Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Microsoft Fabric позволяет пользователям работать с моделями машинного обучения с помощью масштабируемой функции PREDICT. Эта функция поддерживает пакетную оценку в любом вычислительном ядре. Пользователи могут создавать пакетные прогнозы непосредственно из записной книжки Microsoft Fabric или на странице элемента данной модели машинного обучения.
В этой статье вы узнаете, как применить PREDICT, написав код самостоятельно или используя интерактивный интерфейс пользовательского интерфейса, который обрабатывает пакетную оценку для вас.
Необходимые компоненты
Получение подписки Microsoft Fabric. Или зарегистрируйте бесплатную пробную версию Microsoft Fabric.
Войдите в Microsoft Fabric.
Используйте переключатель интерфейса в левой нижней части домашней страницы, чтобы перейти на Fabric.

Ограничения
- Функция PREDICT в настоящее время поддерживается для этого ограниченного набора вариантов модели машинного обучения:
- CatBoost
- Keras
- LightGBM
- ONNX
- Prophet
- PyTorch
- SKLearn
- Spark
- Statsmodels
- TensorFlow
- XGBoost
- ПРОГНОЗ требует сохранения моделей машинного обучения в формате MLflow с заполненными подписями.
- PREDICT не поддерживает модели машинного обучения с несколькими тензорными входными или выходными данными
Вызов PREDICT из записной книжки
PREDICT поддерживает модели с пакетом MLflow в реестре Microsoft Fabric. Если в рабочей области уже обученная и зарегистрированная модель машинного обучения существует, можно перейти к шагу 2. Если нет, шаг 1 предоставляет пример кода для обучения модели логистической регрессии. Эту модель можно использовать для создания пакетных прогнозов в конце процедуры.
Обучить модель машинного обучения и зарегистрировать ее в MLflow. Следующий пример кода использует API MLflow для создания эксперимента машинного обучения и запуска MLflow для модели логистической регрессии scikit-learn. Затем версия модели хранится и зарегистрирована в реестре Microsoft Fabric. Узнайте, как обучить модели машинного обучения с помощью ресурса scikit-learn , чтобы получить дополнительные сведения о моделях обучения и отслеживании собственных экспериментов.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Загрузка тестовых данных в виде кадра данных Spark. Чтобы создать пакетные прогнозы с помощью модели машинного обучения, обученной на предыдущем шаге, необходимо проверить данные в виде кадра данных Spark. В следующем коде замените значение переменной
testсобственными данными.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))MLFlowTransformerСоздайте объект для загрузки модели машинного обучения для вывода. Чтобы создатьMLFlowTransformerобъект для создания пакетных прогнозов, необходимо выполнить следующие действия:- укажите столбцы DataFrame, необходимые
testв качестве входных данных модели (в данном случае все из них) - выберите имя нового выходного столбца (в данном случае
predictions) - укажите правильное имя модели и версию модели для создания этих прогнозов.
Если вы используете собственную модель машинного обучения, замените значения входных столбцов, имени выходного столбца, имени модели и версии модели.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- укажите столбцы DataFrame, необходимые
Создайте прогнозы с помощью функции PREDICT. Чтобы вызвать функцию PREDICT, используйте API преобразователя, API SQL Spark или определяемую пользователем функцию PySpark (UDF). В следующих разделах показано, как создавать пакетные прогнозы с помощью тестовых данных и модели машинного обучения, определенной на предыдущих шагах, используя различные методы для вызова функции PREDICT.
PREDICT с помощью API преобразователя
Этот код вызывает функцию PREDICT с ПОМОЩЬЮ API преобразователя. Если вы используете собственную модель машинного обучения, замените значения для модели и тестовых данных.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
ПРОГНОЗИРОВАНИе с помощью API SQL Spark
Этот код вызывает функцию PREDICT с помощью API SQL Spark. Если вы используете собственную модель машинного обучения, замените значения для model_name, model_versionа также features именем модели, версией модели и столбцами признаков.
Примечание.
Использование API SQL Spark для создания прогнозов MLFlowTransformer по-прежнему требует создания объекта (как показано на шаге 3).
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
PREDICT с определяемой пользователем функцией
Этот код вызывает функцию PREDICT с UDF PySpark. Если вы используете собственную модель машинного обучения, замените значения для модели и функций.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
Создание кода PREDICT на странице элемента модели машинного обучения
На странице элемента любой модели машинного обучения можно выбрать один из следующих вариантов, чтобы запустить создание пакетного прогнозирования для конкретной версии модели с помощью функции PREDICT:
- Копирование шаблона кода в записную книжку и настройка параметров самостоятельно
- Использование интерактивного интерфейса пользовательского интерфейса для создания кода PREDICT
Использование интерактивного пользовательского интерфейса
В интерактивном интерфейсе пользовательского интерфейса описаны следующие действия.
