Кэширование в хранилище данных Fabric
Область применения:✅ конечная точка аналитики SQL и хранилище в Microsoft Fabric
Получение данных из озера данных имеет решающее значение для операций ввода-вывода (ввода-вывода) с существенными последствиями для производительности запросов. Хранилище данных Fabric использует улучшенные шаблоны доступа для улучшения операций чтения данных из хранилища и повышения скорости выполнения запросов. Кроме того, он интеллектуально сокращает потребность в удаленном хранилище считывает, используя локальные кэши.
Кэширование — это метод, который повышает производительность приложений обработки данных, уменьшая операции ввода-вывода. Кэширование сохраняет часто доступ к данным и метаданным в более быстром уровне хранения, например локальной памяти или локальном диске SSD, чтобы последующие запросы могли выполняться быстрее непосредственно из кэша. Если определенный набор данных ранее был получен запросом, все последующие запросы будут извлекать эти данные непосредственно из кэша в памяти. Этот подход значительно уменьшает задержку ввода-вывода, так как локальные операции памяти значительно быстрее по сравнению с получением данных из удаленного хранилища.
Кэширование полностью прозрачно для пользователя. Независимо от происхождения, будь то таблица хранилища, ярлык OneLake или даже ярлык OneLake, ссылающийся на службы, отличные от Azure, запрос кэширует все данные, к которым он обращается.
В этой статье описаны два типа кэшей:
- Кэш в памяти
- кэш диска.
По мере доступа к запросу и получения данных из хранилища он выполняет процесс преобразования, который перекодирует данные из исходного формата на основе файлов в высокооптимизированные структуры в кэше памяти.

Данные в кэше организованы в сжатом формате столбцов, оптимизированном для аналитических запросов. Каждый столбец данных хранится вместе, отдельно от других, что позволяет улучшить сжатие, так как аналогичные значения данных хранятся вместе, что приводит к снижению объема памяти. Если запросы должны выполнять операции с определенным столбцом, например агрегатами или фильтрацией, подсистема может работать более эффективно, так как не нужно обрабатывать ненужные данные из других столбцов.
Кроме того, это хранилище столбцов также способствует параллельной обработке, что может значительно ускорить выполнение запросов для больших наборов данных. Модуль может одновременно выполнять операции с несколькими столбцами, используя современные многоядерные процессоры.
Этот подход особенно подходит для аналитических рабочих нагрузок, в которых запросы включают сканирование больших объемов данных для выполнения агрегирования, фильтрации и других операций с данными.
Некоторые наборы данных слишком большие для размещения в кэше в памяти. Чтобы обеспечить быструю производительность запросов для этих наборов данных, хранилище использует место на диске в качестве дополнительного расширения для кэша в памяти. Все сведения, загруженные в кэш в памяти, также сериализуются в кэш SSD.
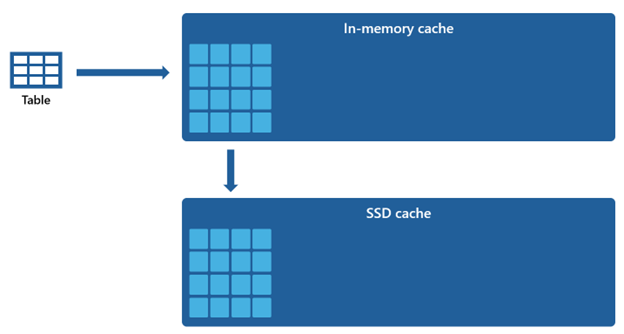
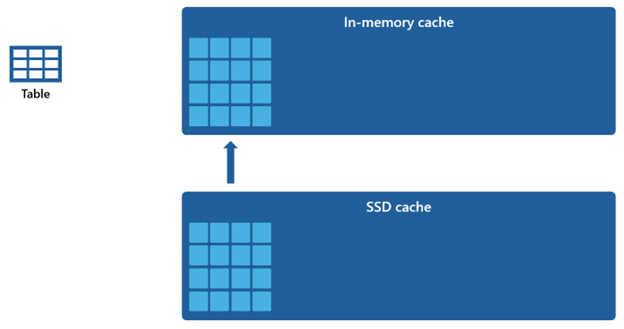
Учитывая, что кэш в памяти имеет меньшую емкость по сравнению с кэшем SSD, данные, удаленные из кэша в памяти, остаются в кэше SSD в течение длительного периода. Когда последующие запросы запрашивают эти данные, он извлекается из кэша SSD в кэш в памяти значительно быстрее, чем при получении из удаленного хранилища, в конечном счете обеспечивает более согласованную производительность запросов.
Кэширование остается постоянно активным и работает легко в фоновом режиме, не требуя вмешательства со своей стороны. Отключение кэширования не требуется, так как это неизбежно приведет к заметному ухудшению производительности запросов.
Механизм кэширования управляется и поддерживается самим Microsoft Fabric, и он не предлагает пользователям возможность вручную очистить кэш.
Полная согласованность транзакций кэша гарантирует, что любые изменения данных в хранилище, такие как с помощью операций языка обработки данных (DML), после первоначальной загрузки в кэш в памяти приведет к согласованным данным.
Когда кэш достигает порогового значения емкости и в первый раз считывается свежие данные, объекты, которые остаются неиспользуемыми в течение большей длительности, будут удалены из кэша. Этот процесс принят для создания пространства для притока новых данных и поддержания оптимальной стратегии использования кэша.