Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
Эта функция доступна в предварительной версии.
Среда выполнения Fabric обеспечивает простую интеграцию в экосистеме Microsoft Fabric, предлагая надежную среду для проектов разработки и обработки и анализа данных, управляемых Apache Spark.
В этой статье представлена общедоступная предварительная версия среды выполнения Fabric 2.0, последняя среда выполнения, предназначенная для вычислений больших данных в Microsoft Fabric. Он выделяет ключевые функции и компоненты, которые делают этот выпуск значительным шагом вперед для масштабируемой аналитики и расширенных рабочих нагрузок.
Среда выполнения Fabric 2.0 включает следующие компоненты и обновления, предназначенные для улучшения возможностей обработки данных:
- Apache Spark 4.1
- Операционная система: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.13
- Delta Lake: 4.1
- R: 4.5.2
Это важно
Среда выполнения Fabric 2.0 обновлена до Spark 4.1, Delta Lake 4.1 и Python 3.13. Версия среды выполнения Fabric, отображаемая на портале (параметры рабочей области и параметр среды выполнения в пользовательском интерфейсе среды) не изменяется.
| Компонент | Предыдущая версия | Текущая версия |
|---|---|---|
| Spark | 4.0 | 4.1 |
| Delta Lake | 4.0 | 4.1 |
| Python | 3.12 | 3.13 |

Критическое изменение: Обновление Python требует от вас повторно опубликовать каждую среду, содержащую библиотеки. До повторной публикации открытые библиотеки и вкладки настраиваемых библиотек отображаются пустыми, а задания Spark, предназначенные для затронутой среды, завершаются ошибкой "Не найден модуль" или "Класс не найден".
Обязательные действия
- Запишите или экспортируйте список библиотек из каждой среды.
- Повторно добавьте библиотеки и выберите Опубликовать, чтобы пересобрать их для Spark 4.1.
Подсказка
Среда выполнения Fabric 2.0 включает поддержку собственного обработчика выполнения, что может значительно повысить производительность без дополнительных затрат. Вы можете включить собственный модуль выполнения на уровне среды, чтобы все задания и записные книжки автоматически наследуют расширенные возможности производительности.
Включение среды выполнения 2.0
Среду выполнения 2.0 можно включить на уровне рабочей области или на уровне элемента среды. Используйте параметр рабочей области, чтобы применить среду выполнения 2.0 в качестве значения по умолчанию для всех рабочих нагрузок Spark в рабочей области. Кроме того, создайте элемент среды с средой выполнения 2.0 для использования с определенными записными книжками или определениями заданий Spark, которые переопределяют рабочую область по умолчанию.
Включение среды выполнения 2.0 в параметрах рабочей области
Чтобы задать runtime 2.0 в качестве значения по умолчанию для всей рабочей области:
Перейдите на страницу параметров рабочей области в рабочей области Fabric.
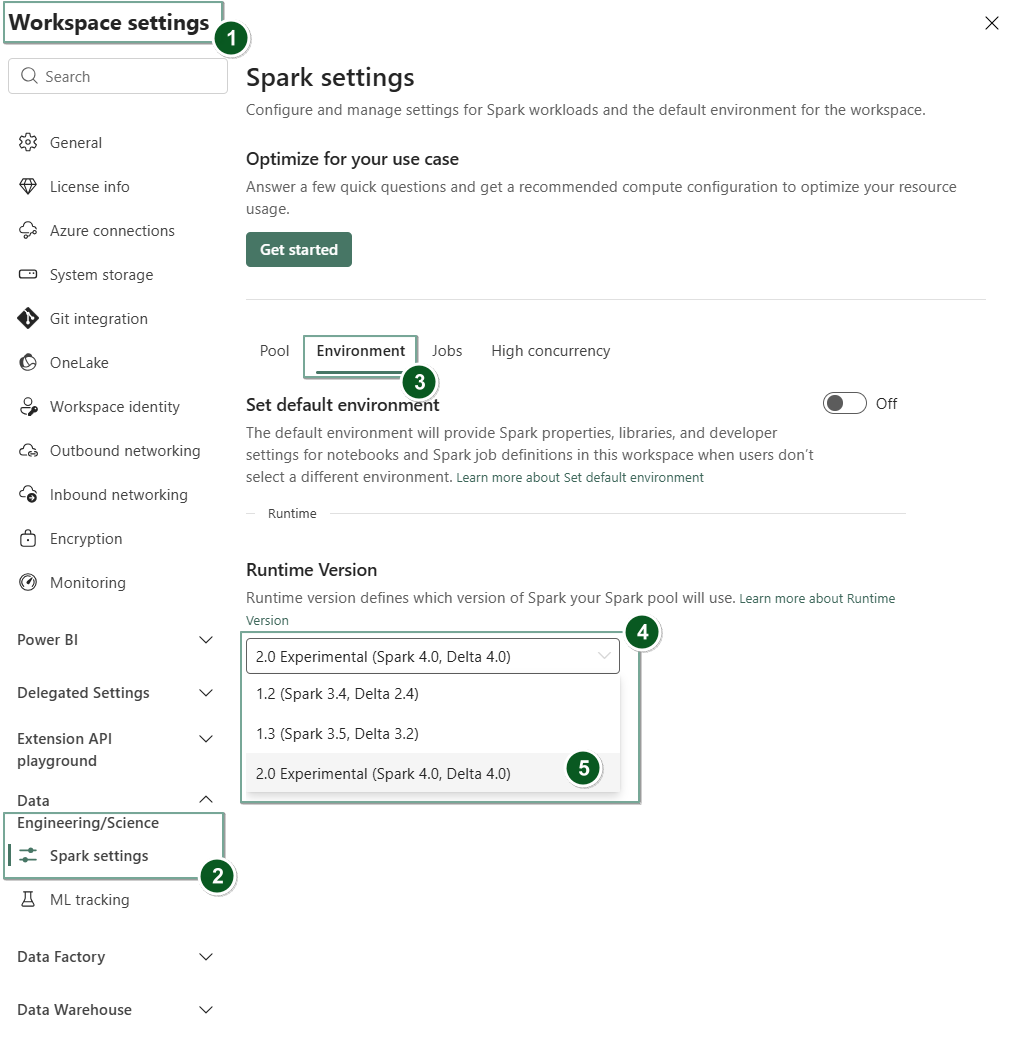
Перейдите на вкладку "Инженерия и наука данных" , а затем выберите параметры Spark.
