцы (по индексу столбца) в наборе данных должны быть загружены.
userId и movieId столбцы — это ваши Features (входные данные, которые вы предоставите модели для прогнозирования и Label), а столбец рейтинга — это Label, который вы будете прогнозировать (выходные данные модели).
Создайте другой класс, MovieRatingPredictionчтобы представить прогнозируемые результаты, добавив следующий код после MovieRating класса в MovieRatingData.cs:
public class MovieRatingPrediction
{
public float Label;
public float Score;
}
В Program.cs замените Console.WriteLine("Hello World!") следующий код:
MLContext mlContext = new MLContext();
Класс MLContext — это отправная точка для всех операций ML.NET, и инициализация mlContext создает новую среду ML.NET, которую можно совместно использовать для объектов рабочего процесса создания модели. Концептуально, это похоже на DBContext в Entity Framework.
В нижней части файла создайте метод:LoadData()
(IDataView training, IDataView test) LoadData(MLContext mlContext)
{
}
Замечание
Этот метод даст ошибку, пока не добавьте оператор return в следующих шагах.
Необходимо инициализировать переменные пути к данным, загрузить данные из файлов *.csv и вернуть данные Train и Test в виде объектов IDataView, добавив следующую строку кода в LoadData().
var trainingDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-train.csv");
var testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-test.csv");
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<MovieRating>(trainingDataPath, hasHeader: true, separatorChar: ',');
IDataView testDataView = mlContext.Data.LoadFromTextFile<MovieRating>(testDataPath, hasHeader: true, separatorChar: ',');
return (trainingDataView, testDataView);
Данные в ML.NET представлены в виде интерфейса IDataView.
IDataView — это гибкий, эффективный способ описания табличных данных (числовых и текстовых данных). Данные можно загружать из текстового файла или в режиме реального времени (например, базы данных SQL или файлов журналов) в IDataView объект.
LoadFromTextFile() определяет схему данных и считывает его в файле. Он принимает переменные пути к данным и возвращает значение IDataView. В этом случае вы предоставляете путь к Test файлам и Train указываете как заголовок текстового файла (так что он может правильно использовать имена столбцов), так и разделитель символов запятой (разделитель по умолчанию — это вкладка).
Добавьте следующий код для вызова LoadData() метода и возврата TrainTest данных:
(IDataView trainingDataView, IDataView testDataView) = LoadData(mlContext);
Создание и обучение модели
BuildAndTrainModel() Создайте метод сразу после LoadData() метода, используя следующий код:
ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainingDataView)
{
}
Замечание
Этот метод даст ошибку, пока не добавьте оператор return в следующих шагах.
Определите преобразования данных, добавив в него следующий код BuildAndTrainModel():
IEstimator<ITransformer> estimator = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "userIdEncoded", inputColumnName: "userId")
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "movieIdEncoded", inputColumnName: "movieId"));
Так как userId и movieId представляют пользователей и названия фильмов, а не реальные значения, используйте метод MapValueToKey(), чтобы преобразовать каждое userId и каждое movieId в столбец с числовым типом ключа Feature (формат, поддерживаемый алгоритмами рекомендаций) и добавить их как новые столбцы в набор данных:
| userId | movieId | Этикетка | userIdEncoded | movieIdEncoded |
|---|---|---|---|---|
| 1 | 1 | 4 | userKey1 | movieKey1 |
| 1 | 3 | 4 | userKey1 | movieKey2 |
| 1 | 6 | 4 | userKey1 | movieKey3 |
Выберите алгоритм машинного обучения и добавьте его в определения преобразования данных, добавив следующую строку кода в BuildAndTrainModel():
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
var trainerEstimator = estimator.Append(mlContext.Recommendation().Trainers.MatrixFactorization(options));
MatrixFactorizationTrainer — это ваш алгоритм обучения рекомендаций. Матричная факторизация — это распространенный подход к рекомендациям при наличии данных о том, как пользователи оценили продукты в прошлом, что является примером наборов данных в этом руководстве. Существуют другие алгоритмы рекомендаций при наличии различных доступных данных (см. раздел "Другие алгоритмы рекомендаций " ниже, чтобы узнать больше).
В этом случае Matrix Factorization алгоритм использует метод с именем "совместная фильтрация", который предполагает, что если пользователь 1 имеет то же мнение, что и Пользователь 2 по определенной проблеме, то пользователь 1, скорее всего, будет чувствовать себя так же, как Пользователь 2 о другой проблеме.