- Выбор исходных данных для оценки
- Правильно сопоставлять данные с входными данными модели машинного обучения
- Укажите назначение выходных данных модели
- Создание записной книжки, которая использует PREDICT для создания и хранения результатов прогнозирования
Чтобы использовать интерактивный интерфейс, выполните следующие действия.
Перейдите на страницу элемента для заданной версии модели машинного обучения.
В раскрывающемся списке "Применить эту версию" выберите " Применить эту модель" в мастере.
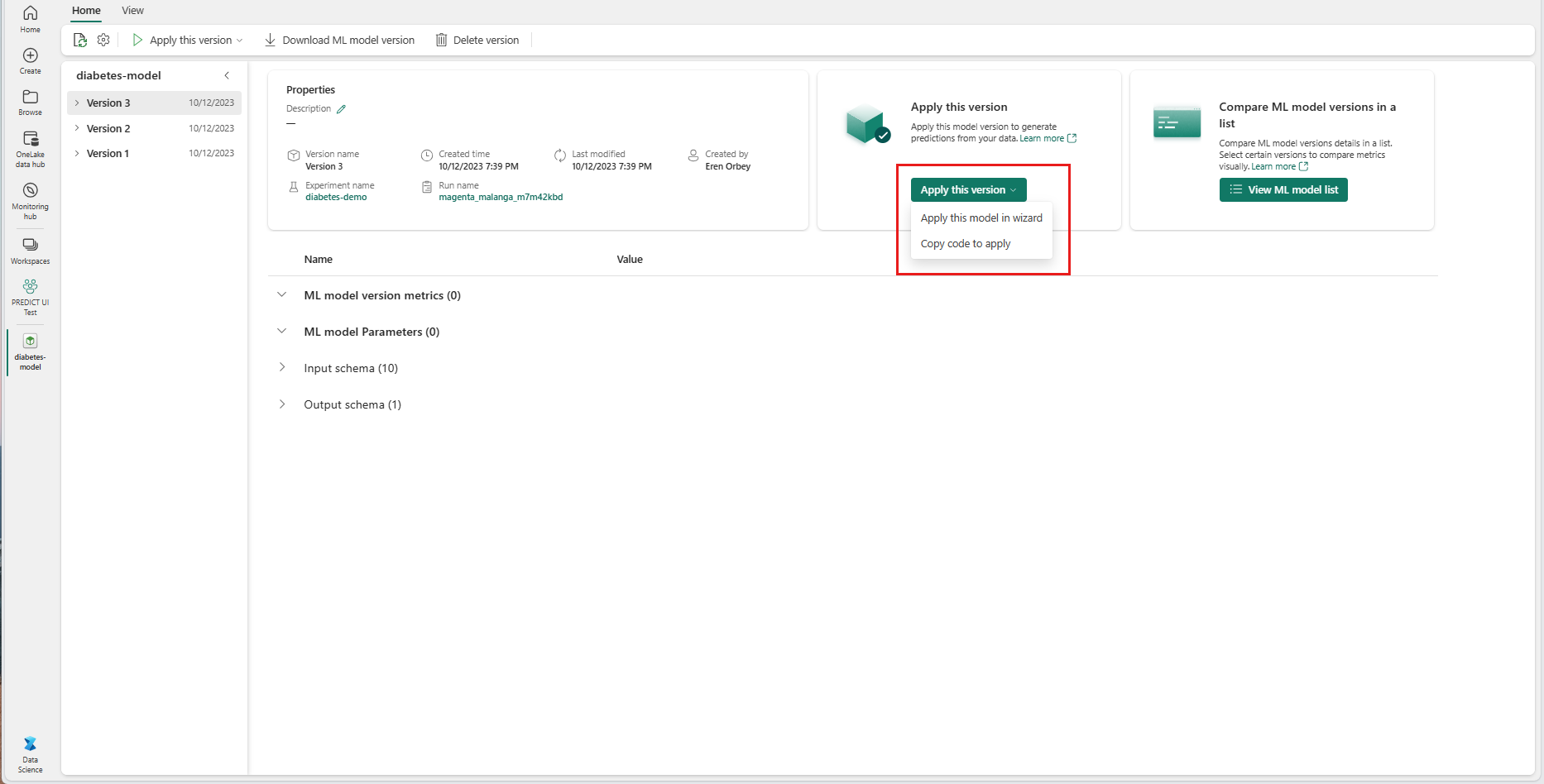
На шаге "Выбор входной таблицы" откроется окно "Применить прогнозы модели машинного обучения".
