Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Применимо к:✅ Хранилище данных в Microsoft Fabric
В этой статье рассматриваются функции и инновации в архитектуре хранилища данных Fabric, которые поддерживают производительность, масштабируемость и эффективность затрат.
Хранилище данных Fabric работает на архитектуре, подготовленной к будущему, в объединенной платформе данных. С открытым форматом хранилища Delta и интеграцией OneLake данные в хранилище данных Fabric готовы к анализу.
Архитектура высокого уровня

Хранилище данных Fabric предназначено для аналитики в масштабе с использованием следующих ключевых компонентов:
| Базовый элемент | Описание |
|---|---|
| Оптимизатор унифицированных запросов | Создает оптимальный план выполнения для распределенных облачных сред независимо от качества пользовательских запросов SQL. |
| Обработка распределенных запросов | Поддерживает массовое параллельное выполнение запросов с быстрой автоматической масштабированием облачной инфраструктуры, мгновенно предоставляя необходимые вычислительные ресурсы для запросов. Отдельные рабочие нагрузки SELECT и DML используют отдельные пулы для эффективного и изолированного выполнения. |
| Обработчик выполнения запросов | Подсистема на основе SQL для выполнения запросов аналитики на большом количестве данных с быстрой производительностью и высокой параллелизмом. |
| Управление метаданными и транзакциями | Метаданные находятся в интерфейсе, серверной части и в локальном кэше SSD, а также в удаленном хранилище OneLake. Поддерживает одновременные транзакции и гарантирует соответствие ACID. |
| Хранилище в OneLake | Лог-структурированные таблицы, реализованные с помощью открытого формата таблицы Delta, модели хранилища типа Lakehouse с безопасным открытым хранилищем. |
| Платформа Fabric | Платформа Fabric предоставляет единую модель проверки подлинности и безопасности, мониторинг и аудит. Хранилище данных Fabric автоматически доступно другим службам платформы Fabric для удовлетворения бизнес-потребностей, включая Power BI, конвейеры данных в фабрике данных, Real-Time аналитику и многое другое. |
Модуль оптимизатора унифицированных запросов
Оптимизатор унифицированных запросов в хранилище данных Fabric — это механизм, который решает самый умный способ выполнения запросов SQL.
При отправке запроса оптимизатор унифицированных запросов проверяет возможные способы его выполнения: объединение таблиц, расположение для перемещения данных и использование ресурсов, таких как ЦП, память и сеть. Оптимизатор унифицированных запросов не просто выбирает первый вариант, он выбирает наиболее оптимальный план в течение времени, разрешенного путем оценки затрат по этим факторам и доступным метаданным и статистике.
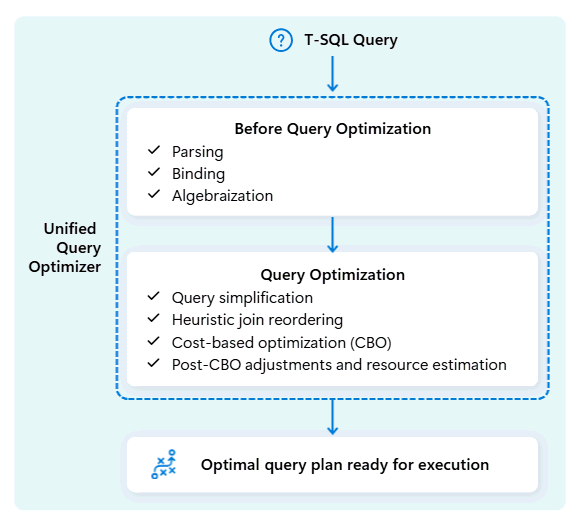
При оптимизации плана выполнения запроса оптимизатор унифицированных запросов учитывает все в одном пути: форму запроса, распределение данных таблиц и затраты на перемещение данных и локальную обработку. Унифицированный оптимизатор запросов может принимать грамотные компромиссы, например, решая, дешевле ли трансляция небольшой таблицы, чем перетаскивание большой. Это означает меньше ненужного перемешивания данных, более эффективное использование вычислительных ресурсов и более высокую производительность, даже для сложных или некачественно написанных запросов T-SQL.
Согласованность производительности не требует, чтобы разработчики потратили время на настройку запросов T-SQL вручную. Например, вам не нужно вручную определять оптимальный JOIN порядок запросов. Если в SQL сначала указывается большая таблица, а затем меньшая, высоко селективная таблица данных, оптимизатор может автоматически поменять их местами для повышения производительности. Будет использована меньшая таблица в качестве отправной точки для сопоставления строк (сторона "сборки"), а большая таблица будет использована для поиска (сторона "проверки", где будут осуществляться проверки на совпадения). Этот подход сводит к минимуму использование памяти, уменьшает перемещение данных и улучшает параллелизм, обеспечивая точные результаты.