Например, если пользователь 1 и пользователь 2 оценивают фильмы аналогично, то Пользователь 2, скорее всего, будет наслаждаться фильмом, который Пользователь 1 смотрел и оценил высоко:
Incredibles 2 (2018) |
The Avengers (2012) |
Guardians of the Galaxy (2014) |
|
|---|---|---|---|
| Пользователь 1 | Просмотр и понравился фильм | Просмотр и понравился фильм | Просмотр и понравился фильм |
| Пользователь 2 | Просмотр и понравился фильм | Просмотр и понравился фильм | Не смотрел - РЕКОМЕНДУЕМ фильм |
Тренер Matrix Factorization имеет несколько параметров, о которых можно узнать больше в разделе "Гиперпараметры алгоритма " ниже.
Вместите модель в Train данные и верните обученную модель, добавив следующую строку кода в BuildAndTrainModel() методе:
Console.WriteLine("=============== Training the model ===============");
ITransformer model = trainerEstimator.Fit(trainingDataView);
return model;
Метод Fit() обучает модель предоставленным набором данных обучения. Технически он выполняет Estimator определения, преобразовав данные и применяя обучение, и он возвращает обученную модель, которая является .Transformer
Дополнительные сведения о рабочем процессе обучения модели в ML.NET см. в разделе "Что такое ML.NET" и как это работает?.
Добавьте следующую строку кода под вызовом метода для вызова LoadData()BuildAndTrainModel() метода и возврата обученной модели:
ITransformer model = BuildAndTrainModel(mlContext, trainingDataView);
Оценка модели
Обучив модель, используйте тестовые данные для оценки того, как выполняется модель.
EvaluateModel() Создайте метод сразу после BuildAndTrainModel() метода, используя следующий код:
void EvaluateModel(MLContext mlContext, IDataView testDataView, ITransformer model)
{
}
Test Преобразование данных путем добавления следующего кода EvaluateModel()в:
Console.WriteLine("=============== Evaluating the model ===============");
var prediction = model.Transform(testDataView);
Метод Transform() делает прогнозы для нескольких предоставленных входных строк тестового набора данных.
Оцените модель, добавив следующую строку кода в EvaluateModel() методе:
var metrics = mlContext.Regression.Evaluate(prediction, labelColumnName: "Label", scoreColumnName: "Score");
После получения прогнозируемого набора метод Evaluate() оценивает модель, которая сравнивает прогнозируемые значения с фактическим Labels в тестовом наборе данных и возвращает метрики о том, как выполняется модель.
Распечатайте метрики оценки в консоль, добавив следующую строку кода в EvaluateModel() методе:
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError.ToString());
Console.WriteLine("RSquared: " + metrics.RSquared.ToString());
Добавьте следующую строку кода под вызовом BuildAndTrainModel() метода для вызова EvaluateModel() метода:
EvaluateModel(mlContext, testDataView, model);
Выходные данные до сих пор должны выглядеть примерно так:
=============== Training the model ===============
iter tr_rmse obj
0 1.5403 3.1262e+05
1 0.9221 1.6030e+05
2 0.8687 1.5046e+05
3 0.8416 1.4584e+05
4 0.8142 1.4209e+05
5 0.7849 1.3907e+05
6 0.7544 1.3594e+05
7 0.7266 1.3361e+05
8 0.6987 1.3110e+05
9 0.6751 1.2948e+05
10 0.6530 1.2766e+05
11 0.6350 1.2644e+05
12 0.6197 1.2541e+05
13 0.6067 1.2470e+05
14 0.5953 1.2382e+05
15 0.5871 1.2342e+05
16 0.5781 1.2279e+05
17 0.5713 1.2240e+05
18 0.5660 1.2230e+05
19 0.5592 1.2179e+05
=============== Evaluating the model ===============
Rms: 0.994051469730769
RSquared: 0.412556298844873
В этих выходных данных содержится 20 итераций. В каждой итерации мера ошибки уменьшается и приближается к 0.
( root of mean squared error RMS или RMSE) используется для измерения различий между прогнозируемыми значениями модели и наблюдаемых значений тестового набора данных. Технически это квадратный корень среднего значения квадратов ошибок. Чем ниже, тем лучше модель.
R Squared указывает, насколько хорошо данные соответствуют модели. Диапазоны от 0 до 1. Значение 0 означает, что данные являются случайными или иным образом не могут соответствовать модели. Значение 1 означает, что модель точно соответствует данным. Вы хотите, чтобы оценка R Squared была как можно ближе к 1.