Выберите входную таблицу из lakehouse в текущей рабочей области.
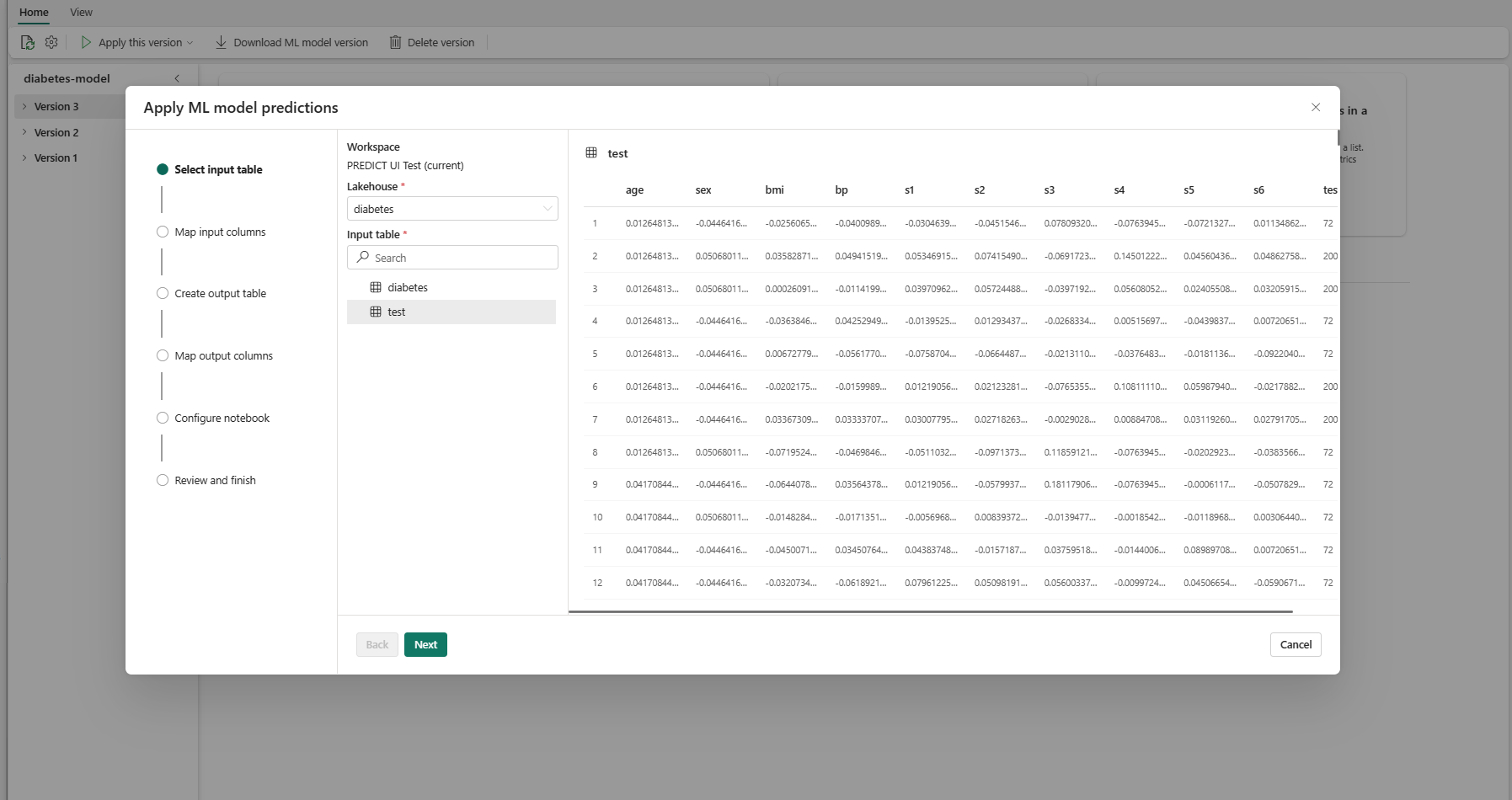
Нажмите кнопку "Далее ", чтобы перейти к шагу "Сопоставление входных столбцов".