Перейдите на вкладку Среда.
В раскрывающемся списке версии среды выполнения выберите общедоступную предварительную версию 2.0 (Spark 4.1, Delta 4.1) и сохраните изменения.
Среда выполнения 2.0 устанавливается в качестве среды выполнения по умолчанию для рабочей области.

Включение среды выполнения 2.0 в элементе среды
Чтобы использовать Runtime 2.0 с определенными ноутбуками или определениями заданий Spark:
Создайте новый элемент среды или откройте существующий элемент.
В раскрывающемся списке среды выполнения выберите общедоступную предварительную версию 2.0 (Spark 4.1, Delta 4.1),сохраните и опубликуйте изменения.
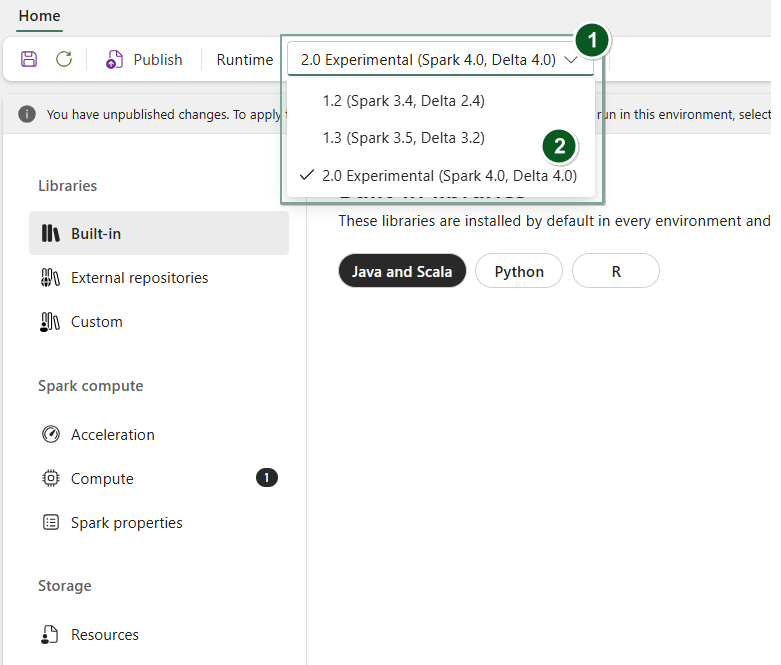
Затем этот элемент среды можно использовать в записной книжке или определении задания Spark.

Теперь вы можете начать экспериментировать с новыми улучшениями и функциями, представленными в Fabric Runtime 2.0 (Spark 4.1 и Delta Lake 4.1).
Замечание
Протокол WASB для учетных записей хранения Azure Общие назначения v2 (GPv2) устарел. Вместо этого следует использовать последний протокол ABFS для чтения и записи в учетные записи хранения GPv2.
Общедоступная предварительная версия
Этап общедоступной предварительной версии среды выполнения 2.0 Fabric предоставляет доступ к новым функциям и API из Spark 4.1 и Delta Lake 4.1. Предварительная версия позволяет сразу использовать последние улучшения На основе Spark и Delta, а также обеспечить плавную готовность и переход для расширенных и улучшенных изменений, таких как новые версии Java, Scala и Python.
Подсказка
Актуальные сведения, список изменений и содержательные заметки о выпуске для сред Fabric, ознакомьтесь и подпишитесь на выпуски и обновления Spark Runtimes.
Ключевые моменты
Усовершенствования производительности и движка выполнения
Среда выполнения Fabric 2.0 включает собственный модуль выполнения, который обеспечивает значительные улучшения производительности по сравнению с открытым исходным кодом Spark. Модуль использует векторную обработку для ускорения запросов Spark в инфраструктуре Lakehouse, не требуя изменения кода.
