Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом руководстве показано, как взаимодействовать с Power BI из записной книжки Jupyter и обнаруживать связи между таблицами с помощью библиотеки SemPy.
В этом руководстве описано, как:
- Обнаружение связей в семантической модели (набор данных Power BI), используя библиотеку Python семантической ссылки (SemPy).
- Используйте компоненты SemPy, поддерживающие интеграцию с Power BI и помогающие автоматизировать анализ качества данных. К этим компонентам относятся:
- FabricDataFrame — структура, похожая на pandas, обогащенная дополнительной семантической информацией.
- Функции для извлечения семантических моделей из рабочей области Fabric в ноутбук.
- Функции, автоматизирующие оценку гипотез о функциональных зависимостях и определяющие нарушения связей в семантических моделях.
Необходимые условия
Получите подписку Microsoft Fabric. Или зарегистрируйтесь на бесплатную пробную Microsoft Fabric.
Войдите в Microsoft Fabric.
Используйте переключатель интерфейса в левой нижней части домашней страницы, чтобы перейти на Fabric.

Выберите рабочую область в левой панели навигации, чтобы найти и выбрать вашу рабочую область. Эта рабочая область становится вашей текущей рабочей областью.
Скачайте из репозитория GitHub fabric-samples семантические модели Customer Profitability Sample.pbix и Customer Profitability Sample (auto).pbix и загрузите их в вашу рабочую область.
Следуйте инструкциям в записной книжке
Тетрадь powerbi_relationships_tutorial.ipynb сопровождает это руководство.
Чтобы открыть сопровождающий блокнот для этого руководства, следуйте инструкциям из Подготовьте вашу систему для учебников по работе с данными, чтобы импортировать блокнот в ваше рабочее пространство.
Если вы хотите скопировать и вставить код на этой странице, можно создать новую записную книжку.
Не забудьте подключить lakehouse к блокноту перед началом запуска кода.
Настройка записной книжки
В этом разделе описана настройка среды записной книжки с необходимыми модулями и данными.
Установите
SemPyиз PyPI с помощью функции встроенной установки%pipв ноутбуке.%pip install semantic-linkВыполните необходимые импорты модулей SemPy, которые потребуются позже:
import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violationsИмпорт pandas для применения параметра конфигурации, который помогает в форматировании выходных данных.
import pandas as pd pd.set_option('display.max_colwidth', None)
Изучение семантических моделей
В этом руководстве используется стандартная семантическая модель рентабельности клиента на примере файла Sample.pbix . Описание семантической модели см. в примере рентабельности клиентов для Power BI.
Используйте функцию SemPy
list_datasetsдля изучения семантических моделей в текущей рабочей области:fabric.list_datasets()
Для остальной части этой записной книжки вы будете использовать две версии семантической модели рентабельности клиентов.
- пример рентабельности клиента: семантическая модель, исходя из примеров Power BI с предопределенными связями таблиц
- Пример рентабельности клиента (авто): те же данные, но взаимосвязи ограничены теми, которые Power BI будет автоматически определять.
Извлечение примера семантической модели с помощью предопределенной семантической модели
Загрузите связи, которые предварительно определены и хранятся в семантической модели Customer Profitability Sample, с помощью функции
list_relationshipsSemPy. Эта функция выводит список из табличной объектной модели:dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsВизуализировать DataFrame
relationshipsв виде графа с помощью функцииplot_relationship_metadataиз SemPy.plot_relationship_metadata(relationships)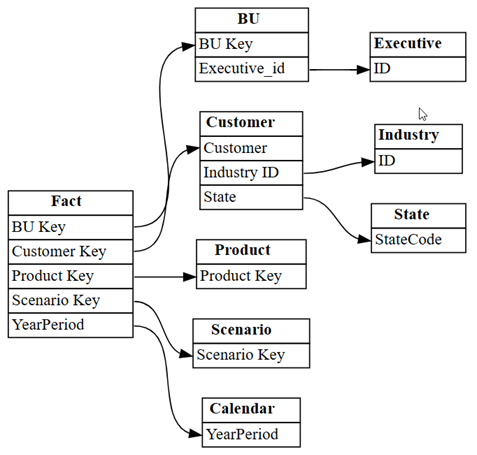