Сопоставлять имена столбцов из исходной таблицы с полями входных данных модели машинного обучения, которые извлекаются из подписи модели. Необходимо указать входной столбец для всех обязательных полей модели. Кроме того, типы данных исходного столбца должны соответствовать ожидаемым типам данных модели.
Совет
Мастер предварительно заполняет это сопоставление, если имена входных столбцов таблицы соответствуют именам столбцов, зарегистрированным в сигнатуре модели машинного обучения.
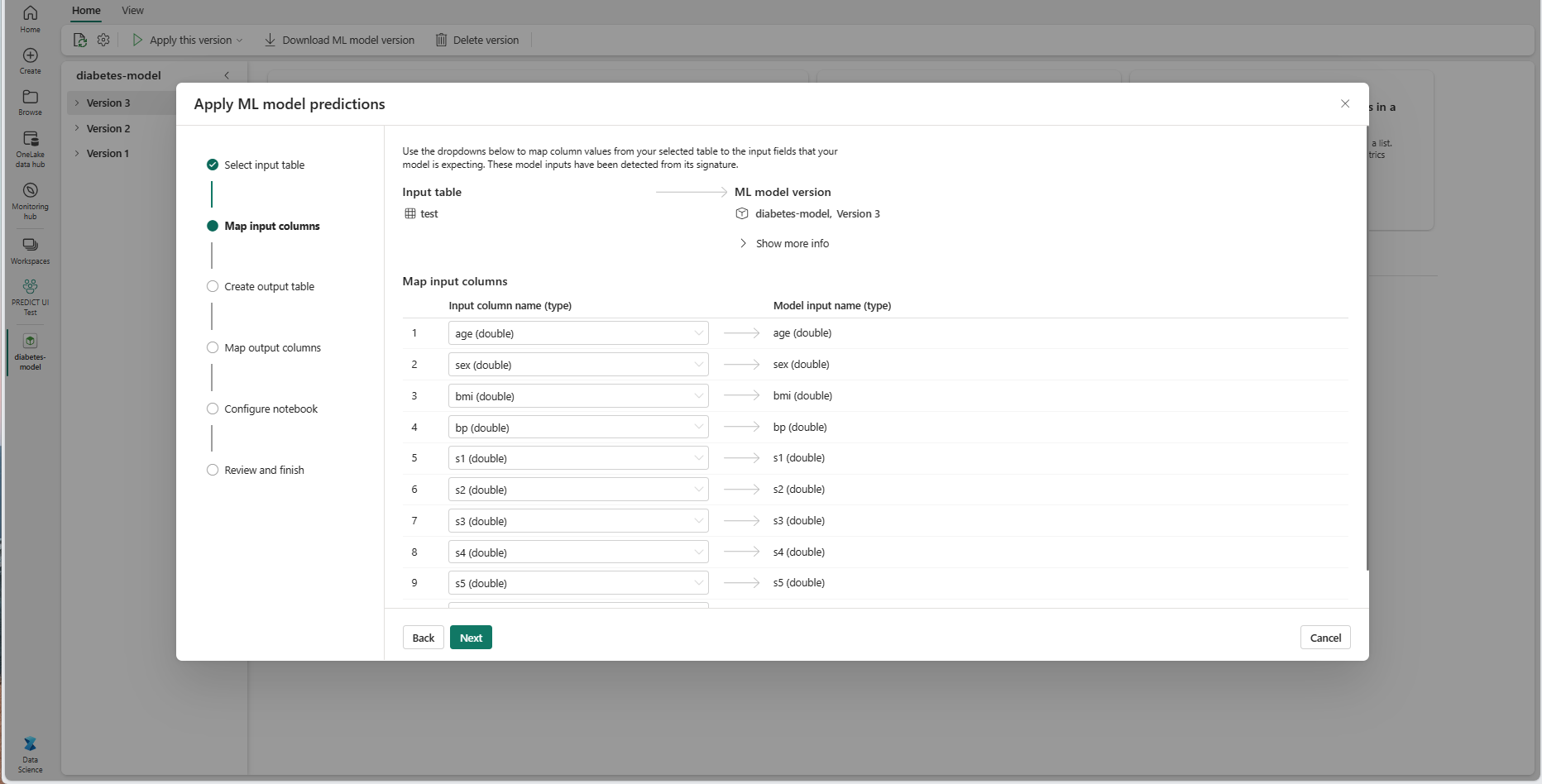
Нажмите кнопку "Далее ", чтобы перейти к шагу "Создать выходную таблицу".