Оптимизатор унифицированных запросов постоянно изучает прошлые выполнения запросов по мере развития рабочих нагрузок, уточняя алгоритм оптимизации, чтобы обеспечить оптимальную производительность. Пользователи получают преимущества от быстрого выполнения запросов автоматически, независимо от сложности и без необходимости вмешиваться.
Подсистема обработки распределенных запросов
В хранилище данных Fabric подсистема распределенной обработки запросов выделяет вычислительные ресурсы задачам в планах запросов. Модуль распределенной обработки запросов может планировать задачи между вычислительными узлами, чтобы каждый узел запускал часть плана запроса, что позволяет параллельно выполнять выполнение для повышения производительности. Сложные отчеты для больших наборов данных могут воспользоваться распределенной обработкой запросов.
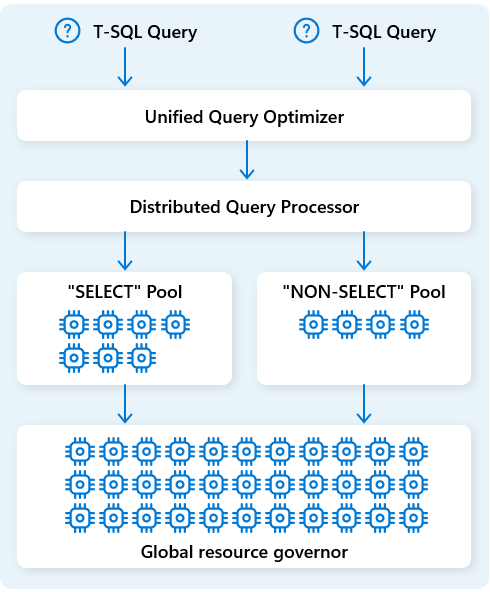
Для дальнейшего оптимизации ресурсов модуль распределенной обработки запросов разделяет вычислительные ресурсы на два пула: для SELECT запросов и задач приема данных (NON-SELECT запросов). Каждая рабочая нагрузка получает выделенные ресурсы по мере необходимости. Это означает, например, что ночные задания ETL не задерживают утренние панели мониторинга.
При быстрой подготовке узлов в облаке модуль распределенной обработки запросов автоматически масштабирует вычислительные ресурсы вверх или вниз в ответ на изменения тома запроса, размера данных и сложности запросов. Хранилище данных Fabric имеет возможности параллельной обработки для небольших наборов данных или данных в масштабе с несколькими петабайтами.
Подсистема выполнения запросов
Обработчик выполнения запросов — это процесс, который выполняет части распределенного плана выполнения, назначенные отдельным вычислительным узлам. Модуль выполнения запросов основан на том же механизме, который используется SQL Server и Базой данных SQL Azure для использования пакетного режима выполнения и форматов данных столбцов для эффективной аналитики больших данных с оптимальной стоимостью.
Модуль выполнения запросов считывает данные непосредственно из файлов Delta Parquet, хранящихся в Fabric OneLake, и использует несколько слоев кэширования (память и SSD) для ускорения производительности запросов и обеспечения оптимальной скорости выполнения запросов. Подсистема выполнения запросов обрабатывает данные в памяти и при необходимости извлекает дополнительные данные из кэша SSD или хранилища OneLake.
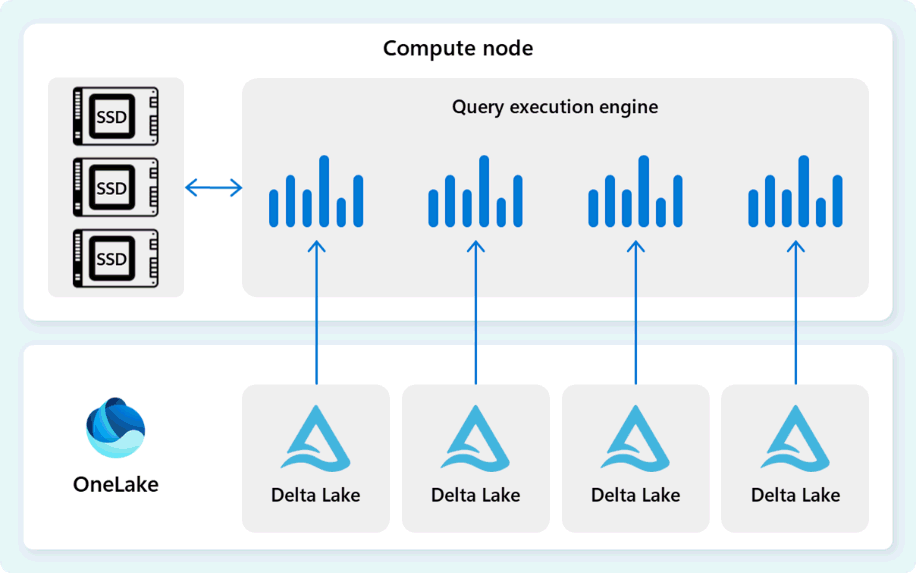
При обработке данных обработчик выполнения запросов выполняет ликвидацию столбцов и групп строк, чтобы пропустить сегменты, которые не относятся к запросу. Эта оптимизация уменьшает объем данных, отсканированных из файлов и кэша памяти, что помогает свести к минимуму использование ресурсов и повысить общее время выполнения.