На этом графике показаны "эталонные данные" для связей между таблицами в этой семантической модели, что отражает, как они были определены в Power BI экспертом в предметной области.
Обнаружение комплементарных отношений
Если вы начали с отношений, которые Power BI обнаружил автоматически, у вас был бы меньший набор.
Визуализация связей, которые Power BI автоматически определяется в семантической модели:
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)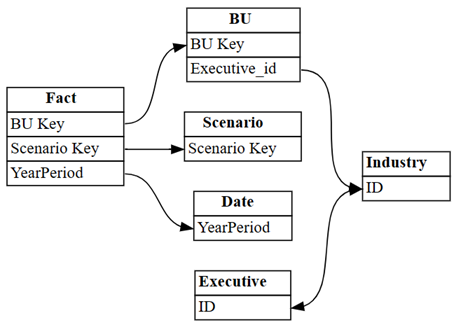
Автоопределение Power BI не обнаружило многие связи. Кроме того, две из автоматически определенных связей являются семантической ошибкой:
-
Executive[ID]—>Industry[ID] -
BU[Executive_id]—>Industry[ID]
-
Распечатайте отношения в виде таблицы.
autodetectedНеправильные связи с таблицей
Industryотображаются в строках с индексом 3 и 4. Используйте эти сведения для удаления этих строк.Отмена неправильно определенных связей.
autodetected.drop(index=[3,4], inplace=True) autodetectedТеперь у вас есть правильные, но неполные отношения.
Визуализация этих неполных связей с помощью
plot_relationship_metadata:plot_relationship_metadata(autodetected)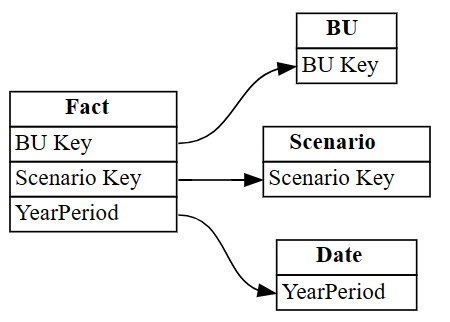
Загрузите все таблицы из семантической модели, используя функции
list_tablesиread_tableбиблиотеки SemPy.tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Найдите связи между таблицами, используя
find_relationships, и просмотрите выходные данные журнала, чтобы узнать, как работает эта функция:suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )Визуализировать только что обнаруженные связи:
plot_relationship_metadata(suggested_relationships_all)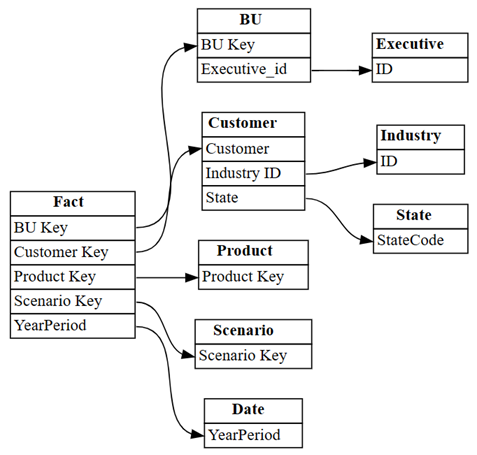
SemPy смог обнаружить все связи.
Используйте параметр
exclude, чтобы ограничить поиск дополнительными связями, которые ранее не были определены:additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



Проверка связей
Сначала загрузите данные из семантической модели Пример рентабельности клиента.
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Проверьте перекрытие значений первичного и внешнего ключа с помощью функции
list_relationship_violations. Укажите выходные данные функцииlist_relationshipsв качестве входных данных дляlist_relationship_violations:list_relationship_violations(tables, fabric.list_relationships(dataset))Нарушения связей предоставляют некоторые интересные сведения. Например, одно из семи значений в
Fact[Product Key]отсутствует вProduct[Product Key], и это отсутствующее значение —50.
Исследовательский анализ данных — это захватывающий процесс, и очистка данных тоже. Всегда есть что-то, что данные скрывают, в зависимости от того, как вы на них смотрите, что вы хотите узнать, и т. д. Семантическая ссылка предоставляет новые средства, которые можно использовать для получения дополнительных возможностей с данными.
Связанное содержимое
Ознакомьтесь с другими руководствами по семантической ссылке / SemPy:
- Руководство: Очистка данных с помощью функциональных зависимостей
- Руководство: анализ функциональных зависимостей в примере семантической модели
- Руководство: Извлечение и вычисление мер Power BI из записной книжки Jupyter
- Руководство по . Обнаружение связей в наборе данных Synthea с помощью семантической связи
- Руководство: Проверка данных с помощью SemPy и Great Expectations (GX)