Укажите имя новой таблицы в выбранном озерном доме текущей рабочей области. Эта выходная таблица сохраняет входные значения модели машинного обучения и добавляет значения прогнозирования в эту таблицу. По умолчанию выходная таблица создается в том же лейкхаусе, что и входная таблица. Вы можете изменить целевой лейкхаус.
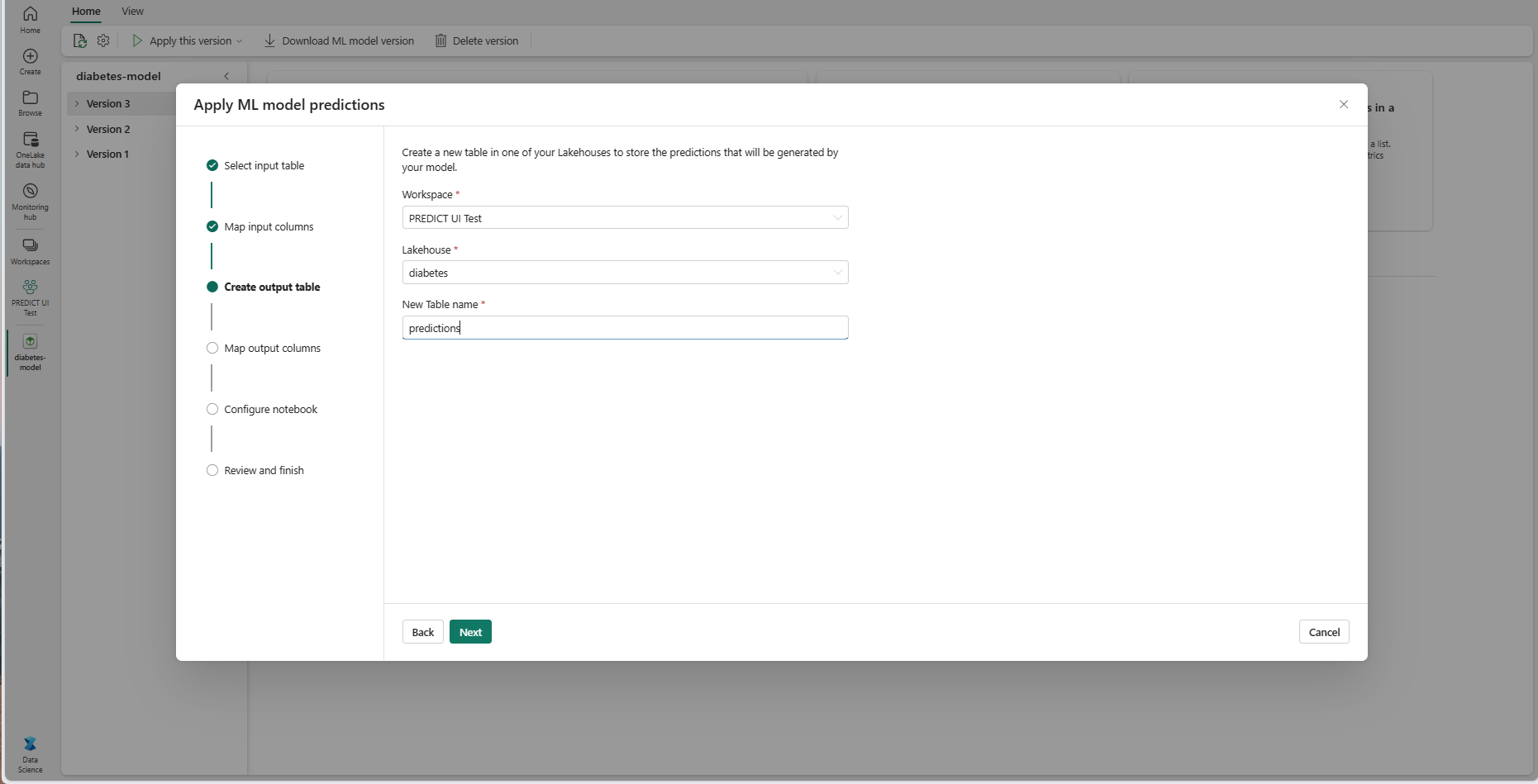
Нажмите кнопку "Далее ", чтобы перейти к шагу "Сопоставление выходных столбцов".
Используйте предоставленные текстовые поля для имени столбцов выходной таблицы, в которой хранятся прогнозы модели машинного обучения.