Ключевые функции производительности среды выполнения 2.0:
- До шести раз быстрее: тесты показывают до шести раз более высокую производительность по сравнению с open-source версией Spark на рабочих нагрузках TPC-DS.
- Векторный синтаксический анализ CSV: собственный модуль выполнения включает векторный парсер CSV, ускоряющий прием и обработку запросов CSV. Векторный анализ JSON и поддержка структурированной потоковой передачи Spark планируется для будущих обновлений.
Сведения о включении собственного механизма выполнения см. в разделе «Механизм выполнения для проектирования данных Fabric».
Apache Spark 4.1
Apache Spark 4.0 стал важной вехой как первый релиз серии 4.x, воплотив в себе коллективные усилия активного сообщества разработчиков open source. Среда выполнения Fabric 2.0 теперь использует Apache Spark 4.1, который основан на этой основе и включает ряд дополнительных улучшений.
В этой версии Spark SQL значительно обогащен мощными новыми функциями, предназначенными для повышения экспрессивности и универсальности рабочих нагрузок SQL, таких как поддержка типов данных VARIANT, определяемые пользователем функции SQL, переменные сеанса, синтаксис канала и параметры сортировки строк. PySpark видит постоянное развитие как в функциональных возможностях, так и в общем опыте разработчиков, предложив родной API для построения графиков, новый API источника данных Python, поддержку определяемых пользователем табличных функций (UDTF) Python и унифицированное профилирование для UDF PySpark, а также множество других улучшений. Структурированная потоковая передача развивается с помощью ключевых добавлений, которые обеспечивают больший контроль и простоту отладки, в частности введение API произвольного состояния версии 2 для более гибкого управления состоянием и источника данных состояния для упрощения отладки.
Вы можете проверить полный список и подробные изменения здесь:
Замечание
В Spark 4.x не рекомендуется использовать SparkR и может быть удален в будущей версии.
Delta Lake 4.1
Delta Lake 4.1 развивает достижения знакового релиза Delta Lake 4.0, подтверждая приверженность обеспечению совместимости Delta Lake с разными форматами, упрощению работы с ней и повышению производительности. Он включает в себя мощные новые функции, оптимизацию производительности и базовые улучшения для будущего открытых озер данных.
Вы можете проверить полный список и подробные изменения, представленные в Delta Lake 3.3, 4.0 и 4.1 здесь:
Макет данных и оптимизация
Среда выполнения 2.0 поддерживает функции макета данных и оптимизации для таблиц Delta:
- Z-упорядочение: упорядочивание данных в файлах таблиц Delta по указанным столбцам для повышения производительности запросов для отфильтрованных запросов.
- Liquid Clustering: гибкий подход к кластеризации, который автоматически оптимизирует макет данных без ручного обслуживания.
- Параллельная загрузка моментальных снимков Delta: движок выполнения загружает моментальные снимки таблиц Delta параллельно, сокращая время запуска запросов для больших таблиц.
Это важно
Специальные функции Delta Lake 4.1 являются экспериментальными и работают только над функциями Spark, такими как записные книжки и определения заданий Spark. Если вам нужно использовать одни и те же таблицы Delta Lake в нескольких рабочих нагрузках Microsoft Fabric, не включите эти функции. Дополнительные сведения о версиях и функциях протокола, совместимых во всех интерфейсах Microsoft Fabric, см. в статье о взаимодействии с форматом таблицы Delta Lake.
Управление вычислениями в среде выполнения 2.0
Среда выполнения 2.0 поддерживает следующие функции управления вычислительными ресурсами:
- Профили ресурсов: настройте предварительно определенные выделения ресурсов для сеансов Spark, чтобы соответствовать требованиям рабочей нагрузки и управлению затратами.
- Настраиваемые динамические пулы (предварительная версия): создание выделенных предварительно теплых пулов Spark, которые сокращают время запуска сеанса. Пользовательские динамические пулы доступны в предварительной версии для рабочих нагрузок среды выполнения 2.0.
Ограничения и заметки
- Специальные функции Delta Lake 4.x являются экспериментальными и работают только над функциями Spark, такими как записные книжки и определения заданий Spark. Если вам нужно использовать одни и те же таблицы Delta Lake для нескольких рабочих нагрузок Fabric, не включите эти функции. Дополнительные сведения см. в разделе "Взаимодействие с форматом таблицы Delta Lake".
- Среда выполнения 2.0 находится в общедоступной предварительной версии. Некоторые функции и API могут изменяться до общедоступной доступности.
- Расширение VS Code для Fabric Spark поддерживает среду выполнения 2.0 для разработки ноутбуков и определения заданий Spark.
Связанный контент
- Среда выполнения Apache Spark в Fabric — обзор, управление версиями и поддержка нескольких сред выполнения
- Руководство по миграции Spark Core
- Руководства по миграции SQL, датасетов и DataFrame
- Руководство по миграции структурированной потоковой передачи
- Руководство по миграции MLlib (Машинное обучение)
- Руководство по миграции PySpark (Python в Spark)
- Руководство по миграции SparkR (R в Spark)