Модуль выполнения запросов используется для фильтрации и агрегирования миллиардов строк, поддерживая универсальные шаблоны аналитики данных, используемые в современных решениях хранилища данных. Использование пакетного режима позволяет современным ЦП параллельно обрабатывать несколько строк, что значительно уменьшает издержки и обеспечивает выполнение запросов в сотни раз быстрее по сравнению с традиционным выполнением по строкам.
Управление метаданными и транзакциями
Подсистема хранилища использует метаданные для описания схемы таблицы, файловой организации, журнала версий и состояний транзакций. Эти метаданные позволяют подсистеме хранилища эффективно управлять данными и запрашивать их. Хранилище данных Fabric предлагает надежную и комплексную архитектуру управления метаданными и транзакциями, расширяя диспетчер транзакций OLTP для оркестрации параллельных операций метаданных и обеспечения соответствия ТРЕБОВАНИЯМ ACID.
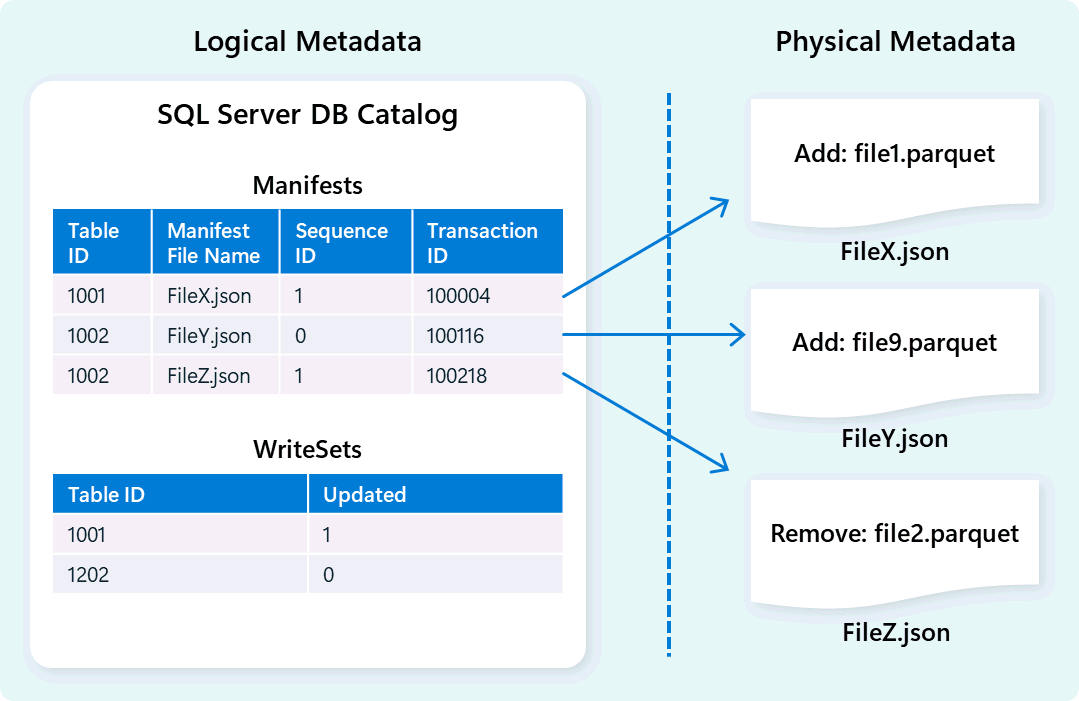
Эта конструкция обеспечивает быструю, надежную навигацию по состояниям транзакций, поддерживая рабочие нагрузки с высокой параллелизмом, обеспечивая согласованность.
Хранение данных и прием данных
Хранилище данных Fabric использует архитектуру Lakehouse с открытым форматом Delta для масштабируемого, безопасного и высокопроизводительного хранения. Формат таблицы Delta поддерживает управление версиями данных, обеспечивая мгновенный доступ к историческим моментальным снимкам с помощью перемещения по времени и клонирования без копирования для безопасных операций тестирования и отката. Пользовательские данные хранятся в OneLake, что позволяет всем движкам Fabric эффективно получать доступ к данным совместного использования без избыточности.
На основе этой основы хранилище данных Fabric предназначено для обеспечения оптимальной производительности приема данных с акцентом на простоту и гибкость. Движок эффективно управляет хранением данных таблицы с помощью автоматического сжатия данных, который объединяет фрагментированные файлы в фоновом режиме, чтобы уменьшить ненужное сканирование данных. Его интеллектуальный метод распределения данных делит и упорядочивает данные в микросекционные ячейки, чтобы повысить параллельную обработку и повысить результаты запроса. Эти возможности работают автономно без необходимости корректировки вручную.