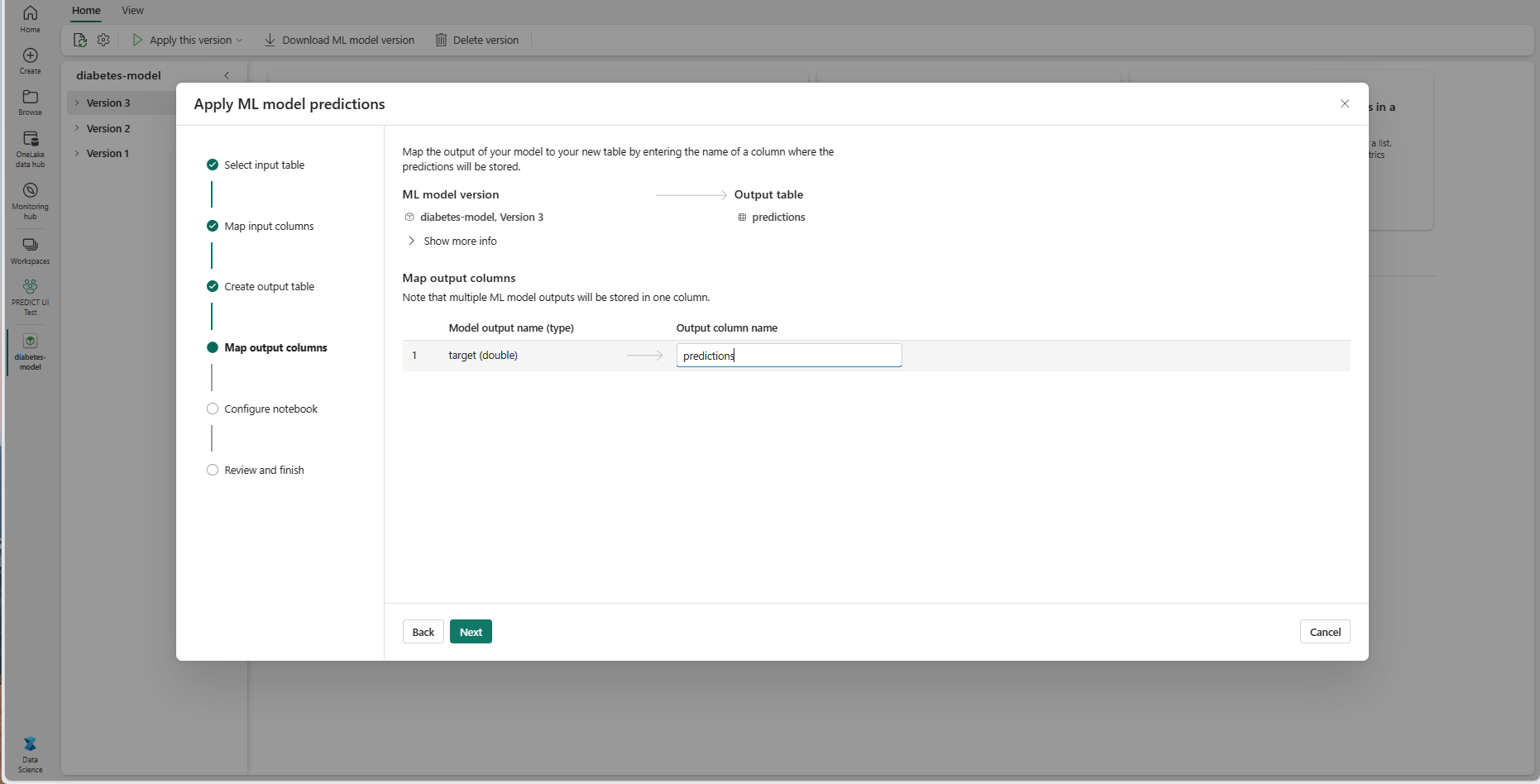
Нажмите кнопку "Далее ", чтобы перейти к шагу "Настройка записной книжки".
Укажите имя новой записной книжки, которая запускает созданный код PREDICT. Мастер отображает предварительный просмотр созданного кода на этом шаге. Если вы хотите, можно скопировать код в буфер обмена и вставить его в существующую записную книжку.