Построение успешных моделей — это итеративный процесс. Эта модель имеет начальное низкое качество, так как в этом руководстве используются небольшие наборы данных для быстрого обучения модели. Если вы не удовлетворены качеством модели, вы можете попытаться улучшить его, предоставив более крупные наборы данных обучения или выбрав различные алгоритмы обучения с различными гиперпараметров для каждого алгоритма. Дополнительные сведения см. в разделе "Улучшение модели " ниже.
Использование модели
Теперь вы можете использовать обученную модель для прогнозирования новых данных.
UseModelForSinglePrediction() Создайте метод сразу после EvaluateModel() метода, используя следующий код:
void UseModelForSinglePrediction(MLContext mlContext, ITransformer model)
{
}
PredictionEngine Используйте для прогнозирования рейтинга, добавив следующий код UseModelForSinglePrediction()в:
Console.WriteLine("=============== Making a prediction ===============");
var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
PredictionEngine — это удобный API, который позволяет выполнять прогноз на одном экземпляре данных.
PredictionEngine не является потокобезопасным. Его можно использовать в однопоточных или прототипных средах. Для повышения производительности и безопасности потоков в рабочих средах используйте PredictionEnginePool службу, которая создает ObjectPoolPredictionEngine объекты для использования во всем приложении. См. это руководство по использованию PredictionEnginePool в веб-API ASP.NET Core.
Замечание
PredictionEnginePool Расширение службы в настоящее время находится в предварительной версии.
Создайте экземпляр вызываемого MovieRating и передайте его в обработчик прогнозированияtestInput, добавив следующие строки кода в UseModelForSinglePrediction() методе:
var testInput = new MovieRating { userId = 6, movieId = 10 };
var movieRatingPrediction = predictionEngine.Predict(testInput);
Функция Predict() делает прогноз на одном столбце данных.
Затем можно использовать Scoreпрогнозируемый рейтинг или определить, следует ли рекомендовать фильм с movieId 10 пользователю 6.
ScoreЧем выше, тем выше вероятность того, что пользователь нравится конкретному фильму. В этом случае предположим, что рекомендуется фильмы с прогнозируемым рейтингом > 3,5.
Чтобы распечатать результаты, добавьте следующие строки кода в UseModelForSinglePrediction() методе:
if (Math.Round(movieRatingPrediction.Score, 1) > 3.5)
{
Console.WriteLine("Movie " + testInput.movieId + " is recommended for user " + testInput.userId);
}
else
{
Console.WriteLine("Movie " + testInput.movieId + " is not recommended for user " + testInput.userId);
}
Добавьте следующую строку кода после вызова EvaluateModel() метода для вызова UseModelForSinglePrediction() метода:
UseModelForSinglePrediction(mlContext, model);
Выходные данные этого метода должны выглядеть примерно так:
=============== Making a prediction ===============
Movie 10 is recommended for user 6
Сохранение модели
Чтобы использовать модель для прогнозирования в приложениях конечных пользователей, необходимо сначала сохранить модель.
SaveModel() Создайте метод сразу после UseModelForSinglePrediction() метода, используя следующий код:
void SaveModel(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer model)
{
}
Сохраните обученную модель, добавив следующий код в SaveModel() метод:
var modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "MovieRecommenderModel.zip");
Console.WriteLine("=============== Saving the model to a file ===============");
mlContext.Model.Save(model, trainingDataViewSchema, modelPath);
Этот метод сохраняет обученную модель в файл .zip (в папке Data), который затем можно использовать в других приложениях .NET для прогнозирования.
Добавьте следующую строку кода после вызова UseModelForSinglePrediction() метода для вызова SaveModel() метода:
SaveModel(mlContext, trainingDataView.Schema, model);
Использование сохраненной модели
После сохранения обученной модели можно использовать модель в разных средах. См. статью "Сохранение и загрузка обученных моделей ", чтобы узнать, как работать с обученной моделью машинного обучения в приложениях.
Results
Выполнив описанные выше действия, запустите консольное приложение (CTRL+F5). Результаты из приведенного выше прогноза должны совпадать со следующими результатами. Вы можете видеть предупреждения или сообщения о процессе, но эти сообщения были удалены из следующих результатов ради ясности.