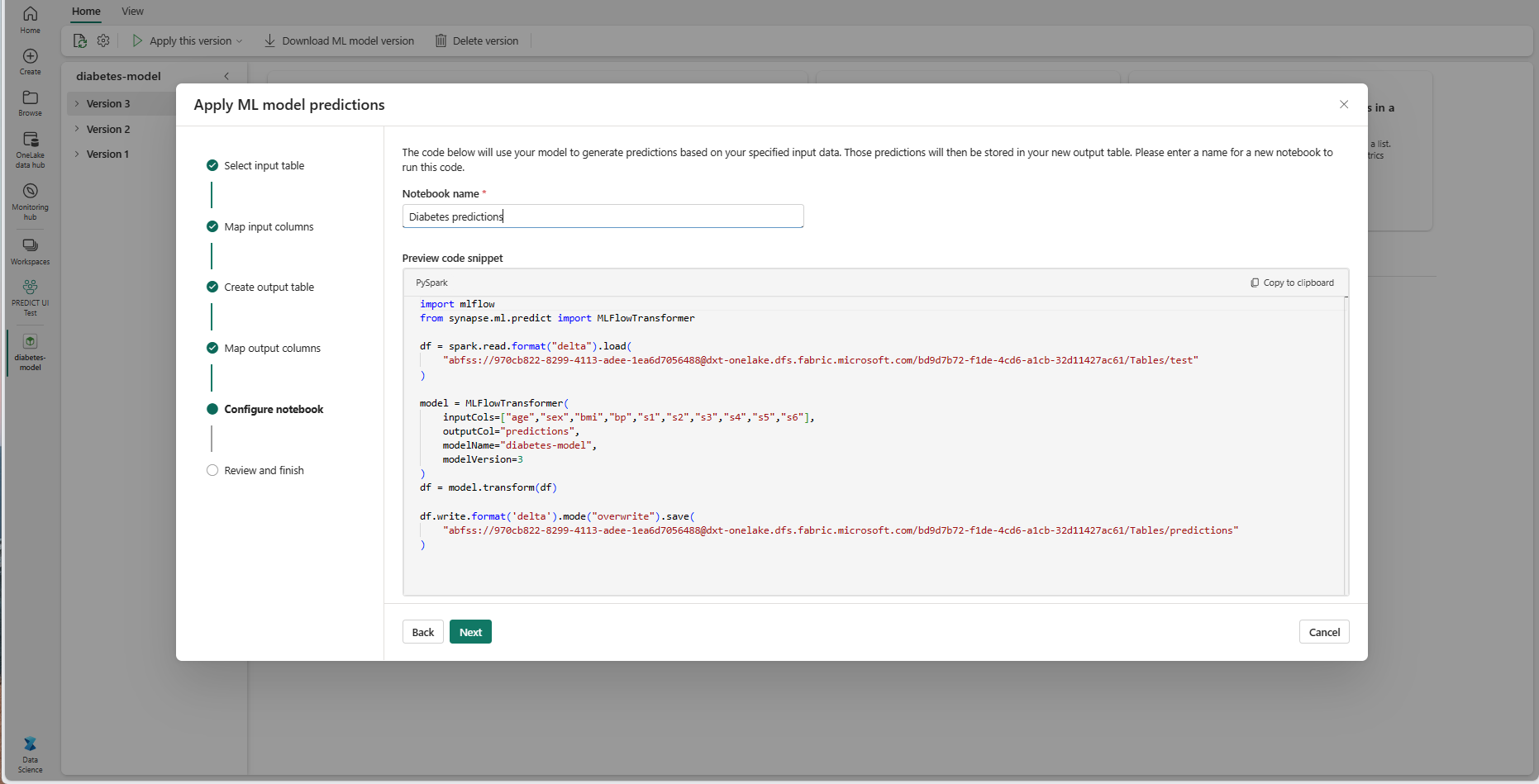
Нажмите кнопку "Далее ", чтобы перейти к шагу "Проверка и завершение".
Просмотрите сведения на странице сводки и выберите "Создать записную книжку", чтобы добавить новую записную книжку с созданным кодом в рабочую область. Вы перейдете непосредственно в эту записную книжку, где можно запустить код для создания и хранения прогнозов.