=============== Training the model ===============
iter tr_rmse obj
0 1.5382 3.1213e+05
1 0.9223 1.6051e+05
2 0.8691 1.5050e+05
3 0.8413 1.4576e+05
4 0.8145 1.4208e+05
5 0.7848 1.3895e+05
6 0.7552 1.3613e+05
7 0.7259 1.3357e+05
8 0.6987 1.3121e+05
9 0.6747 1.2949e+05
10 0.6533 1.2766e+05
11 0.6353 1.2636e+05
12 0.6209 1.2561e+05
13 0.6072 1.2462e+05
14 0.5965 1.2394e+05
15 0.5868 1.2352e+05
16 0.5782 1.2279e+05
17 0.5713 1.2227e+05
18 0.5637 1.2190e+05
19 0.5604 1.2178e+05
=============== Evaluating the model ===============
Rms: 0.977175077487166
RSquared: 0.43233349213192
=============== Making a prediction ===============
Movie 10 is recommended for user 6
=============== Saving the model to a file ===============
Поздравляю! Теперь вы успешно создали модель машинного обучения для рекомендаций фильмов. Исходный код для этого руководства можно найти в репозитории dotnet/samples .
Улучшение модели
Существует несколько способов повышения производительности модели, чтобы получить более точные прогнозы.
Данные
Добавление дополнительных обучающих данных, которые имеют достаточно примеров для каждого пользователя и идентификатора фильма, могут помочь улучшить качество модели рекомендаций.
Перекрестная проверка — это метод оценки моделей, которые случайным образом разбивают данные на подмножества (вместо извлечения тестовых данных из набора данных, как вы сделали в этом руководстве) и принимают некоторые группы как обучающие данные и некоторые группы в качестве тестовых данных. Этот метод превысивает производительность обучения, разделяя тест на качество модели.
Функции
В этом руководстве вы используете только три элемента Features (user id, movie id и rating), предоставленные набором данных.
Хотя это хороший старт, в действительности может потребоваться добавить другие атрибуты или Features (например, возраст, пол, географическое расположение и т. д.), если они включены в набор данных. Добавление дополнительных соответствующих возможностей Features может помочь повысить производительность модели рекомендаций.
Если вы не уверены, какой Features может быть наиболее актуальным для вашей задачи машинного обучения, вы также можете использовать вычисление вклада признаков (FCC) и переменную важность признаков, которую предоставляет ML.NET для обнаружения наиболее влиятельных Features.
Гиперпараметры алгоритма
Хотя ML.NET предоставляет хорошие алгоритмы обучения по умолчанию, вы можете дополнительно настроить производительность, изменив гиперпараметры алгоритма.
Для Matrix Factorization можно поэкспериментировать с гиперпараметрами, такими как NumberOfIterations и ApproximationRank, чтобы узнать, даст ли вам это лучшие результаты.
Например, в этом руководстве параметры алгоритма:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
Другие алгоритмы рекомендаций
Алгоритм факторизации матрицы с совместной фильтрацией — это только один подход для выполнения рекомендаций по фильмам. Во многих случаях у вас могут отсутствовать доступные данные о рейтингах и быть доступна только история просмотров фильмов от пользователей. В других случаях у вас может быть больше, чем только данные о рейтинге пользователя.
| Алгоритм | Scenario | Sample |
|---|---|---|
| Факторизация матрицы одного класса | Используйте это, если у вас есть только userId и movieId. Этот стиль рекомендаций основан на сценарии совместного приобретения или продуктах, часто приобретенных вместе, что означает, что он будет рекомендовать клиентам набор продуктов на основе собственной истории заказа на покупку. | >Попробуйте его |
| Компьютеры с учетом полей | Используйте это, чтобы сделать рекомендации, если у вас больше функций за пределами userId, productId и рейтинг (например, описание продукта или цена на продукт). Этот метод также использует подход к совместной фильтрации. | >Попробуйте его |
Новый сценарий пользователя
Одна из распространенных проблем при совместной фильтрации — это проблема холодного запуска, которая заключается в том, что у вас есть новый пользователь без предыдущих данных для вывода. Эта проблема часто решается путем запроса новых пользователей создать профиль и, например, оценить фильмы, которые они видели в прошлом. Хотя этот метод ставит некоторую нагрузку на пользователя, он предоставляет некоторые начальные данные для новых пользователей без журнала оценки.
Ресурсы
Данные, используемые в этом руководстве, являются производными от набора данных MovieLens.
Дальнейшие шаги
Из этого руководства вы узнали, как:
- Выбор алгоритма машинного обучения
- Подготовка и загрузка данных
- Создание и обучение модели
- Оценка модели
- Развертывание и использование модели
Перейдите к следующему руководству, чтобы узнать больше
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.