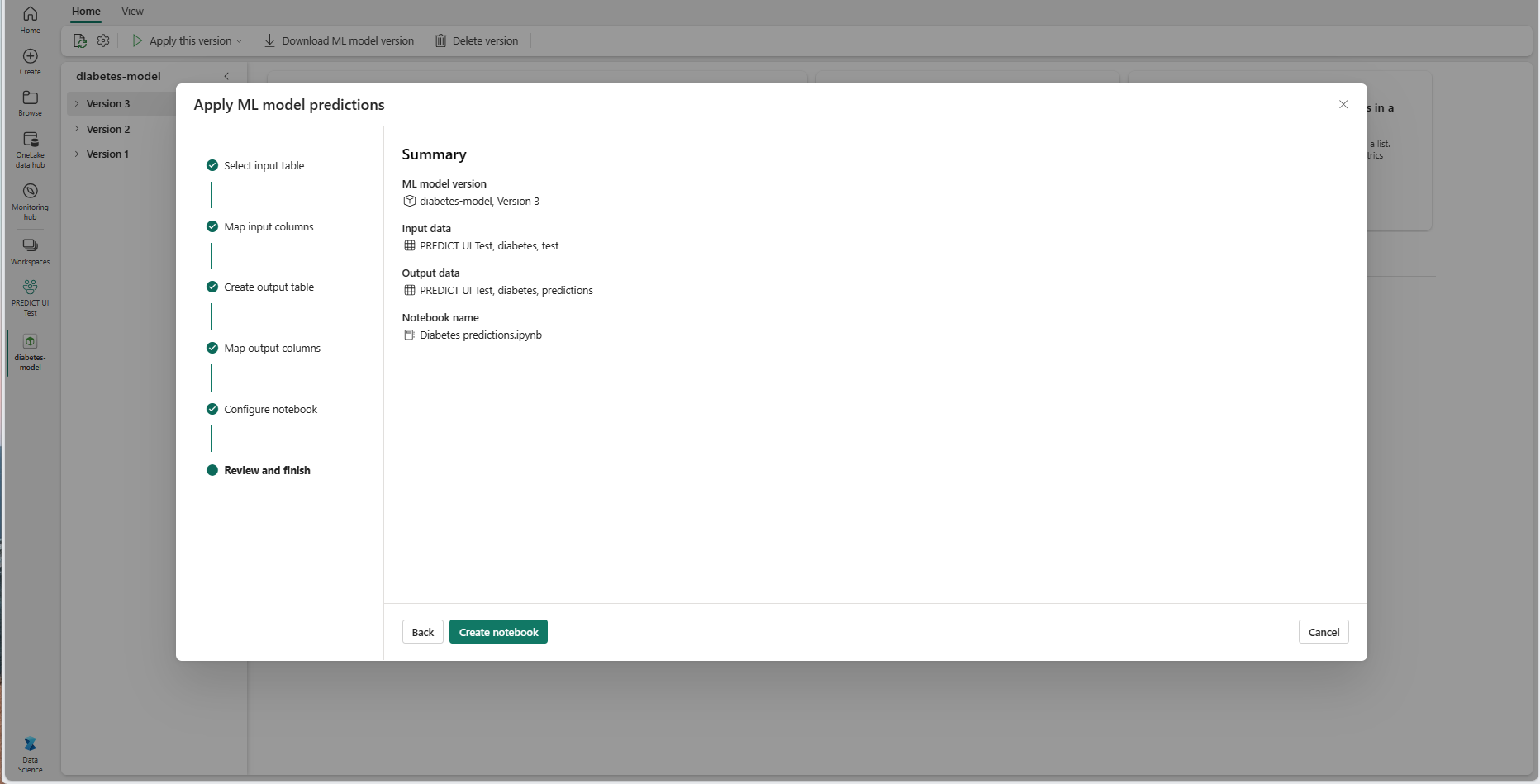







Использование настраиваемого шаблона кода
Чтобы использовать шаблон кода для создания прогнозов пакетной службы, выполните следующее:
- Перейдите на страницу элемента для заданной версии модели машинного обучения.
- Выберите "Копировать код", чтобы применить этот раскрывающийсясписок "Применить эту версию ". Выбор позволяет скопировать настраиваемый шаблон кода.
Этот шаблон кода можно вставить в записную книжку, чтобы создать пакетные прогнозы с помощью модели машинного обучения. Чтобы успешно запустить шаблон кода, необходимо вручную заменить следующие значения:
-
<INPUT_TABLE>: путь к файлу для таблицы, предоставляющей входные данные модели машинного обучения -
<INPUT_COLS>: массив имен столбцов из входной таблицы для канала модели машинного обучения -
<OUTPUT_COLS>: имя нового столбца в выходной таблице, в которой хранятся прогнозы -
<MODEL_NAME>: имя модели машинного обучения, используемой для создания прогнозов -
<MODEL_VERSION>: версия модели машинного обучения, используемая для создания прогнозов -
<OUTPUT_TABLE>: путь к файлу для таблицы, в которой хранятся прогнозы

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)